


21. CORAL
CORAL이란?
•
Benchmarking Multi-turn Conversational Retrieval-Augmentation Generation
•
RAG 시스템을 평가하기 위해 설계된 새로운 벤치마크
•
CORAL은 다양한 대화 흐름과 데이터 처리 전략을 사용하여 복잡한 대화 시나리오를 모델링하고, RAG 시스템이 실제 응용 환경에서 발생할 수 있는 문제를 해결할 수 있는지 체계적으로 평가한다.
•
일반적인 RAG 시스템은 단일 턴 대화에서 특정 질문에 대해 신속하게 정보를 검색하고 응답을 생성하는 데 초점을 맞추지만, 현실 세계의 상호작용적인 대화에서는 여러 턴의 대화가 빈번하게 발생하고, 이에 따른 문맥을 관리하고 이해하는 능력이 필요하다.
•
CORAL은 이러한 복잡한 다중 턴 대화 환경에서 RAG 시스템이 얼마나 효과적으로 작동하는지 검증하며, 궁극적으로 정확성, 일관성, 사용자 의도 이해, 투명성을 포함한 다양한 평가 기준을 제공하여 RAG 시스템의 실용성을 강화하고자 한다
목표
다중 턴 대화의 복잡성을 처리하는 능력 평가
•
다중 턴 대화는 단순히 연속적인 질문에 대한 응답을 제공하는 것을 넘어, 이전 대화에서 발생한 문맥을 이해하고 유지하는 능력을 요구한다.
•
CORAL은 복잡한 다중 턴 대화 시나리오에서 RAG 시스템의 성능을 평가하기 위해 Wikipedia와 같은 대규모 데이터 소스를 사용하여 다중 턴 대화 흐름을 구성한다.
사용자가 "암에 대한 치료 방법은 무엇인가요?"라고 질문하고, 이어서 "그 치료 방법의 부작용은 무엇인가요?"라고 추가 질문을 던질 때, RAG 시스템은 첫 번째 질문과 두 번째 질문 사이의 문맥적 연관성을 파악하여, 부작용에 대한 정보만을 집중적으로 제공할 수 있어야 한다.
•
여기서 사용되는 게 대화 흐름 샘플링이다.
◦
CORAL은 이와 같은 복잡한 다중 턴 대화의 자연스러운 흐름을 모델링하기 위해 다양한 샘플링 전략을 도입한다.
◦
직선 하강 샘플링(Linear Descent Sampling), 형제 포함 하강 샘플링(Sibling-Inclusive Descent Sampling), 단일 트리 무작위 행보(Single-Tree Random Walk), 이중 트리 무작위 행보(Dual-Tree Random Walk) 등의 기법을 통해 다중 턴 대화에서 발생할 수 있는 다양한 흐름을 표현한다.
◦
이러한 샘플링 방법은 단순히 연관된 문서의 나열을 넘어, 자연스러운 대화의 진행 방식을 반영한다.
지식 기반 응답 생성 능력 강화
•
CORAL은 단순한 질문에 대한 사실적 응답을 넘어, 다층적이고 지식이 풍부한 응답을 생성하는 능력을 평가하고자 한다.
•
특히 복잡한 질문에 대해 자유형 응답을 생성할 수 있는 능력은 RAG 시스템의 실제 응용에 필수적이다.
•
CORAL은 RAG 시스템이 Wikipedia와 같은 방대한 정보 소스를 바탕으로, 복잡한 질문에 대해 구체적이고 풍부한 정보를 제공할 수 있는지 평가하는데, 이러한 응답 생성 능력은 단순한 정보 제공을 넘어 심층적인 설명과 관련 정보의 연결을 포함한다.
•
이를 위해 CORAL은 질문을 대화 상황에 맞게 변형하는 문맥화(Contextualization) 단계를 도입한다.
문맥화(Contextualization): 문장에 표현된 의미가 연결되어 하나의 흐름이 됨
GPT-4 같은 대형 언어 모델을 통해 단순한 질문을 더 구체적이고 맥락적인 질문으로 변환하며, 이 과정에서 생략된 정보나 암시적인 참조를 반영하여 자연스러운 대화 형식으로 질문을 재구성한다.
◦
이러한 문맥화는 RAG 시스템이 실제 대화에서의 복잡한 문맥을 반영할 수 있도록 한다.
출처 인용을 통한 응답의 투명성과 신뢰성 확보
•
정보의 출처를 명확히 제시하는 것은 RAG 시스템이 신뢰할 수 있는 응답을 제공하는 데 있어 매우 중요하다.
•
CORAL은 생성된 응답의 출처를 명확히 표시하고, 사용자가 정보의 근거를 직접 확인할 수 있도록 출처 인용(citation labeling) 기능을 필수 요소로 평가한다.
•
이는 RAG 시스템이 응답을 생성할 때 사용하는 외부 자료의 출처를 체계적으로 제시함으로써, 사용자가 제공된 정보의 신뢰도를 평가할 수 있게 한다.
•
CORAL은 생성된 응답이 참조한 문서나 데이터의 출처를 표시하여, 응답이 신뢰할 수 있는 자료에 기반하고 있음을 보장한다.
출처 인용(Citation Labeling): 출처 인용 기능은 응답 생성 과정에서 시스템이 사용한 외부 자료의 출처를 자동으로 라벨링하여, 최종 응답과 함께 출처를 제시하도록 한다.
Wikipedia의 특정 페이지나 문서의 내용을 바탕으로 응답을 생성한 경우, 해당 페이지의 링크를 포함하여 사용자가 응답의 근거를 검토할 수 있도록 한다.
주요 동작
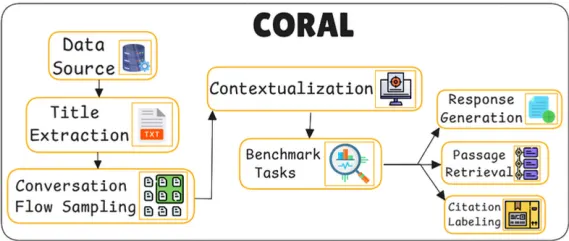
데이터셋 구성 프로세스
Overview of the CORAL dataset construction process
•
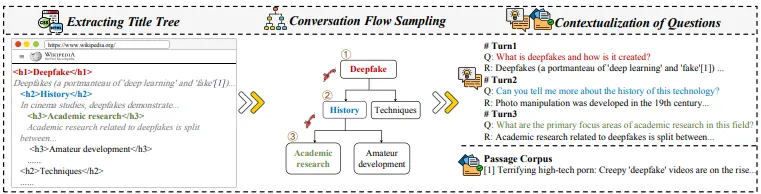
Title Extraction(Title Tree 추출)
◦
Wikipedia 문서(Data Source)의 HTML 구조에서 H1~H6 헤더를 추출하여 트리 구조(title tree)를 생성한다. 이 구조는 문서의 계층적 관계를 명확히 표현한다.
▪
루트 노드: 각 Wikipedia 페이지의 H1 헤더는 주제의 가장 상위 노드로서 대화의 주요 주제를 나타낸다.
▪
하위 노드: H2부터 H6까지의 헤더가 하위 주제 노드로 연결된다. 각 노드는 점진적으로 세부 정보로 나뉘며, 이러한 구조는 Wikipedia 페이지의 논리적 계층에 따라 생성된다.
"Deepfake" 페이지에서는 "History", "Academic Research", "Techniques"와 같은 서브 주제들이 계층적으로 나열된다.
▪
이 계층적 구조는 페이지 제목을 루트 노드로 하여 하위 섹션들을 자식 노드로 가지는 트리 형태로 표현된다.
◦
이후 본문 텍스트를 정제하여 잡음(noise)을 제거한다.
짧은 텍스트(16단어 이하)나 비영어 비율이 30% 이상인 텍스트를 제거한다.
•
이를 통해 정보의 품질과 일관성을 유지한다.
•
Conversation Flow Sampling (대화 흐름 샘플링)
◦
Title Tree에서 각 노드 사이의 연결을 기반으로 다양한 샘플링 전략을 사용하여 대화 흐름을 구성한다.
'Deepfake' 주제에 대해 첫 번째 턴에서는 "Deepfake란 무엇이며 어떻게 만들어지는가?"라는 질문으로 시작하여, 이후 역사적 배경 및 연구 주제로 점차 세부 주제를 탐구해 나간다.
◦
샘플링 전략은 네 가지가 있으며, 이는 각각 다른 대화 흐름과 맥락을 제공하기 위해 설계되었다.
1.
Linear Descent Sampling (LDS)
•
트리의 루트 노드에서 시작하여 하위 노드로 점진적으로 이동한다.
◦
각 질문 는 이전 질문의 맥락을 기반으로 한다.
•
이는 대화가 논리적으로 깊어지는 과정을 시뮬레이션한다.
기후 변화 → 기후 변화의 영향 → 인간 건강.
2.
Sibling-Inclusive Descent Sampling (SIDS)
•
형제 노드 간 이동을 허용하여 동일한 레벨에서 주제를 확장한다.
"해리 포터의 상업적 성공"에서 "문학적 비평"으로 이동.
•
동일 부모 아래 있는 형제 노드 간 이동 허용.
3.
Single-Tree Random Walk (STRW)
•
하나의 트리 내에서 무작위로 노드를 탐색하며 다양한 대화 경로를 생성한다.
•
이는 사용자가 다양한 하위 주제를 자유롭게 탐색하는 시나리오를 반영한다.
4.
Dual-Tree Random Walk (DTRW)
•
두 개의 트리 간 연결을 BM25 알고리즘으로 검색한 후, 무작위 이동 허용.
•
서로 다른 두 트리 간 전환을 허용하여 관련성이 있는 주제를 연결한다.
"알바니아의 스포츠"에서 "독일의 야구 역사"로 이동.
질문 맥락화(Contextualization of Questions)
•
샘플링된 제목을 자연스러운 대화형 질문으로 변환하여, GPT-4를 통해 실제 대화에서 발생할 수 있는 생략, 참조, 간결화 등의 현상을 반영한다.
Multi-turn의 첫 번째 턴에서는 "Deepfake란 무엇이며 어떻게 만들어지는가?"라는 질문으로 시작하고, 두 번째 턴에서는 "이 기술의 역사에 대해 더 알려줄 수 있는가?"라는 식으로 질문이 진행되며, 대화가 깊어지면서 이전 맥락을 고려한 질문들이 이어진다.
•
각 노드의 제목(Title)을 자연스러운 대화형 질문으로 변환한다.
•
함수는 자연스러운 언어 표현을 생성하도록 위 GPT-4와 같이 훈련된 모델을 사용한다.
•
질문 변환은 다음과 같은 수식으로 표현된다.
