



문제
값은 300초가 주어지기 때문에 트래픽이 많지 않거나 커넥션을 오래 유지할 필요가 없다면 이 시간만큼 Fargate인스턴스를 더 사용하는 셈 그래서 비용 및 시간 문제에 직면함
문제 설명

컨테이너 인스턴스가 DRAINING으로 설정된 경우 중지하는 데 시간이 오래 걸리는 Amazon ECS 작업
문제 설명
•
◦
컨테이너 인스턴스에 새 작업을 배치하도록 예약하는 것을 방지
◦
RUNNING 상태인 컨테이너 인스턴스의 작업 중지
•
구성 매개 변수 또는 작업 문제로 인해 작업이 RUNNING 상태에서 중단되거나 STOPPED 상태로 이동하는 데 시간이 더 오래 걸릴 수 있다.
•
이러한 문제를 해결하려면 다음 옵션을 고려해 보자.
◦
DeploymentConfiguration 파라미터가 올바르게 설정되었는지 확인
◦
등록 취소 지연 값이 올바르게 설정되었는지 확인
◦
ECS_CONTAINER_STOP_TIMEOUT 값이 올바르게 설정되었는지 확인
해결 방법
•
Draining을 해결하는 방법은 여러가지가 있지만 필자는 ALB Target Group Draining 해결 방법을 사용함.
•
ALB Target Group Draining 해결
◦
타겟그룹의 Draining에 걸리는 시간은 “Deregistration delay”항목에서 수정할 수 있다.
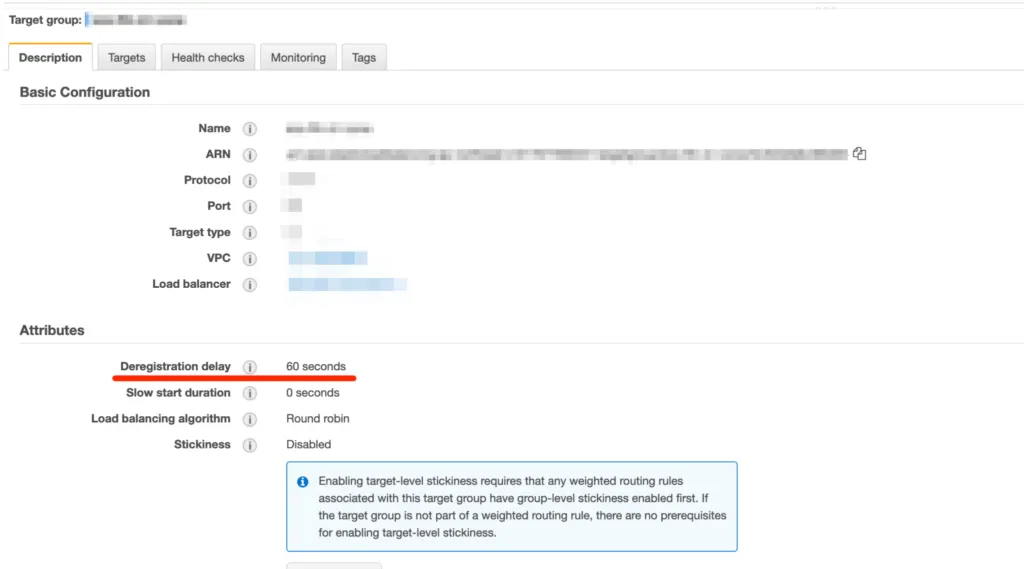
•
DeploymentConfiguration 파라미터가 올바르게 설정되었는지 확인
1.
Amazon ECS 콘솔을 엽니다.
2.
탐색 창에서 클러스터를 선택한 다음 컨테이너 인스턴스가 드레이닝되는 클러스터를 선택합니다.
3.
ECS 인스턴스 탭을 선택한 다음 상태 섹션에서 DRAINING을 선택합니다.
4.
컨테이너 인스턴스를 선택한 다음 드레이닝되거나 드레이닝되는 데 시간이 오래 걸리는 작업에 대한 서비스를 찾습니다.
5.
서비스 탭을 선택하고 서비스를 선택한 다음 배포를 선택합니다.
6.
minimumHealthyPercent 및 maximumPercent 값을 확인합니다.참고: RUNNING 상태인 컨테이너 인스턴스의 서비스 작업이 서비스의 배포 구성 파라미터(minimumHealthyPercent and maximumPercent)에 따라 중지되고 대체됩니다.
•
등록 취소 지연 값이 올바르게 설정되었는지 확인
중요: 다음 단계는 Application Load Balancer 또는 Network Load Balancer를 사용하는 서비스에만 적용됩니다. 서비스에서 Classic Load Balancer를 사용하는 경우 Connection Draining 값을 확인합니다.
1.
Amazon ECS 콘솔을 엽니다.
2.
탐색 창에서 클러스터를 선택한 다음 컨테이너 인스턴스가 드레이닝되는 클러스터를 선택
3.
서비스 탭을 선택한 다음 스택이 RUNNING에 멈춘 서비스를 선택
4.
대상 그룹 이름을 선택
5.
세부 정보 탭에서 아래로 스크롤한 다음 등록 취소 지연 확인란을 선택
•
ECS_CONTAINER_STOP_TIMEOUT 값이 올바르게 설정되었는지 확인
2.
docker inspect ecs-agent --format '{{json .Config.Env}}' 명령을 실행
3.
ECS_CONTAINER_STOP_TIMEOUT 값이 있는지 확인
참고: ECS_CONTAINER_STOP_TIMEOUT : Amazon ECS가 컨테이너를 종료하기 전에 대기하는 시간을 정의하는 ECS 컨테이너 에이전트 파라미터
기간은 작업이 중지될 때 계산되기 시작
2단계에서 명령을 실행한 후 출력에 ECS_CONTAINER_STOP_TIMEOUT 파라미터가 표시되지 않는 경우 Amazon ECS는 기본값인 30초를 사용하고 있는 것이다.
•
