
.png&blockId=10f00c82-b138-8046-aa52-e4144e4413f2)
.png&blockId=10f00c82-b138-8046-aa52-e4144e4413f2&width=256)
Glue
•
완전 관리형 ETL(Extract, Transform, Load) 서비스
ETL : Extract(추출), Transform(변환), Load(로드)의 약자
데이터를 추출하고, 필요한 형식으로 변환한 후, 데이터 웨어하우스 또는 분석 시스템과 같은 시스템으로 로드하는 과정
•
사용자와 워크로드를 지원하기 위한 여러 데이터 통합 엔진을 제공하는 서버리스 데이터 통합 서비스
•
워크로드의 특성과 개발자 및 애널리스트의 선호도를 기준으로 모든 워크로드에 맞는 적절한 엔진을 사용할 수 있다.
•
데이터 스토어 및 데이터 스트림 간에 원하는 데이터를 분류, 정리, 보강, 이동할 수 있다.
•
AWS Glue에서는 Script를 Visualizing 하여 설정이 편하고 쉽다.
•
또한 AWS 서비스이기에 다른 AWS 서비스와의 연동성도 뛰어나며 S3, RDS, DynamoDB 등 다양한 데이터 소스를 받아 사용이 가능하다.
•
제일 중요한 점은 알아서 GUI 환경에서 Flow를 생성하면 그에 맞춰서 Spark 문을 완성시켜준다!
왜 AWS Glue를 선택하는가
•
ETL의 기능을 필요로 하는 고객이 있는데 오픈 소스를 사용한 ETL 과정을 사용할 경우, 처음부터 아키텍칭을 해야 하며 그 툴의 사용 방법을 익히기까지 많은 시간이 든다.
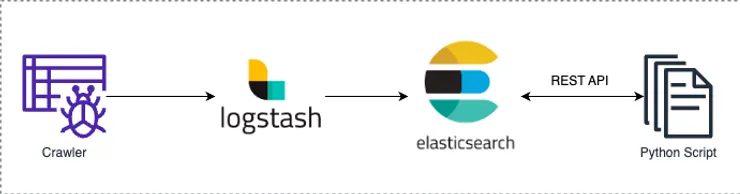
예제 : ElasticStack 사용한 ETL 구조
1.
데이터 수집을 위한 API나 크롤링 스크립트 작성을 하여 데이터를 수집
2.
logstash로 정기적으로 가져와 통합시킨 후 Elasticsearch에 저장
3.
이후 데이터 분석을 위해 Elasticsearch API를 사용해 데이터를 가져와 python 스크립트를 사용해 데이터 분석을 진행 후 다시 export
•
ElasticStack flow를 보면 사실 Glue와 비교할 만한 서비스는 logstach이다.
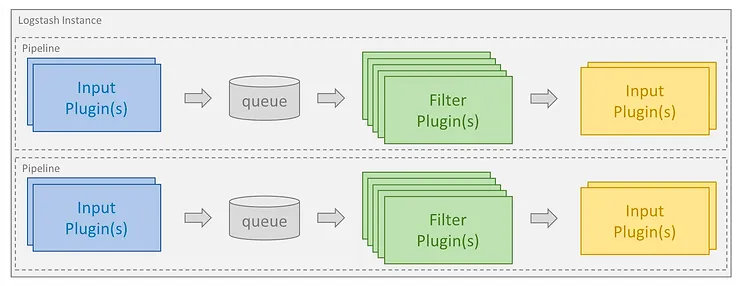
elastic 홈페이지에서 발췌한 Logstach의 ETL
•
Logstash는 사용자가 직접 서버를 관리하고 설정해야 한다.
•
말 그대로 서버를 열어 초기 세팅이 필요하다 것이 단점
•
또한 Filter에서 지원하는 Plugin이나 사용 방법 등 많은 내용을 공부해야 하기 때문에 데이터 파이프라인에 익숙지 않다면 사용하기 어려울 수 있다.
