.gif&blockId=11b00c82-b138-8050-a58b-dcbceda2ef8f)



11. REVEAL for Visual-Language Model
REVEAL for Visual-Language Model란?
•
이미지 또는 비디오와 같은 시각 정보를 기반으로 언어를 이해하고 생성할 수 있는 시스템인 시각 언어 모델에 사용되는 기법
•
추론(논리적으로 사고하기) 과 작업에 필요한 특정 행동을 결합하고 외부 지식(외부 출처에서 얻은 정보)을 활용하여 이러한 모델의 의사 결정 방식을 개선하기 위해 고안된 기법이다.
목표
시각 정보와 언어 정보를 융합하여 정확한 답변을 제공
•
Vision Transformer와 T5 Encoder를 활용하여 시각 정보와 언어 정보를 최적화된 방식으로 결합함으로써 보다 정확한 응답을 생성할 수 있다.
•
복잡한 질문에 대해 정확하고 일관된 답변을 제공하며, 더 적은 학습 데이터로도 높은 성능을 발휘할 수 있어 효율적이고 유연하게 활용될 수 있다.
편향과 환각(hallucination)을 줄이는 것
•
Knowledge Base에서 검색한 외부 정보를 바탕으로 실세계의 사실을 기반으로 답변을 생성하므로, 사실에 기반한 추론을 하기 때문에, 편향과 환각(hallucination) 현상이 크게 개선된다.
적은 교육 사례로 강력한 성능
•
REVEAL은 적은 수의 예제로 학습한 경우에도 잘 작동하도록 설계되었다.
•
이는 모델이 많은 데이터를 필요로 하지 않고도 빠르게 학습하고 새로운 작업에 적응할 수 있다는 것을 의미하기 때문에 중요하다.
예를 들어 모델이 고양이 사진을 몇 개만 본 경우에도 새로운 고양이 사진을 효과적으로 인식하고 설명할 수 있다.
주요 동작
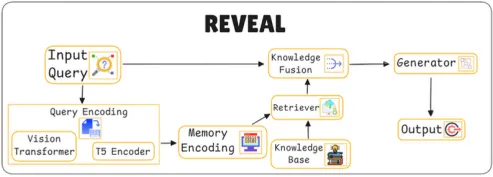
Multi Query Encoding (쿼리 인코딩)
•
쿼리를 인코딩하여 모델이 텍스트와 이미지 정보를 처리할 수 있도록 한다.
•
Vision Transformer: 이미지 데이터를 인코딩하여 시각적 특징을 추출한다.

•
T5 Encoder: 텍스트 쿼리를 인코딩하여 언어 정보를 추출한다.
•
시각 정보와 언어 정보를 각각 최적의 방식으로 처리할 수 있어, 모델이 두 가지 정보를 결합하여 해석할 수 있다.
사람이 글을 읽으면서 동시에 사진을 보며 이해하는 것과 같다. 글과 이미지 정보를 따로 처리한 후, 종합적으로 이해하는 과정이다.
Memory Encoding (메모리 인코딩) with Retriever
•
모델이 과거의 지식이나 외부 지식과 관련된 정보를 저장하고, 이를 바탕으로 답변을 생성할 수 있도록 메모리 인코딩을 수행한다.
•
Knowledge Base(지식 베이스)와 연결하여 과거의 정보를 검색하고, 필요한 경우 이전 정보를 참조하여 메모리 인코딩을 수행한다. - Retriever
•
메모리 인코딩을 통해 모델이 일관성 있는 답변을 제공할 수 있다.
사람이 이미 알고 있는 배경 지식을 활용하여 새로운 질문에 답하는 것과 유사하다. 예를 들어, 이전에 배운 지식을 바탕으로 새 정보를 더 잘 이해할 수 있다.
Knowledge Fusion (지식 융합)
•
검색된 정보, 메모리 정보, 입력 쿼리를 결합하여 최적의 답변을 생성하기 위한 문맥을 형성한다.
