EfficientNet 설명
•
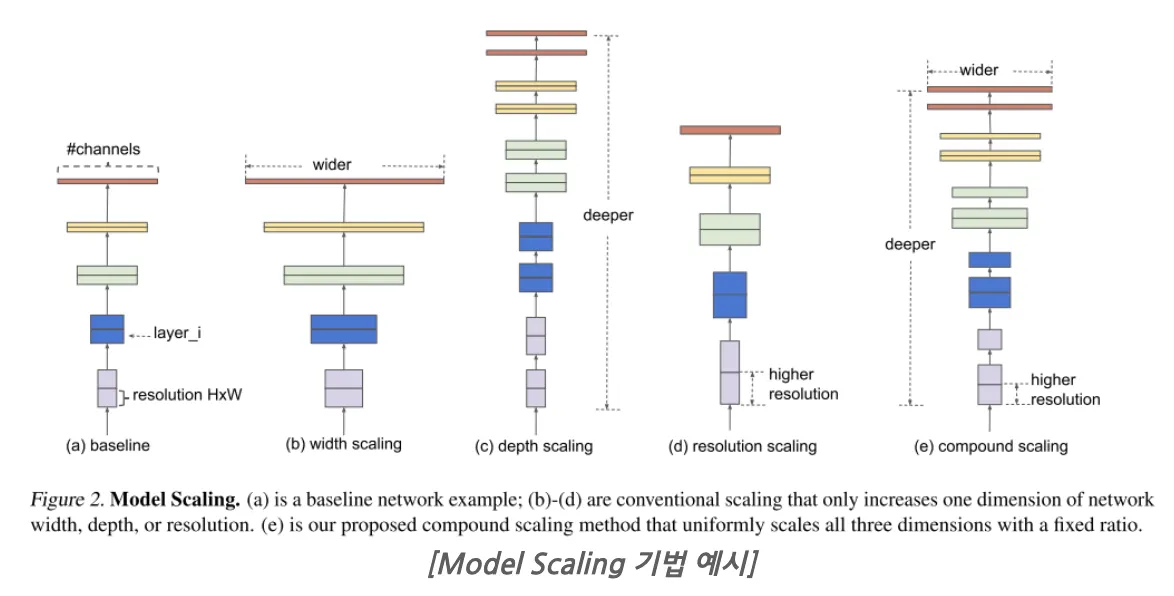
한정된 자원으로 최대의 효율을 내기 위한 방법으로 model scaling(depth, width, resolution)의 크기를 조절한다.
•
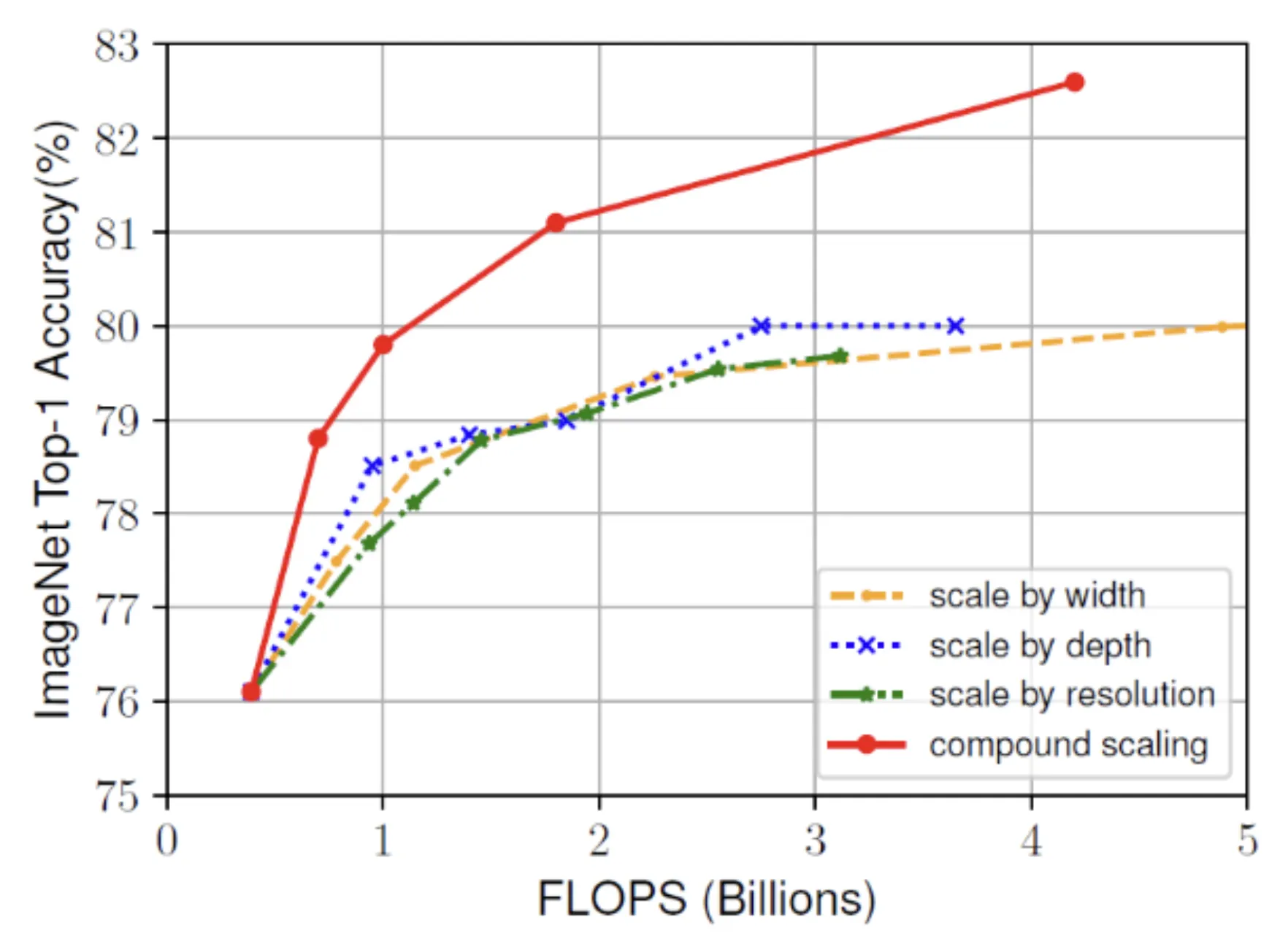
기존에는 이 세 가지를 수동으로 조절하였다면, EfficientNet은 model scaling 방법으로 compound scaling 방법을 제안
•
이 방법을 통해 기존 ConvNet보다 8.4배 작으면서, 6.1배 빠르고 더 높은 정확도를 갖는다.
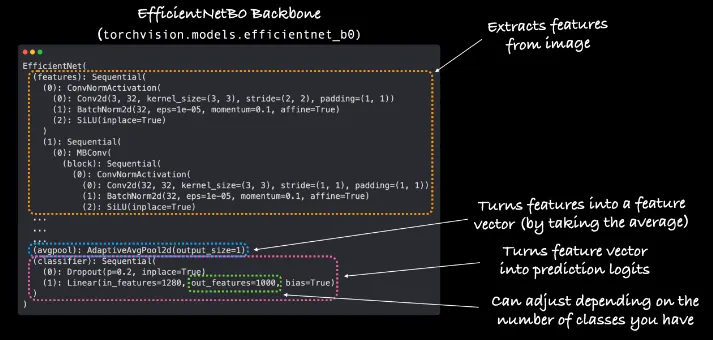
torchvision.models.efficientnet_b0
•
features: A collection of layers
•
avgpool: features layers의 결과값을 평균하여 feature vector로 변환
•
classifier: feature vector를 최종 결과를 나타내는 output classes vector로 변환
•
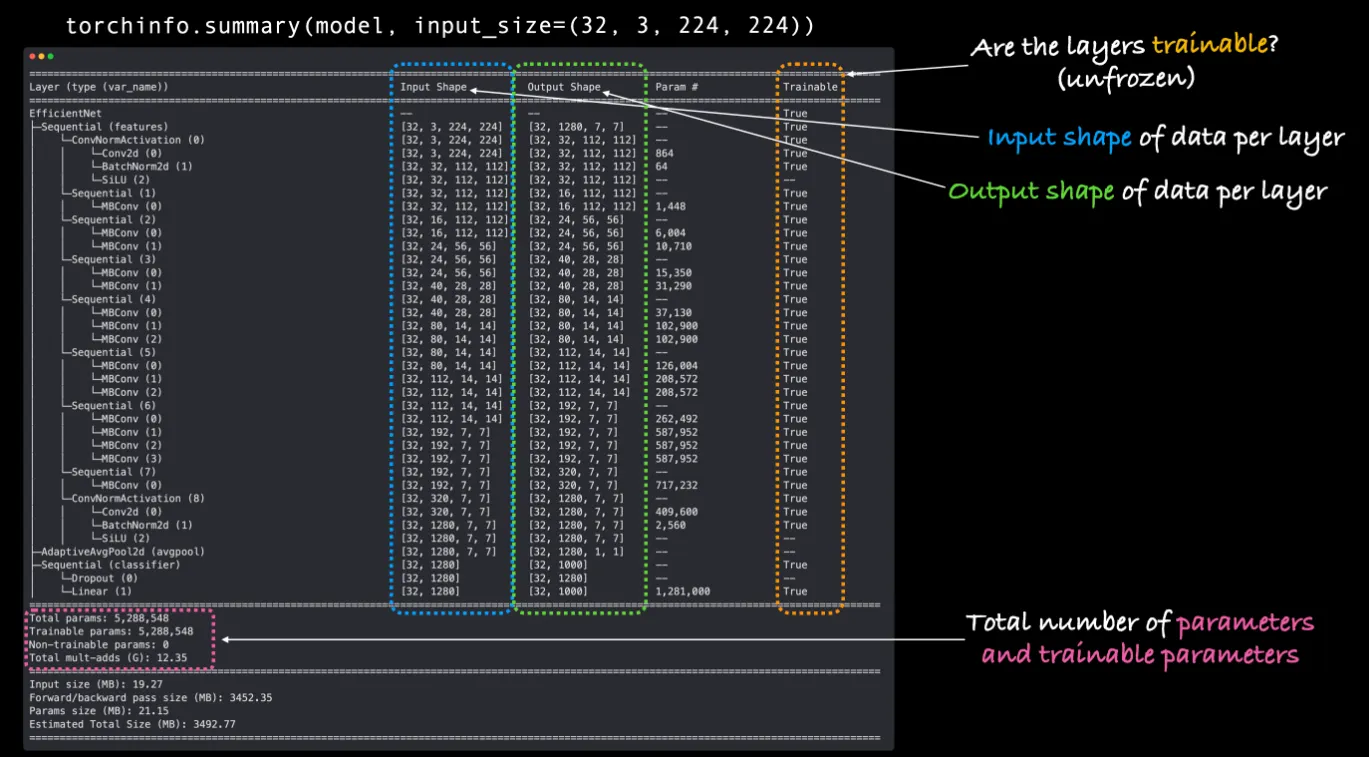
Summary