•
그러나 AWS Glue는 관리형 서비스로서 사용자가 서버나 인프라를 직접 관리할 필요가 없고 Filter 과정이 정형화 되어있는 편이라고 할 수 있다.
Glue의 구성 요소
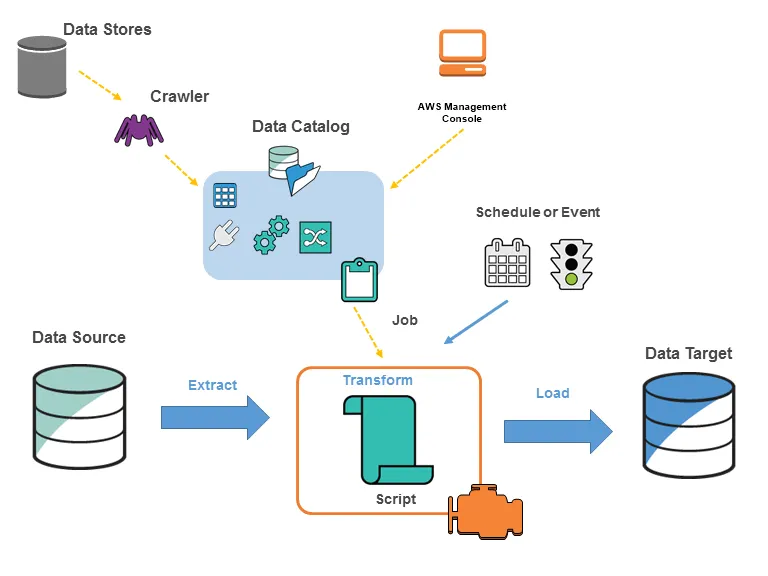
1.
Data Store : S3, RDS, Redshift, Kinesis, Apache kafka 등 데이터 저장 서비스나 데이터 스트림 서비스
2.
Classifier : 데이터의 스키마를 결정하고 일반적인 파일들의 분류자를 제공(ex. csv, tsv 파일들)
3.
Crawler : Classifier의 우선 순위 지정 목록을 통해 데이터의 스키마를 결정한 다음, 메타 데이터 테이블을 생성
4.
Data Catalog : 테이블 정의, 작업 정의 및 기타 관리 정보를 포함
5.
Job : ETL 작업을 수행하는 데 필요한 변환 스크립트, 데이터 원본 및 데이터 대상으로 구성된 비즈니스 로직
6.
Connection : AWS의 다른 데이터 저장 서비스나 사용자의 VPC환경 내부에 있는 데이터베이스에서 데이터 추출을 위한 장치
7.
Script : Apache Spark에서 사용하는 PySpark, Scala등으로 짜여진 ETL 작업 스크립트
8.
Schedule or Event : Job이 실행되는 주기를 설정하거나, 혹은 특정 이벤트로 인한 트리거로 실행
Data Stores(데이터 스토어)
•
데이터를 지속적으로 저장하기 위한 저장소(Ex. S3, 관계형 데이터베이스 등)
Classifier(분류자)
•
데이터 스키마를 결정하며, Glue는 CSV, JSON, AVRO, XML 등과 같은 일반 파일 형식에 대한 분류자를 제공한다.
Data Source와 Data Target
•
Data Source: 데이터가 추출되는 원본 위치로, AWS의 데이터 저장소뿐만 아니라 외부 데이터베이스와 데이터 파일 시스템 등에서 데이터를 가져올 수 있다.
•
Data Target: 변환된 데이터를 저장하는 목적지로, 데이터 웨어하우스나 데이터 레이크와 같은 저장소에 데이터를 로드한다.
Crawler (크롤러)
•
Data Source에서 메타데이터를 수집하여 Data Catalog에 등록하는 역할을 한다.
