


Transformer - JUST ATTENTION
•
2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델
•
seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션(Attention)만으로 구현
•
이 모델은 RNN을 사용하지 않고, 인코더-디코더 구조를 설계하였음에도 번역 성능에서도 RNN보다 우수한 성능을 보인다.
•
어텐션 과정 한번만 사용하는 것이 아니라 여러 레이어를 거쳐서 반복하도록 만듦
•
Pytorch에서는 nn.TransformerEncoder을 이용한 단일 컴포넌트를 이용하여 쉽게 Transformer 모델링을 할 수 있다.

Transformer와 Seq2Seq의 차이점
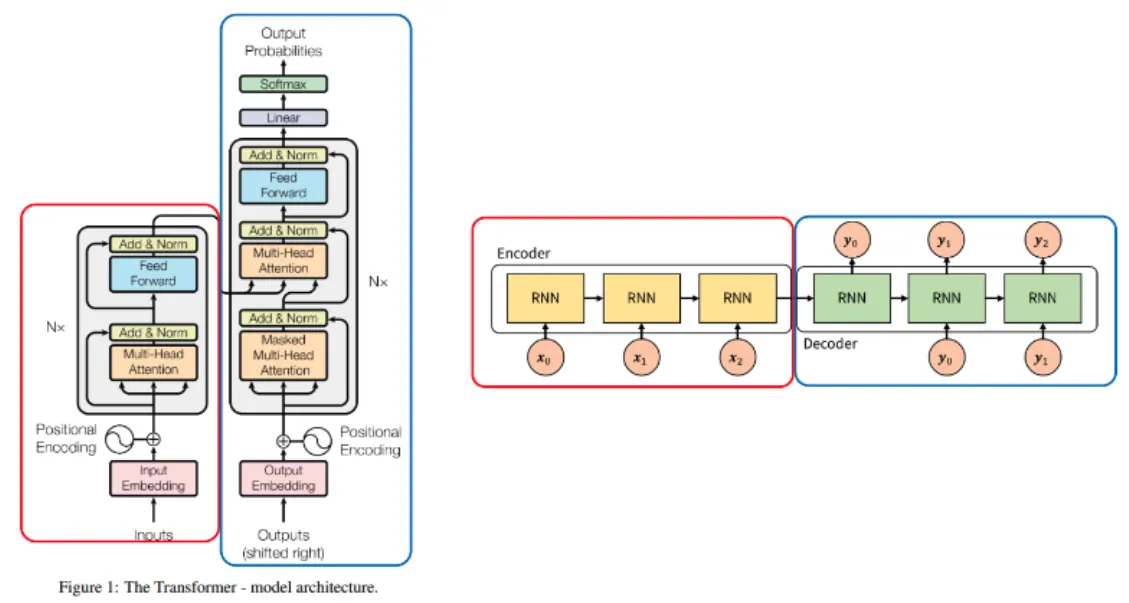
비슷한 점
•
Seq2Seq의 경우 Encoder(빨간색)와 Decoder(파란색) 형태로 이루어져 있고, 각 Encoder, Decoder에는 RNN을 사용하였다.
그리고 Encoder에서 Decoder로 정보를 전달할 때, 가운데 화살표인 context vector에 Encoder의 모든 정보를 저장하여 Decoder로 전달한다.
•
Transformer의 경우에도 Encoder(빨간색)와 Decoder(파란색) 형태가 있고 Encoder 끝단 부분에 Decoder로 전달되는 화살표가 있어서 Seq2Seq와 유사한 구조를 가진다.
차이점
•
가장 큰 차이점은 Seq2Seq에서는 Encoder 연산이 끝난 후에 Decoder 연산이 시작된다면, Transformer는 Encoder와 Decoder가 같이 연산이 일어난다는 차이점이 있다.
•
Seq2Seq에서는 Attention을 이용하기 때문에 RNN을 사용한다면, Transformer는 Self-Attention을 사용하기 때문에 RNN을 사용하지 않는다.
요약
•
인코더와 디코더 N 번 만큼 중첩되어 사용하도록 만듦.
•
Seq2Seq 구조에서는 인코더 / 디코더 하나에서 각 RNN 이 t개의 시점을 가지는 구조. 트랜스포머 논문에서는 인코더, 디코더 개수 6개씩 사용
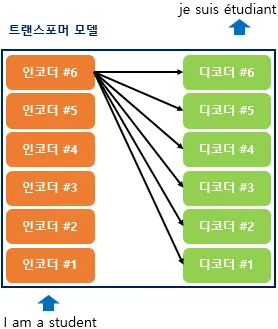
인코더/디코더가 6개씩 존재하는 트랜스 포머 구조
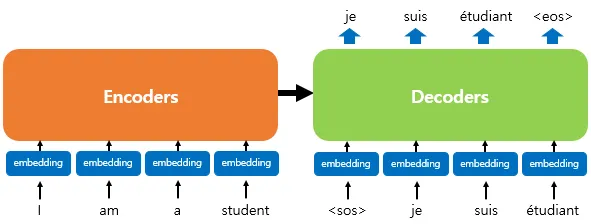
인코더로부터 정보를 전달받아 디코더가 출력 결과를 만들어내는 트랜스포머 구조
트랜스포머(Transformer)의 주요 하이퍼파라미터
•
아래에서 정의하는 수치는 트랜스포머를 제안한 논문에서 사용한 수치로 하이퍼파라미터는 사용자가 모델 설계시 임의로 변경할 수 있는 값들이다.
1.
