


Seq2seq
•
Sequence to sequence는 sequence를 입력받아 sequence를 출력하는 모델
•
사용사례
◦
번역기 : "뉴진스의 하입보이요"라는 sequence를 받아 "Newjeans' Hypeboy"이라는 sequence를 출력한다.
◦
언어 번역: 영어를 한국어로 번역하거나 그 반대의 작업에 사용된다.
◦
챗봇: 사용자와 자연스럽게 대화할 수 있는 챗봇을 만드는 데 활용된다.
◦
음성 인식: 음성을 텍스트로 변환하는 데 사용된다.
◦
텍스트 요약: 긴 문장을 짧게 요약하는 작업에 활용된다.
•
장점과 한계
◦
장점
▪
긴 문장이나 복잡한 구조도 효과적으로 처리할 수 있다.
▪
학습을 통해 점점 더 정확한 결과를 만들어낼 수 있다.
◦
한계
▪
매우 긴 시퀀스의 경우, 인코더가 모든 정보를 제대로 기억하지 못할 수 있다.
▪
번역의 정확도는 학습 데이터의 품질에 크게 의존한다.
구성요소
•
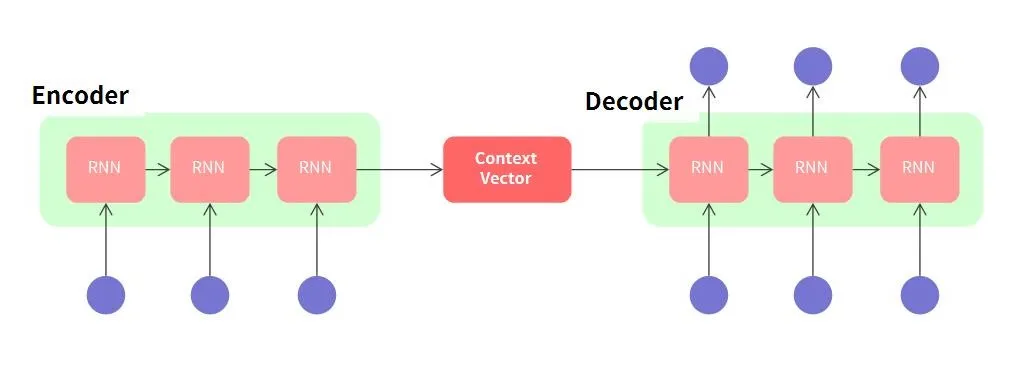
Seq2seq 모델은 주로 두 개의 신경망으로 구성된다.
•
첫 번째는 인코더이고, 두 번째는 디코더이다.
◦
인코더와 디코더의 RNN은 성능상 LSTM, GRU로 변경될 수 있다.
◦
인코더의 역할
▪
인코더는 입력된 시퀀스를 하나씩 읽어들이면서 그 의미를 파악하려고 노력한다.
▪
예를 들어, 영어 문장을 입력받으면, 인코더는 각 단어를 분석하여 전체적인 의미를 이해한다.
▪
이렇게 이해한 정보는 벡터라는 숫자의 집합으로 저장된다.
◦
디코더의 역할
▪
디코더는 인코더가 저장한 벡터를 바탕으로 새로운 시퀀스를 만든다.
▪
영어 문장을 한국어로 번역하는 경우, 디코더는 저장된 정보를 사용하여 올바른 한국어 문장을 하나씩 생성한다.
▪
이 과정을 통해 자연스러운 번역이 완성된다.
인코더 (Encoder)
•
입력된 문장을 이해하는 역할
•
인코더는 단어들을 숫자로 변환한 후, 이 숫자들을 사용하여 문장의 의미를 하나의 벡터로 저장(압축)한다.
영어 문장 "I am a student"를 입력받으면, 인코더는 이 문장의 각 단어를 하나씩 분석하여 전체적인 의미를 파악하려고 노력한다.
컨텍스트 벡터 (Context Vector)
•
인코더가 입력된 문장을 처리한 후 생성되는 중요한 정보의 집합이다.
•
이는 입력 문장의 의미를 하나의 숫자 벡터로 압축한 것이다.
•
컨텍스트 벡터는 문장의 전체적인 의미를 담고 있기 때문에, 디코더가 정확하고 자연스러운 출력을 만들 수 있도록 도와준다.
인코더가 "I am a student"라는 문장을 처리하면, 이 문장의 의미를 담은 컨텍스트 벡터가 만들어진다.
디코더 (Decoder)
•
인코더가 만든 컨텍스트 벡터를 바탕으로 새로운 문장을 생성하는 역할
•
디코더는 먼저 시작 단어를 생성하고, 그 다음에 올 단어를 예측하면서 순서대로 문장을 완성해 나간다.
•
첫 RNN 은닉층 벡터로 Context Vector를 사용한다. 그리고 첫 RNN은 <sos>를 입력으로 받는다. 마지막 RNN은 <eos>를 출력한다. <sos>와 <eos>는 시작과 끝을 알리기 위해 약속된 벡터다.
인코더가 "I am a student"를 처리하여 컨텍스트 벡터를 만들었다면, 디코더는 이 벡터를 사용하여 한국어로 "나는 학생이다"라는 문장을 하나씩 만들어낸다.
예측 과정

•
t시점의 RNN 입력은 t−1시점 출력이 된다. 앞에서 예측한 정보를 바탕으로 연속된 결과를 예측한다.
학습 과정
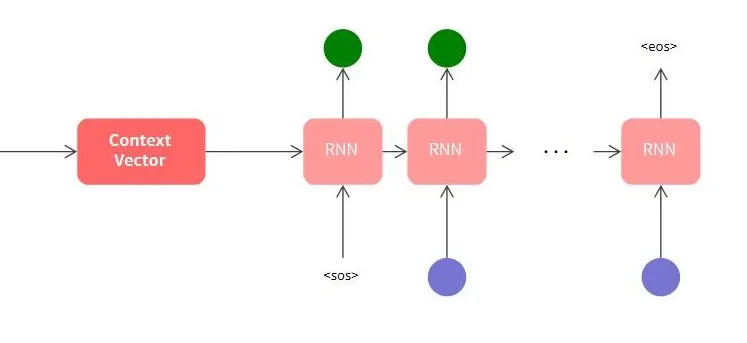
•
Decoder 입력으로 정답 sequence를 입력한다.
◦
이러한 학습 방법을 Teacher forcing이라고 한다.
•
예측과정에서 봤듯이 Decoder는 이전 RNN에서 예측한 결과를 바탕으로 다음 RNN 결과를 예측한다.
→ 중간에 잘못된 출력이 발생하면 연쇄적으로 잘못된 출력을 만들게 된다.
→ → 정답 데이터를 입력해 정답에 가깝게 예측할 수 있도록 도와준다.
•
실제 모델은 단어를 Embedding하는 과정부터 Decoder에서 Softmax를 거쳐 값을 예측하는 과정 등 일부 연산이 추가된다.
