.gif&blockId=11b00c82-b138-8050-a58b-dcbceda2ef8f)



16. RETRO
RETRO란?
•
대규모 언어 모델을 더욱 효율적으로 개선하기 위한 RETRO(Retrieval-Enhanced Transformer) 모델
•
입력 텍스트를 작은 조각으로 나누어, 대규모 텍스트 데이터베이스에서 유사한 정보를 검색하여 문맥을 풍부하게 한다.
•
사전 학습된 BERT 임베딩을 사용해 관련된 조각(chunks)을 찾아내고, 이를 통해 모델의 예측을 개선하는 chunked cross-attention 메커니즘을 사용하여 보다 적은 계산 자원으로도 효율적인 예측을 가능하게 한다.
•
이 시스템은 단순히 모델의 파라미터 수를 늘리기보다, 외부 대규모 데이터베이스(최대 2조 개 토큰)를 활용하여 모델이 더 효과적인 예측을 수행할 수 있도록 설계되었다.
•
질문 응답 및 텍스트 생성과 같은 작업에서 우수한 성능을 발휘한다.
목표
기존 모델의 컴퓨팅 자원 소모 절감
•
전통적으로 언어 모델의 성능을 높이기 위해 모델의 파라미터를 증가시키거나 더 많은 데이터를 학습하는 방식을 사용해 왔다.
•
그러나 이러한 접근법은 컴퓨팅 자원을 대폭 소모하며, 대규모 데이터 학습이 제한된 환경에서는 비효율적일 수 있다.
•
그래서 RETRO 모델은 모델의 파라미터 수를 크게 증가시키지 않으면서도, 대규모 데이터베이스(최대 2조 개의 토큰)에 접근하여 모델 성능을 향상시키는 것으로 목표를 잡았다.
•
이를 통해서 RETRO는 파라미터 수가 25배 더 많은 모델과 유사한 성능을 나타낼 수 있게 되었고, 데이터베이스에서 직접적으로 관련된 문맥을 검색해 예측을 개선시킨다.
주요 동작
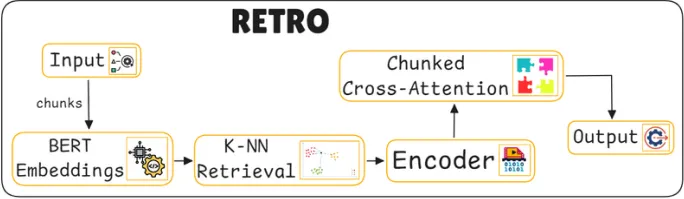
입력 데이터 분할
•
사용자가 입력한 텍스트는 일정 길이의 청크(chunk)로 분할된다.
◦
긴 텍스트 입력을 처리하기 위해 일정한 길이의 작은 조각으로 나누고, 이를 개별적으로 처리하여 필요한 문맥을 보강할 수 있게 한다.
예를 들어, 2048개의 토큰 길이로 이루어진 입력 텍스트는 64개의 토큰을 가진 청크로 나뉜다.
BERT 임베딩
•
BERT Embeddings (BERT 임베딩)
◦
1에서 생성된 각 청크를 BERT 임베딩으로 변환하여 의미를 벡터화하고, 이후 검색 과정에서 유사도를 비교할 수 있게 한다.
k-최근접 이웃(k-NN) 검색
•
K-NN Retrieval (K-최근접 이웃 검색)
◦
검색된 유사한 청크들은 인코더(encoder)를 통해 처리된다.
◦
인코더는 이러한 유사 청크들을 모델의 예측에 유용하게 활용할 수 있도록 정보를 구조화하고 통합한다.
◦
이때 청크 단위 교차 주의(chunked cross-attention) 메커니즘이 사용된다. 이 메커니즘은 검색된 유사 청크들이 각 입력 청크의 예측에 영향을 미치도록 하며, 청크 단위의 병렬 처리를 통해 효율적인 계산이 가능하다.

청크 단위 교차 어탠션(chunked cross-attention) 메커니즘
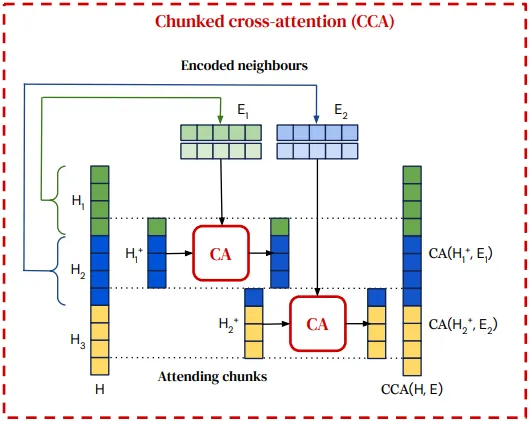
•
청크의 병렬 처리: 각 입력 청크는 검색된 유사 청크들과 병렬로 Cross-attention(CA)를 수행하며, 이로 인해 정보 교환이 효율적이고 빠르게 이루어진다.
•
상대적 위치 인코딩 사용: 청크와 검색된 청크 간의 상대적 위치 정보를 반영하여, 모델이 시퀀스 내에서의 위치와 관계를 이해할 수 있게 한다.
•
선형 시간 복잡도: 검색된 데이터 양에 비례하여 선형적으로 계산이 이루어지므로, 매우 대규모 데이터베이스를 사용하더라도 모델의 계산 효율성을 유지할 수 있다.
•
첫 번째 청크의 Neighbours은 첫 번째 청크의 마지막 토큰과 두 번째 청크의 토큰에만 영향을 미치므로 인과관계가 유지된다.
•
주어진 텍스트 청크()와 가장 유사한 텍스트 청크들(Neighbours)을 데이터베이스에서 검색해와 모델의 예측에 활용하는 역할을 한다.
RETRO 시스템 전체 동작 수식
•
수식의 결론은 모델이 각 청크별로 검색된 정보를 기반으로 더 풍부한 문맥을 반영할 수 있도록 한다는 것이다.
◦
: 입력 텍스트 시퀀스.
◦
: 모델의 파라미터.
◦
: 데이터베이스.
◦
: 청크 에 대해 데이터베이스에서 검색된 -최근접 이웃들.
•
첫 번째 청크 에는 검색된 데이터가 없으며, 이후의 청크들은 각 청크의 이전 청크의 검색 결과를 바탕으로 예측을 수행한다.
•
이를 통해 각 토큰의 예측은 해당 토큰 이전의 텍스트와 데이터베이스에서 검색된 유사 문맥에 의존하게 된다.
17. AUTO RAG
AUTO RAG란?