•
검색된 정보와 메모리 인코딩 정보를 바탕으로 관련된 지식을 통합하여 쿼리와 관련된 최적의 컨텍스트를 만든다.
•
이 과정을 통해 모델은 시각적 정보와 언어적 정보를 결합하여 더 구체적이고 정확한 답변을 생성할 준비를 한다.
•
시각 정보와 언어 정보를 통합하여, 다양한 정보 소스에서 일관성 있는 문맥을 형성할 수 있다.
여러 자료를 조합하여 종합적인 결론을 내는 것과 같다. 예를 들어, 여러 책을 참고하여 한 주제에 대한 깊이 있는 이해를 만들어 내는 것과 비슷하다.
12. ReAct
ReAct란?
•
추론과 행동(Reasoning and Action)을 결합하여 모델이 환경과 상호 작용하며, 상황을 인식하고 실시간으로 업데이트하는 시스템
•
모델이 주변 상황과 정보를 지속적으로 반영하여 논리적인 의사 결정을 할 수 있도록 돕는다.
•
과거 행동과 생각을 업데이트하여 모델이 일관성을 유지하면서도 신뢰성 있는 답변을 생성하도록 설계되었다.
목표
추론과 행동의 결합
•
ReAct 기법을 사용하면 AI 모델이 해야 할 일을 생각하는 것 뿐만 아니라 그 생각을 바탕으로 행동을 취할 수 있다.
•
과거의 정보를 반영하여 상황에 맞는 결정을 내리고, 실시간 피드백을 통해 오류를 줄이며 신뢰성을 높인다.
예를 들어 AI가 게임을 플레이하는 경우 게임 상황을 분석 (추론) 한 다음 게임에서 승리하는 데 가장 적합한 동작 (액션) 을 할 수 있다.
컨텍스트(Context) 업데이트
컨텍스트: 모델이 현재 상황을 이해하는 데 도움이 되는 배경 정보
•
React는 컨텍스트를 지속적으로 업데이트한다.
→ 즉, 모델이 환경과 상호 작용하면서 새로운 정보를 수집하고 그에 따라 이해도를 조정한다.
예를 들어 미로의 특정 경로가 막다른 길로 이어진다는 사실을 AI가 알게 되면, 향후에는 해당 경로를 피하도록 컨텍스트를 업데이트합니다.
실시간 피드백
•
모델이 조치를 취한 후 즉시 받는 정보
•
이 피드백은 모델이 해당 동작이 올바른지 아닌지를 이해하는 데 도움이 된다.
•
작업이 완료되었는지를 실시간으로 확인하고, 필요할 경우 추가적인 행동을 수행하기 때문에 실수(오류)를 줄이고 신뢰성을 높인다.
•
이를 통해 ReAct는 복잡한 상황에서의 문제 해결 능력을 향상시키고, 보다 투명하고 일관성 있는 응답을 제공할 수 있다.
예를 들어 AI가 미로 속에서 방향을 잘못 틀면 그 실수에 대한 피드백을 즉시 받게 됩니다.이를 통해 모델은 향후 동작을 학습하고 개선할 수 있습니다.
주요 동작
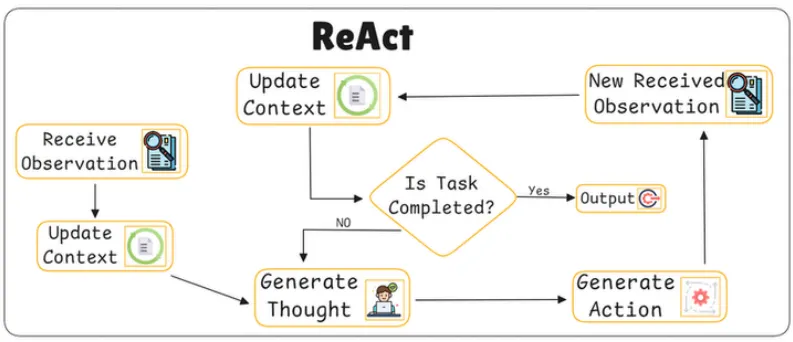
Receive Observation (관찰 수신)
•
모델이 새로운 환경 정보를 수신하여 상황을 인식하는 단계
•
모델은 사용자로부터 새로운 입력(관찰)을 받거나 주변 환경에서 정보를 수집한다.