: Embedding Size (임베딩 벡터 차원 크기) = 512
•
트랜스포머의 인코더와 디코더에서의 입력과 출력의 차원 크기
•
각 토큰을 벡터화한 임베딩 벡터의 차원
•
각 인코더와 디코더는 이 크기의 벡터를 사용하여 다음 레이어로 신호
•
의미 : 해당 값이 클수록 모델이 더 많은 정보를 처리할 수 있지만, 메모리 사용량과 계산량이 증가
2.
: 트랜스포머의 인코더와 디코더 레이어 수 = 6
•
트랜스포머는 여러 개의 인코더와 디코더 블록으로 구성되며, 일반적으로 이 수가 클수록 모델의 복잡도가 높아진다.
•
의미 : 레이어 수가 많으면 더 깊은 네트워크를 형성할 수 있어 복잡한 패턴을 학습할 수 있지만, 과도한 레이어는 오버피팅의 위험을 증가시킴.
3.
: 멀티헤드 셀프 어텐션에서 사용되는 헤드(병렬)의 개수 = 8
•
각 헤드는 병렬로 다른 부분의 입력에 주의를 기울여 다양한 정보를 추출
•
트랜스포머는 이 결과들을 병합하여 하나의 출력으로 결합
•
이 때 병렬의 개수를 의미
•
의미 : 더 많은 어텐션 헤드를 사용하면 더 다양한 관점을 학습할 수 있지만, 메모리 사용량과 계산 비용이 늘어난다.
4.
: 피드 포워드(순방향) 신경망 내의 은닉층 크기 = 2048
순방향 신경망(FNN) : 입력값이 출력까지 한 방향으로 전달되는 구조를 가진 인공 신경망
•
트랜스포머에서 어텐션 블록 이후에는 피드포워드 신경망이 위치
•
이 신경망은 더 큰 차원의 은닉층을 사용해 입력을 변환하고 처리
•
의미: 이 값이 클수록 피드포워드 네트워크가 더 복잡한 연산을 수행할 수 있지만, 연산 비용과 메모리 요구 사항이 증가한다.
Transformer 구조
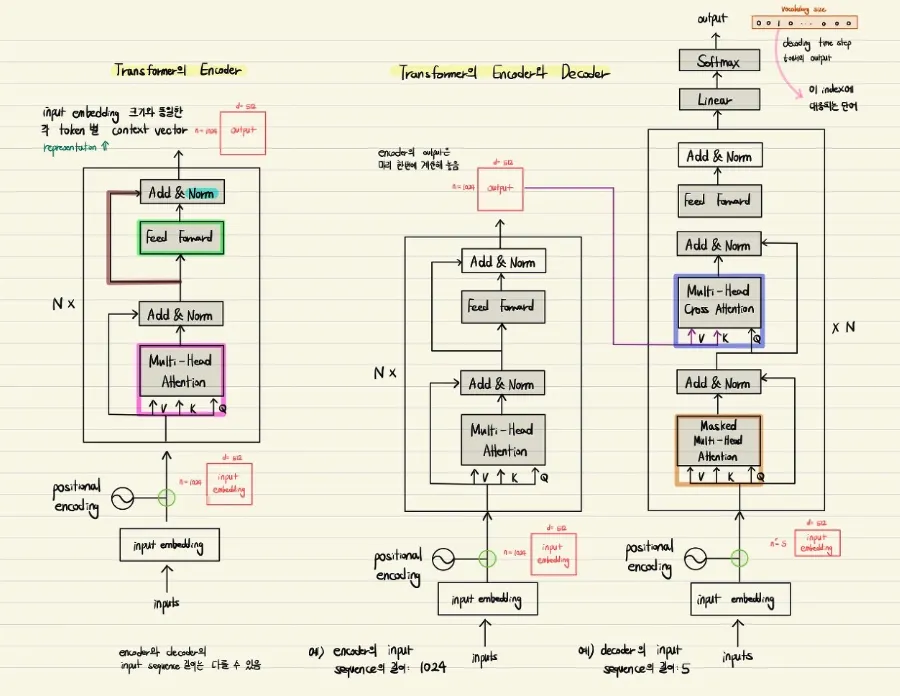
구조 - 임베딩&인코딩
Input / Output (입력값 임베딩)
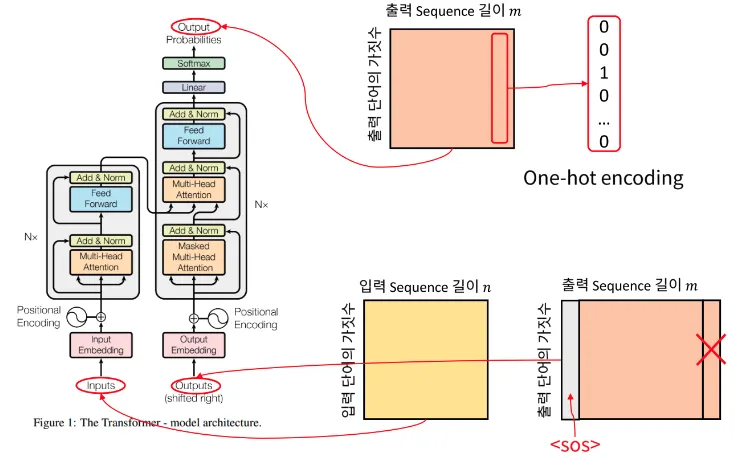
•
입력 값 임베딩
◦
각 단어는 One-hot Encoding 형태의 백터로 나타내어진다.
◦
따라서 열벡터가 한 단어에 해당하며 열 벡터의 길이
⇒ 즉, 행렬에서 행의 크기는 입력 단어의 가짓수와 관련이 있다.
◦
어떤 단어 정보를 네트워크에 넣기 위해서는 일반적으로 '임베딩' 과정을 거침
⇒ 맨 처음에 들어가는 입력 차원 자체는 단어의 개수와 같기 때문.
