사전 용어
정수 인코딩(Integer-Encoding)
•
자연어 처리에서 텍스트를 숫자로 변환하는 과정 중 하나
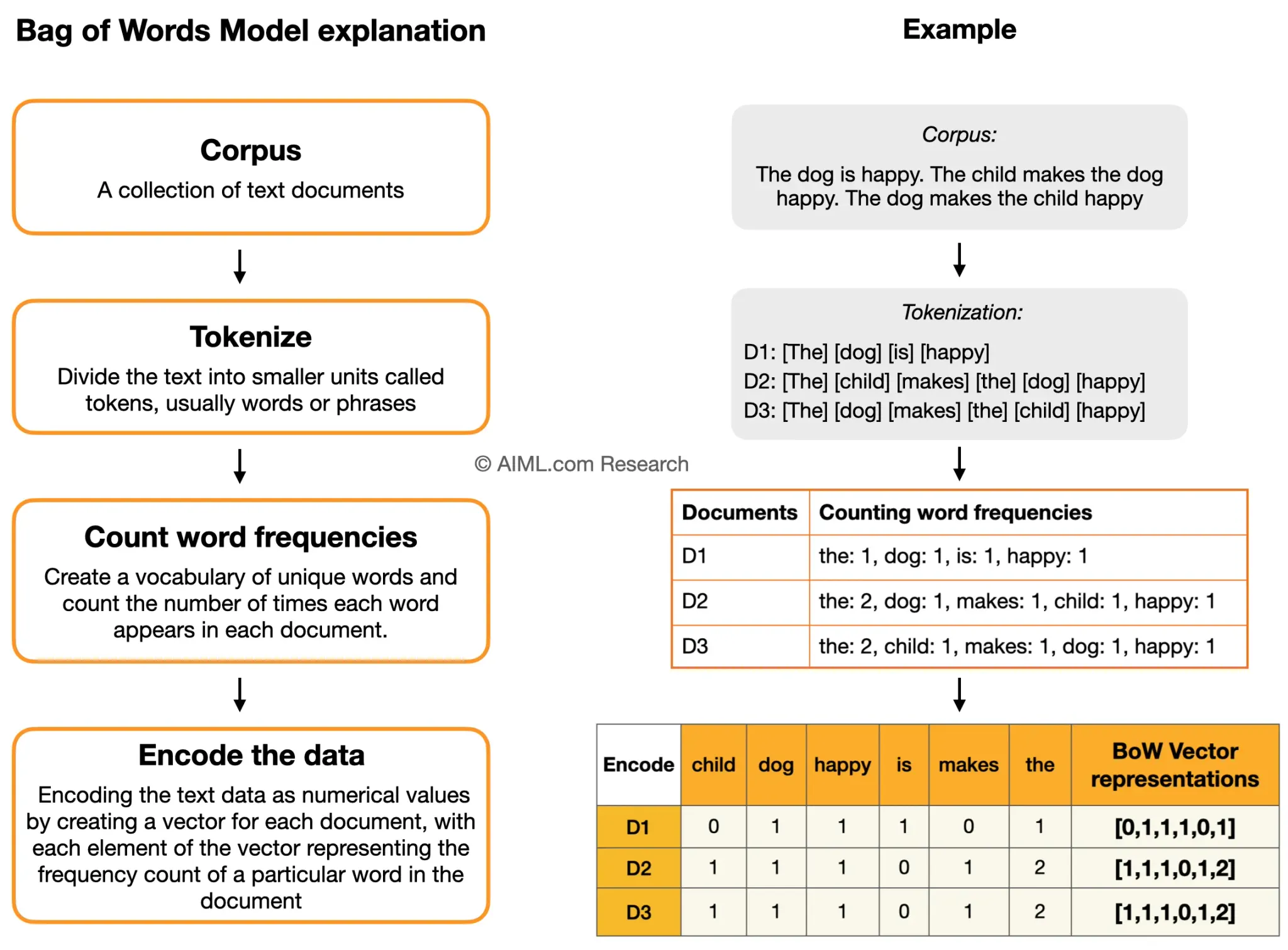
Bag of Words - BOW
•
문서가 가지는 모든 단어(Words)를 문맥이나 순서를 무시하고 일괄적으로 단어에 대해 빈도 값을 부여해 피처 값을 추출하는 방법
Vectorizer(벡터화) 종류
DictVectorizer
•
각 단어의 수를 세어놓은 사전에서 BOW 인코딩 벡터를 만든다.
•
Bag of Words는 문서가 가지는 모든 단어(Words)를 문맥이나 순서를 무시하고 일괄적으로 단어에 대해 빈도 값을 부여해 피처 값을 추출하는 방법이다.
•
원본 데이터:
◦
첫번째 문서: When you have faults, do not fear to abandon the
허물이 있다면, 버리기를 두려워 말라. (공자)
•
you, fault, fear abandom
◦
두번째 문서: You will face many defeats in life, but never let yourself be defeated.
