


•
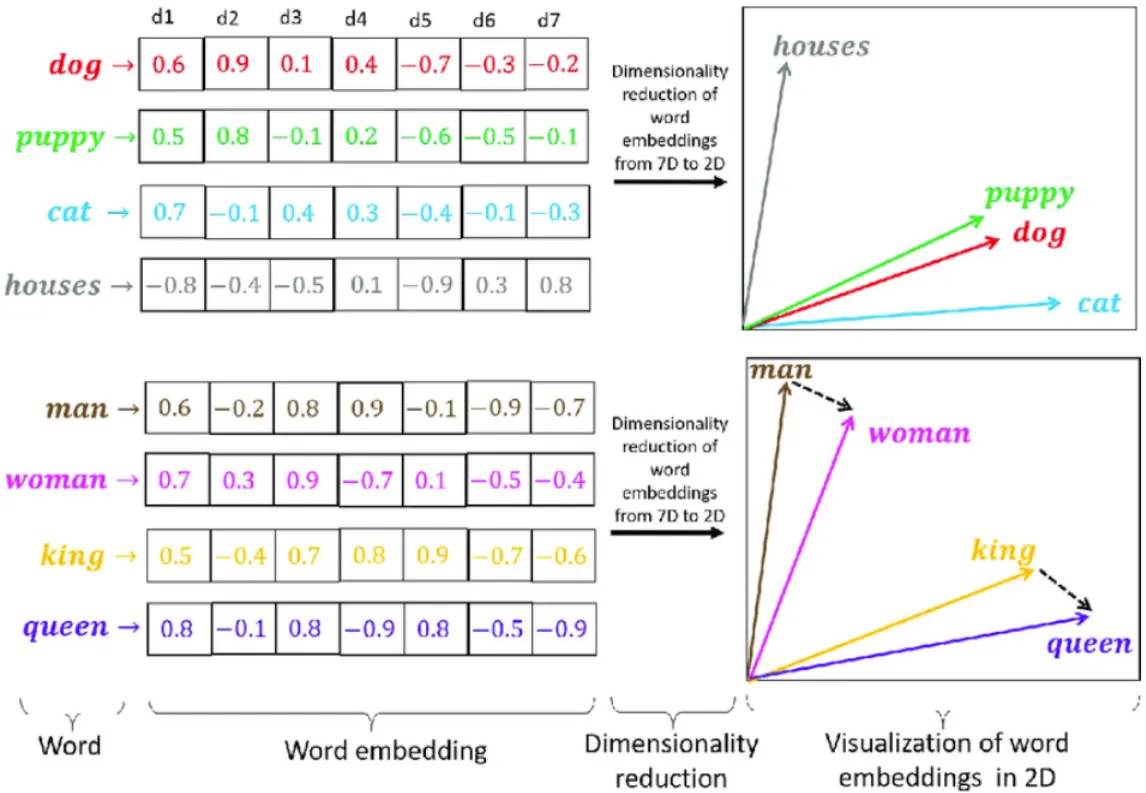
Word2Vec은 word embedding을 학습시키는 가장 유명한 방법 중 하나
•
어떠한 단어가 서로 유사한 의미를 지니는지를 학습하기 위해 Word2Vec에서는 같은 문장에서 나타난 인접 단어들 간의 의미가 서로 유사할 것이라는 가정을 전제로 가져간다.
•
즉, 어떤 한 단어가 주변에 등장하는 단어를 통해 그 의미를 유추할 수 있다는 아이디어에서 출발한 방법이며, 주어진 학습 데이터를 바탕으로 특정 단어의 주변에 나타나는 단어의 등장 확률 분포를 예측하게 된다.
•
단어의 빈도를 기준으로 단어의 벡터화(Bag of Words)를 하여 특징을 추출하는 방법은 단어 사이의 유사도를 나타내기 힘들다. 단어의 특징과 유사도를 나타내 주는 방법이 Word2Vec이다.
•
Word2Vec에는 CBow와 Skip-gram이 있다. CBOW는 어떤 단어를 문맥 안의 주변 단어들을 통해 예측하는 방법이고, Skip-gram은 반대로 어떤 단어를 가지고 특정 문맥 안의 주변 단어들을 예측하는 과정이다.