현재 상황에 대한 정보를 얻어내는 것이 키포인트.
•
모델이 새로운 정보에 따라 상황을 인식하고 이에 맞는 행동을 준비할 수 있도록 돕는다.
사람이 새로운 장소에 도착하여 주변을 둘러보고 상황을 이해하는 것과 같다.
Update Context (문맥 업데이트)
•
관찰된 정보를 바탕으로 문맥을 업데이트하여 모델의 상황 인식을 최신 상태로 유지한다.
•
새롭게 관찰된 정보나 과거의 행동을 문맥(Context)에 추가하여 모델이 일관성 있게 상황을 인식할 수 있도록 한다.
•
모델이 과거의 정보를 잊지 않고, 현재의 상황을 기반으로 다음 행동을 결정할 수 있게 한다.
사람이 이전 경험과 현재 정보를 바탕으로 지금의 상황을 이해하는 것과 같다.
Generate Thought (사고 생성)
•
현재 문맥을 바탕으로 모델이 무엇을 해야 할지에 대한 생각을 생성하는 단계
•
문맥을 바탕으로 다음 단계에 대한 사고를 형성한다.
•
상황에 맞는 논리적인 판단을 내려, 모델이 불필요한 행동을 줄이고 효율적으로 작업을 수행할 수 있도록 한다.
사람이 현재 상황을 분석하고 다음에 해야 할 일을 계획하는 것과 유사하다.
Generate Action (행동 생성)
•
사고에서 결정된 내용을 바탕으로 구체적인 행동을 생성하는 단계
•
사고에서 얻은 정보를 토대로 모델이 실제 행동을 수행하거나, 특정 작업을 실행할 준비를 한다.
•
모델이 단순히 생각에서 끝나는 것이 아니라, 구체적인 행동으로 이어져 문제를 해결할 수 있도록 한다.
사람이 계획한 내용을 바탕으로 실제로 행동에 옮기는 것과 비슷하다.
Is Task Completed? (과제가 완료되었는가?)
•
모델이 수행해야 할 작업이 완료되었는지 확인하는 단계
1.
현재 상황을 평가하여, 목표한 작업이 완료되었는지 또는 추가적인 행동이 필요한지를 확인한다.
2.
작업이 완료되지 않았다면 새로운 관찰을 수신하고 과정을 반복한다. → Generate Thought(사고 생성) 단계로 돌아간다.
•
과제를 명확하게 완료하고, 필요할 경우 계속해서 작업을 수행하도록 하여 일관된 결과를 제공한다.
사람이 목표한 일을 마쳤는지 확인하고, 마무리되지 않았다면 추가 작업을 수행하는 것과 같다.
13. RE-PLUG(Retrieval Plugin)
REPLUG란?
•
외부 database로부터 knowledge를 받아와 특정 정보가 필요한 경우
→ 즉 knowledge-intensive task에서 knowledge를 보충하여 hallucination 문제를 줄여준다는 개념
•
대형 언어 모델(LLM)에 외부 문서를 검색하여 추가 정보를 제공함으로써 예측 정확성을 향상시키는 시스템
•
언어 모델을 수정하지 않고 외부 정보를 입력에 추가하는 방식으로 동작하므로, 기존 모델에 유연하게 적용할 수 있다.
•
환각(hallucination)을 줄이고, 필요한 경우 특정 분야에 대한 전문 지식을 확장하는 데 유용하다.
목표
환각 현상 감소
•
외부 문서를 통해 사실 기반의 정보를 추가함으로써, 모델이 잘못된 정보를 생성하는 환각 현상을 줄일 수 있다.