•
다양한 RAG(Retrieval-Augmented Generation) 구성 요소를 자동으로 최적화하여 각 데이터셋에 적합한 RAG 설정을 찾는 프레임워크
•
모듈화된 노드 기반 구조를 사용하여 여러 구성 요소를 실험하고, 효율성을 높이기 위해 greedy 최적화 접근법을 사용한다.
목표
자동 최적화
•
AutoRAG는 AutoML(자동화 머신러닝) 접근 방식을 사용해 다양한 RAG 기술 조합을 실험하고 평가하여 성능을 최적화한다.
•
기존 RAG 시스템에서는 쿼리 확장, 검색, 패시지 보강, 패시지 재랭킹, 프롬프트 생성 등 다양한 기술을 수동으로 설정하고 평가해야 한다.
•
하지만 이러한 방식은 데이터셋에 따라 성능이 크게 달라질 수 있고, 최적의 설정을 찾는 데 시간과 자원이 많이 소요된다.
•
그래서 AutoRAG는 이러한 문제를 해결하기 위해 자동으로 최적화된 RAG 모듈 구성을 탐색하고, 데이터셋에 최적화된 RAG 파이프라인을 제공하는 것을 목표로 하고 있다.
주요 동작
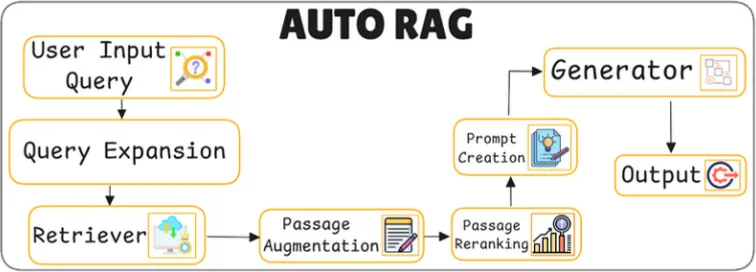
쿼리 확장(Query Expansion)
•
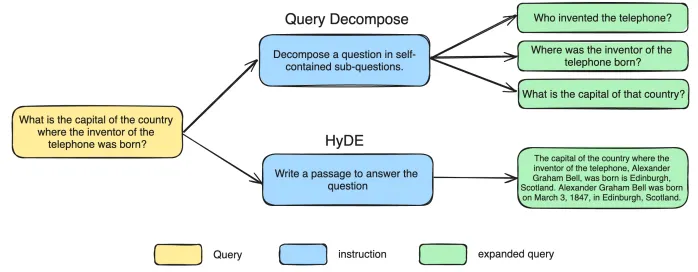
쿼리 분해(Query Decompose)
◦
복잡한 다중 단계(multi-hop) 질문을 단일 단계(single-hop) 질문으로 분해하는 방식
예를 들어, "전화를 발명한 사람이 태어난 나라의 수도는?"이라는 질문을 세 개의 단순한 질문으로 나눈다: "전화를 발명한 사람은 누구인가?", "그 사람은 어디에서 태어났는가?", "그 나라의 수도는 무엇인가?" 이렇게 나누어 검색을 수행하면 각 질문에 대한 정확한 정보를 찾을 수 있다.
◦
해당 과정에서 각 분해된 질문의 검색 정확도를 다음과 같은 수식으로 평가할 수 있다.
•
HyDE(Hypothetical Document Embedding)
◦
사용자가 요청한 질문에 대해 가상으로 예측된 문서를 생성하여 해당 질문에 대한 관련 문서를 더 잘 찾을 수 있도록 한다.
◦
질문과 유사한 가상 텍스트를 생성하여 검색의 유사도를 높인다.
예를 들어, "Ars-HDGunn 구조는 무엇인가?"라는 질문에 대해 HyDE는 "Ars-HDGunn 구조는 첨단 재료와 혁신적인 기술을 통합하여 고효율적이며 지속 가능한 건축 디자인이다"와 같은 가상 답변을 생성하고, 이를 검색에 활용하여 정확한 문서를 찾는다.
◦
이때, HyDE로 생성된 가상 텍스트 와 실제 검색된 문서 간의 코사인 유사도(Cosine Similarity)를 계산하여 검색 성능을 평가한다. 아래는 해당 수식이다.
▪
이 유사도가 높을수록 HyDE 확장된 쿼리가 검색 성능에 긍정적인 영향을 미친다고 할 수 있다.
검색(Retriever)
•
위 과정을 지나서 나온 확장된 쿼리를 사용하여 데이터베이스에서 관련 정보를 찾아낸다.
•
AutoRAG는 각각의 검색 모듈을 평가하여 최적의 검색 모듈을 선택한다.
•
대표적인 검색 방법으로는 다음이 있다.
◦
BM25
▪
텍스트의 빈도수와 길이를 고려하여 쿼리와 문서 간의 유사도를 계산하는 전통적인 검색 알고리즘
◦
Vector DB
▪
텍스트를 임베딩 벡터로 변환하여 의미적으로 유사한 문서를 찾는 방식
▪
이를 통해 단순한 키워드 일치를 넘어, 문장의 의미까지 고려하여 검색할 수 있다.
◦
하이브리드 검색
▪
BM25와 벡터 데이터베이스의 장점을 결합하여, 텍스트의 키워드 기반 유사도와 의미 기반 유사도를 동시에 고려한 검색 결과를 제공한다.
▪
하이브리드 검색에서는 Reciprocal Rank Fusion(RRF), Convex Combination(CC), Distribution-Based Score Fusion(DBSF) 등 다양한 조합 방식이 사용될 수 있다
▪
여기서 특히 하이브리드 검색에서 검색 결과의 순위를 결정하는 Reciprocal Rank Fusion (RRF) 방식을 사용하는 경우가 많다.
RRF는 아래 보이는 수식처럼 두 가지 다른 검색 방식의 결과를 통합하여 최종 순위를 결정한다.
•
: 쿼리 q와 문서 d의 BM25(레벨적) 검색 결과의 순위
•
: 쿼리 q와 문서 d의 벡터 임베딩(의미적) 검색 결과의 순위
•
: 작은 정수 값으로, 보통 60이 사용되며 순위가 낮을수록 큰 가중치를 부여하는 역할을 한다.
•
RRF 수식은 두 가지 검색 결과를 융합하여 높은 순위에 있을수록 큰 가중치를 부여하고, 최적의 검색 결과를 산출하는 데 도움을 준다.
패시지 보강(Passage Augmentation)
•
검색 단계에서 얻은 패시지를 더 보강하여 문맥을 더욱 풍부하게 만든다.
•
여기서는 패시지 보강을 통해 검색된 결과에 추가적인 정보(예: 이전 또는 이후 패시지)를 추가하여 사용자 질문에 대한 답변을 강화한다.