◦
: 현재 노드의 제목.
◦
: 이전 대화의 히스토리.
대화형 검색-증강 생성(RAG) 시스템
•
사용자의 현재 질문과 대화 히스토리를 기반으로 문서에서 관련 정보를 검색하는 과정
1.
검색 과정
•
검색 모델 은 대화 히스토리와 질문을 입력받아 패시지 집합 를 반환한다.
◦
여기서 은 BM25, KD-ANCE 등의 검색 알고리즘이 될 수 있다.
2.
검색 성능 평가
•
검색 성능을 평가할 때는 MRR과 NDCG@k 등을 사용한다.
◦
MRR: 사용자가 검색 결과에서 첫 번째 관련 패시지를 얼마나 빨리 찾을 수 있는지를 나타낸다.
▪
: 번째 질문의 관련 패시지 순위
◦
NDCG@k: NDCG는 검색 결과의 관련성에 따라 가중치를 부여하며, 검색 결과 품질을 측정한다.
▪
: 번째 문서의 관련성 점수
•
대화 히스토리 압축
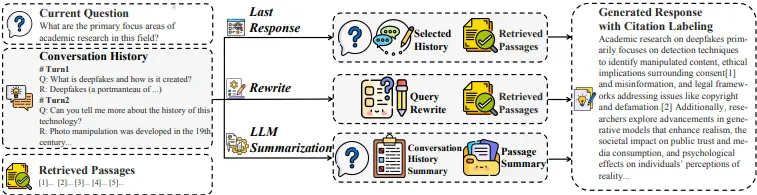
Overview of three conversation compression strategies
◦
이 압축은 검색기와 생성기에 전달되는 입력 데이터를 줄여 성능 저하를 방지하며, 각각의 전략은 다중 턴 대화 맥락에서 발생할 수 있는 다양한 상황을 처리하기 위해 설계되었다. 각 전략은 다음과 같은 방식으로 작동한다.
◦
대화 히스토리가 길어질 경우, 검색 및 생성 성능이 저하될 수 있으므로 입력 데이터를 압축하여 이를 개선한다.
◦
주요 전략
1.
Last Response Strategy
•
이 전략에서는 대화 히스토리 중 이전의 모든 질문과 마지막 응답만을 포함하여 압축된 히스토리를 구성한다.
•
이전의 전체 대화 맥락을 요약하는 간단한 방식, 마지막 응답이 주어진 질문에 대한 최신 정보를 제공하는 경우 특히 유용하다.
◦
: 이전 모든 질문
◦
: 마지막 응답
•
장점
◦
대화의 흐름을 간결하게 유지하면서도 주요 질문과 마지막 응답을 포함하여 의미를 보존한다.
◦
불필요한 세부 정보를 제거해 검색 및 생성 과정에서 효율성을 높인다.
•
단점
◦
이전 질문에 대한 깊이 있는 맥락을 모두 포함하지 않으므로, 일부 정보가 손실될 수 있다.
2.
Rewrite Strategy
•
이 전략에서는 현재 질문과 대화 히스토리를 기반으로 질문을 독립적이고 완전한 형태로 재작성한다.
→ 대화 히스토리와 현재 질문을 독립적인 질문으로 재작성한다.
•
해당 방식은 질문을 대화의 연속선상에서 벗어나 하나의 독립적인 질문으로 표현함으로써, 검색 시스템이 질문을 처리하기 용이하게 한다.
•
: 현재 질문과 대화 히스토리를 기반으로 독립적 질문를 생성하는 함수
•
장점
◦
질문을 독립적으로 재구성하여 검색기에 전달함으로써 검색 정확도를 높일 수 있다.
◦
검색기 모델이 맥락에 의존하지 않고 질문을 처리하도록 돕는다.
•
단점
◦
질문이 재작성됨에 따라 원래 대화 맥락의 일부가 손실될 수 있다.
◦
맥락을 반영한 응답이 필요한 경우에는 제한적일 수 있다.
3.
LLM Summarization Strategy
•
대화 히스토리를 대규모 언어 모델(GPT, Llama 등)을 사용하여 요약한다.
•
이 요약은 대화의 전체 흐름을 압축하여 필요한 정보만을 간결하게 전달한다.
•
LLM은 대화 기록을 이해하고 중요한 부분을 추출하여 요약본을 생성하는 역할을 한다.
◦
LLM(Hk)는 대화 히스토리 를 입력으로 받아 요약된 대화 히스토리를 출력
•
장점
◦
대화가 매우 길어질 경우 중요한 정보만을 요약하여 전달하므로 효율적이다.
◦
대규모 언어 모델의 능력을 활용하여 중요한 정보를 자동으로 추출할 수 있다.
•
단점
◦
LLM의 요약 결과가 불완전할 수 있으며, 중요한 세부 정보가 누락될 수 있다.
◦
모델을 활용하는 데 비용이 많이 들 수 있다.
22. ReSP - Iterative RAG
ReSP(Retrieve, Summarize, Plan)란?
•
멀티-홉 질문 응답(Multi-hop Question Answering) 문제를 해결하는 데 주안점을 둔다.
•
기존의 RAG 접근 방식은 한 번의 검색으로 모든 필요한 정보를 얻으려 하지만, 단일 검색으로는 충분한 정보를 얻기 어려워 반복적인 검색(iterative retrieval)이 필요하게 된다.
•
그러나, 기존의 반복적 RAG 방식은 두 가지 문제를 갖는다.
1.
문맥 과부하: 여러 번의 검색 결과가 축적되면서 맥락이 길어지고, 모델이 불필요한 정보까지 포함하게 되어 중요한 정보를 놓칠 수 있다.
2.
과도한 계획 및 중복 계획 문제: 검색 경로가 기록되지 않기 때문에 동일한 질문이나 하위 질문에 대한 계획이 반복될 수 있다.
•
이를 해결하기 위해, ReSP에서는 반복적 RAG 프로세스에서 이중 기능 요약기(dual-function summarizer)를 도입하여 정보를 효율적으로 요약하고 관리함으로써, 맥락 과부하와 중복 계획 문제를 해결한다.
목표
멀티-홉 질문 응답의 정확성 향상
•
다단계로 연결된 정보를 기반으로 정확한 답변을 도출하는 것
•
멀티-홉 질문 응답에서는 단일한 정보 소스가 아닌, 여러 소스에서 정보를 종합해 답변을 구성해야 하므로 정확한 정보 검색이 중요하다.
•
단일 검색의 한계 극복
◦
기존 RAG 시스템은 단일 검색으로 필요한 모든 정보를 얻으려 하지만, 멀티-홉 질문 응답에서는 한 번의 검색으로 충분한 정보를 얻기 어려울 때가 많다.
질문이 여러 주제를 포함하거나 연관된 문서들이 다양한 경우, 반복적인 검색이 필수적이다.
◦
ReSP는 검색을 반복하면서 필요한 정보를 단계별로 추가 확보하여, 단일 검색 방식의 한계를 보완한다.
•
다중 문서 종합 능력 강화
◦
멀티-홉 질문 응답에서는 서로 다른 문서에서 얻은 정보를 통합하는 능력이 요구된다.
특정 인물의 생애와 업적에 관한 정보가 여러 문서에 분산되어 있다면, 이를 종합해 하나의 일관된 응답을 생성해야 한다.
◦
ReSP는 이중 기능 요약기를 사용하여, 다중 문서에서 얻은 정보를 효과적으로 요약하고 종합해 높은 정확도를 달성한다.
•
반복적인 정보 갱신
◦
ReSP는 매 반복마다 새로운 정보를 축적하고, 이전 반복에서 놓친 정보를 추가적으로 검색하여 정확성을 높인다.
→ 특히 초기 검색에서 충분한 답변을 얻지 못했을 때, 다음 반복을 통해 정보를 보완할 수 있도록 한다.
◦
ReSP는 이걸 사용하여 정보를 갱신하며 정답에 필요한 모든 세부 정보를 종합할 수 있게 된다.
문맥 과부하 문제 해결
•
멀티-홉 질문 응답에서 자주 발생하는 문맥 과부하(context overload) 문제를 해결하는 것
•
다중 검색 결과가 누적되면, 모델이 중요하지 않은 정보까지 포함해 응답의 품질이 떨어질 수 있다.
•
요약을 통해 정보 축적을 효율화시킨다.
◦
ReSP는 이중 기능 요약기를 통해 검색된 정보를 요약하여 필요한 부분만 메모리에 축적한다.
◦
이렇게 함으로써 전체 검색 내용 중 중요한 정보만 남겨, 모델이 더 효율적으로 맥락을 처리할 수 있다.
◦
이 과정에서 Global Evidence Memory와 Local Pathway Memory로 나누어 정보를 요약해 저장하므로, 필요한 정보가 적절하게 축적되고 불필요한 내용은 배제된다.
•
요약 과정을 통해 불필요한 잡음(noise)을 제거한다.
◦
여러 번의 검색 반복으로 문맥이 길어지면, 잡음이 포함될 가능성이 높아진다.
◦
ReSP는 요약 과정을 통해 잡음을 제거하여, 모델이 필요한 핵심 정보에만 집중하도록 만든다.
•
검색 메모리를 최적화한다.
◦
반복적인 검색 결과를 저장할 때, 모든 내용을 메모리에 저장하는 것은 비효율적이다.
◦
ReSP는 요약된 정보만 메모리에 저장하고, 필요한 부분만 선택적으로 불러와 메모리 사용을 최적화한다.
→ 시스템의 메모리 부담을 줄이며, 긴 대화나 대규모 문서 검색에서도 효율성을 보장할 수 있게 한다.
과도한 계획 및 중복 계획 문제 해결
•
과도한 계획(over-planning) 및 중복 계획(repetitive planning) 문제를 해결하는 것
•
정보에 기반하여 검색 경로 추적을 통한 중복 검색을 방지한다.
◦
ReSP는 이전에 검색한 하위 질문과 경로를 Local Pathway Memory에 기록하여, 이미 검색한 질문을 중복하여 검색하지 않도록 한다.
→ 동일한 질문에 대한 반복 검색을 방지해 검색 효율성을 높인다.
◦
이를 통해 시스템은 이미 확보한 정보에 기반하여 새로운 질문을 생성할 수 있어, 불필요한 반복을 줄이고 효율성을 높인다.
•
메모리를 이용한 효율적 계획 관리 전략
◦
ReSP는 Global Evidence Memory와 Local Pathway Memory에 정보를 나누어 기록하여, 전체 질문과 하위 질문에 대한 계획을 효율적으로 관리한다.
→ 모델이 각 검색 단계에서 어떤 정보가 충분히 수집되었는지 파악하는 데 도움이 된다.