◦
이는 차원이 많을 뿐만 아니라 각각의 정보들은 원 핫 인코딩 형태로 표현되기 때문에 '임베딩' 과정을 거쳐 더욱 더 작은 차원으로 표현 - continuous 한 값 (실수 값) 으로 표현
◦
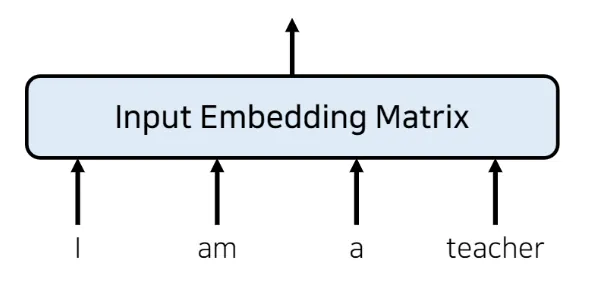
예시
▪
I am a teacher 문장이 들어오면 이를 input embedding matrix 로 만들기이 입력 임베딩 행렬은 단어의 개수만큼 행의 크기를 가짐 (즉, 여기선 4개의 행)
▪
각각의 열 데이터는 임베딩 차원과 같은 크기의 데이터가 담긴 배열 사용
▪
임베딩 크기(차원: Dimension)은 모델 아키텍쳐 만드는 사람이 임의로 설정
(이 트랜스포머 논문에서는 512 값 사용)

seq2seq 와 같은 RNN 기반 아키텍쳐를 사용한다고 하면, RNN 을 사용하는 것만으로도 각각의 단어가 RNN 에 들어갈 때 순서에 맞게 들어가기 때문에 자동으로 각각의 hidden state 값은 순서에 대한 정보를 갖게 됨.
RNN 이 자연어 처리에서 유용했던 이유 : 단어의 위치에 따라 단어를 순차적으로 입력받아서 처리하기 때문에, 각 단어의 위치 정보를 가질 수 있었기 때문
•
출력: 입력과 다르게 출력은 2가지의 Output이 표시되어 있다.
◦
위쪽에 있는 Output은 Transformer 모델을 통해 출력되는 실제 출력이고 아래쪽에 있는 Output은 Trnasformer에서 만들어낸 Output을 다시 입력으로 사용되는 것을 나타낸다.
◦
다시 입력되는 Output의 첫 열벡터는 <sos>가 되고 X 표시가 되어있는 마지막 열벡터는 <eos>이므로 큰 의미는 없는 벡터이다.
◦
따라서 shifted right라고 적힌 부분은 Output에서 하나씩 오른쪽으로 밀려서 다시 입력으로 들어가는 구조로 이해하면 된다.
Word Embedding
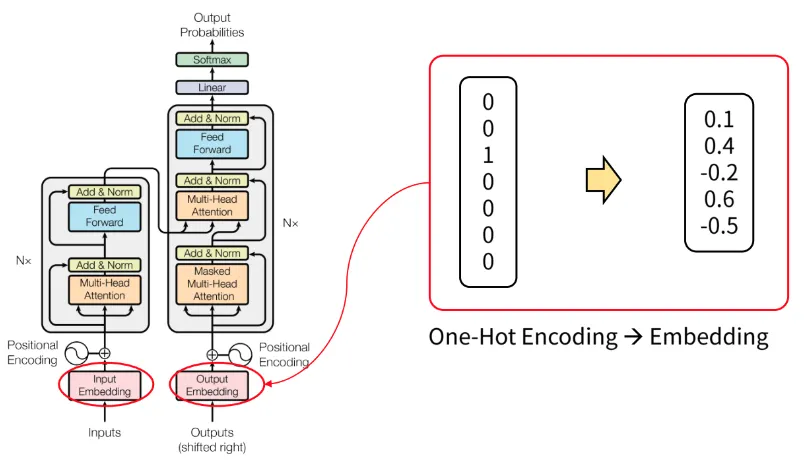
•
위 그림과 같이 one-hot encoding 벡터를 실수 형태로 변경하면 차원의 수를 줄일 수 있다.
•
embedding의 경우 0을 기준으로 분포된 형태로 표현된다.