예를 들어, "이론적으로 유사한 내용이 더 앞뒤에 있다면?"이라는 가정 하에, 패시지 보강 단계에서 Prev-Next Passage Augmenter가 사용될 수 있다. 이는 특정 패시지의 이전 및 다음 패시지를 함께 가져와 추가적인 문맥 정보를 제공하여 정확성을 높인다.
•
이때 선택된 패시지의 순위와 정확도를 평가하는 방식으로 패시지 보강의 효과를 측정한다.
•
여기서는 Precision@K와 같은 지표를 사용할 수 있다.
◦
: 상위 개의 패시지를 고려할 때, 관련성 높은 패시지의 개수를 기준으로 정확도를 평가하는 지표
패시지 재랭킹(Passage Reranking)
•
패시지 재랭킹은 검색된 패시지들 중에서 가장 관련성이 높은 패시지를 상위에 배치하는 단계이다.
•
초기 검색된 패시지를 순위를 재조정하여 가장 관련성이 높은 패시지를 상위에 배치한다.
•
AutoRAG는 다양한 재랭킹 모델을 사용하여 패시지의 순위를 다시 평가한다.
•
이 단계에서는 다음과 같은 재랭킹 방법들이 사용된다.
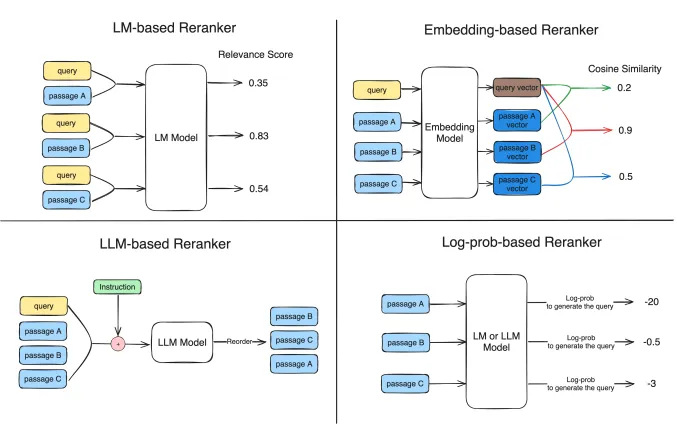
◦
MonoT5(LM-based Reranker): T5 모델을 기반으로 한 재랭킹 기법으로, 쿼리와 패시지의 유사도를 평가하여 관련성이 높은 패시지에 높은 점수를 부여한다.
◦
Flag Embedding Reranker(LM-based Reranker): 다양한 임베딩을 조합하여 패시지의 유사성을 평가하는 방식이다. 이 모델은 특히 LLM을 기반으로 한 Flag Embedding Reranker가 높은 성능을 보인다
◦
RankGPT(LLM-based Reranker): LLM을 활용하여 직접적으로 쿼리와 패시지의 관련성을 평가하고 순서를 정렬한다.
◦
ColBERT(Embedding-based Reranker): BERT 모델을 기반으로 한 임베딩 방식으로, 각 패시지의 의미적 유사성을 비교하여 순위를 결정한다.
•
이 단계에서는 Log-Probability 기반 재랭킹을 사용하는 경우, 주어진 패시지에서 쿼리를 생성할 확률의 로그값을 계산하여, 이 값이 클수록 관련성이 높다고 평가한다.
◦
: 사용자의 쿼리
◦
: 패시지(Passage)
•
이 값()을 바탕으로 관련성이 높은 순서로 패시지를 재정렬하여 최종 프롬프트에 포함할 패시지를 선택한다.
프롬프트 생성(Prompt Creation)
•
최종적으로 선택된 패시지를 기반으로 LLM에 입력할 프롬프트를 작성한다.
•
프롬프트가 생성될 때는 다음과 같은 방식들을 사용할 수 있다.
◦
f-string을 사용하여 선택된 패시지를 적절한 순서로 배치하여 프롬프트를 구성한다.
f-string: 관련성이 높은 패시지를 앞부분에 배치하고, 덜 중요한 패시지를 뒤로 배치하여 LLM이 중요한 정보에 집중할 수 있게 하는 방식
◦
Long Context Reorder 기술을 사용하여 LLM이 중요한 정보를 더 잘 이해하도록 한다.
Long Context Reorder: LLM이 중간 정보를 잘못 인식할 수 있는 문제(‘Lost in the Middle’ 현상)를 해결하기 위해 가장 중요한 정보를 시작과 끝에 배치하여 정보 유실을 방지하는 방식
입력의 중간 정보를 잃지 않기 위해 중요한 패시지를 프롬프트의 처음과 끝에 위치시킨다.
◦
이 단계의 성능을 측정하기 위해 문맥 정밀도(Context Precision)를 사용할 수 있다.
▪
: 해당 패시지가 실제로 관련성이 있는지를 나타내는 인디케이터 값
(1이면 관련 있음, 0이면 관련 없음)
▪
: 평가할 패시지 수
18. CORAG (Cost-Constrained RAG)
CORAG란?
•
Cost-Constrained Retrieval Optimization System for RAG
•
최적의 청크(문맥 조각) 선택을 통해 RAG(Retrieval-Augmented Generation) 시스템을 개선하는 모델
•
대규모 데이터베이스에서 최적의 정보 조각을 선별하는 방식으로 성능을 높이며, 특히 다양한 쿼리 유형에 적응하고, 불필요한 정보 추가로 인한 유틸리티 감소 문제를 해결하는 데 중점을 둔다.
•
몬테카를로 트리 탐색(MCTS: Monte Carlo Tree Search)를 통해 최적의 청크 조합을 찾아내며, 비용 제약을 고려하면서도 성능을 최대 30%까지 개선할 수 있다.
목표

청크 간 상관관계 고려
•
기존의 RAG 시스템에서는 각 청크를 독립적으로 선택하거나, 특정 클러스터 내에서 청크를 모두 반환하는 방식이 주로 사용된다.
•
하지만 이러한 방식은 여러 청크 간의 상관관계를 고려하지 않거나, 청크를 동일한 중요도로 간주하여 중복성과 정보 손실이 발생할 수 있다.
•
그래서 CORAG는 몬테카를로 트리 탐색(Monte Carlo Tree Search, MCTS)을 사용하여 청크 간의 상관관계를 포괄적으로 고려함으로써, 중복이 없는 최적의 청크 조합을 찾고자 한다.
청크 유틸리티의 비단조성 문제 해결
•
대부분의 RAG 시스템은 추가되는 청크가 많을수록 유용성이 증가한다고 가정한다.
•
하지만 실제로는 지나치게 많은 청크가 오히려 정보의 품질을 저하시킬 수 있다.