◦
이러한 구조 덕분에, 시스템은 이미 해결된 하위 질문에 대한 재계획을 피하고 새로운 하위 질문으로 효율적으로 전환할 수 있다.
•
불필요한 검색을 방지하여 반복적인 검색 시간을 절약한다.
◦
중복 계획이 반복되면, 시스템은 불필요한 검색을 수행하느라 시간이 낭비된다.
◦
ReSP는 중복 계획을 방지함으로써 검색 시간을 줄이고, 시스템이 빠르게 새로운 정보를 얻어 최종 답변을 생성할 수 있도록 돕는다.
◦
이로 인해 ReSP는 반복적인 검색 과정에서도 효율적으로 작동하며, 응답 시간을 단축시킬 수 있다.
주요 동작
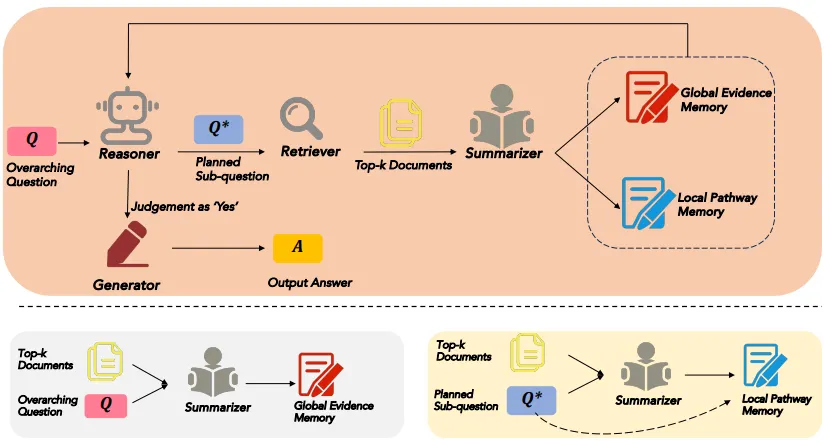
ReSP framework
Reasoner를 통한 하위 질문 생성
•
사용자가 제시한 Overarching Question 을 Reasoner가 받아들인다.
•
Reasoner는 현재까지 축적된 정보를 바탕으로 가 해결되지 않았다면, 이 질문을 해결하기 위해 필요한 하위 질문 을 생성한다.
•
이 하위 질문은 최종 답변에 필요한 정보를 특정하기 위해 설계되었으며, 반복적으로 Retriever에게 전달되어 새로운 정보를 얻는 데 사용된다.
Retriever를 통한 문서 검색
•
생성된 하위 질문 을 입력으로, Retriever는 문서 집합 에서 가장 관련성이 높은 문서 개를 검색한다.
◦
: 검색된 개의 상위 관련 문서들
◦
: 하위 질문
◦
: 전체 문서 집합
•
검색된 문서들은 ReSP 시스템의 Summarizer로 전달되어 요약되고 축적된다.
Summarizer를 통한 정보 요약 및 메모리 저장
•
Summarizer는 검색된 문서를 요약하여 두 가지 메모리(Global Evidence Memory와 Local Pathway Memory)에 저장한다.
◦
Global Evidence Memory: 전체 질문을 해결하기 위해 필요한 주요 정보를 요약하여 누적한다.
◦
Local Pathway Memory: 하위 질문을 해결하기 위해 필요한 정보를 요약하여 저장한다.
•
이 과정에서 Global Evidence Memory는 지속적으로 업데이트되며, Local Pathway Memory는 각 하위 질문에 대한 정보가 갱신된다.
•
이로써 ReSP는 정보의 중복 저장을 줄이고 필요한 정보만 남겨놓아 메모리 사용을 최적화한다.
Reasoner의 판단 및 반복
•
Reasoner는 Global Evidence Memory와 Local Pathway Memory에 저장된 정보를 평가하여, 최종 답변 생성이 가능한지 판단한다.
•
만약 정보가 충분하다고 판단되면, Generator에 "Yes" 신호를 보내 최종 답변을 생성하도록 한다.
•
그렇지 않은 경우, Reasoner는 새로운 하위 질문을 생성하고 다시 Retriever에 전달한다.
Generator를 통한 최종 답변 생성
•
충분한 정보가 축적되었다고 판단되면, Generator가 최종 답변 를 생성한다.
•
Generator는 Global Evidence Memory와 Local Pathway Memory에 저장된 정보를 종합하여 응답을 도출한다.
23. ConTReGen
ConTReGen이란?
•
Context-driven Tree-structured Retrieval for Open-domain Long-form Text Generation
•
복잡하고 개방형인 멀티-홉 질문 응답 작업에서 높은 성능과 정확도를 목표로 설계된 프레임워크
•
주요 특징은 컨텍스트 트리 기반의 검색 및 생성 구조를 사용하여 각 질문의 다양한 측면을 깊이 있게 탐구하고, 상향식 통합을 통해 응답을 구성한다는 점이다.
•
이 접근 방식은 쿼리를 계층적인 하위 쿼리로 분해하여 검색 깊이를 높이고, 그런 다음 통합된 요약 정보를 바탕으로 일관성 있는 장문 응답을 생성하는 데 있다.
•
ConTReGen은 Top-Down Planning and Retrieval 단계와 Bottom-Up Synthesis and Generation 단계로 구성된다. 각 단계를 통해 정보를 체계적으로 검색하고, 응답을 통합하여 정확하고 풍부한 정보를 포함한 답변을 생성한다.
목표
개방형 도메인에서의 장문 생성 정확성 향상
•
개방형 도메인에서 사용자가 요청하는 복잡한 질문에 대해 긴 형태의 정확한 응답을 제공하는 것
•
이를 위해서는 다양한 정보 소스 통합 필요하다.
◦
개방형 도메인의 질문은 특정한 정보뿐만 아니라, 다양한 출처의 정보를 종합적으로 고려해야 한다.
예를 들어, 특정 주제에 대해 다양한 관점이나 세부 정보를 통합하는 작업이 필요하다.
◦
ConTReGen은 트리 구조의 검색을 통해 다양한 정보를 통합할 수 있게 설계되어 있어, 하나의 응답에 여러 출처에서의 정보를 포함할 수 있다.
•
단계별 정리를 통해 장문 응답의 일관성을 유지한다.
◦
개방형 질문의 경우 사용자가 명확하고 일관된 장문 응답을 기대한다.
→ 이는 서로 다른 출처에서 수집된 정보가 충돌하지 않고 통합되어야 함을 의미
◦
ConTReGen의 하향식 계획과 상향식 통합 과정은 정보가 단계별로 정리되어 최종 응답이 일관성을 유지할 수 있게 한다.
•
복잡한 질문의 세부적 처리를 다룬다.
◦
사용자의 질문이 다층적이고 복잡할 경우, 단순한 검색으로는 충분한 정보를 수집할 수 없다.
◦
복잡한 질문을 작은 하위 질문으로 나누어 처리해야 정보가 누락되지 않는다.
◦
ConTReGen은 질문을 하위 질문으로 분해하고 각 하위 질문을 체계적으로 처리하여 복잡한 질문의 다양한 측면을 세부적으로 다룬다.
정보 검색의 깊이와 관련성 향상
•
개방형 질문의 여러 측면을 탐색할 때 정보 검색의 깊이와 관련성을 높이고자 한다.
•
다양한 측면 탐색의 필요성
◦
복잡한 질문에는 여러 측면이 존재할 수 있으며, 이러한 측면 각각에 대해 적절한 정보가 필요하다.
예를 들어, "How to Detect Hidden Cameras and Microphones"라는 질문은 물리적 탐색, 전자 신호 검색 등 여러 세부 주제를 포함할 수 있다.
◦
ConTReGen의 트리 구조 검색 방식은 질문을 여러 세부 주제로 분할하여 각 주제를 깊이 탐색함으로써 포괄적인 답변 생성을 가능하게 한다.
•
서로 다른 출처에서 정보 수집
◦
특정 측면을 해결하기 위해서는 다양한 출처의 정보가 필요할 수 있으며, 이러한 정보가 체계적으로 통합되어야 한다.
◦
ConTReGen은 각 하위 질문별로 연관된 문서를 찾아 통합함으로써, 여러 출처에서 얻은 정보를 적절하게 결합한다. 이를 통해 관련성 높은 정보가 수집된다.
•
적절한 하위 질문 생성
◦
질문을 적절히 분해하지 못하면 일부 중요한 정보가 누락될 수 있다.
◦
그래서 여기선 하위 질문을 체계적으로 생성하고 검증하는 과정을 통해, 모든 측면을 완전히 탐색할 수 있도록 하여 정보 수집의 효율성을 극대화한다.
생성된 응답의 문맥적 풍부함과 일관성 보장
•
트리 구조를 통한 정보의 체계적 통합:
◦
트리 구조의 검색과 통합은 문맥을 유지하면서 정보가 논리적으로 결합될 수 있게 한다.
◦
하위 질문들을 통해 얻은 정보가 트리 구조의 하위 노드에서 상위 노드로 통합되면서 응답의 문맥적 일관성을 높일 수 있다.
◦
ConTReGen의 상향식 통합 과정은 각 하위 질문의 정보를 정리해 일관된 응답을 생성하게 해준다.
•
불필요한 정보 필터링:
◦
긴 응답 생성 과정에서 불필요한 정보는 문맥적 풍부함을 방해할 수 있다.
◦
하위 질문별로 핵심 정보를 요약하고, 덜 중요한 세부사항은 필터링하여 최종 응답이 집중도와 일관성을 유지할 수 있도록 한다.
◦
이를 통해 사용자가 질문한 내용에 맞춘 구체적이고 관련성 높은 정보를 전달할 수 있다.
•
정보 축적 및 상향식 통합:
◦
각 하위 질문의 답변은 더 큰 질문을 해결하기 위한 부분적인 요소들로, 상위 노드에서 단계적으로 통합된다.
◦
이렇게 축적된 정보는 문맥적 풍부함을 더하며, 일관성 있는 최종 응답으로 이어진다.
◦
이러한 상향식 접근을 통해 정보가 점진적으로 결합되면서 응답의 질을 높인다.