•
hallucination 억제 예시

◦
형광색으로 표시된 결과가 기존 LM의 방법론인 BART의 결과이고, RAG, FiD-RAG DPR과 같은 model들은 retrieval-augmented language model이다.
◦
BART의 결과에서는, 앙리가 1931년생 잉글랜드 축구선수라는, 사실과 다른 output을 산출한 것과 달리, retrieval-augmented language model은 실제 정보를 아주 잘 산출해 낸 것을 확인할 수 있다.
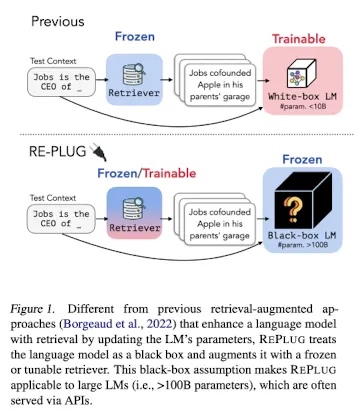
•
이러한 기존 retrieval-augmented language model 방법론들은 retriever와 함께 붙어있는 LM부분의 내부에 접근이 가능해야만 하며, 이 부분도 retriever와 함께 한번에 train 시켜야 하기 때문에 GPT와 같은, API로만 제공되는 LLM, 즉 black box LM에 대해서는 적용하기 힘들다는 한계가 존재하였다.
•
그래서, 이러한 LM 부분을 fixed-black box로 두고, retrieval에 대해서만 훈련하며, LM과 retriever을 탈부착하는 개념으로 둔 새로운 retrieval-augmented LM framework인 REPLUG(Retrieve and Plug)를 제안했다.
주요 동작
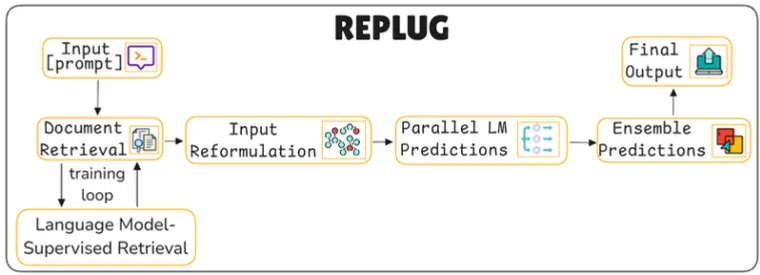
Document Retrieval (문서 검색)
•
입력된 쿼리와 관련된 문서를 외부 데이터베이스에서 검색하여 모델이 참고할 수 있도록 한다.
•
시스템은 쿼리와 연관된 문서를 데이터베이스에서 찾아 검색 결과를 생성한다.
•
이 과정에서 언어 모델 기반 검색(Language Model-Supervised Retrieval)이 사용되며, 모델의 피드백을 통해 검색 정확도를 높일 수 있다.
좀 더 살펴보자면
Input Reformulation (입력 재구성) + Ensemble
•
검색된 문서를 바탕으로 입력 쿼리를 재구성하여 모델이 더 잘 이해할 수 있도록 만든다.
•
검색된 문서에서 주요 정보를 추출하여 쿼리에 추가하거나, 질문을 더 구체화하여 모델이 정확한 답변을 생성할 수 있도록 한다.
•
모델이 필요한 정보를 놓치지 않도록 입력을 최적화하여 응답의 정확성을 높이는 데 있다.
좀 더 살펴보자면
14. MEMO RAG
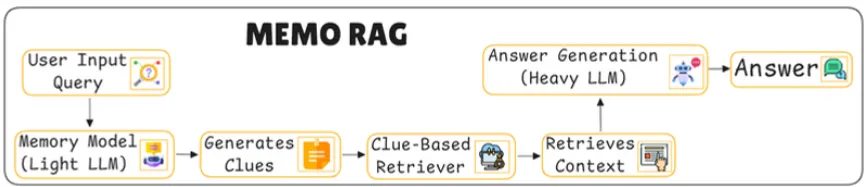
MEMO RAG란?