포지셔널 인코딩 (positional encoding)
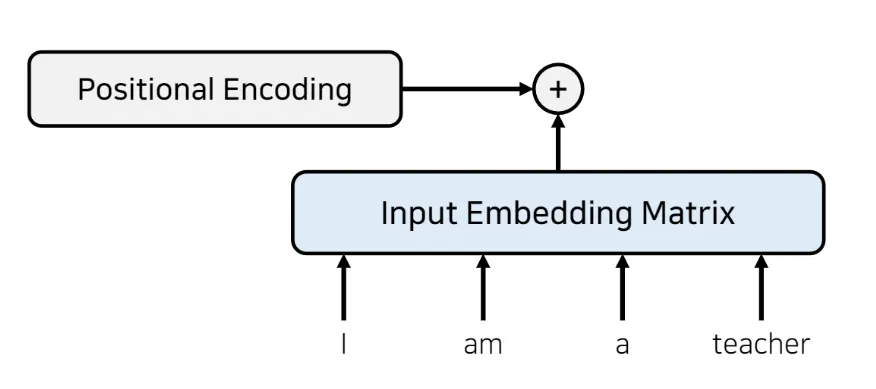
트랜스포머와 같이 RNN 사용하지 않아서 단어 입력을 순차적으로 받는 방식이 아니라면, 문장 안의 각 단어들에 대해 어떤 단어가 앞에 오고 어떤 단어가 뒤에 오는지에 대한 정보를 따로 제공해야 함 = 위치 임베딩
•
따라서 트랜스포머는 'positional encoding' 을 통해 단어의 위치 정보(위치 임베딩)를 인코딩단어의 위치 정보를 얻기 위해 각 단어의 임베딩 벡터에 위치 정보들을 더함

•
Input Embedding Matrix 와 같은 크기(dimension)를 가지는 별도의 (위치 정보를 가지고 있는) 인코딩 정보를 넣어서 각각 element wise 로 더해줌 (크기가 같기 때문에 element wise 더하기 가능)
•
별도의 위치 정보를 가지고 있는 포지셔널 인코딩 값을 구하기 위해 아래 두 개의 함수 사용
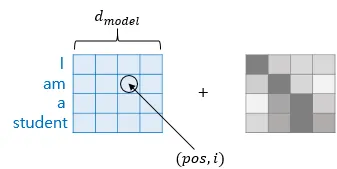
◦
입력 임베딩의 차원이 d라 할 때, p번째 단어(token)의 positional encoding
구조 - 어텐션(Attentions)
Transformer에서 사용되는 3가지 어탠션
•
Self(Multi-head) Attention 사용 Layer 구조
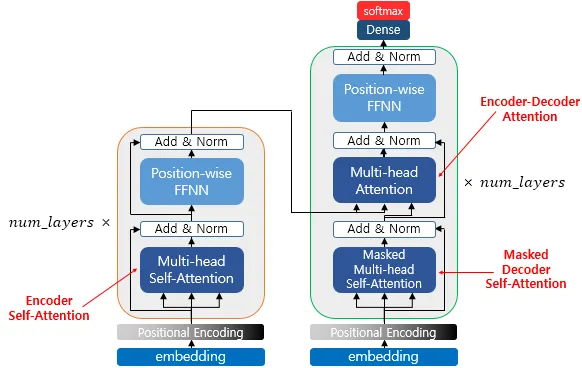
•
인코더에서 동작하는 Attention
1.
Encoder Self-Attention
•
인코더에서 이루어짐
•
self-attention : query, key, value가 같음 (벡터의 값이 같은 것이 아니라, 벡터의 출처가 같음)
•
인코더의 self-attention : Query = Key = Value
•
디코더에서 동작하는 Attention
2.
Masked Decoder Self-Attention
•
디코더의 masked self-attention : Query = Key = Value : 디코더 벡터
3.
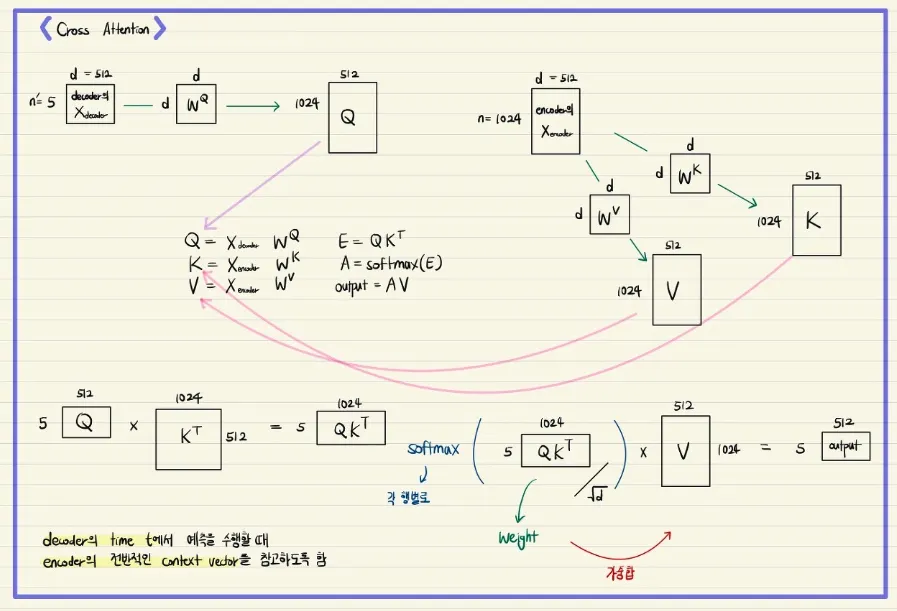
Encoder-Decoder Attention
•
디코더의 encoder-decoder attention :
Query : 디코더 벡터
Key = Value : 인코더 벡터
<Seq2Seq with attention의 경우>
Q = Query : 시점의 디코더 셀에서의 은닉 상태(hidden state)
K = Keys : 모든 시점의 인코더 셀의 은닉 상태(hidden state)들
V = Values : 모든 시점의 인코더 셀의 은닉 상태(hidden state)들
→
<시점은 계속 변화하면서 반복적으로 쿼리가 수행 ⇒ 시점 t를 전체 시점으로 일반화>
Q = Querys : 모든 시점의 디코더 셀에서의 은닉 상태(hidden state)들
K = Keys : 모든 시점의 인코더 셀의 은닉 상태(hidden state)들
V = Values : 모든 시점의 인코더 셀의 은닉 상태(hidden state)들
=
<트랜스포머의 셀프 어텐션>
Q = Querys : 입력 문장의 모든 단어 벡터들
K = Keys : 입력 문장의 모든 단어 벡터들
V = Values : 입력 문장의 모든 단어 벡터들
•
세 가지 어텐션에 추가적으로 "multi-head" 가 붙어있는데, 이는 트랜스포머가 어텐션을 병렬적으로 수행하는 방법을 의미함.
Encoder Self-Attention
•
Transformer 모델은 일반 Attention이 아닌 Self-Attention 기법을 사용
기존 Attention 기법 vs 셀프 Attention 기법
•
위의 이미지와 같이 기존 Attention 기법은 입력-출력 간에 대응되는 단어 관계를 파악하는 게 핵심이었다.