•
데이터 스키마를 자동으로 탐지하고 업데이트하며, 다양한 데이터 소스에서 구조를 추출하여 데이터 카탈로그에 기록한다.
Data Catalog (데이터 카탈로그)
•
AWS Glue의 핵심 메타데이터 저장소로, 데이터베이스, 테이블, 스키마 정보 등 데이터를 구조화하여 저장한다.
•
Glue의 모든 작업은 이 Data Catalog를 참조하여 수행된다.
•
Crawler가 데이터 소스에서 메타데이터를 수집하고 Data Catalog를 업데이트한다.
Job (작업)
•
ETL 작업을 수행하는 데 필요한 비즈니스 로직
◦
추출한 데이터를 변환하고, 변환된 데이터를 로드하는 ETL(Extract, Transform, Load) 프로세스를 정의하는 실행 단위
•
변환 스크립트, 데이터 원본 및 데이터 대상으로 구성
◦
스크립트를 통해 데이터를 변환할 수 있으며, 주로 파이썬이나 스파크를 사용하여 작성된 ETL 스크립트를 실행한다.
Scheduler or Event (스케줄러 또는 이벤트)
•
Job을 자동으로 실행하도록 예약하거나 특정 이벤트에 의해 트리거될 수 있다.
•
정기적으로 데이터 파이프라인을 자동화할 때 유용하며, EventBridge와 같은 서비스와 연계할 수 있다.
Connection(연결)
•
특정 데이터 스토어에 연결하는 데 필요한 속성을 포함하는 Data Catalog 객체
Glue Studio - ETL Jobs
•
AWS Glue 의 새로운 시각적 인터페이스
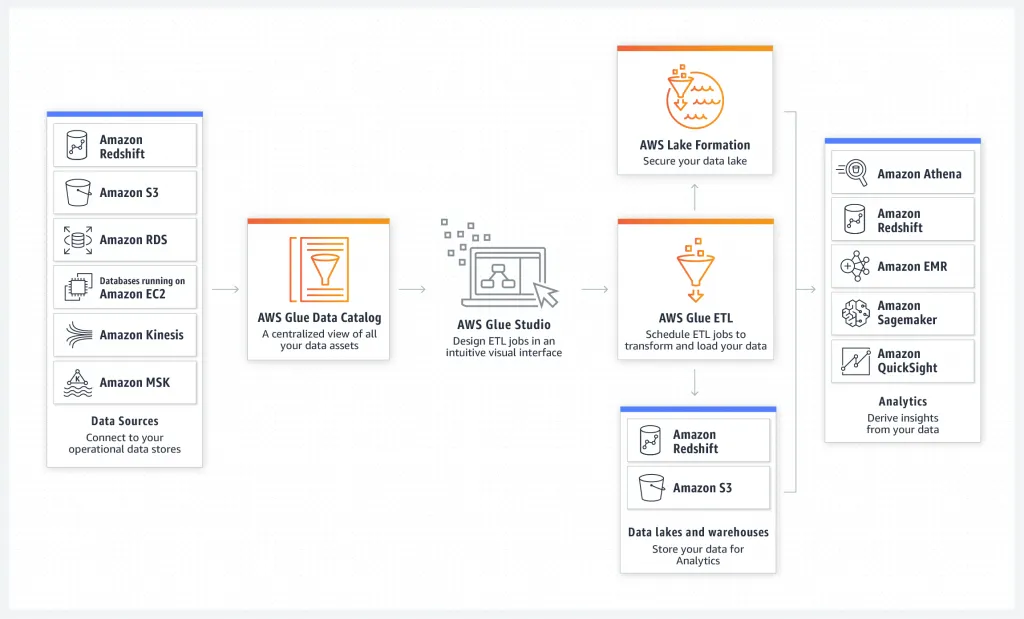
•
추출-변환-로드(ETL)가 필요한 개발자들이 AWS Glue 에서 ETL 작업을 손쉽게 작성하여 실행 및 모니터링 가능이 가능하다.