•
복잡한 쿼리를 처리하기 위해 메모리와 검색 기능을 결합한 시스템
•
이 시스템은 비교적 가벼운 모델(Light LLM)을 사용하여 먼저 임시 답변 초안을 작성하고, 이 답변을 단서로 삼아 보다 정확한 외부 데이터를 검색한 뒤, 더욱 강력한 모델(Heavy LLM)이 이를 기반으로 최종 답변을 생성하는 구조(Light to Heavy)이다.
•
특히 금융, 법률 등과 같은 복잡하고 긴 문서의 요약 및 질문 응답에 강점을 지니며, 다중 증거 기반의 정보 집계 작업에서도 우수한 성능을 보인다.
목표
암시적 정보 요구 처리
•
암시적인 정보 요구가 있는 경우, 단순한 텍스트 매칭을 넘어 문맥을 이해하고 추론하여 필요한 정보를 찾아야 한다.
•
기존 RAG에서는 사용자가 명확하게 표현하지 않은 정보 요청에 대해서는 제대로 대응하지 못한다.
•
이를 위해 MemoRAG는 '메모리 모듈'을 통해 전체 데이터베이스의 중요한 정보를 기억하고, 이를 기반으로 필요한 단서를 생성하여 최종 답변을 형성하는 데 도움을 준다.
예를 들어, "이 소설에서 사랑의 주제는 어떻게 표현되었나요?"라는 질문에 대해 기존 RAG는 직접적인 검색 결과를 제공하기 어렵다.
기존 RAG의 텍스트 매칭 의존성을 감소시키는 것
•
검색에 필요한 단서를 포함시켜 최종 답변을 형성하는 데 도움을 주도록 한다.
•
기존 RAG는 사용자 질문과 데이터베이스 간의 단순한 텍스트 매칭에 의존하는 한계를 지닌다.
•
기존 RAG의 수식:
◦
: 생성 모델,
◦
: 검색 모델
◦
: 입력 쿼리
◦
: 데이터베이스
◦
: 검색된 문맥
◦
: 최종 답변
•
MemoRAG의 수식:
◦
: 메모리 모델 에 의해 생성된 임시 답변
▪
검색에 필요한 단서를 포함
→ 데이터베이스 의 전역 메모리를 형성하여 사용자가 원하는 정보를 암시적인 쿼리에서도 찾아낼 수 있도록 한다.
주요 동작
Light LLM (메모리 모듈)
•
가벼운 언어 모델로서, 사용자 쿼리에 대한 임시 답변 초안(정보 검색을 위한 힌트)을 생성하고 검색에 사용할 단서를 형성한다.
•
입력된 쿼리를 바탕으로 대략적인 답변을 생성하며, 이를 통해 검색기가 외부 데이터에서 관련 정보를 더 효과적으로 찾을 수 있게 단서를 제공한다.
•
이 과정에서 단서는 정보 검색의 가이드 역할을 한다.
•
사용자의 입력 쿼리가 들어오면, 먼저 경량 LLM이 해당 쿼리를 기반으로 메모리에서 단서를 생성한다.
•
MemoRAG의 메모리 모듈은 긴 문맥을 효율적으로 처리하기 위해 토큰을 압축하여 메모리 토큰으로 변환하는데, 이를 통해 더 긴 텍스트도 작은 메모리 자원을 사용하여 관리할 수 있다.
•
토큰 압축 과정
◦
일반적으로 LLM의 각 층(layer)은 입력 토큰 을 QKV(query-key-value) 프로젝션을 통해 연산하여 주어진 문맥을 이해하게 된다. 하지만 이 방식은 메모리에 많은 자원을 소모한다.
◦
MemoRAG에서는 특정 층에서 '메모리 토큰' 을 추가하고, 이 메모리 토큰을 통해 문맥을 압축하여 유지한다.