# Print a summary using torchinfo (uncomment for actual output)
summary(model=efficientnet_model,
input_size=(32, 3, 224, 224), # make sure this is "input_size", not "input_shape"
# col_names=["input_size"], # uncomment for smaller output
# trainable -> requires_grad
col_names=["input_size", "output_size", "num_params", "trainable"],
col_width=20,
row_settings=["var_names"]
)
Python
복사
FineTuning
output layer 변경
•
학습용 layers들은 고정을하여 더 이상 학습을 하지 않도록 하고, 마지막 결과를 내보내는 output layer만 추가 학습을 시켜 변경시키는 방법
•
The process of transfer learning usually goes: freeze some base layers of a pretrained model(typicall the features section) and then adjust the output layers (also called head/classifier layers) to suit your needs.

•
features의 layers는 더이상 학습을 하지 않도록 고정!
•
code
# Freeze all base layers in the "features" section of the model (the feature extractor) by setting requires_grad=False
for param in efficientnet_model.features.parameters():
param.requires_grad = False
# Print a summary using torchinfo (uncomment for actual output)
summary(model=efficientnet_model,
input_size=(32, 3, 224, 224), # make sure this is "input_size", not "input_shape"
# col_names=["input_size"], # uncomment for smaller output
# trainable -> requires_grad
col_names=["input_size", "output_size", "num_params", "trainable"],
col_width=20,
row_settings=["var_names"]
)