주요 동작
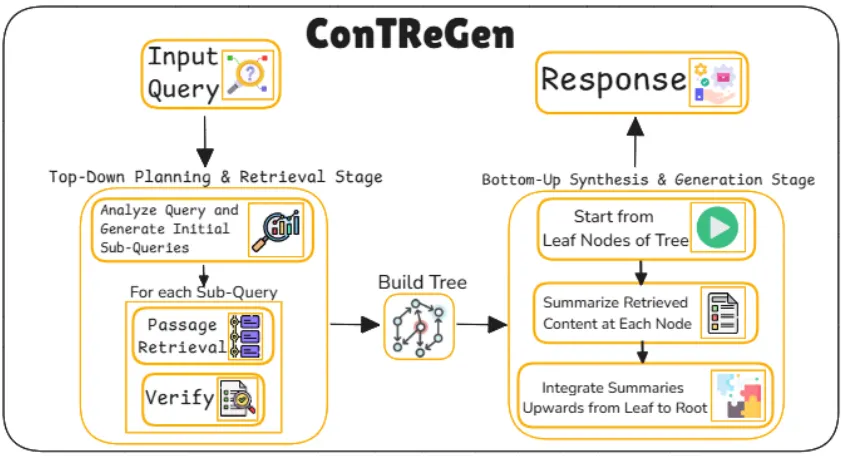
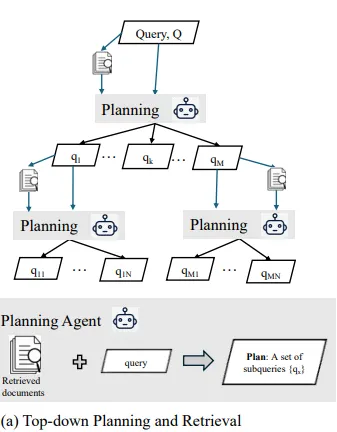
Top-Down Planning and Retrieval
•
사용자가 제시한 복잡한 질문을 여러 하위 질문(sub-query)으로 분해하여 각 질문의 다양한 측면을 심층적으로 탐구하는 단계
→ 이를 통해 모든 관련 정보를 폭넓게 탐색하고자 한다.
•
초기 질문 분석 및 하위 질문 생성(Analyze Query and Generate Initial Sub-Queries)
◦
질문 분석 및 분해
▪
사용자가 입력한 복잡한 질문 는 다양한 측면에서 접근해야 하는 주제를 포함할 수 있다.
▪
이를 위해, ConTReGen은 를 여러 개의 하위 질문 으로 분해한다.
▪
ConTReGen의 Planning Agent는 원 질문 Q를 질문 분해 함수 를 통해 하위 질문 집합으로 분해한다.
•
함수: 사용자가 입력한 질문 를 다양한 주제로 나누어 각 하위 질문이 독립적으로 검색 가능하게 한다.
▪
질문 분석은 하위 질문들이 원 질문을 해결하는 데 필요한 모든 주요 측면을 다루도록 도와준다.
•
패시지 검색 및 검증 (Passage Retrieval and Verification)
◦
각 하위 질문에 대해 필요한 정보를 검색하고, 검색된 정보가 유효한지를 검증하는 단계

◦
각 하위 질문 에 대해 관련 패시지들을 검색하는 패시지 검색 단계에선 다음과 같이 동작한다.
▪
: 하위 질문 qi에 대해 검색된 상위 k개의 패시지 집합
▪
: 전체 문서 말뭉치(corpus)
▪
: 검색할 패시지의 개수
◦
검증 프로세스
▪
검색된 패시지가 원 질문 와 관련성이 있는지를 검증하는 단계, 자기 검증(Self-Verification)과 검색 검증(Retrieval Verification)을 포함한다.
▪
각 패시지 (질문 에 대한 검색 결과 중 하나)에 대해 검증 과정을 거친 후, 최종적으로 유효한 하위 질문과 패시지 집합 을 결정한다.
•
: 패시지 가 원 질문 에 유의미한 정보를 제공하는지를 판단하는 검증 함수
•
트리 구조 생성 및 재귀적 탐색
◦
트리 구조 생성
▪
ConTReGen은 하위 질문들을 트리 구조로 정리하며, 각 하위 질문 와 해당 검색 결과 가 트리의 노드와 연결된다.
▪
이 트리 구조에서 루트 노드는 원 질문 이고, 각 하위 질문은 이를 보완하는 정보로 구성된 하위 노드가 된다.
◦
재귀적 탐색과 추가 하위 질문 생성
▪
각 하위 질문에 대해 필요시 추가적인 하위 질문을 생성하고 이를 트리의 하위 노드로 연결한다.
▪
질문의 깊이를 확장하면서 새로운 하위 질문을 생성하는 과정은 다음과 같은 재귀적 수식으로 표현된다.
•
여기서 함수는 하위 질문 가 더 세부적인 하위 질문들 으로 분해하는 역할을 한다.
Bottom-Up Synthesis and Generation
•
트리 구조의 리프 노드에서부터 정보를 상향식으로 통합하여 최종 응답을 생성하는 것
•
각 노드의 정보를 요약하고 통합하는 과정이다.
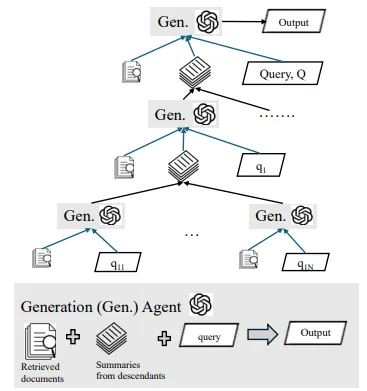
•
리프 노드에서의 요약 및 통합
◦
리프 노드
▪
각 리프 노드에 대해 요약 함수를 사용하여 검색된 정보를 간략하게 정리한다.
•
: 리프 노드 에 대해, 요약된 정보
•
: 리프 노드의 검증된 패시지 집합 을 요약하여 주요 정보를 추출하는 요약 함수
◦
상향식 통합 수식
▪
리프 노드에서부터 상위 노드로 요약된 정보를 통합한다.
▪
하위 노드들의 요약 정보 들을 상위 노드 에 결합하는 방식 표현법
•
: 여러 하위 노드들의 요약을 하나의 응답으로 통합하는 역할
•
중간 노드 통합 및 최종 응답 생성
◦
중간 노드 통합
▪
중간 노드에서는 하위 노드들의 요약 정보를 추가적으로 통합하여 포괄적인 응답을 형성한다.
▪
중간 노드 에 대해 하위 노드들의 통합은 다음과 같이 수식화된다.
◦
최종 응답 생성 수식
▪
최종적으로 루트 노드에서 모든 통합된 요약 정보를 바탕으로 최종 응답 A가 생성된다.
•
: 모든 하위 정보가 상향식으로 통합된 결과
•
: 를 사용하여 최종 응답을 생성
24. CRAT
CRAT이란?
•
LLM(대형 언어 모델) 기반 번역에서 문맥 의존적인 용어나 도메인 특정 용어의 번역 문제를 해결하기 위해 개발된 다중 에이전트 프레임워크
•
특히, LLM 기반 번역에서 발생하는 문맥 의존적 문제 해결 및 번역의 정확성과 일관성을 향상시키기 위해 RAG과 인과성 기반 자기 반영(causality-enhanced self-reflection)을 결합하였다.
•
CRAT는 BLEU, COMET, CONSIS 등의 지표를 통해 기존 번역 모델보다 높은 정확성과 일관성을 보였으며, 특히 복잡한 문맥에서 효과적이었다.
•
실험 결과, GPT-4o와 Qwen-72B-Instruct 모델에서 성능이 크게 향상된 것이 확인되었다.
•
결론적으로 CRAT는 특히 문맥 의존적이고 도메인 특화된 용어 처리에 강점을 보인다. 다만 외부 지식 의존성과 계산 비용 측면에서 일부 한계를 가진다.
한계
•
외부 데이터가 부정확하거나 최신 상태가 아닐 경우 번역 오류가 발생할 수 있다.
•
다중 에이전트 구조로 인해 실시간 번역에서는 높은 계산 복잡도를 가지며 성능 저하가 발생할 수 있다.
•
방언이나 문화적 특수성을 지닌 용어 처리에서 한계가 있을 수 있다.
목표
문맥 의존적 용어 번역의 정확성 향상
•
다의어, 신조어, 도메인 특화 용어와 같이 문맥에 따라 의미가 달라질 수 있는 용어들을 정확하게 번역하는 것
•
번역 작업에서 특정 용어는 문맥에 따라 여러 가지 의미를 가질 수 있으며, LLM은 문맥을 충분히 고려하지 않을 경우 이러한 용어들을 잘못 번역할 가능성이 있다.
"bank"라는 단어는 문맥에 따라 금융기관이 될 수도 있고, 강둑을 의미할 수도 있다.
•
CRAT는 이러한 문제를 해결하기 위해 다음과 같은 방식으로 접근한다.
◦
미지 용어 자동 식별
▪
CRAT는 번역 과정에서 신뢰도가 낮은 용어(다의어, 약어, 고유명사 등)를 자동으로 식별하는 Unknown Terms Detector를 갖추고 있다.
→ 문맥에 따라 의미가 달라질 수 있는 용어를 미리 감지하여 별도로 처리할 수 있게 된다.
▪
이 과정은 LLM의 한계를 보완하여, 단순히 단어를 그대로 번역하는 대신 문맥에 맞게 용어를 정확히 해석할 수 있도록 한다.
◦
내부 및 외부 지식을 활용한 의미 명확화
▪
CRAT는 용어의 의미를 명확히 하기 위해 소스 텍스트에서 추출한 내부 지식과, 외부 데이터베이스에서 수집한 외부 지식을 결합하여 Translation Knowledge Graph(TransKG)를 생성한다.
TransKG는 각 용어의 문맥적 의미를 체계적으로 정리하여 번역 과정에 참조할 수 있게 하며, 특히 다의어 또는 도메인 특화 용어가 포함된 문장에서 적절한 의미를 선택하는 데 중요한 역할을 한다.
"Scotia"가 금융기관(Scotiabank)인지, 지리적 장소(Scotia Sea)인지 구분하여 올바른 번역을 생성할 수 있도록 도와준다.
◦
인과성 강화 판별을 통한 정보 검증
▪
CRAT는 번역 과정에서 수집된 정보가 문맥적으로 적합한지를 평가하기 위해 인과성 반영(causality reflection) 메커니즘을 도입했다.
Causality-Enhanced Judge 에이전트는 수집된 정보의 인과적 연관성을 검토하여, 문맥에 부적합한 정보를 배제하거나 수정한다.
▪
이 검증 과정은 단어가 문맥에 따라 올바른 의미로 해석되었는지를 판단하여 번역의 신뢰성을 높인다.
▪
특히, 다의어와 같이 여러 의미를 가진 단어의 경우 이 과정을 통해 문맥에 맞는 의미가 선택되도록 보장한다.
•
위를 보고 알 수 있듯이 CRAT은 단순히 용어를 대체하는 것이 아니라, 문맥을 반영하여 번역의 의미적 정확성을 높이도록 설계되었다.
다중 에이전트 협력
•
CRAT의 각 에이전트는 번역 과정에서 정보를 공유하고 협력하여 번역의 일관성을 보장한다.