◦
이 과정은 사람의 단기 기억과 유사하게 작동하여, 즉각적으로 필요한 정보는 유지하면서 불필요한 세부 정보는 제거해 효율성을 높인다.
•
이와 같은 메모리 토큰 방식으로 MemoRAG는 기존 LLM이 처리할 수 없는 수백만 토큰 수준의 데이터를 관리할 수 있게 된다.
예를 들어, MemoRAG는 NVIDIA T4 16GiB GPU에서 최대 68K 토큰까지, NVIDIA A100 80GiB GPU에서는 최대 1백만 토큰까지 처리할 수 있다.
Heavy LLM (답변 생성)
•
검색된 문맥을 바탕으로 최종 답변을 생성하는 무거운 언어 모델
•
이전 단계에서 준비된 문맥을 참고하여 최종적으로 정확하고 종합적인 답변을 생성한다.
•
이 모델은 무거운 연산을 수행할 수 있어, 보다 세부적이고 정교한 답변을 제공할 수 있다.
•
단서들을 바탕으로 실제 검색이 이루어지고, 필요한 문맥을 가져온 후 무거운 LLM이 최종 답변을 생성한다.
•
이 단계에서 단서 기반 검색을 통해 더 구체적이고 정확한 답변을 생성하게 된다.
15. ATLAS(Attention-based RAG)
ATLAS(Attention-based Language Augmented System)란?
•
외부 문서를 검색하여 언어 모델의 응답 정확성을 높이는 시스템
•
외부 문서에 액세스하고 검색할 수 있도록 하여 이러한 모델을 개선한다.
→ 질문이 있을 때 ATLAS는 방대한 텍스트 모음에서 관련 정보를 검색할 수 있으므로 보다 정확한 답변을 제공할 수 있다.
•
이중 인코더 검색기와 Fusion-in-Decoder 모델을 사용하여 입력 쿼리와 문서 정보를 통합함으로써, 단순한 기억에 의존하지 않고 정확한 응답을 생성할 수 있도록 설계되었다
목표
퓨전-인-디코더 모델
•
ATLAS는 관련 문서를 검색한 후 퓨전-인-디코더라는 모델을 사용한다.
•
이 모델은 질문의 정보와 검색된 문서를 결합한다.
•
언어 모델이 검색된 문서와 쿼리를 통합해 응답을 생성하므로, 단순한 기억 기반 응답이 아닌 정확한 추론에 기반한 답변을 제공할 수 있다.
재훈련 없이 문서 색인 업데이트 가능
•
기존 언어 모델은 정보 암기에 크게 의존하는 경우가 많다.
•
ATLAS는 문서 색인을 재훈련 없이 업데이트할 수 있어 최신 정보에 기반한 답변을 생성할 수 있다.
•
모델은 학습한 사실만 회상하는 대신 현재 정보와 특정 정보를 조회할 수 있어 더욱 정확하고 상황에 맞는 응답을 제공할 수 있다.
주요 동작
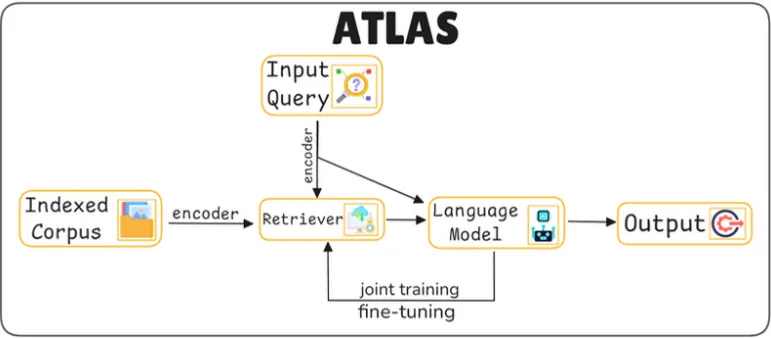
Dual Encoder - Retriever(Contriever) (검색기)
•
여기서 쓰인 리트리버 모듈은 연속 dense 임베딩을 기반으로 하는 정보 검색 기법인 Contriever를 기반한다.