# -- 기존 classifier는 1000개의 사물을 구분하게 하는 로직 --
# (classifier): Sequential(
# (0): Dropout(p=0.2, inplace=True)
# (1): Linear(in_features=1280, out_features=1000, bias=True)
# 이것을 pizza, steak, sushi를 구분할 수있게 수정하고 학습을 시키면 된다.
# Set the manual seeds
torch.manual_seed(42)
torch.cuda.manual_seed(42)
# Get the length of class_names (one output unit for each class)
output_shape = len(class_names)
# Recreate the classifier layer and seed it to the target device
efficientnet_model.classifier = torch.nn.Sequential(
torch.nn.Dropout(p=0.2, inplace=True),
torch.nn.Linear(in_features=1280,
out_features=output_shape, # same number of output units as our number of classes
bias=True)).to(device)
# Summary
# # Do a summary *after* freezing the features and changing the output classifier layer (uncomment for actual output)
summary(efficientnet_model,
input_size=(32, 3, 224, 224), # make sure this is "input_size", not "input_shape" (batch_size, color_channels, height, width)
verbose=0,
col_names=["input_size", "output_size", "num_params", "trainable"],
col_width=20,
row_settings=["var_names"]
)
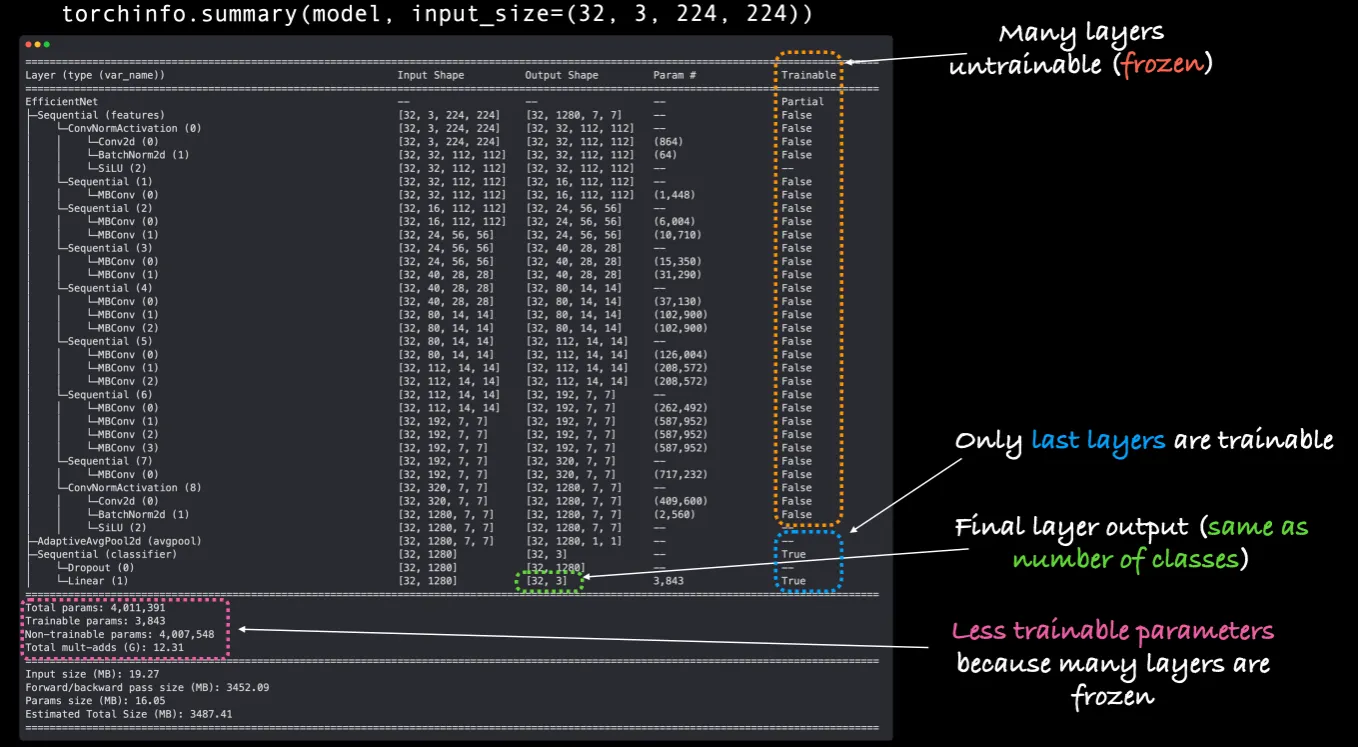
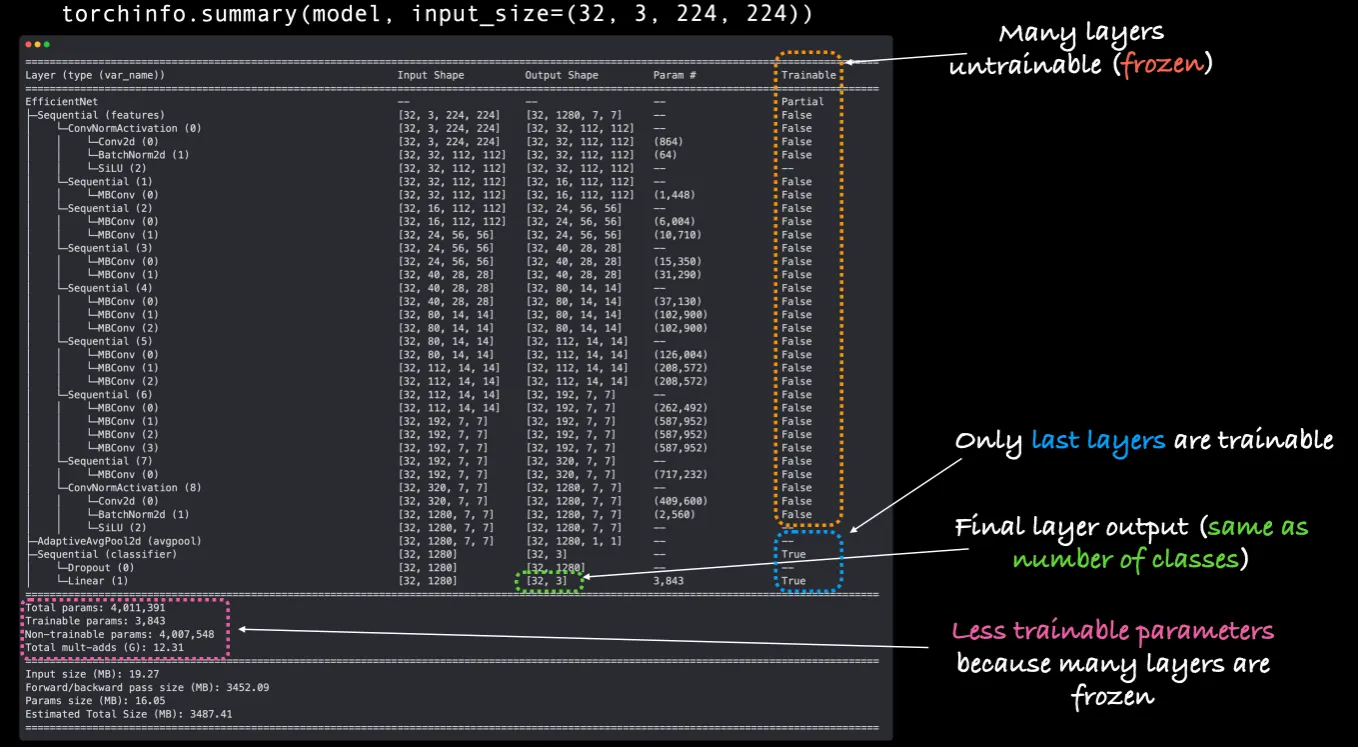
# Total params: 4,011,391
# Trainable params: 3,843
# Non-trainable params: 4,007,548
# Total mult-adds (G): 12.31
# =================
# Forward/backward pass size (MB): 3452.09
# Params size (MB): 16.05
# Estimated Total Size (MB): 3487.41
Python
복사
•
생각해보자:
◦
Trainable column: feature layers는 변경되지 않고 학습에 대한 부분만(requires_grad=False) 변경되었다.
◦
Output shape of classifier: 결과 모양이 [32, 1000]에서 [32, 3]으로 변경되었다. 또한 학습을 진행하는 것으로 표현되어 있다.
◦
Less trainable parameter: 기존 학습용 파라미터 수가 5,288,548에서 4,007,548로 줄어들었다.