•
이 다중 에이전트 구조는 번역의 각 단계가 상호 연계되어 일관성을 유지할 수 있게 하며, LLM의 번역 정확도를 높이는 데 필수적인 역할을 한다.
•
에이전트(Agent) 종류
◦
Causality-Enhanced Judge 에이전트는 Unknown Terms Detector 에이전트와 협력하여 문맥에 맞는 의미를 확인하는 과정을 거친다.
▪
확인한 결과를 Translator 에이전트에 전달하여 일관된 번역이 생성되도록 한다.
→ 번역 과정에서 발생할 수 있는 오류를 자동으로 검토하고 수정함으로써, 사용자가 별도로 오류를 검토하지 않아도 번역의 정확성을 보장한다.
◦
Unknown Terms Detector 에이전트는 번역 문맥에서 신뢰도가 낮은 용어를 자동으로 탐지하고 이를 처리한다.
다의어나 신조어, 특정 도메인 용어 등 번역이 까다로운 용어들을 자동으로 인식하여 이후 단계에서 적절히 처리할 수 있도록 한다.
→ 번역자가 번역 중에 잠재적 오류를 발견하고 수정하는 시간을 줄여주며, 번역 과정에서 발생할 수 있는 오역 가능성을 사전에 줄여준다.
◦
Knowledge Graph Constructor 에이전트는 외부 지식과 내부 지식을 결합하여 자동으로 TransKG를 생성한다.
▪
TransKG는 위에서 설명했듯이 번역에 필요한 문맥 정보를 체계적으로 정리하여, 자동으로 번역 과정에 반영되도록 돕는다.
→ 번역자가 개별 용어의 의미를 일일이 확인할 필요 없이, 관련 지식을 번역 문맥에 바로 활용할 수 있도록 하며, 번역 과정의 효율성을 크게 향상시킨다.
주요 동작
•
CRAT에서 각 동작은 Agent로 작동하게 된다.
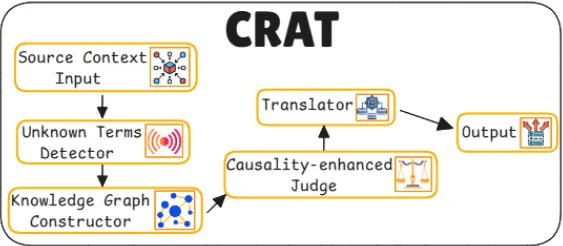
•
전체적으로 CRAT 시스템의 번역 작업은 다음과 같이 수식으로 요약할 수 있다.
◦
: 내부 지식을 소스 문맥으로부터 추출할 확률
◦
: 외부 지식을 소스 문맥으로부터 추출할 확률
◦
: 내부 및 외부 지식을 기반으로 최종 번역 를 생성할 확률
미지 용어 탐지기(Unknown Terms Detector) Agent
•
번역에서 잠재적으로 번역이 어려운 낮은 신뢰도 용어(다의어, 약어, 신조어 등)를 자동으로 탐지하는 역할
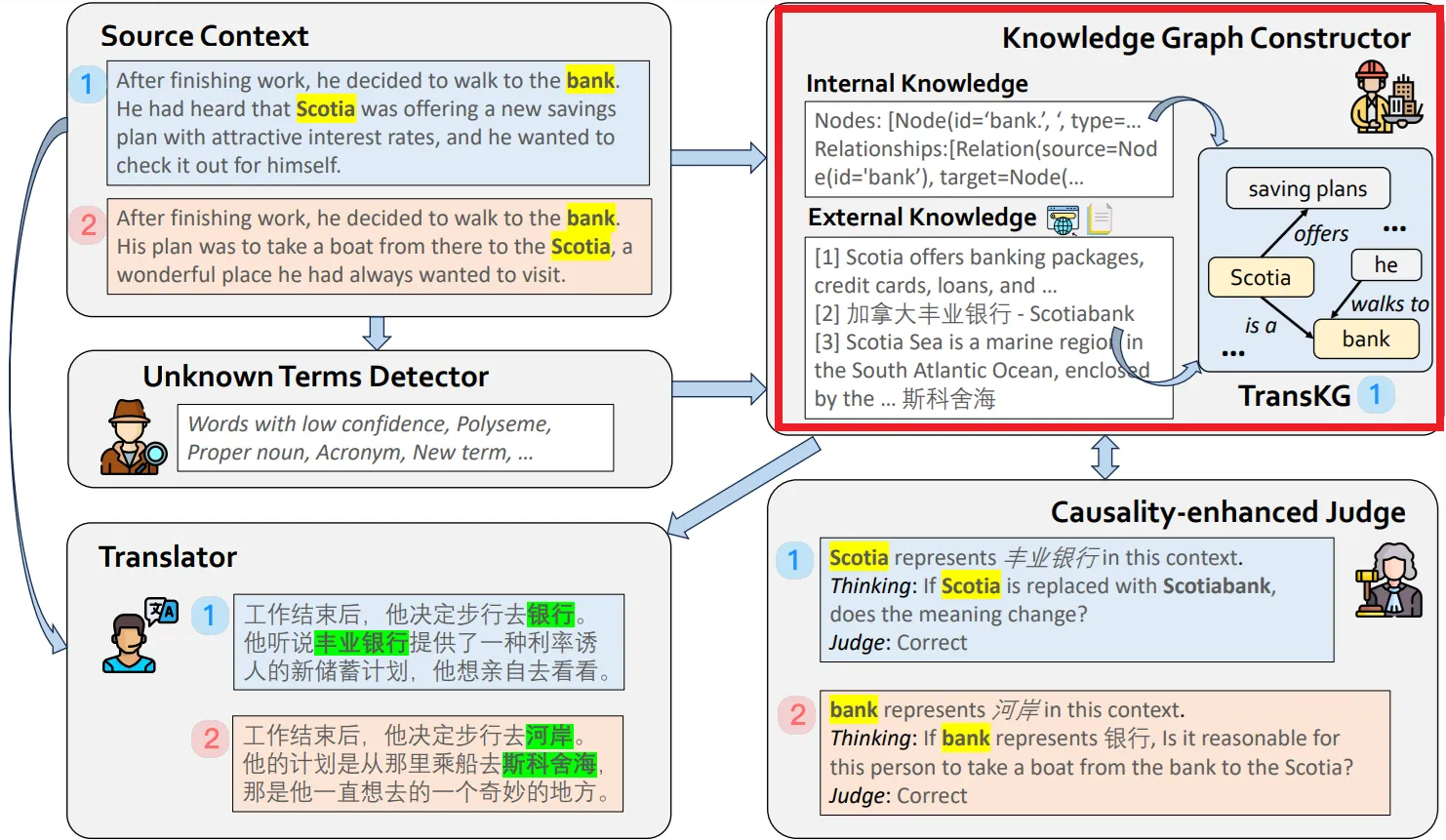
•
이 에이전트는 소스 문장에서 신뢰도가 낮은 단어를 식별하고, 이 단어들을 별도로 처리할 준비를 한다.
"bank"라는 단어가 등장하면 이 단어가 금융기관을 의미할 수도, 강둑을 의미할 수도 있기 때문에 탐지된 단어로 분류된다.
•
이 과정은 번역의 정확도를 높이기 위해 사전에 번역이 어려운 용어를 선별하여, 이후 단계에서 이 용어에 대해 보다 심층적인 처리를 가능하게 한다.
지식 그래프 생성기(Knowledge Graph Constructor) Agent
•
Unknown Terms Detector에 의해 식별된 용어들에 대한 추가 정보를 수집해 TransKG(Translation Knowledge Graph)라는 지식 그래프를 생성한다.
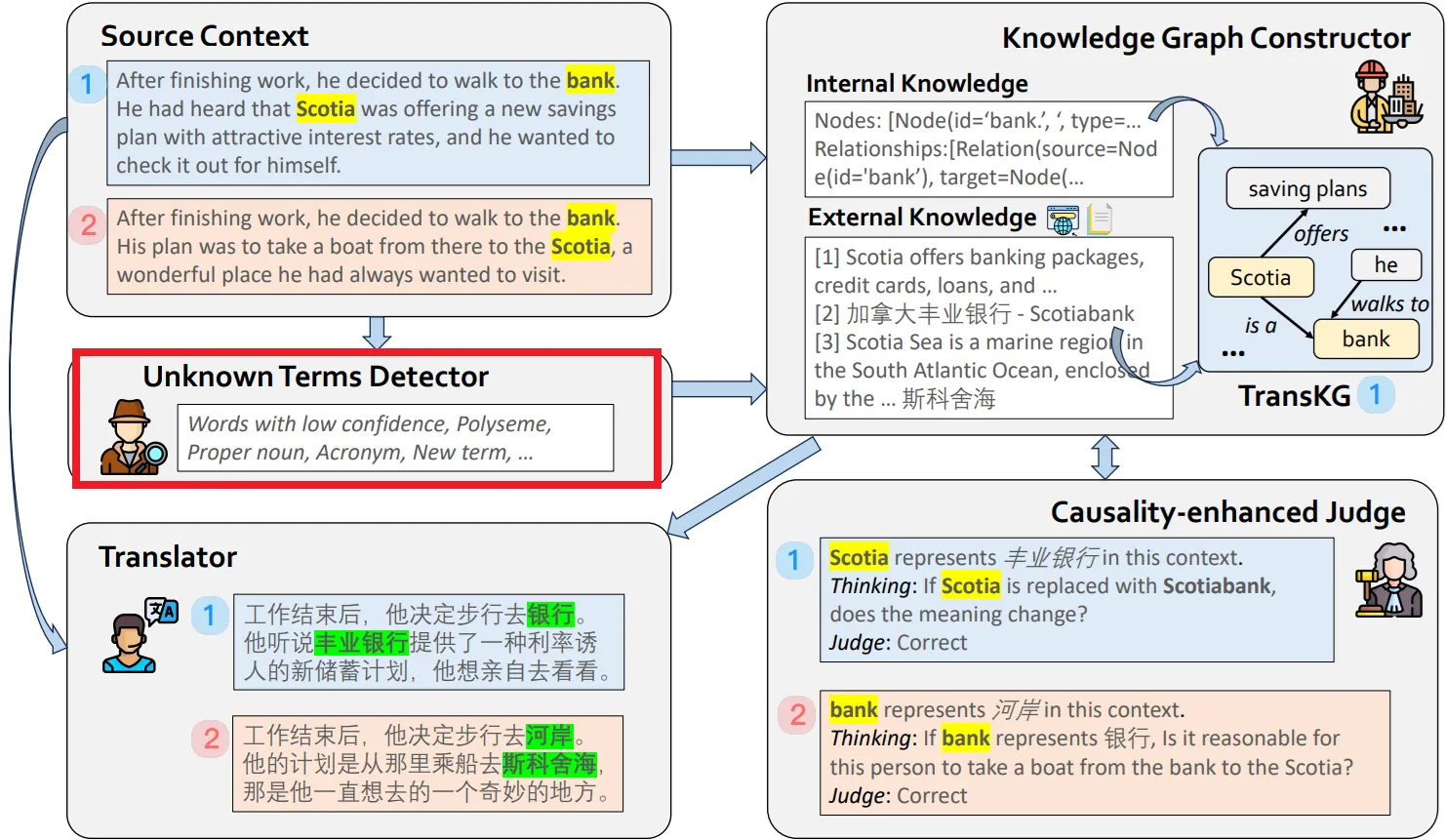
•
내부 지식: 먼저, 내부 텍스트를 분석하여 관계를 정의한다.