•
경험 수준과 관계없이 모든 사용자가 코드를 작성하지 않고 AWS Glue의 서버리스 Apache Spark 기반 ETL 플랫폼에서 빅데이터를 처리 가능하다.
Apache Spark는 Python, Scala를 지원한다.
Visual ETL
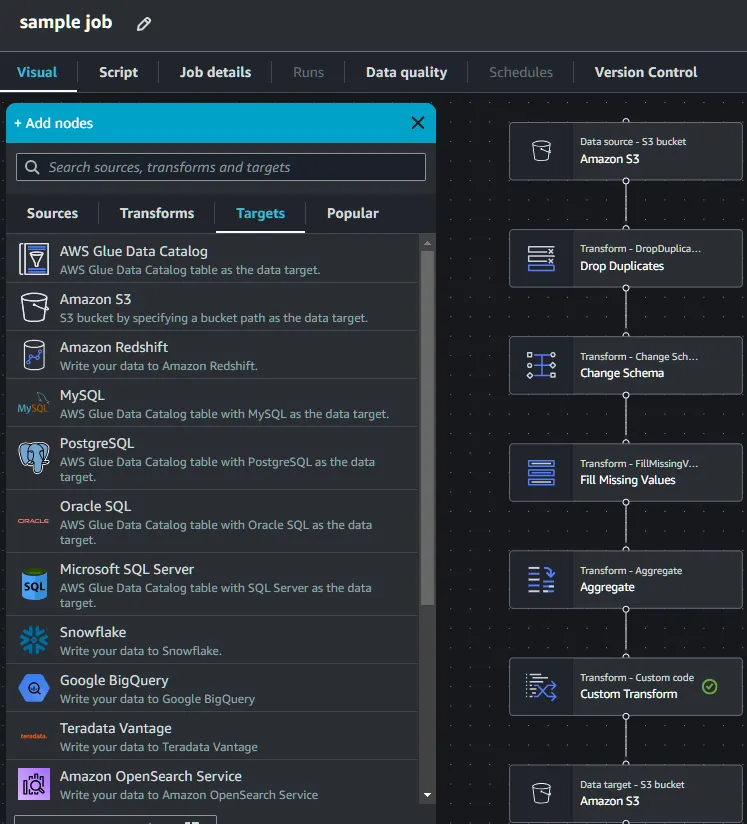
주요 Sources & Targets
1.
S3 (Simple Storage Service)
•
설명: AWS Glue에서 가장 널리 사용되는 데이터 소스 중 하나, 구조화된 데이터(CSV, JSON, Parquet 등)와 비구조화된 데이터를 저장할 수 있다.
2.
RDS (Relational Database Service)
•
설명: MySQL, PostgreSQL, Oracle, SQL Server 등 다양한 관계형 데이터베이스를 지원
3.
Redshift
•
설명: AWS의 데이터 웨어하우스 서비스로, 대규모 데이터 분석에 최적화되어 있다.
4.
DynamoDB
•
설명: 완전관리형 NoSQL 데이터베이스 서비스로, 키-값 및 문서 데이터 구조를 지원
5.
Aurora
•
설명: MySQL 및 PostgreSQL 호환의 고성능 관계형 데이터베이스 서비스
6.
Data Catalog
•
설명 : 데이터의 메타데이터를 중앙에서 관리하고 조직화하는 역할
Transforms
1.
ApplyMapping
•
설명: 데이터의 필드 이름과 데이터 타입을 매핑하여 변환
•
용도: 소스 데이터의 스키마를 타겟 스키마에 맞추기 위해 사용
2.
SelectFields
•
설명: 특정 필드만 선택하여 데이터 프레임을 축소
•
용도: 불필요한 필드를 제거하고 필요한 데이터만 선택할 때 사용
3.