•
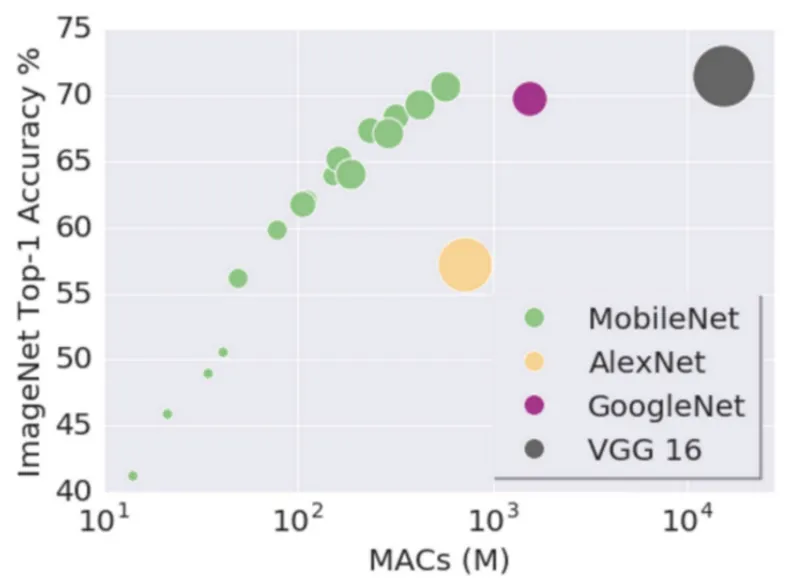
MobileNet 모델의 key idea는 Depth-wise Separable Convolution을 통해 연산량을 줄였다.
•
따라서 다른 기존 모델보다 layers는 많지만 전체 연산량을 획기적으로 줄임으로써 고성능이 아닌 환경에서도 작동할 수 있는 알고리즘
MobileNet의 필요성
고성능의 환경
•
데이터 센터 환경에서는 고성능의 CPU가 매우 많이 있기 때문에 연산 처리 성능이 매우 고성능이고, 고성능의 그래픽 카드(GPU) 다수를 가지고 있을 수 있으며, 메모리도 대용량을 사용할 수 있다.
•
또한 전력 공급이 지속적으로 이루어지기 때문에 전원을 아끼기 위해 성능을 낮추는 것 보다는 더 높은 퍼포먼스에 초점을 두는 경우가 많다.
•
이런 컴퓨터 환경에서는 어떤 모델을 넣더라도 잘 작동을 할 것
고성능이 아닌 환경
•