"Scotia offers savings plans"와 같은 구문을 그래프의 노드와 엣지로 변환해 구성한다.
•
외부 지식: 외부 데이터베이스를 검색하여 관련 정보를 가져온다.
"Scotia"가 지리적 위치일 수도 있고 금융기관일 수도 있다는 외부 지식을 수집하여 TransKG에 포함시킨다.
•
이 단계에서, 수식 로 내부 지식 를 소스 컨텍스트 로부터 추출하는 확률을 나타낸다.
•
외부 지식을 수집하는 과정은 로 나타내며, 이는 외부 지식 가 소스 문맥에 맞는지를 판단하는 확률로 설명된다.
인과성 강화 판별기(Causality-Enhanced Judge) Agent
•
Knowledge Graph Constructor가 구축한 TransKG의 정보를 검토하여, 이 정보가 번역 문맥에 적합한지를 평가한다.
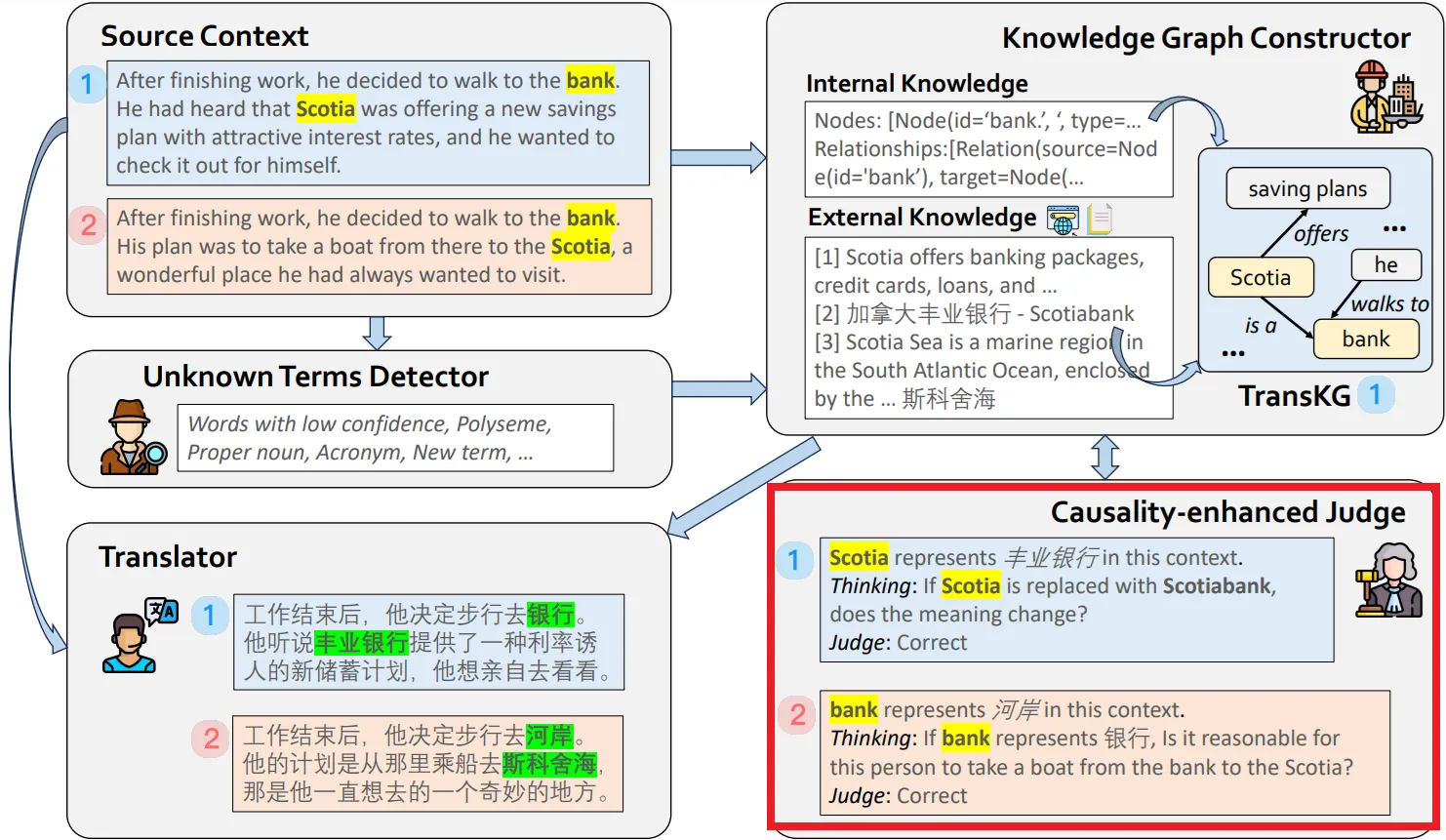
•
이 에이전트는 인과성 반영(Causality Reflection) 메커니즘을 통해 용어가 문맥에서 올바르게 해석되고 있는지 검토한다.
"bank"가 강둑으로 해석되었을 때, 소스 문맥에서 강둑이 맞는지 다시 평가하는 식이다.
•
이 단계에서 causal invariance를 통해 수집된 정보의 신뢰성을 검토하며, 특정 용어의 번역이 문맥적 일관성을 유지하는지 확인한다. 수식 를 통해 최종 번역 가 소스 문맥 와 내부/외부 지식 를 기반으로 일관된지를 평가하는 방식으로 나타낸다.
•
예를 들어, "Scotia"가 금융기관일 때와 지리적 장소일 때 문맥이 어떻게 달라지는지를 판단하여, 적절한 정보를 선택하도록 돕는다.
검색 증강 번역기(Retrieval-Augmented Translator) Agent
•
Causality-Enhanced Judge에 의해 검토된 정보를 바탕으로 최종 번역을 생성하는 단계
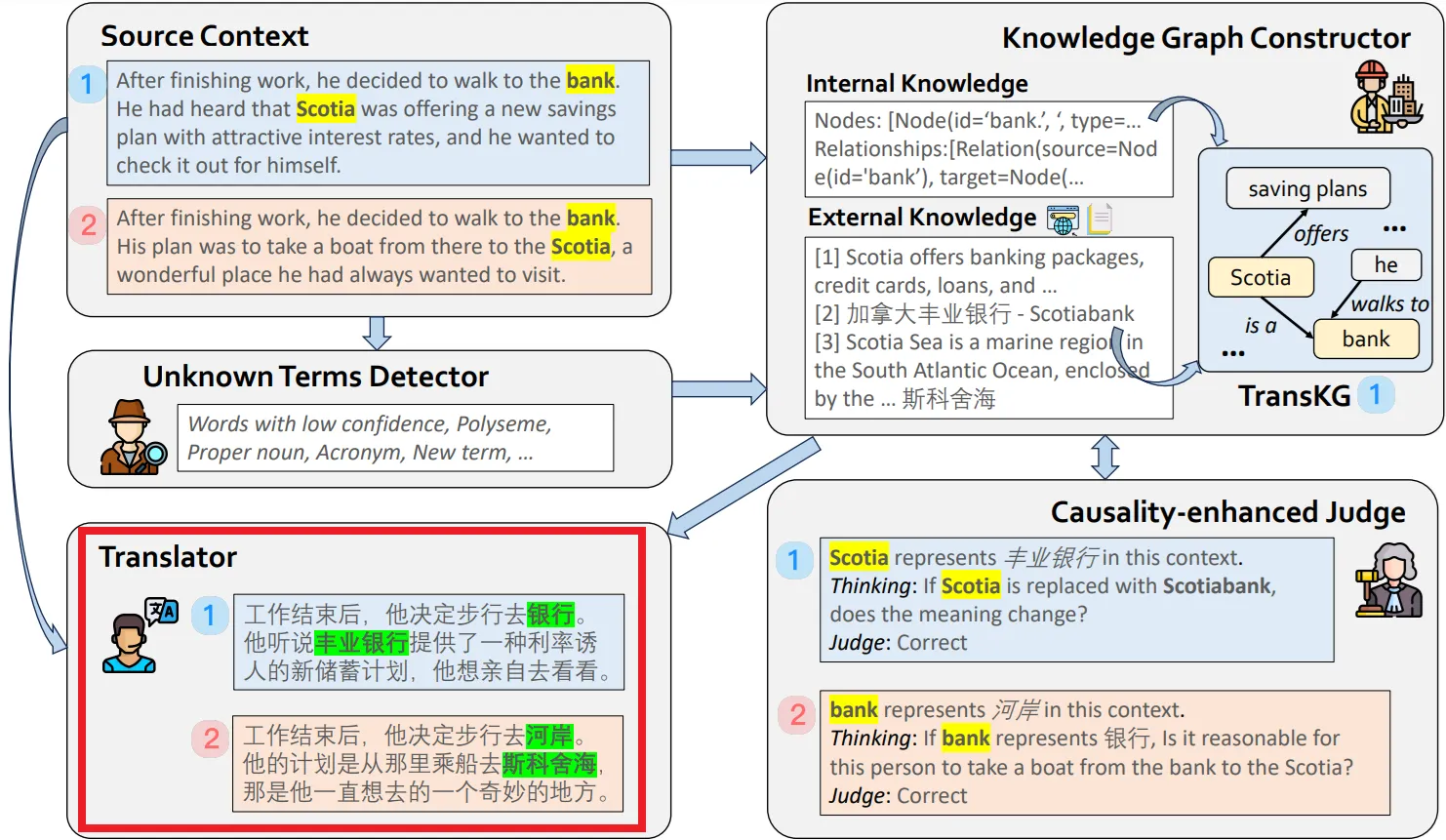
•
이 에이전트는 단어 대 단어 번역이 아닌, 문맥을 반영한 번역을 생성한다.
"bank"가 금융기관이 아닌 강둑으로 해석된 경우, 해당 단어를 적절히 "河岸(: 한국어론 강둑)"으로 번역해준다.