•
특정 청크가 유용하더라도 과도하게 많은 정보가 포함되면 잡음이 증가하여 모델의 응답 정확도가 떨어질 수 있다.
•
CORAG는 이러한 문제를 해결하기 위해, 비용 제한을 최적화 과정에 통합하여 유틸리티의 비단조성(non-monotonicity)을 해결한다.
•
이를 통해 높은 유틸리티를 유지하면서도 불필요한 청크를 최소화할 수 있도록 한다.
다양한 질의 특성에 따른 적응성 제공
•
사용자의 질의 유형은 매우 다양하며, 각 유형에 맞춘 랭킹 전략이 필요하다.
예를 들어, 특정 질의는 사실 확인이 중요할 수 있지만, 다른 질의는 해석적 설명이 필요할 수 있다.
•
기존의 RAG 시스템은 고정된 재랭커(reranker) 모델을 사용하여 이와 같은 다양한 요구 사항을 충족하지 못하는 경우가 많다.
•
CORAG는 대조 학습 기반 구성 에이전트(configuration agent)를 통해 각 질의 유형에 맞춰 재랭커 모델과 설정을 동적으로 조정하여 RAG 시스템의 적응성을 높인다.
•
이를 통해 다양한 질의 환경에 맞춰 RAG의 성능을 최적화할 수 있다.
주요 동작

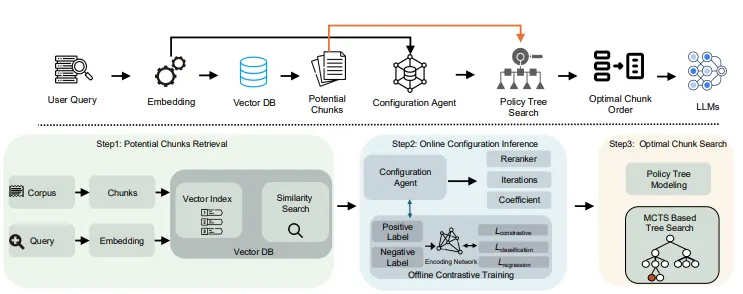
잠재 청크 검색 (Retrieve Potential Chunks)
•
사용자로부터 입력된 질의를 바탕으로 관련성이 높은 텍스트 청크들을 데이터베이스에서 선별하여 추출하는 단계
•
사용자 질의(Query)를 벡터화하여 데이터베이스에 있는 각 청크와 유사도를 비교하여 상위 K개의 잠재 청크를 선택한다.
•
질의 벡터화(Query Embedding)
◦
사용자 질의를 벡터화하여 수치화된 형태로 변환한다.
◦
주로 BERT 또는 Sentence Transformers와 같은 임베딩 모델을 사용하여 질의를 고차원 벡터로 변환한다.
•
유사도 기반 청크 검색
◦
벡터화된 질의를 기반으로 데이터베이스에 저장된 청크들과 코사인 유사도를 계산하여 가장 관련성 높은 상위 K개의 청크를 선택한다.
◦
FAISS와 같은 벡터 데이터베이스를 여기서 사용한다.
◦
이 과정에서 사용되는 코사인 유사도(Cosine Similarity)는 다음과 같은 수식으로 계산된다.
▪
: 질의 벡터
▪
: 각 청크의 벡터를 나타낸다.
▪
유사도가 높은 청크일수록 질의와 관련성이 높다고 판단된다.
MCTS을 통한 최적 청크 조합 찾기
•
앞 단계에서 추출된 잠재 청크들을 바탕으로 주어진 예산(Budget) 내에서 최적의 청크 조합을 찾는다.
•
최적의 청크 조합을 선택하는 최적화 문제
◦
주어진 비용 제한(Budget) 하에서 유틸리티가 최대가 되는 청크 조합을 찾기 위해 사용
▪
: 최적화해야 할 청크 조합 == CORAG 시스템이 최종적으로 선택하는 청크들의 집합
▪
: 청크 조합 Φ의 유틸리티 함수, 조합된 청크들이 RAG 시스템에 얼마나 유용하게 기여할 수 있는지를 수치화한 값
▪
: 유틸리티 U(Φ)가 최대가 되는 청크 조합 Φ를 찾는 것을 의미
▪
: 선택된 청크들의 총 비용이 주어진 예산 B를 초과하지 않도록 하는 제약 조건, 여기서 는 청크 의 비용을 나타낸다.
•
그래서 이 최적화 문제를 해결하기 위해 각 청크 조합의 유틸리티를 평가하고, 주어진 예산 내에서 가장 높은 유틸리티 값을 가지는 청크 조합을 탐색해야 되는데,
•
여기서는 바로 몬테카를로 트리 탐색(Monte Carlo Tree Search, MCTS) 알고리즘이 사용된다.
MCTS: 최적의 경로를 찾는 데 매우 효과적인 탐색 방법, 비용 대비 높은 유틸리티를 가진 청크 조합을 결정하는 데 중요한 역할을 한다.
지식덤프
◦
MCTS의 각 노드 의 유틸리티는 다음 수식을 통해 계산된다.
▪
: 노드 의 이익(정보의 유용성) 값, 청크가 답변 생성에 얼마나 기여할 수 있는지를 나타낸다.
▪
노드 가 탐색된 횟수, 탐색된 횟수가 적을수록 탐색의 가치가 높다고 판단한다.
▪
: 탐색과 활용의 균형을 조절하는 상수, c 값이 클수록 더 많은 탐색이 이루어지며 새로운 조합을 더 많이 탐색할 수 있도록 한다.
▪
탐색 항 (): 아직 충분히 탐색되지 않은 조합을 우선적으로 탐색할 수 있도록 유도한다.
▪
: 비용에 대한 페널티 계수, 이 값을 조정함으로써 비용 제한을 엄격하게 적용할 수 있다.
▪
비용 페널티 항 (): 주어진 예산 내에서 비용이 높아질수록 유틸리티를 감소시키며, 예산 초과를 방지한다.
◦
MCTS는 탐색을 통해 다양한 청크 조합을 시도하고, 각 시도에서 최적의 유틸리티를 찾아나가는 과정을 반복한다.
◦
이를 통해 최적의 경로가 결정되며, 이 경로에 따라 최종적으로 선택된 청크 조합이 구성된다.
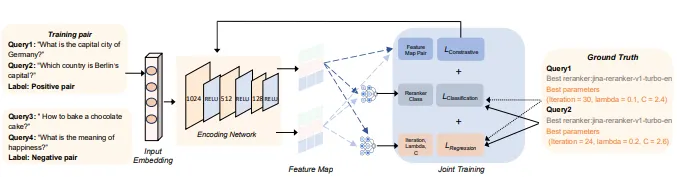
최적화 구성 예측 (Configuration Agent with Contrastive Learning)
•
CORAG의 구성 에이전트(configuration agent)가 대조 학습(contrastive learning)을 통해 사용자의 질의 유형에 맞는 최적의 설정을 예측한다.