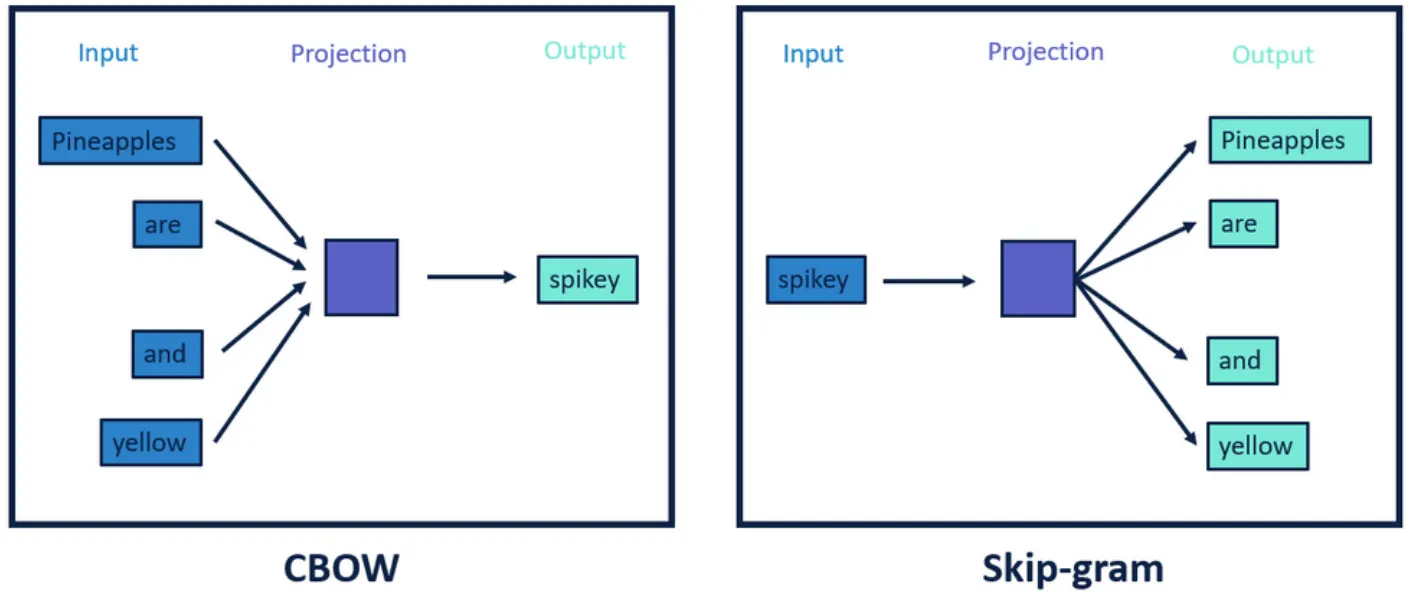
1. tokenizing을 통한 Vocabulary 구축
2. sliding window
•
Word2Vec에서는 인접한 단어의 의미적인 유사성을 파악하기 위해 슬라이딩 윈도우(sliding window) 기법을 사용하는데, 이는 중심 단어로부터 얼마나 멀리 떨어져 있는 단어까지 유사한 관계로 학습할지를 반영하기 위함이다.
•
그래서 슬라이딩 윈도우 기법을 적용하여 어떤 한 단어를 중심으로 앞뒤로 나타나는 각각의 단어와 짝을 지어 입출력 쌍을 구성한다.
3. 행렬연산을 이용하여 의미적인 유사성 파악
•
이 예시에서 One-hot vector의 차원 수이자 전체 단어의 개수가 5이므로 input layer와 output layer의 node 개수는 5가 된다.
•
Hidden layer의 node 수는 사용자가 정하는 하이퍼파라미터이며, word embedding을 수행하는 좌표 공간의 차원 수의 동일한 값으로 설정한다.
•
이번 예시에서는 차원이 3인 임베딩 공간에서 임베딩을 수행한다고 가정하여 hidden layer의 node 수를 3으로 설정했다.
또한 각 layer 사이의 파라미터에 주목할 필요가 있다. 위의 예시에서 Input layer에서 hidden layer로 가는 파라미터를 W1, hidden layer에서 output layer로 가는 파라미터를 W2라고 하자.
◦
W1를 행렬로 나타냈을 때의 크기는 (임베딩 차원 수) × (one-hot vector 차원 수)이고, W2는 (one-hot vector 차원 수) × (임베딩 차원 수)이다.
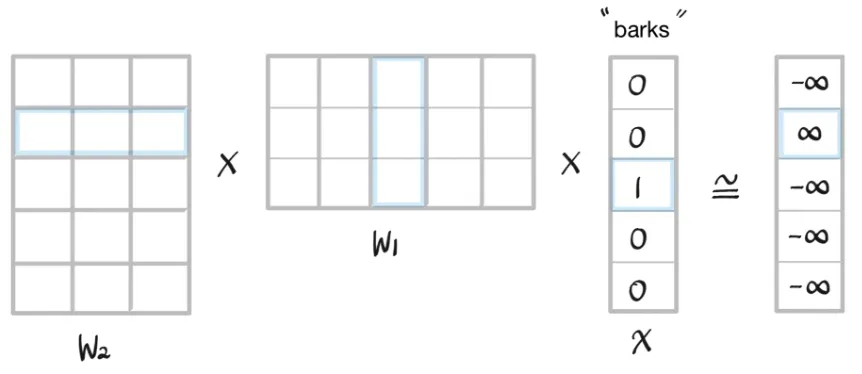
4. softmax
•
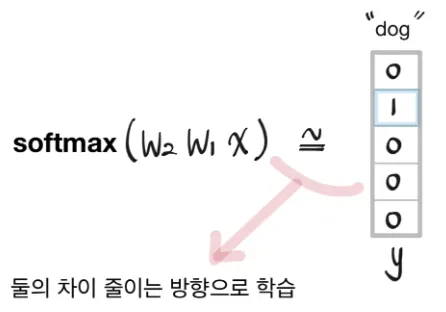
위에서 구한 결과를 의 row vector와 곱해서 나온 결과에 softmax를 취해서 나오는 확률 분포가 ground truth인 "dog"의 one-hot vector와 유사해지도록 학습해야 한다.
•
그래서 의 결과에다가 softmax를 취해서 0과 1사이의 확률 값으로 나타내도록 하여 output 과 얼마나 차이나는지 loss를 구하고 이를 줄이는 방향으로 학습을 진행한다.
학습결과 시각화 사이트
Pre-trained Word2Vec
사전 학습된 모델
import gensim
from gensim.test.utils import datapath
import urllib.request
# 구글의 사전 훈련된 Word2Vec 모델을 로드.
DATA_PATH = "/content/data/MyDrive/google_lecture/06. deep learning/3. NLP Pytorch/models/"
word2vec_model = gensim.models.KeyedVectors.load_word2vec_format(DATA_PATH+'GoogleNews-vectors-negative300.bin.gz', binary=True)
SQL
복사