•
하지만 Self-Attention 기법은 입력, 출력 각 시퀀스 내부의 단어들 간의 대응 관계를 파악하는 것이 핵심이다.
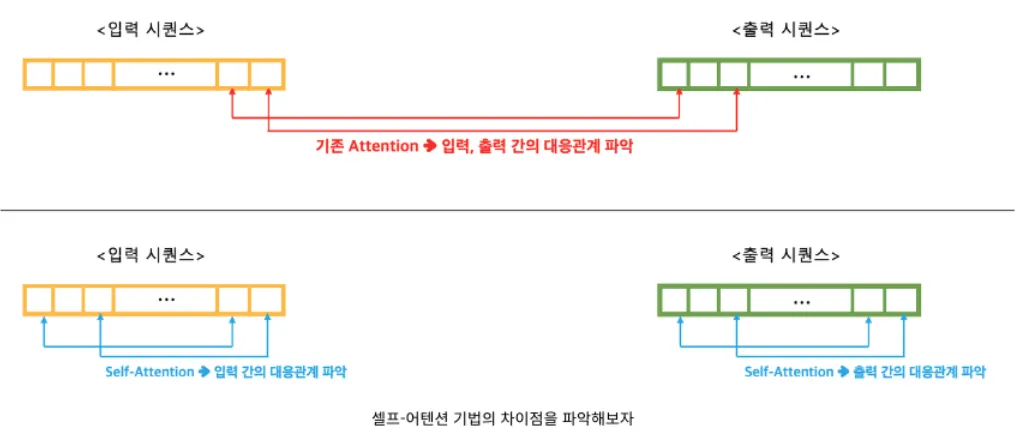
기법 차이
•
Self-Attention 기법은 입력 시퀀스 내에서의 대응관계를 학습하고 동시에 출력 시퀀스 내에서의 대응관계도 학습하는 방법이다.
•
그리고 이러한 Self-Attention 기법을 사용해 만든 계층을 재귀적으로 쌓아서 기존 Seq2Seq2 모델의 RNN이 하던 (과거의 기억을 유지하는) 메모리 네트워크 역할을 대체하기도 한다.
•
주어진 입력 벡터에 관해 어떠한 벡터를 중요하게 선별하여 반영할지에 관한 그 기준이 되는 벡터로 사용
•
transformer에서는 여기서 각 단어에 대응되는 query vector를 만들어 사용한다.
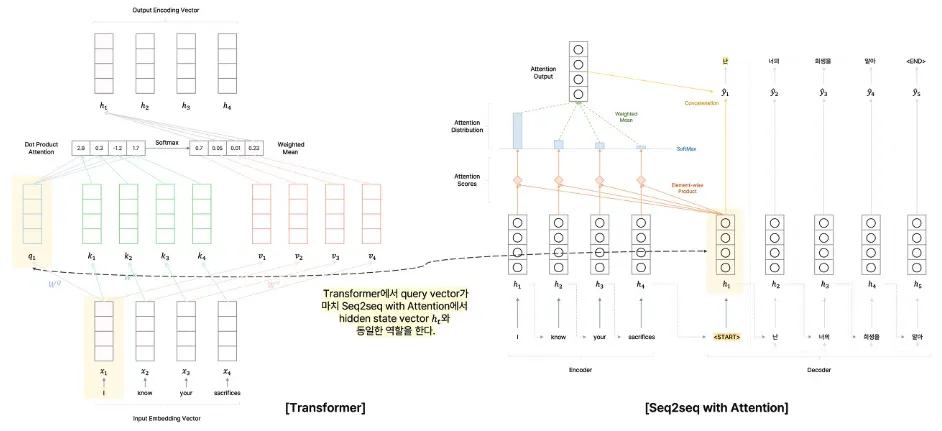
•
attention 모듈에서 query vector와의 유사도를 구할 때 언급한 각 단어의 input vector를 그대로 사용하지 않고 각 단어마다 key vector라는 별개의 vector를 만들어 사용
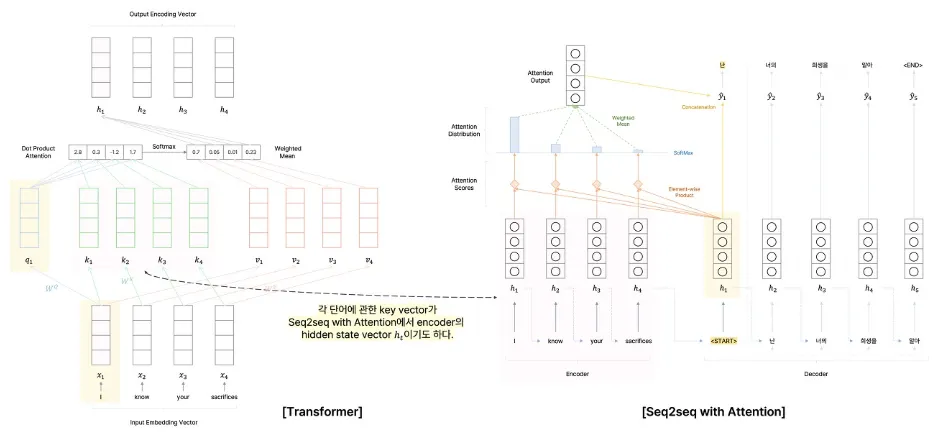
•
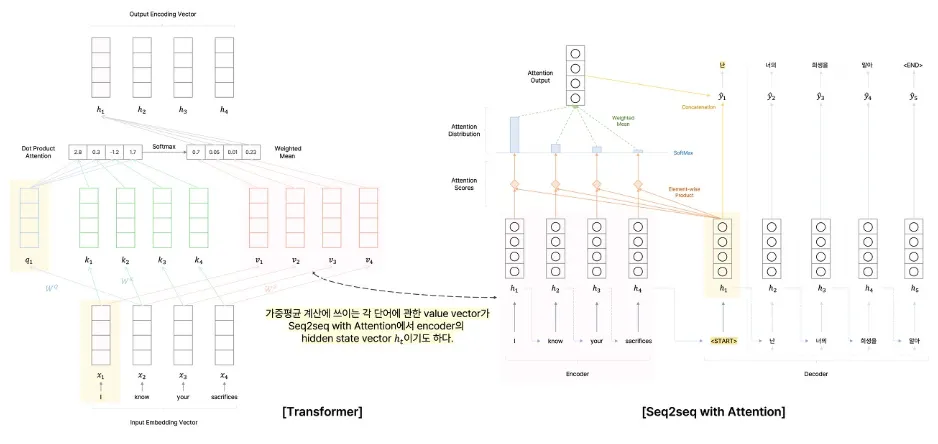
Transformer에서는 Attention 모듈에서와는 달리 가중 평균을 구할 때 각 단어별로 임베딩된 input vector를 그대로 사용하지 않고 각 단어별 value vector를 사용
Self Attention 이해하기
•
하단 그림에서 "그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤하였기 때문이다." 라는 문장

•
여기서 그것(it)은 당연히 동물(animal)
•
우리는 피곤한 주체가 동물이라는 것을 쉽게 알 수 있지만,
기계는 이 it 가 길(street)인지 동물(animal)인지 쉽게 알기 어려움.