실생활에서 사용하는 AI 서비스들은 데이터 센터 또는 슈퍼 컴퓨터보다는 자동차, 드론, 스마트폰과 같은 환경에서 잘 작동이 되어야 하는 경우가 많아지고 있다.
•
이런 저성능의 환경에서 잘 작동할 수 있으며, 성능도 보장이되어야 하는 요구들이 늘어나면서 딥러닝 모델 경량화(MobileNet) 알고리즘이 발전하게 되었다.
MobileNet 설명
•
CNN(Standard Convolution) 연산량
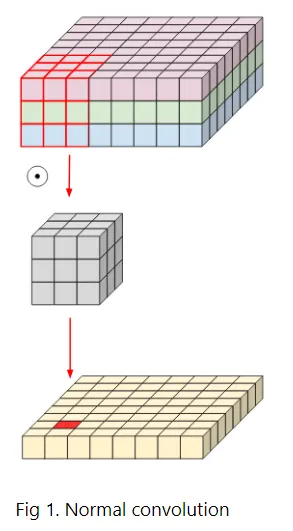
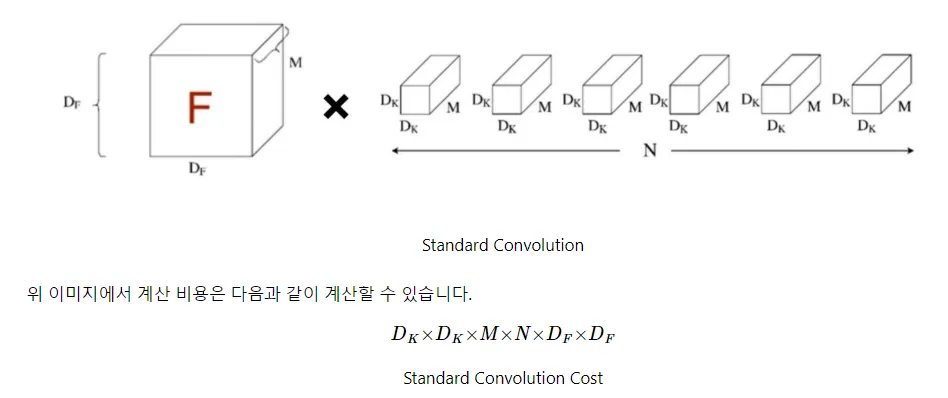
•
MobileNet(Depth-wise Separable Convolution) 연산량
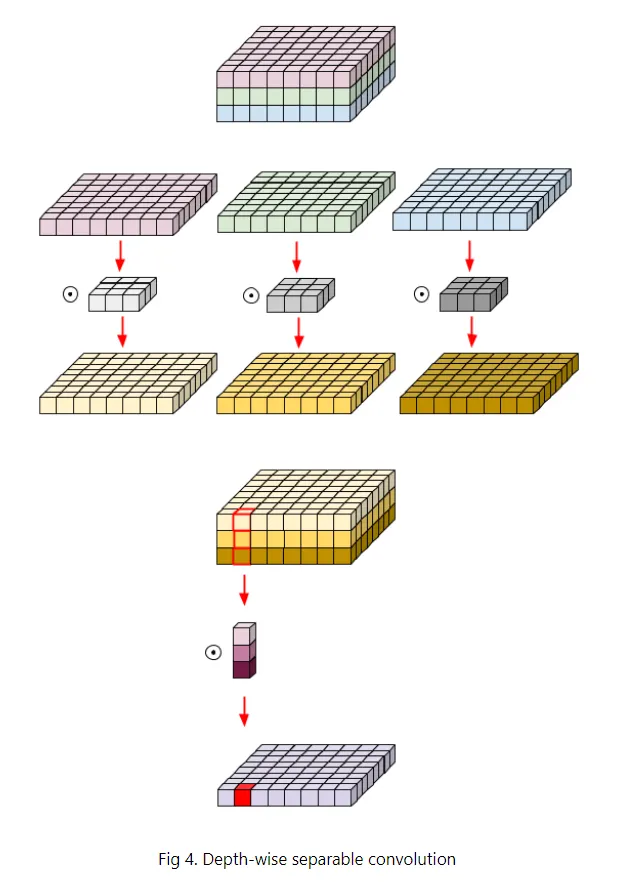

•
Depthwise Convolution 연산량
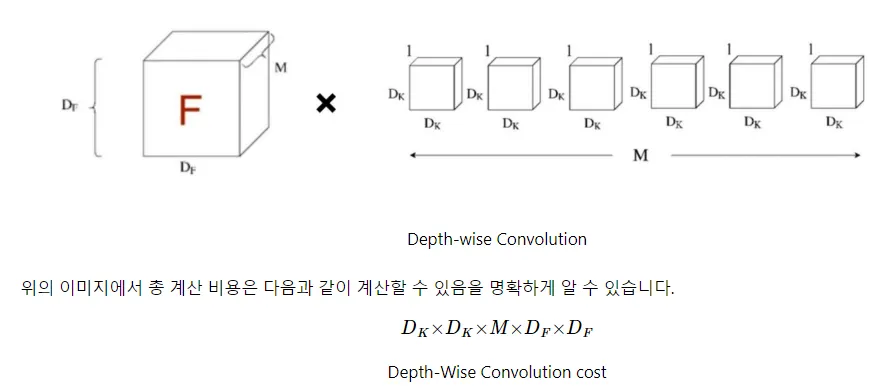
•
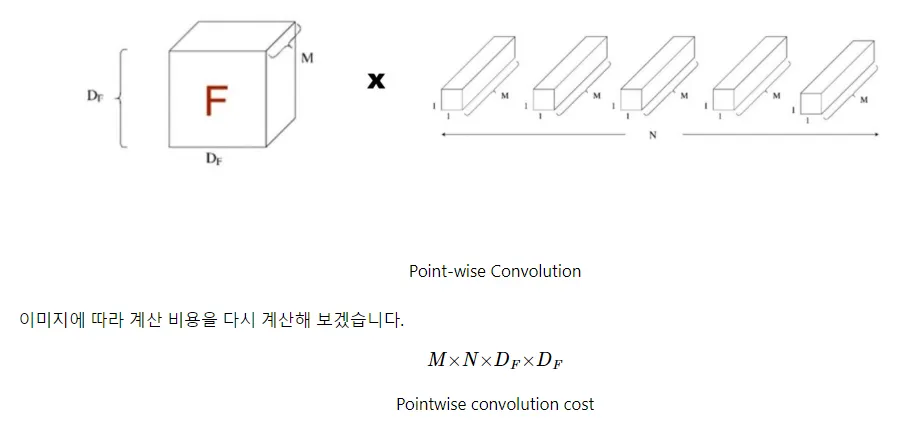
Pointwise Convolution 연산량