DropFields
•
설명: 지정된 필드를 데이터 프레임에서 제거
•
용도: 특정 필드를 삭제하여 데이터의 크기를 줄이거나 보안 목적으로 사용
4.
Filter
•
설명: 지정된 조건에 따라 행을 필터링
•
용도: 데이터의 특정 조건을 만족하는 부분만 추출할 때 사용
5.
Join
•
설명: 두 개 이상의 데이터 프레임을 특정 키를 기준으로 조인
•
용도: 서로 다른 데이터 소스를 통합하여 분석할 때 사용
6.
ResolveChoice
•
설명: 데이터 타입 불일치나 선택적 필드 처리를 해결
•
용도: 데이터 타입 충돌을 해결하거나 NULL 값을 처리할 때 사용
7.
Relationalize
•
설명: 중첩된 구조의 데이터를 관계형 데이터로 변환
•
용도: JSON이나 복잡한 구조의 데이터를 SQL 쿼리로 쉽게 접근할 수 있는 형태로 변환할 때 사용
8.
Unnest
•
설명: 배열이나 리스트 형태의 중첩 데이터를 평탄화
•
용도: 중첩된 데이터 구조를 단순화하여 분석을 용이하게 할 때 사용
9.
GroupBy
•
설명: 특정 필드를 기준으로 데이터를 그룹화하고 집계
•
용도: 데이터의 통계적 분석이나 집계가 필요할 때 사용
10.
Map
•
설명: 사용자 정의 함수를 각 행에 적용하여 데이터를 변환
•
용도: 복잡한 변환 로직을 구현하거나 맞춤형 데이터 처리가 필요할 때 사용
11.
Explode
•
설명: 배열이나 리스트 형태의 필드를 여러 행으로 분해
•
용도: 중첩된 리스트 데이터를 개별 행으로 분리하여 처리할 때 사용
12.
RenameField
•
설명: 필드의 이름을 변경
•
용도: 스키마 변경이나 가독성을 위해 필드 이름을 수정할 때 사용
13.
SplitFields
•
설명: 하나의 필드를 여러 개의 필드로 분할
•
용도: 예를 들어, 하나의 문자열 필드에 여러 정보가 포함되어 있을 때 이를 개별 필드로 분리하여 분석을 용이하게 할 때 사용
14.
Convert
•
설명: 특정 필드의 데이터 타입을 변환
•
용도: 데이터 타입 불일치를 해결하거나, 분석 및 저장을 위해 데이터 타입을 변경할 때 사용
15.
DropNullFields
•
설명: NULL 값을 포함하는 모든 필드를 데이터 프레임에서 제거
•
용도: NULL 값이 있는 필드를 삭제하여 데이터의 일관성을 유지하거나, 분석 시 오류를 방지할 때 사용
16. FillMissingValues
•
설명: 누락된 값을 지정된 값으로 채움
•
용도: 데이터 누락으로 인한 분석 오류를 방지하기 위해 기본값이나 특정 값을 사용하여 NULL을 대체할 때 사용
17.
Sort
•
설명: 특정 필드를 기준으로 데이터를 정렬
•
용도: 데이터의 순서를 지정하여 정렬된 상태로 분석하거나 저장할 때 사용
18.
ApplyFunction
•
설명: 사용자 정의 함수를 데이터 프레임의 각 행에 적용
•
용도: 복잡한 변환 로직을 구현하거나 맞춤형 데이터 처리가 필요할 때 사용
Editer
•
GUI 환경이 아닌 스크립트 환경에서 작업을 할 수 있는
•
사실상 Visual ETL에서 전부 가능한 작업들이라 필자는 Visual ETL을 추천한다.
종류
•
Notebook
◦
ipynb 파일을 직접 업로드하거나 생성하여 관리
◦
우선 iam 정책 설정이 필요하다.
•
Script Editer
◦
spark/python 엔진을 선택하여 Script를 작성할 수 있도록 해주는 에디터