•
따라서 셀프 어텐션을 통해 입력 문장 내의 단어들끼리 유사도를 구해서 it 이 animal 과 연관되었을 확률이 높다는 것을 찾을 수 있음.
Multi-Head Attention 이해하기
•
일반적인 Attention:
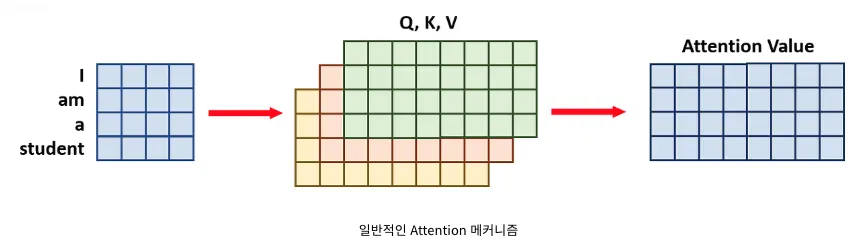
◦
예를 들어 [4x4] 크기의 문장 임베딩 벡터와 [4x8]의 Query, Key, Value가 있을 때
◦
일반적인 한 번에 계산하는 Attention 메커니즘은 의 Attention Value가 한 번에 도출된다.
•
Multi-head Attention:
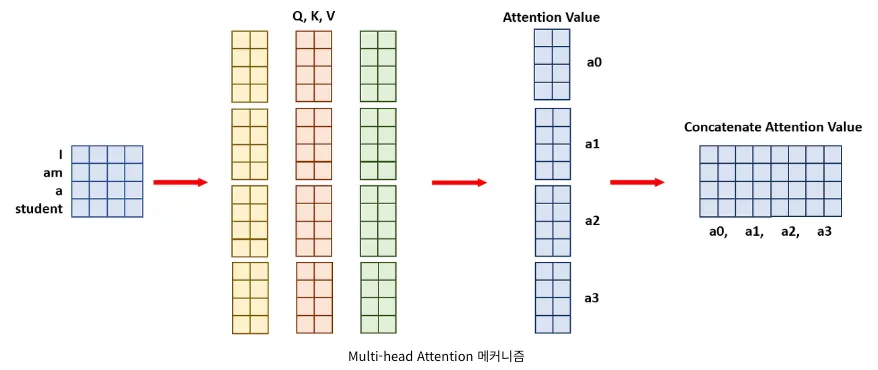
◦
head의 수가 4개이므로 각 연산과정이 4분의 1만큼만 필요하다.
◦
때문에 위에서 크기가 [4x8]이었던 Query, Key, Value를 4 등분하여 [4x2]로 만든다.
◦
이렇게 되면 자연스럽게 각 Attention Value는 [4x2]가 된다.
◦
이 Attention Value들을 마지막에 결합(concatenate)을 시켜주면 위 그림과 같이 크기가 [4x8]이 되어 일반적인 Attention 메커니즘의 결괏값과 동일하게 된다.
트랜스포머에서의 셀프 어텐션 동작 메커니즘
0.
셀프 어텐션은 위의 예시들처럼, 단어들 사이의 유사도를 구할 때 주로 이용하고, 따라서 입력 문장의 단어 벡터들을 가지고 계산한다.
트랜스포머에서의 셀프 어텐션 동작 메커니즘을 이해하기 위해 먼저 인풋을 생각해보자.
•
위에서 설명했던 포지셔널 인코딩을 거치면 위치 정보가 포함된 최종 input embedding matrix가 만들어졌음.
•
d_model 차원의 초기 입력 input embedding matrix 단어 벡터들을 바로 사용하는 것이 아니라 각 단어 벡터들로부터 먼저 Q, K, V 벡터들을 얻어야 함.
1.
Q, K, V 벡터 얻기
•
이 Q, K, V 벡터들은 초기 입력의 d_model 차원의 단어 벡터들보다 더 작은 차원을 가짐.