인생에서 많은 패배에 직면하겠지만 결코 패배하지 말라. (마야 안젤루)
•
you, face defeat, life, let, defeat
◦
각 문서별 단어의 수를 정리하면,
▪
you는 모든 문장에서 사용됨
▪
defeat는 하나의 문장에서 여러번 사용됨
from sklearn.feature_extraction import DictVectorizer
vect = DictVectorizer(sparse=False)
SQL
복사
data = [{'A': 1, 'B': 2}, {'B': 3, 'C': 1}]
X = vect.fit_transform(data) # 인코딩 수치 벡터로 변환(X)
SQL
복사
•
X는 아래와 같이 변환됨
{'A': 1, 'B': 2} -> [1, 2, 0] {'B': 3, 'C': 1} -> [0, 3, 1]
X
# array([[1., 2., 0.],
# [0., 3., 1.]])
vect.feature_names_
# ['A', 'B', 'C']
vect.transform({'A': 1, 'E': 3}) # E는 제외됨
# array([[1., 0., 0.]])
vect.transform({'C': 4, 'D': 3}) # D는 제외됨
# array([[0., 0., 4.]])
vect.transform({'B': 4, 'T': 3})
# array([[0., 4., 0.]])
vect.transform([{'B': 4, 'T': 3}, {'C': 4, 'A': 3}])
# array([[0., 4., 0.],
# [3., 0., 4.]])
SQL
복사
CountVectorizer
•
문서 집합에서 단어 토큰을 생성하고 각 단어의 수를 세어 BOW 인코딩 벡터를 만든다.

from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This is the second second documents.',
'And the third one.',
'Is this the first document?',
'The last document?',
]
SQL
복사
vect = CountVectorizer() # 객체화
{'this': 10,
'is': 4,
'the': 8,
'first': 3,
'document': 1,
'second': 7,
'documents': 2,
'and': 0,
'third': 9,
'one': 6,
'last': 5}
# 학습 -> 어간추출/표제어추출하지 못함!!! 단순 단어 카운트
vect.fit(corpus)
vect.vocabulary_ # 학습 데이터 확인
vect.transform(['This This is the second document.']).toarray()
# array([[0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 2]])
vect.transform(['Something completely new.']).toarray()
# array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
corpus
['This is the first document.',
'This is the second second documents.',
'And the third one.',
'Is this the first document?',
'The last document?']
vect.transform(corpus).toarray()
array([[0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1],
[0, 0, 1, 0, 1, 0, 0, 2, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0],
[0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1],
[0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0]])
SQL
복사
stop words
•
stop words는 문서에서 단어장을 생성할 때 무시할 수 있는 단어를 말한다. 보통 관사, 접속사, 조사 등이 여기에 해당한다.
token
•
analyzer, tokenizer 등의 인수로 사용할 토큰 생성기를 선택할 수 있다.
nltk(형태소 분석기)
•
오래된 영어 전용 형태소 분석기
N-gram
•
N-gram은 단어장 생성에 사용할 토큰의 크기를 결정한다. 모노그램(monogram)은 토큰 하나만 단어로 사용하며 바이그램(bigram)은 두 개의 연결된 토큰을 하나의 단어로 사용한다.

빈도수
•
max_df, min_df인수를 사용하여 문서에서 토큰이 나타난 횟수를 기준으로 단어장을 구성할 수도 있다.
•
토큰의 빈도가 max_df로 지장한 값을 초과 하거나 min_df로 지정한 값보다 작은 경우에는 무시
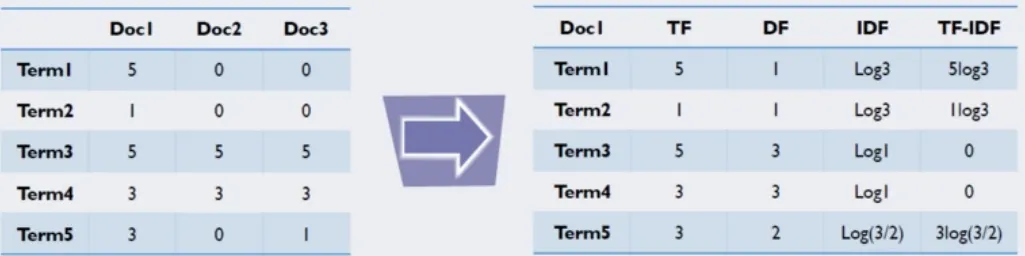
TfidVectorizer
•
CountVectorizer와 비슷하지만 TF-IDF 방식으로 단어의 가중치를 조정한 BOW 인코딩 벡터를 만든다.
•
정리
◦
TF(Team Frequency) : 특정 단어가 하나의 데이터 안에서 등장하는 횟수
◦
DF(Document Frequency) : 문서 빈도 값, 특정 단어가 여러 데이터에 자주 등장하는지를 알려주는 지표
◦
IDF(Inverse Document Frequency) : DF값에 역수를 취해서 구할 수 있으며, 특정 단어가 다른 데이터에 등장하지 않을수록 값이 커진다.
•
단순 횟수를 이용하는 것보다 각 단어의 특성을 좀 더 반영할 수 있다.