Contriever: Izacard et al., 2022에서 효율적인 정보 검색(retrieval)을 수행하기 위해 설계된 딥러닝 기반의 문장 임베딩 모델이다.
◦
쿼리와 문서가 트랜스포머 인코더에 의해 독립적으로 임베드되는 이중 인코더 아키텍처를 사용한다.
•
Contriever 모델은 MoCo contrastive loss을 사용하여 사전 학습되며, 비지도 데이터만 사용한다.
MoCo contrastive loss: 대조 학습(contrastive learning)에서 서로 다른 이미지나 텍스트 간의 유사도와 차이를 학습하도록 설계된 손실 함수
•
여기서 dense retriever의 장점은 경사 하강 및 증류와 같은 표준 기술을 사용하여 문서 주석 없이 쿼리 및 문서 인코더를 모두 학습시킬 수 있다는 것이다.
언어 모델(Language Model)
•
언어 모델은 Fusion-in-Decoder(T5) 방식을 사용하여 쿼리와 검색된 문서의 정보를 결합하여 응답을 생성
•
이 과정에서는 문서와 질문이 통합된 형태로 디코딩되며, 단순한 기억이 아닌 외부 지식을 활용한 추론이 가능해진다.
•
과정
1.
시퀀스 간 모델의 인코더 내 퓨전 수정에 의존하며, 인코더에서 각 문서를 독립적으로 처리
2.
다음 서로 다른 문서에 해당하는 인코더의 출력을 연결하고 디코더에서 이 단일 시퀀스에 대해 교차 주의를 수행
3.
인코더에서 쿼리를 각 문서에 연결
•
언어 모델에서 검색된 문서를 처리하는 또 다른 방법은 쿼리와 모든 문서를 연결하고 이 긴 시퀀스를 모델의 입력으로 사용하는 것이다.
그러나 해당 접근 방식은 인코더의 자체 주의로 인해 문서 수에 따라 복잡성이 이차적으로 증가하기 때문에 문서 수에 따라 확장되지 않는다.
Joint Training (동시 학습) 및 Fine-tuning (미세 조정)
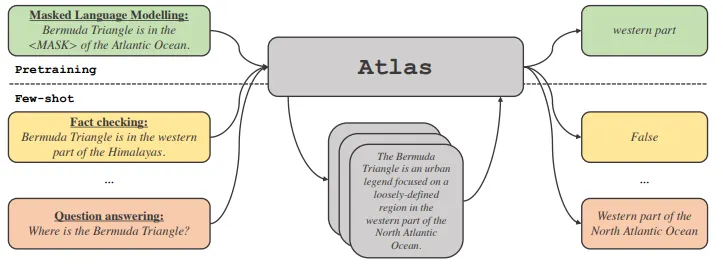
•
검색기와 언어 모델을 공동으로 학습하여 검색과 응답 생성이 조화를 이루도록 최적화한다.
•
Fine-tuning을 통해 특정 분야의 질문 응답 성능을 더욱 개선할 수 있다.
•
검색과 응답 생성 과정이 서로 긴밀하게 협력할 수 있도록 최적화하는 데 있다.
책을 찾는 기술과 그 책의 내용을 바탕으로 설명하는 기술을 동시에 연마하는 것과 같다.
•
구성 요소를 Joint로 사전 훈련하는 것이 few-shot 성능에 매우 중요하다는 사실을 발견했고 이를 위해 기존 및 새로운 사전 훈련 작업과 체계를 신중하게 평가한다.
•
Masked Language Modelling (MLM) 작업을 통해 모델이 문장에서 누락된 단어(예: "Bermuda Triangle is in the <MASK> of the Atlantic Ocean")를 추론하게 학습한다. 이를 통해 텍스트의 문맥을 이해하고 정보를 잘 추출할 수 있도록 모델의 기본 언어 이해 능력을 향상시킨다.