•
번역기의 결과는 정확하고 자연스러운 번역을 제공하며, 수식을 통해 최종 번역이 문맥과 의미에 따라 올바른지 확인한다.
25. Graph RAG
Graph RAG란?
•
대규모 언어 모델(LLM)을 활용해 대규모 문서 데이터셋에서 전역적인 요약 및 질의응답(Query-Focused Summarization, QFS)을 수행하는 시스템
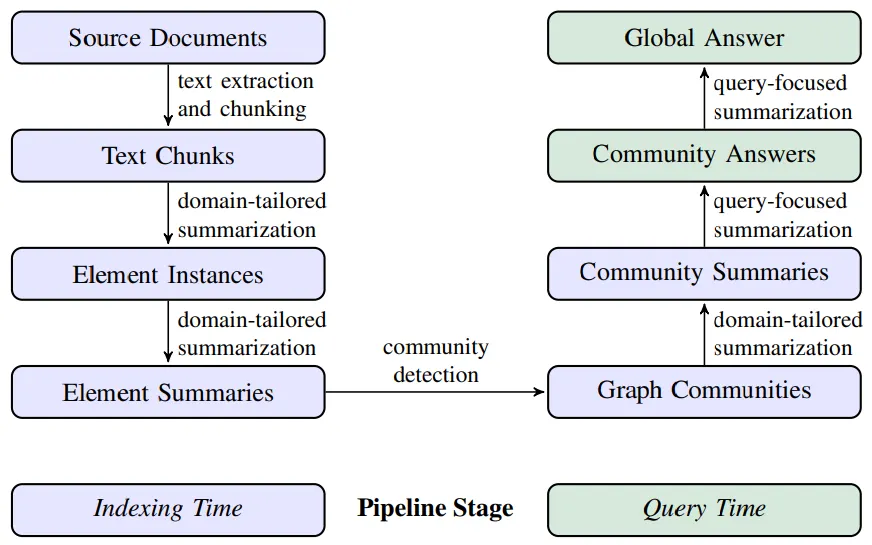
•
기존의 RAG(Retrieval-Augmented Generation) 시스템은 특정 텍스트 조각의 직접적인 검색과 요약을 목표로 하여, 광범위한 데이터셋의 전체 주제나 의미를 종합하는 데 한계가 있다.
•
Graph RAG는 이러한 한계를 해결하기 위해 전체 문서 집합을 구조화된 그래프로 나타내어 단순한 질의 응답이 아닌, 데이터셋 내 전체적인 주제 및 의미를 파악하고 요약하는 데 초점이 맞춰져 있다.
Naive RAG와의 비교
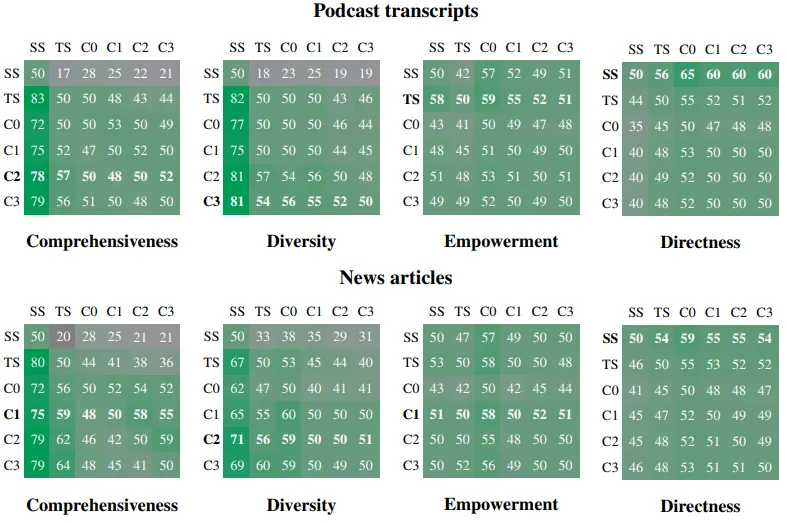
Podcast Transcripts와 News Articles 두 데이터 세트를 사용해 Comprehensiveness (포괄성), Diversity (다양성), Empowerment (사용자 이해 지원), Directness (직접성) 조건을 비교한 결과를 나타낸 그림
•
Graph RAG의 C1~C3 조건은 SS(Naive RAG)와 비교하여 포괄성과 다양성 면에서 월등히 우수.
•
특히, C3 수준의 커뮤니티 요약은 데이터 다양성과 심층적 분석에서 높은 성과를 보임.
•
TS는 여전히 Comprehensiveness과 Empowerment에서 우위를 보였으나, Graph RAG의 C1~C3가 이에 근접한 성능을 발휘.
•
Graph RAG는 리소스 효율성에서 유리한 이점을 가짐(C3가 TS 대비 적은 토큰 수로 유사한 성능 발휘).
•
SS는 간결성과 직접성이 중요할 때 유리하나, 심층적 질문에 대한 응답 품질(포괄성과 다양성)에서는 Graph RAG 방식이 더 나은 성과를 보여줌.
목적
글로벌 질문 처리
•
대규모 데이터셋은 다양하고 방대한 데이터로 구성되어 있어 처리 및 분석이 어렵다.
•
기존 RAG 시스템은 특정 텍스트 조각에 대한 지역적 질문(Local Questions)에는 효과적이지만, 데이터셋의 주요 주제나 맥락을 요약하는 데는 한계가 있다.
◦
개별 텍스트 조각에서 정보 검색이 가능하지만, 전체적인 데이터셋에 대해 종합적이거나 글로벌한 질문에 답변하기에는 어려움이 있다.
“이 데이터셋의 주요 주제는 무엇인가?” 같은 질문에 답하기 위해서는 각기 다른 문서들 사이의 연결과 주제적 흐름을 파악할 수 있어야 한다.
•
Graph RAG는 데이터셋 전반에 걸쳐 있는 엔티티(entity)와 관계를 파악해 이를 그래프 구조로 만들어, 전체적인 맥락에서 질문에 대한 답변을 할 수 있도록 한다.
◦
텍스트 데이터를 그래프 형태로 모델링하여 엔티티(노드)와 관계(엣지)를 정의하고 이를 구조적으로 표현함으로써, 데이터셋 전반의 맥락을 이해할 수 있는 기반을 마련한다.
◦
여기서 Leiden 알고리즘을 활용하여 그래프의 노드들을 유사성이 높은 그룹(커뮤니티)으로 분할하고, 이러한 커뮤니티 요약을 통해 글로벌 질문에 답변한다.
•
최종적으로 Graph RAG는 커뮤니티 요약을 통해 데이터셋의 주요 주제를 포괄적으로 다루며, 질문에 대한 통합적이고 심층적인 답변을 생성한다.
질문 중심 요약(QFS)의 확장성 제공
•
대규모 데이터셋에서도 질문 중심 요약 작업을 효율적으로 수행할 수 있는 확장성을 제공한다.
•
기존 QFS 시스템은 데이터셋의 크기가 커질수록 처리 성능이 급격히 저하되는 문제가 있었다.
•
Graph RAG는 그래프 기반 모델링과 병렬 처리 방식을 도입해 이러한 한계를 극복한다.
•
여기서 사용된 주요 설계 및 특징은 다음과 같다.
◦
맵-리듀스(Map-Reduce) 접근 방식
▪
Graph RAG는 커뮤니티 단위로 요약을 병렬 처리한 후, 이들을 통합해 최종 글로벌 요약을 생성한다.
→ 대규모 데이터를 빠르게 처리할 수 있다.
◦
계층적 요약 구조
▪
그래프의 계층적 구조를 활용해, 최상위 커뮤니티부터 하위 커뮤니티까지 다양한 수준에서 요약을 생성한다.
→ 질문에 적합한 깊이의 답변을 제공한다.
◦
질문 중심 초점 유지
▪
커뮤니티별 요약은 사용자의 질문과 직접적으로 연관된 정보를 선별하고, 질문에 최적화된 요약을 제공한다.
저비용 고효율 요약 제공
•
효율적인 데이터 처리를 통해 높은 품질의 요약을 제공하면서도 계산 비용을 최소화한다.
•
기존의 텍스트 요약 방식은 데이터셋 전체를 한 번에 처리하기 때문에 비용이 많이 드는 반면, Graph RAG는 커뮤니티 단위로 데이터를 분할 처리하여 효율성을 극대화한다.
◦
그래프 커뮤니티별로 요약을 수행함으로써 텍스트 전체를 처리할 때 소요되는 토큰 비용을 줄인다.
◦
루트 커뮤니티 수준에서 요약을 생성하면 전체 텍스트를 요약하는 데 필요한 비용의 2.6%만 사용하면서도 높은 품질을 유지할 수 있다.
•
그러면서 Graph RAG는 각 커뮤니티 요약을 독립적으로 병렬 처리하여 처리 속도를 크게 향상시킨다.
→ 대규모 데이터셋에서 특히 유리하다.
•
다음은 실제로 Graph RAG 방식의 계층적 요약이 소스 텍스트 직접 요약(Map-Reduce)보다 훨씬 리소스 효율적임을 보여주는 표이다.

데이터 세트 내 텍스트 요약 방식의 리소스 요구량 및 효율성 비교 표
◦
Root-level summaries (C0)은 가장 적은 단위(Units)와 토큰(Token)을 필요로 하며, Podcast Transcripts에서는 전체(TS) 대비 2.6%, News Articles에서는 2.3%의 토큰만 필요로 함.
◦
반면, Map-Reduce 방식의 요약(TS)은 가장 많은 단위와 토큰을 요구하며, 가장 리소스 집약적임.
◦
Podcast Transcripts의 경우, 커뮤니티 계층이 낮아질수록(더 세부적일수록) 필요한 토큰 수가 증가함(C0: 26657 → C3: 746100 → TS: 1014611).
◦
News Articles에서도 동일한 패턴이 나타남(C0: 39770 → C3: 1140266 → TS: 1707694).
◦
C0 같은 최상위 레벨 요약은 리소스 효율적이지만, 상세도와 포괄성 면에서 제한적일 수 있음.
◦
C3와 TS 방식은 더 포괄적이지만 리소스 사용량이 높아짐.
◦
Graph RAG의 계층적 커뮤니티 요약(C0~C3)은 Map-Reduce 방식에 비해 리소스를 크게 절감하며, 반복적 질의(Iterative Query)에 적합한 효율성을 제공함.
◦
특히 루트 커뮤니티 요약(C0)은 최대 97%까지 토큰 소비를 줄일 수 있음.