Overview of Configuration Agent
•
구성 에이전트는 질의의 특성을 분석하여 최적의 탐색 설정 및 Re-ranking 전략을 동적으로 조정하며, 이를 통해 다양한 유형의 질의에 대해 최적의 성능을 발휘할 수 있도록 한다.
•
질의 임베딩(Embedding)
◦
구성 에이전트는 각 질의를 임베딩하여 임베딩 공간에서 유사한 질의와 그룹화한다.
◦
질의 임베딩은 BERT와 같은 임베딩 모델을 사용하여 수행된다.
•
대조 학습(Contrastive Learning)
◦
유사한 질의는 가까이 배치하고, 상이한 질의는 멀리 배치하는 방식으로 학습하여, 각 질의 유형에 맞는 최적의 설정을 공유하도록 한다.
•
다양한 설정 조정
◦
각 질의 유형에 대해 재랭킹 모델과 탐색 설정을 유동적으로 조정하여, 질의 특성에 최적화된 정보를 검색하고 응답할 수 있도록 한다.
•
구성 에이전트의 최적화를 위한 총 손실 함수는 대조 손실, 분류 손실, 회귀 손실의 세 가지 손실로 구성된다.
◦
대조 손실 ()
▪
유사한 질의는 가까이, 다른 질의는 멀리 배치하도록 하는 손실 함수
▪
이 손실을 통해 유사한 질의들이 동일한 구성 설정을 공유하도록 학습된다.
◦
분류 손실 ()
▪
최적의 재랭커를 예측하기 위한 손실 함수
▪
각 질의가 요구하는 정보의 특성에 맞춰 최적의 재랭커 모델을 선택하도록 한다.
◦
회귀 손실 ()
▪
MCTS의 탐색 설정 파라미터를 예측하여 효율적인 탐색을 가능하게 하는 손실 함수
▪
탐색 과정에서 적절한 비용 제한을 조절하여 최적의 청크 조합을 찾는 데 도움을 준다.
•
대조 학습 기반 구성 에이전트는 질의 유형에 따라 최적의 조합과 설정을 학습하며, 이를 통해 CORAG는 다양한 유형의 질의에 대한 적응성을 크게 높일 수 있다.
예를 들어, 사실 확인 중심의 질문에는 높은 정확도의 재랭커를 사용하고, 설명적 응답이 필요한 질문에는 포괄적 문맥을 제공하는 재랭커를 선택하여 최적의 정보를 검색할 수 있도록 한다.
19. EACO-RAG
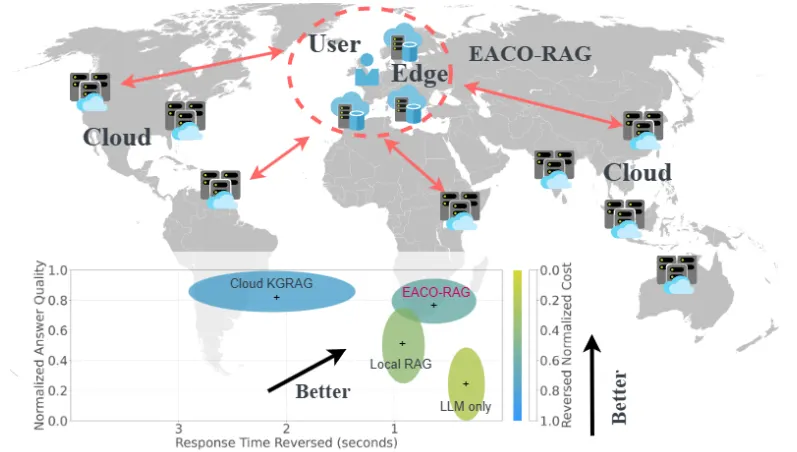
EACO-RAG란?
•
엣지 컴퓨팅을 활용하여 RAG 시스템의 응답 속도와 효율성을 높이는 모델
•
벡터 데이터를 엣지 노드에 분산 저장함으로써 지연과 자원 사용을 줄이고, 적응형 지식 업데이트 및 노드 간 협력을 통해 응답 정확도를 높인다.
•
멀티 암드 밴딧(Multi-Armed Bandit) 접근 방식을 통해 실시간으로 비용, 정확도, 지연 시간을 최적화한다.
멀티 암드 밴딧(Multi-Armed Bandit): 탐색(exploration)과 활용(exploitation) 사이의 균형을 최적화하는 문제를 해결하기 위한 알고리즘 기법
주요 과정은 다음과 같다.
•
탐색 (Exploration): 새로운 레버를 당겨보면서 보상에 대한 정보를 수집하는 단계. 여러 선택지를 시도해보면서 각각의 선택지가 어떤 보상을 줄지 파악해야 한다.
•
활용 (Exploitation): 현재까지의 정보로 보았을 때, 가장 보상이 높은 선택지를 계속 선택하는 단계.
슬롯 머신의 여러 레버(팔)를 당길 때, 각각의 레버가 다른 보상(수익)을 제공할 가능성이 있는 상황에서 최대의 보상을 얻기 위해 어떤 레버를 선택해야 하는지 결정하는 데서 유래했다.
•
이 시스템은 에지 노드 간의 협업과 적응적 지식 업데이트 메커니즘을 통해, 지리적으로 분산된 환경에서도 높은 정확도와 낮은 비용으로 실시간 응답을 제공하도록 설계되었다.
Workflow of the EACO-RAG system design
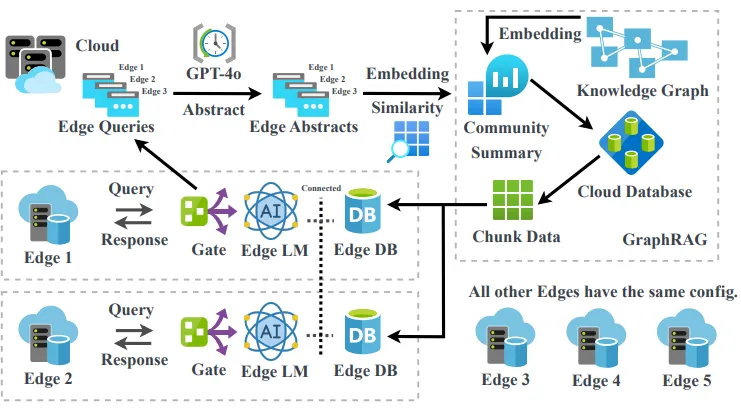
•
위 그림 처럼 사용자 쿼리는 처음에 엣지 노드의 게이트를 통과할 때 클라우드에 저장되며, 이 데이터는 엣지에서 로컬 데이터베이스를 업데이트하는 데 사용된다.