•
트랜스포머 논문에서는 d_model = 512의 차원을 가졌던 초기 단어 벡터들에서 64차원의 Q, K, V 벡터로 변환하여 사용
◦
d_model / (num_heads) = Q, K, V 벡터의 차원
◦
트랜스포머 논문에서는 num_heads를 8로 하여 로 Q, K, V 벡터 차원 결정
ex) "I am a student." 에서 student 라는 단어 벡터를 Q, K, V 벡터로 변환

◦
기존의 512차원의 벡터로부터 더 작은 벡터 Q, K, V를 만들기 위해서는 가중치 행렬을 곱해야함
◦
가중치 행렬의 크기 :
▪
논문의 경우에서는 512 * 64
⇒ 그럼 (1 * 512) x (512 * 64) = (1 * 64) 로 더 작은 벡터인 Q, K, V 구할 수 있다.
▪
이 때, Q, K, V 벡터를 만들기 위한 가중치 행렬은 각각 다름.
▪
따라서 512 크기의 하나의 student 단어 벡터에서 서로 다른 3개의 가중치 행렬을 곱해서 64 크기의 서로 다른 3개의 Q, K, V 벡터를 얻음.
▪
이 가중치 행렬은 훈련 과정에서 계속 학습됨.
◦
"I am a student." 문장의 모든 단어 벡터에 위의 과정을 거치면, I, am, a, student 단어 각각에 대해서 서로 다른 Q, K, V 벡터 구할 수 있음.
2.
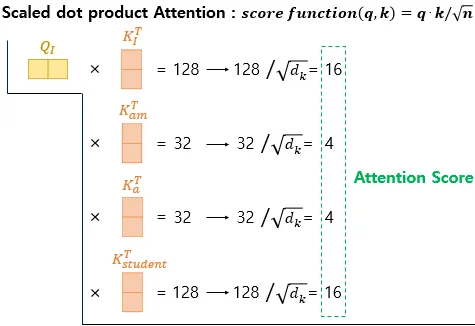
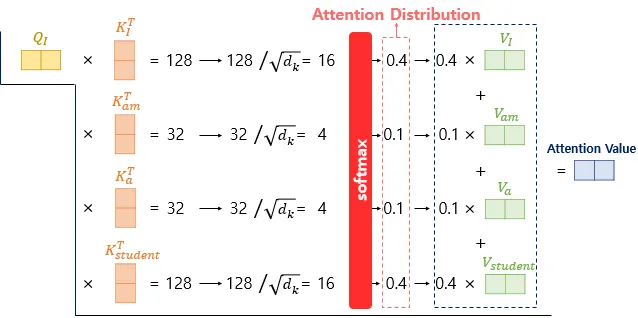
Scaled dot-product Attention 수행하기
•
현재까지 Q, K, V 벡터들을 얻은 상황. 이제 기존의 어텐션 메커니즘과 동일한 작업 수행
•
먼저 각 Q 벡터는 모든 K 벡터들에 대해서 어텐션 스코어 구함 - 어텐션 분포를 구함 - 어텐션 분포로부터 가중치를 적용해 모든 V 벡터들을 가중합함 - 최종 어텐션 값 ( = context vector) 구함
•
위의 과정을 모든 Q 벡터에 대해 반복
•
어텐션 스코어를 구하기 위한 어텐션 함수는 가장 기본인 내적(dot product) 이외에도 종류가 다양함
•
트랜스포머 논문에서는 기본 내적에다가 특정 값으로 나누어주는 어텐션 함수를 사용
◦
위의 함수처럼 특정 값으로 나누어주는 것을 기존의 내적 (dot-product attention)에서 값을 스케일링했다고 표현하여, Scaled dot-product Attention 이라고 함.
Decoder Masked Decoder Self(Multi-Head)-Attention
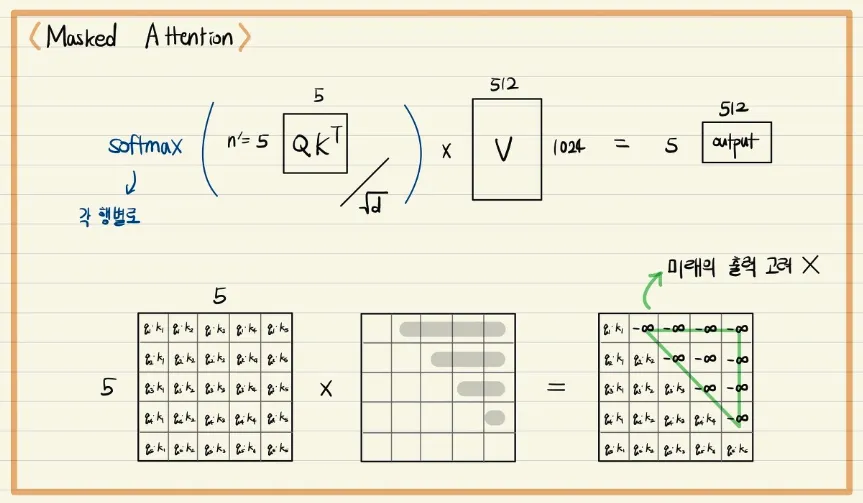
•
Decoder에서 ground truth 문장의 각 단어에 관해 query, key, value vector를 만들어서 각 단어별 encoding vector를 만들고자 할 때
앞에서 등장한 단어가 뒤에서 등장한 단어에 관해 가중치를 부여하여 파라미터 업데이트에 반영하는 경우가 과연 옳은 것인지를 고민해 볼 필요가 있다.