주요 동작
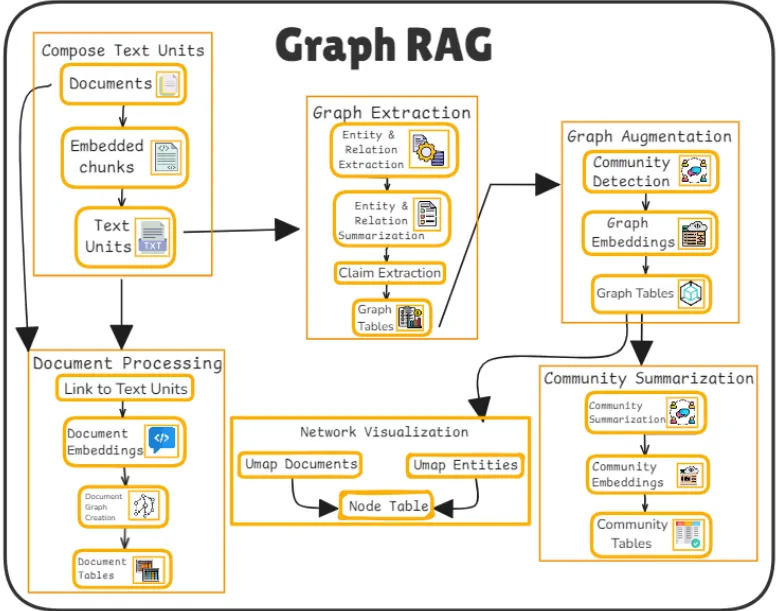
텍스트 조각(청크) 생성 (Compose Text Units)
•
원본 문서를 작은 텍스트 단위(청크)로 분할하여 문맥 정보를 유지하면서도 LLM의 입력 제한 내에서 처리 가능하도록 설계하는 단계
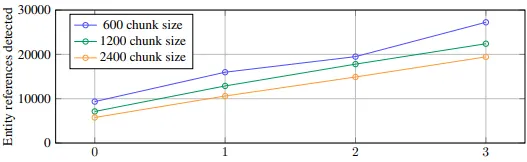
Number of gleanings performed
600 토큰의 청크 크기를 사용하면 2400의 청크 크기를 사용할 때보다 거의 두 배나 많은 entity가 추출.
참조(Reference)가 많을수록 일반적으로 더 좋지만, 모든 추출 프로세스는 대상 활동에 대한 재현율과 정밀도의 균형을 맞춰야 함.
•
문서 코퍼스의 도메인에 맞게 few-shot example을 프롬프트에 주입.
•
각 텍스트 조각(청크)은 고유한 의미를 가지며, 이 텍스트 단위를 기반으로 그래프를 구축할 준비를 한다.
•
이 때 텍스트 문서 D는 n개의 텍스트 조각 T={t1,t2,...,tn}으로 분할된다.
◦
여기서, 은 LLM이 처리할 수 있는 최대 토큰 수 제한을 충족시킨다.
◦
각 텍스트 조각 는 문서의 내용과 문맥을 최대한 유지해야 한다.
•
분할된 텍스트 조각 는 이후, 그래프 추출 단계로 전달된다.
•
LLM이 이전 추출 라운드에서 놓칠 수 있는 entity를 탐지하도록 최대 지정된 횟수까지 여러 라운드의 추출을 함.
◦
모든 Enity가 추출되었는지를 평가하도록 LLM에 요청 -> logit bias를 100으로 설정하여 예/아니오 중 결정하도록 강제.
▪
logit bias: 모델이 특정 출력을 더 혹은 덜 가능하게 만드는 조정 도구
◦
LLM이 누락된 Entity가 있다고 응답하면 누락된 Entity를 탐지하도록 수행
→ 이러한 접근법을 통해 더 큰 청크 크기를 사용하더라도 품질 저하없이 노이즈가 생기지 않도록 강제할 수 있음.
그래프 추출 (Graph Extraction)
•
각 텍스트 조각에서 엔티티(entity), 관계(relationship), 주장(claim)을 추출하여 이를 기반으로 그래프 구조를 생성하는 단계
•
각 엔티티는 그래프의 노드가 되고, 관계는 엣지가 된다.
•
LLM 기반 추출 함수 를 사용하여, 각 텍스트 조각 에서 엔티티와 관계를 감지한다:
여기서 는 엔티티, r은 두 엔티티 간의 관계를 나타낸다.
"COVID-19는 전 세계적으로 대유행을 일으켰다."는 으로 추출된다.
•
각 텍스트 조각의 엔티티와 관계를 기반으로 그래프 테이블 를 생성한다.
◦
: 엔티티 노드 집합
◦
: 관계 엣지 집합
•
이 과정은 정보의 연결성을 모델링하며, 그래프 구조화는 이후 커뮤니티 감지와 요약 작업의 기초를 형성한다.
그래프 확장 및 커뮤니티 감지 (Graph Augmentation and Community Detection)
•
생성된 그래프는 커뮤니티 감지 알고리즘을 통해 노드 간의 상관관계를 파악하여 커뮤니티를 형성한다.
커뮤니티(Community): 그래프 내에서 강하게 연결된 하위 구조, 특정 주제나 개념을 나타냄
•
그리고 이 때 커뮤니티를 감지하기 위해 Leiden 알고리즘을 사용한다.
Leiden 알고리즘: 그래프 커뮤니티 감지를 위해 사용되는 최적화 기법
그래프의 모듈성(Modularity)을 극대화하면서 노드 간 연결 관계를 분석한다.
Leiden 알고리즘은 다음 단계를 거친다.
•
이 단계들은 최적화된 커뮤니티 구조가 생성될 때까지 계속된다.
→ 각 커뮤니티가 하나의 노드로만 구성될 때까지 반복
◦
그래프의 모듈성(Modularity)은 각 커뮤니티 간의 연결 강도를 평가하며, 모듈성 Q는 다음과 같이 계산된다.
모듈성(Modularity): 그래프에서 커뮤니티 간의 연결 강도를 평가하는 지표
동일 커뮤니티 내 노드 간 연결 강도가 높고, 커뮤니티 간 연결 강도는 낮을수록 높은 모듈성을 갖는 것을 의미한다.
•
: 그래프의 인접 행렬(adjacency matrix).
•
: 노드 의 연결 강도(degree).
•
: 그래프의 총 엣지 수.
•
: 노드 와 가 동일한 커뮤니티에 속하는 경우 1, 그렇지 않으면 0.
◦
이는 그래프의 모듈성을 최대화하며, 계층적 커뮤니티를 생성한다.
커뮤니티 요약 (Community Summarization)
•
특정 커뮤니티의 주요 정보(노드, 관계, 속성)를 요약하여 하나의 의미 있는 응답을 생성하는 단계
•
각 커뮤니티 의 요약은 LLM 기반 요약 함수 를 사용하여 생성된다.
◦
: 커뮤니티 의 요약.
◦
: 커뮤니티 내 주요 노드, 엣지, 속성을 반영하여 요약을 생성.
•
리프 커뮤니티 요약을 먼저 생성한 후, 상위 커뮤니티 요약을 통합하여 전체 그래프의 전역 요약을 제공한다.
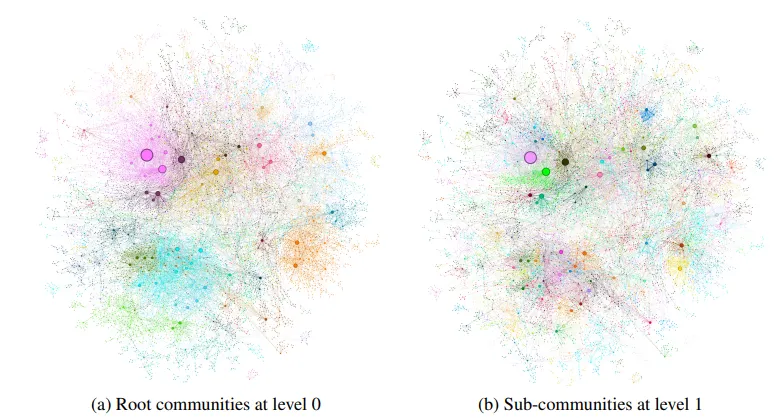
MultiHop-RAG 데이터셋을 기반으로 생성된 그래프의 두 가지 커뮤니티 계층(Level 0-루트와 Level 1-하위)
◦
Leaf-Level Community Summarization
▪
Leaf-level 커뮤니티는 그래프의 가장 세부적인 레벨에서 감지된 커뮤니티를 의미, 노드와 엣지 수준의 정보를 기반으로 요약이 이루어진다.
▪
우선순위화(Prioritization)
1.
먼저 엣지의 소스 노드와 타겟 노드의 결합된 차수(degree)를 기준으로 우선순위를 정한다.
2.
그 다음, 우선순위가 높은 순서대로, 소스 노드, 타겟 노드, 관련 속성(covariates), 그리고 엣지 설명을 LLM의 컨텍스트 창에 추가한다.
3.
컨텍스트 창의 토큰 제한에 도달할 때까지 위 과정을 반복하며, 제한을 초과하면 우선순위가 낮은 정보를 제거한다.
→ 리프 레벨 요약에서 가장 중요한 정보를 추출하는 데 초점
◦
Higher-Level Community Summarization
▪
Higher-level 커뮤니티는 상위 계층의 커뮤니티 구조를 요약, 리프 커뮤니티보다 더 추상적인 정보를 제공한다.
▪
요약 전략
1.
모든 요소가 토큰 제한 내에 들어갈 경우, 리프 커뮤니티와 동일한 방식으로 요약을 수행한다.
2.
이 때, 제한을 초과하면 하위 커뮤니티의 요약 내용을 사용하여 더 간결한 형태로 대체한다.
3.
하위 커뮤니티 요약을 통합하여 상위 레벨의 요약을 생성한다.
→ 상위 커뮤니티에서 정보의 범위와 토큰 제한 문제를 해결하는 데 초점
•
이 과정은 복잡한 그래프 구조를 단순화하고 사용자가 이해하기 쉽게 한다.
네트워크 시각화 및 질의 응답 (Network Visualization and Q&A)
•
시각화는 그래프 데이터의 구조를 이해하는 데 도움을 주며, UMAP을 사용하여 고차원 데이터를 2D/3D로 축소한다.
UMAP(Uniform Manifold Approximation and Projection)
•
고차원 임베딩 데이터를 저차원으로 축소
◦
: 노드 i, j 간의 거리
◦
: 노드의 임베딩 벡터
◦
: 유클리드 거리(Euclidean distance)를 의미
•
사용자의 질문은 시각화된 노드와 연결 정보를 기반으로 최적의 응답을 생성하는 데 사용된다.
◦
사용자의 질문 는 관련 커뮤니티 요약 와 결합되어 최종 응답 를 생성한다.