•
충분한 수의 쿼리가 수집되면 시스템은 LLM(GPT-4o 같은 모델)을 사용하여 '마법사 세계에서 주문의 이름과 기능' 또는 '퀴디치의 규칙, 역사, 주요 이벤트'와 같은 요약을 생성하여 주변 사용자가 쿼리한 공통 주제를 반영하는 초록을 생성한다.
•
그런 다음 이러한 초록은 두 데이터 세트를 모두 포함하고 유사성을 평가하여 지식 그래프에 저장된 커뮤니티 요약과 비교된다.
◦
여기서 가장 관련성이 높은 데이터 청크가 식별되어 로컬 RAG 작업을 위해 엣지로 다운로드된다.
•
엣지에서 최근 사용자 쿼리에 따라 초록이 변경되면 로컬 데이터베이스가 그에 따라 업데이트된다.
•
반면, 엣지에서 새로운 쿼리가 수신되면 시스템은 쿼리 복잡도, 네트워크 지연, 다른 엣지 데이터베이스와의 유사성을 기반으로 최적의 검색 및 생성 전략을 결정한다.
그러나 쿼리 복잡도와 다른 엣지 데이터베이스와의 유사성은 쉽게 구할 수 있는 것이 아니기 때문에 구체적으로 쿼리 복잡도는 간단한 분류기(classifier)를 사용하여 평가할 수 있으며, 다른 엣지 데이터베이스와의 유사성은 사용자 쿼리의 임베딩을 각 엣지의 요약과 비교하여 결정된다.
•
이 접근 방식은 관련 에지 노드에서 효율적인 검색을 용이하게 하고 전반적인 시스템 안정성을 향상시킨다.
안전 집합(Safe Set)
•
EACO-RAG는 안전 집합(Safe Set)을 정의하여, 주어진 문맥에서 정확도와 응답 시간 제약을 만족하는 결정을 포함하는 집합을 형성한다.
•
안전 집합은 각 문맥에서 최적화된 결정을 통해 성능을 유지하도록 한다.
◦
: 정확도 예측값
◦
: 정확도의 표준 편차
◦
: 응답 시간 예측값
◦
: 응답 시간의 표준 편차
◦
: 탐색과 활용을 균형 있게 조절하는 파라미터
•
안전 집합을 통해 시스템은 응답 정확도와 시간 요구 조건을 만족하는 최적의 경로를 선택하며, 동적으로 변화하는 환경에 대응하여 최적의 성능을 유지한다.
목표
에지 노드 활용
•
일반적인 클라우드 RAG 시스템은 클라우드 기반 데이터베이스에서 필요한 정보를 검색하여 언어 모델이 정확한 응답을 생성하도록 한다.
•
그러나, 서비스 수요가 증가함에 따라 데이터 전송 지연, 높은 자원 소비 등의 문제가 발생하며, 이는 대규모 시스템에서 확장성 문제를 초래한다.
•
EACO-RAG의 목적은 이러한 한계를 극복하고자 에지 노드를 활용하여 사용자와 가까운 곳에서 데이터를 처리한다.
•
이를 통해 EACO-RAG는 응답 지연을 줄이고 자원 소비를 최소화하며, 응답 정확도를 유지할 수 있다.
실시간 최적 경로 선택
•
응답 시간, 자원 비용, 질의 복잡성 등을 고려하여 에지와 클라우드 간 최적의 경로를 동적으로 선택함으로써 자원을 효율적으로 활용한다.
•
최적의 정보 검색 및 생성 경로를 실시간으로 선택하여 자원 소비를 최소화하며, 시스템 효율성을 높이는 것
엣지 컴퓨팅의 리소스 할당 전략
•
엣지 컴퓨팅에서 리소스 할당을 최적화하는 것은 지연, 에너지, 처리 능력의 균형을 맞추는 데 중점을 둔다.
•
작업 오프로딩 및 리소스 스케줄링과 같은 기술은 지연 시간과 에너지 소비를 최소화하는 것을 목표로 한다.
•
엣지-클라우드 협업은 엣지 노드와 클라우드 서버 간에 리소스를 동적으로 할당한다.
•
최근 AI와 강화 학습의 발전으로 이기종 엣지 환경에서의 적응성과 확장성이 향상되어 효율성과 비용 측면에서 상당한 이득을 얻을 수 있다.
•
기존의 EACO-RAG에서는 적응형 지식 업데이트(Adaptive Knowledge Update)가 포함된 엣지 지원 및 협업 RAG 엣지 컴퓨팅은 로컬 환경 내 작업 오프로딩에 중점을 둔다.
•
여기서 추가로 EACO-RAG는 노드 간 협업을 도입하여 분산된 엣지 디바이스 네트워크에서 동적 지식 공유와 리소스 할당 최적화를 가능하게 한다.
주요 동작
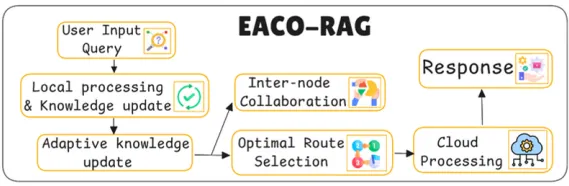
로컬 처리 및 지식 업데이트(Local Processing & Knowledge Update)
•
사용자의 질의가 입력되면, 가장 먼저 에지 노드에서 질의와 관련된 로컬 데이터베이스의 지식을 활용하여 초기 처리를 수행한다.
•
이 단계에서는 기존에 수집된 사용자 데이터와 로컬 데이터베이스에 저장된 정보를 바탕으로 질의에 맞는 응답을 준비한다.
•
적응적 지식 업데이트(Adaptive Knowledge Update)
◦
사용자 행동에 따라 에지 노드의 데이터베이스를 지속적으로 갱신하여, 반복적인 질의에 대해 신속하게 응답할 수 있도록 한다.
◦
에지 노드의 데이터베이스는 사용자의 행동 및 질의 패턴에 따라 지속적으로 업데이트된다.
◦
이를 통해 에지 노드는 특정 지역 또는 사용자 그룹에 특화된 지식을 형성하게 된다.
예를 들어, 특정 지역 또는 사용자 그룹에서 반복적으로 질의가 발생할 경우, 해당 질의에 대한 최신 정보를 로컬 데이터베이스에 추가하여, 빠르고 정확한 응답을 제공할 수 있도록 한다.
인터 노드 협업 (Inter-node Collaboration)
•
사용자의 질의가 특정 에지 노드의 로컬 데이터베이스만으로 충분히 해결되지 않는 경우, 인근의 다른 에지 노드와 협업하여 부족한 정보를 공유하고 보완한다.