◦
예) token은 그 이후에 등장하는 단어 정보에 관해 인코딩된 벡터를 생성하게 되면 이는 결과적으로 앞 단어의 인코딩 벡터가 뒤의 단어의 정보도 반영하게 되는 현상이 발생
•
이러한 문제 발생을 막고자 query와 key vector 간의 내적을 통해 attention score를 구하고
•
해당 index 단어의 뒤에 등장하는 단어와의 attention score는 0으로 만들어서 후처리하는 것이 바로 Masked Multi-Head Attention의 핵심이다.
•
이는 앞에 등장하는 단어를 인코딩할 때 뒤에 등장하는 단어의 정보를 반영하지 못하도록 정보의 접근 권한을 차단하는 역할을 한다고 볼 수 있다.
•
요약 : masking은 self-attention 수행 시 행렬 Q와 K를 곱한 결과인 가중치 행렬에 적용하는데, 이는 self-attention 수행 시 앞 단어를 예측할 때 뒤쪽의 정보가 반영되는 것을 사전에 차단하기 위한 용도이다.
•
마찬가지로 Multi-Head Attention과 residual connection, layer normalization을 한 번 더 거치는데
•
여기서는 encoder에서 각 단어별로 최종 인코딩된 벡터를 key와 value vector로 사용하고, query vector로는 decoder의 앞단에서 인코딩된 단어별 벡터를 사용한다.
•
이는 ground truth의 각 단어들이 encoder의 입력으로 주어지는 입력 문장에서 어떠한 단어에 더 주목할지를 구하고, ground truth 문장의 각 단어를 인코딩할 때 encoder의 입력 문장에서 어떠한 단어의 인코딩 벡터를 더 많이 반영할지를 가중 평균 구하는 것으로 해석이 가능하다.
•
마찬가지로 이를 Seq2Seq with Attention와 대응시킬 때
◦
decoder에서 각 단어에 해당되는 매 time step마다 hidden state를 가지고 encoder에서의 모든 hidden state와 attention score를 구한 후 가중 평균을 계산
⇒ decoder에서 해당 time step에서의 최종 인코딩된 hidden state vector를 구하는 과정으로 볼 수 있다.
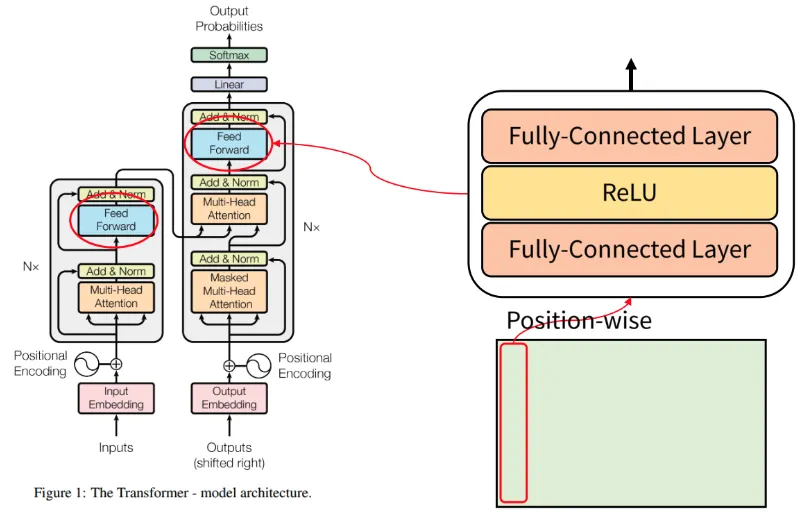
Position-wise Feed-Forward Network(FFN)
•
단어의 Position 별로 Feed Forward(순전파) 한다는 뜻
•
각 단어에 해당하는 열 벡터가 입력으로 들어갔을 때, FC Layer -> Relu -> FC Layer 연산을 거치게 된다.
Add, Norm
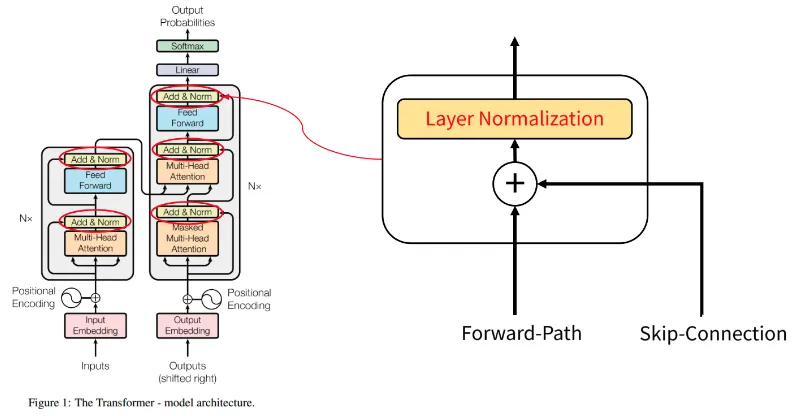
•
◦
Add는 Skip(Residual) Connection을 의미한다.
◦
Skip Connection을 사용하는 이유는 '덧셈' 연산의 역전파 시 기울기를 건드리지 않고 그대로 흘려보내는 특성 때문에 기울기 소실, 폭발 문제를 막을 수 있기 때문이다.
•
Norm(Normalization)
◦
출력값들의 분포를 인위적으로 표준정규분포 형태로 만들어 주는 것이다.
구조 : Output Softmax
•
마지막 Feed Forward(순전파)를 통해 출력이 되면 Linear 연산을 통하여 출력 단어 종류 갯수로 출력 사이즈를 맞춰 준다.
•
최종적으로 Softmax를 이용해 어떤 단어인지 Classification(분류) 문제를 해결할 수 있다.
Softmax : 입력받은 값을 출력으로 0~1사이의 값으로 모두 정규화하며 출력 값들의 총합은 항상 1이 되는 특성을 가진 함수

