.gif&blockId=11b00c82-b138-8050-a58b-dcbceda2ef8f)



CNN(Convolutional Neural Neetwork)
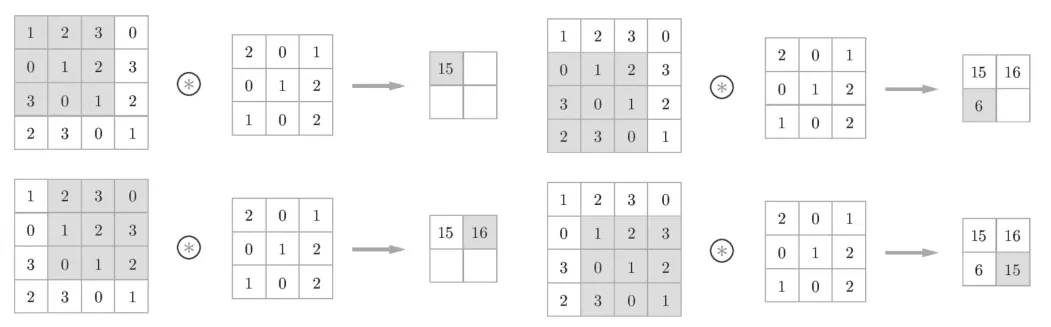
1D CNN
•
구성
◦
in_channels : input 의 feature 차원수
◦
out_channels: output 의 feature 차원수
◦
kernel_size : 입력길이를 얼마만큼 볼것인가
◦
stride: kernel 을 얼마만큼씩 이동할 것인가
◦
padding: 양방향으로 얼마만큼 패딩할 것인가
•
입력 텐서 shape
batch , feature dim , time step(입력 길이)

pooling layer
•
합성곱 layer의 출력 크기를 줄이거나 특정 출력 부분을 강조하기 위해 사용
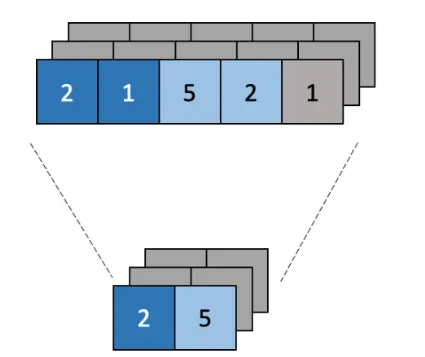
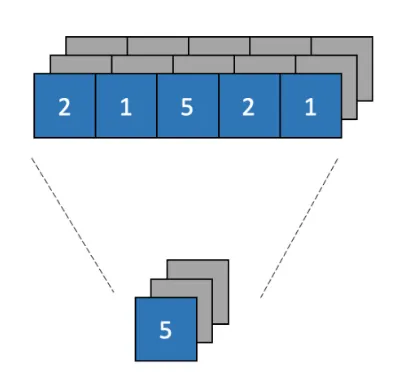
Global Pooling layer
•
pooling layer보다 급격하게 차원을 감소 시킨다.
•
linear layer 넣기 위해 차원을 변경하는 목적으로 쓴다.
1D 감정 분류 진행 과정
1. 데이터 준비 및 전처리
•
텍스트 수집: 감정 분류를 위해 리뷰, 소셜 미디어 게시물 등 텍스트 데이터를 수집한다.
•
라벨링: 각 텍스트에 대해 감정을 라벨링한다. 예를 들어, 긍정, 부정, 중립 등의 레이블을 부여한다.
•
토큰화 및 시퀀스 변환: 텍스트 데이터를 토큰화하여 단어 또는 토큰의 시퀀스로 변환한다.
•
패딩 처리: CNN의 입력으로 들어가는 모든 시퀀스는 동일한 길이를 가져야 하므로, 시퀀스를 특정 길이로 패딩하거나 잘라낸다.
2. 임베딩 층 (Embedding Layer)
•
임베딩 사용: 시퀀스를 임베딩 벡터로 변환한다. 임베딩 레이어는 단어의 의미적 정보를 밀집된 벡터로 표현하는 역할을 한다. 이 단계에서 사전 학습된 임베딩 (예: Word2Vec, GloVe)이나 학습 가능한 임베딩 레이어를 사용할 수 있다.
3. 1D CNN 적용
•
1D Convolution Layer: 임베딩 벡터 시퀀스를 1D 합성곱 계층에 통과시켜 특징을 추출한다. 1D CNN은 텍스트 내의 국소적인 패턴을 인식하는 데 효과적이며, 특정 단어 조합이 감정과 어떤 관련이 있는지 찾아낸다.
◦
커널: 커널 크기는 일반적으로 텍스트의 특정 수의 단어를 커버하도록 설정한다. 예를 들어, 3-5개의 단어를 묶어 패턴을 분석할 수 있다.
◦
필터: 여러 개의 필터를 사용하여 다양한 특징 맵(feature map)을 생성한다.
•
활성화 함수: ReLU와 같은 비선형 활성화 함수를 적용하여 모델의 비선형성을 부여한다.
4. 맥스 풀링 층 (Max Pooling Layer)
•
맥스 풀링: 합성곱의 결과를 다운샘플링하여 중요한 특징을 추출하고, 계산량을 줄인다. 텍스트 데이터에서 맥스 풀링은 각 필터의 가장 중요한 부분을 강조하는 역할을 한다.
5. 완전 연결층 (Fully Connected Layer)
•
Flattening: 풀링된 출력을 일차원 벡터로 펼친다.
•
완전 연결층: 펼친 벡터를 하나 이상의 완전 연결층에 입력한다. 감정의 종류(예: 긍정, 부정, 중립)에 따라 마지막 출력 층에서 클래스 개수만큼 뉴런을 사용한다.
•
출력층: 소프트맥스(Softmax) 함수를 사용하여 각 감정에 대한 확률을 예측한다.
6. 모델 학습
•
손실 함수: 감정 분류 문제는 일반적으로 다중 클래스 분류이므로 categorical cross-entropy를 사용한다.
•
옵티마이저: Adam이나 RMSprop과 같은 옵티마이저를 사용하여 모델을 학습시킨다.
•
에포크와 배치 크기: 일정한 에포크 동안 모델을 학습하고, 배치 크기를 적절히 조절하여 효율적인 학습을 수행한다.
7. 모델 평가 및 테스트
•
평가 지표: 정확도, 정밀도, 재현율, F1 스코어 등을 사용하여 모델의 성능을 평가한다.
•
테스트 데이터 평가: 학습되지 않은 테스트 데이터로 모델을 평가하여 감정 분류 성능을 검증한다.
8. 모델 개선
•
하이퍼파라미터 튜닝: 학습률, 필터 개수, 커널 크기 등을 변경하여 모델 성능을 향상시킨다.
•
정규화 및 드롭아웃: 과적합을 방지하기 위해 드롭아웃을 사용하거나 L2 정규화를 적용한다.