•
이 과정에서 다중 노드 간 데이터 공유를 통해 각 에지 노드가 상호 보완적으로 질의 응답을 구성할 수 있다.
•
인터 노드 협업을 통해 각 노드는 데이터가 분산된 환경에서도 다른 노드에서 필요한 정보를 즉시 가져올 수 있으며, 네트워크 상황에 따라 효율적인 경로를 선택한다.
•
단독 에지 노드의 처리 한계를 보완하고, 분산된 데이터의 효율적 활용을 통해 전체 시스템의 성능을 향상시킨다.
예를 들어, 질의가 특정 지역의 문맥에 종속적일 때, 인접 에지 노드에 있는 유사한 질의를 기반으로 데이터를 얻어 응답의 정확성을 높일 수 있다.
최적 경로 선택 (Optimal Route Selection)
•
EACO-RAG는 MAB(Contextual Multi-Armed Bandit) 문제로 모델링되어 최적의 경로를 실시간으로 선택한다.
•
이는 질의의 복잡성, 네트워크 상태, 로컬 데이터와의 유사성 등을 고려하여, 에지에서 처리할지, 클라우드로 전송할지를 결정한다.
•
최적 경로 선택은 Safe Online Bayesian Optimization을 통해 수행되며, 응답 지연과 자원 비용을 최소화하면서 최적의 성능을 제공하는 경로를 동적으로 조정한다.
예를 들어, 단순한 질의는 인근의 에지 노드에서 바로 처리하고, 복잡한 질의는 클라우드로 전송하여 더 많은 자원과 데이터를 활용한다.
•
여기서 최종 비용 함수는 다음과 같이 정의된다.
◦
자원 비용 : 에지 또는 클라우드에서 데이터 검색과 모델 생성에 소모되는 비용
◦
지연 비용 : 네트워크 지연 및 모델 생성 지연으로 인한 비용
◦
가중치 : 각각 자원 비용과 지연 비용의 중요도를 조정하는 파라미터
•
최적화 문제는 다음과 같다.
◦
: 최소 정확도 요구 조건
◦
: 응답 시간이 초과하지 않도록 하는 제한
•
이 최적화는 에지와 클라우드 자원을 효율적으로 분배하여 최적의 응답 품질을 보장한다.
클라우드 처리 (Cloud Processing) & 응답 생성 (Response Generation)
•
에지 노드에서 처리할 수 없는 대규모 데이터나 복잡한 질의는 클라우드로 전송되어 강력한 중앙 집중형 모델을 통해 처리된다.
•
클라우드는 대규모 데이터베이스와 높은 컴퓨팅 자원을 활용하여 복잡한 질의에 대해 높은 정확도의 응답을 제공할 수 있다.
•
클라우드 처리 단계에서 에지에서 수집된 정보를 바탕으로 추가적인 데이터 검색과 모델 계산을 수행하여, 최적의 응답을 생성한다.
•
이후 최종 응답 생성은 게이트 메커니즘(Gate Mechanism)을 통해 이루어진다.
게이트 메커니즘(Gate Mechanism): 질의의 복잡성과 현재 네트워크 상태 등을 고려하여 에지와 클라우드 중에서 가장 적합한 모델을 선택하여 응답을 생성하는 메커니즘
20. RULE RAG
RULE RAG란?
•
RULE(Reliable Multimodal RAG for Factuality in Medical Vision Language Models)
•
의료용 다중모달 대형 비전 언어 모델(Med-LVLM)의 사실성을 강화하여 정확한 의료 정보를 제공하는 데 중점을 둔 시스템
목적
의료 정보와 같은 전문적 지식의 사실성 향상
•
기존 Med-LVLMs는 의료 영상에서 질병을 식별하고 진단 계획을 수립하는 데 있어 유용한 정보를 제공할 수 있지만, 사실과 일치하지 않는 응답을 생성하는 문제를 가지고 있다.
•
특히, RAG 전략이 외부 정보를 통합함으로써 모델의 정확성을 향상시키는 데 기여할 수 있지만, 불필요하거나 잘못된 정보를 참조할 경우 오히려 오류를 증가시킬 수 있다.
•
RULE의 목표는 RAG의 이점을 최대한 활용하면서 불필요한 참조로 인한 오류를 최소화하여 Med-LVLM의 응답이 사실에 충실하도록 하는 것이다.
•
이는 의료 분야에서 매우 중요한 문제인데 당연하게도 생명에 관련된 문제인 만큼 오류를 최소화시켜야 한다.
→ 즉, 의료 분야처럼 오류에 민감한 분야에서 큰 목적을 지니는 것으로 해석할 수도 있다고 필자는 생각한다.
과도한 참조 의존성 문제 해결
•
Med-LVLM이 자체적으로 올바른 응답을 생성할 수 있는 경우에도 외부 참조 정보가 과도하게 사용될 때 잘못된 응답으로 이어지는 문제가 자주 발생한다.
•
RULE은 모델이 본래의 지식과 외부 참조 정보 간의 균형을 유지할 수 있도록 설계되었다.
•
이를 위해 RULE은 선호 최적화 기법을 도입하여, 과도한 참조로 인한 오류가 발생하는 경우 이를 식별하고 모델의 의존도를 조정한다.
•
이로써 RULE은 모델이 불필요한 외부 참조에 의존하지 않고 자체 지식을 적극적으로 활용할 수 있도록 돕는다.
효율적인 정보 검색 및 참조 컨텍스트 수 선택
•
RULE은 영상에 대한 질문을 정확하게 이해하고 응답을 생성하기 위해 필요한 외부 참조 정보의 양을 동적으로 조정할 수 있다.
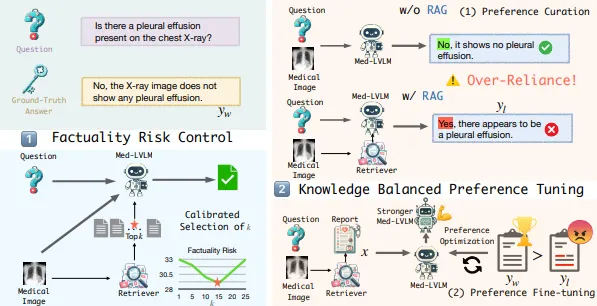
•
이를 위해 RULE은 최적의 참조 컨텍스트 수를 결정하는 사실성 위험 제어 전략(Factuality Risk Control)을 채택하고 있다.
•
이 전략은 모델이 필요한 정보만 참조하도록 하여, 불필요하거나 잘못된 정보가 포함되지 않도록 한다.
•
이를 통해 RULE은 Med-LVLM의 오류를 줄이고, 신뢰성을 높인다.
주요 동작
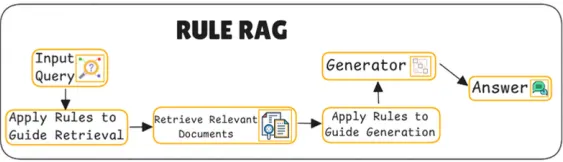
Apply Rules to Guide Retrieval & Context Retrieval
•
검색 단계에서 규칙을 적용하여 검색 프로세스를 지침하는 것
•
이 단계에서는 질의가 단순히 외부 데이터를 검색하는 것이 아니라, 사전 정의된 규칙 집합을 활용하여 검색 프로세스를 가이드한다.
•
이 규칙들은 질의의 특성에 따라 적합한 검색 방법을 결정하고, 필요한 경우 필터링을 통해 불필요한 정보를 배제함으로써 의미 있는 참조 데이터를 찾도록 한다.
예를 들어, RULE은 질의가 질병의 특정 증상과 관련된 경우, 특정 증상에 대한 텍스트 데이터를 우선적으로 검색하도록 규칙을 설정할 수 있다.
또한, 질의가 정확한 진단을 요구할 경우, 최신 의료 연구 자료나 논문 데이터를 우선적으로 참조하도록 유도할 수 있다.
•
이후 관련 문서 검색(Retrieve Relevant Document)을 수행하여 질의에 관련된 외부 데이터를 검색하고, 이를 모델의 응답 생성에 필요한 참조로 제공한다.
•
구체적으로, CLIP(Contrastive Language-Image Pretraining) 모델의 구조를 응용하여 이미지 및 텍스트 임베딩을 생성하고, 대상 의료 이미지와 가장 유사한 텍스트 설명(또는 의료 보고서)을 검색한다.
CLIP: zero-shot으로 물체를 분류(classification)하는 모델
•
이를 위해, 대조 학습(Contrastive Learning)을 통해 이미지와 텍스트 간의 유사성을 강화한다.
◦
여기선 대조 학습 손실 함수가 다음과 같이 정의 된다.
▪
: 이미지와 텍스트 간 유사성을 극대화하며, 동일한 예시의 이미지와 텍스트 임베딩 간의 거리를 최소화한다.
▪
이 수식은 이미지와 텍스트 간의 유사도를 학습하여, 서로 대응되는 예시들이 가까운 위치에 임베딩되도록 한다.
Apply Rules to Guide Generation & Generator
•
검색된 문서가 확보되면, RULE 시스템은 답변 생성을 위해 다시 한번 규칙을 적용하여 응답 생성 프로세스를 안내한다.
•
이 단계는 질의에 대한 정확한 답변을 제공하기 위해 생성 모델이 외부 참조를 사용하는 방식을 조정하는 역할을 한다.
예를 들어, RULE은 특정 상황에서 과도한 참조를 피하고자 할 때 선호 최적화 기법을 활용하여 외부 데이터에 의존하는 정도를 조정할 수 있다.
•
또한, 이 단계에서는 사실성 위험 제어(Factuality Risk Control)와 같은 기법이 사용되어, 참조 컨텍스트의 양을 동적으로 조정한다.
◦
해당 논문에서 사실성 위험(Factuality Risk)은 다음 수식으로 정의된다.
▪
: 상위 k개의 참조 컨텍스트
▪
: Med-LVLM이 제공하는 응답의 정확도
▪
이 수식은 모델이 참조할 문맥의 개수 k를 조정하여, 과도한 참조로 인해 발생할 수 있는 오류를 최소화한다.
▪
RULE은 다양한 k 값에 대해 Kullback-Leibler 발산(KL Divergence)을 계산하여 참조 위험을 분석하고, 허용 가능한 오류율 이하의 참조 개수를 결정한다.
KL Divergence: 두 확률 분포 간의 차이를 측정하는 비대칭적인 척도
KL 발산은 한 확률 분포 가 다른 확률 분포 와 얼마나 다른지를 나타내며, 정보 이론에서 한 분포를 다른 분포로 근사할 때 정보의 손실을 정량화하는 데 사용된다.
수식
•
이를 통해 과도한 정보로 인해 모델의 응답이 사실과 멀어지지 않도록 하며, 필요한 최소한의 참조만을 활용해 정확한 응답을 생성할 수 있도록 한다.
•
마지막으로 RULE 시스템은 Generator(응답 생성기)를 통해 사용자의 질의에 대한 최종 응답을 생성한다.
•
구체적으로, 선호 데이터셋(Preference Dataset)을 구축하여, 모델이 자체적으로 올바른 응답을 생성할 수 있을 때는 외부 참조에 의존하지 않도록 훈련한다.
예를 들어, 모델이 원래는 올바르게 응답했으나 과도한 참조로 인해 오류가 발생한 경우, 이러한 사례를 비선호 예시(dispreferred samples)로 분류하고, 올바른 응답을 선호 예시(preferred samples)로 지정하여 학습시킨다.
◦
이 과정에서 선호 최적화 손실 함수는 다음과 같다.
▪
: 선호 정책
▪
는 선호 응답
▪
는 비선호 응답
•
생성기는 사용자가 제공한 질의, 관련 문서 및 규칙을 기반으로 정확하고 신뢰할 수 있는 답변을 생성하는 역할을 한다.
◦
여기에서 생성된 답변은 시스템이 검색한 문서와 모델 자체의 내장된 지식을 종합하여 응답을 구성한다.
•
이 과정에서 RULE 시스템은 지식 균형 선호 최적화(Knowledge-Balanced Preference Tuning, KBPT) 기법을 통해 응답의 정확성과 신뢰성을 보장한다.
지식 균형 선호도 튜닝(KBPT) 전략
→ 즉, 생성 모델이 외부 참조와 모델 자체의 지식 간의 균형을 유지하여, 불필요한 외부 데이터에 의존하지 않도록 한다.
◦
지식 균형 선호 최적화는 Med-LVLM이 자체 지식과 외부 참조 사이의 적절한 균형을 유지하도록 돕는 중요한 역할을 한다.
◦
이 전략을 통해 RULE은 불필요한 외부 참조 의존을 줄여, 모델이 신뢰성 높은 의료 정보를 바탕으로 정확한 응답을 제공할 수 있도록 한다.
◦
이로써, RULE 시스템은 최종 사용자가 의료 영상에 대한 보다 정확하고 신뢰할 수 있는 정보를 제공받을 수 있도록 한다.
•
이를 통해 RULE은 사용자에게 더욱 신뢰성 있는 답변을 제공할 수 있으며, 외부 참조의 정확도와 모델의 내재된 지식 간의 최적화를 통해 오류를 최소화할 수 있다.
