


Hugging Face란?
•
자연어 처리 스타트업이 개발한, 다양한 트랜스포머 모델(transformer.models)과 학습 스크립트(transformer.Trainer)를 제공하는 모듈
•
허깅 페이스를 사용한다면, 트랜스포머 모델 사용시 layer, model 등을 선언하거나 학습 스크립트를 구현해야하는 수고를 덜 수 있다.
•
(2024년 10월 기준) 120k 이상의 모델, 20k의 데이터셋, 그리고 50k의 데모 앱(Spaces)을 포함하는 플랫폼
•
모든 것은 오픈 소스이며 공개적으로 이용할 수 있다.
•
이 플랫폼에서 사람들은 쉽게 협업하고 함께 ML을 구축할 수 있다.

Hugging Face 키 등록 하기
1.
설정으로 들어간다.
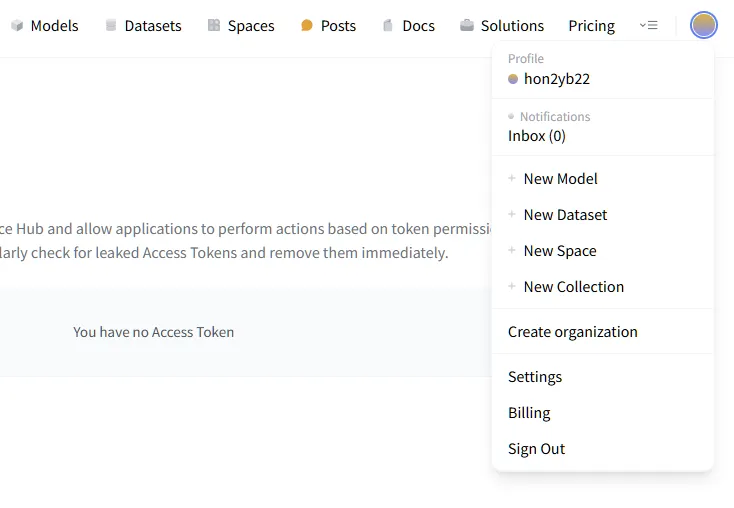
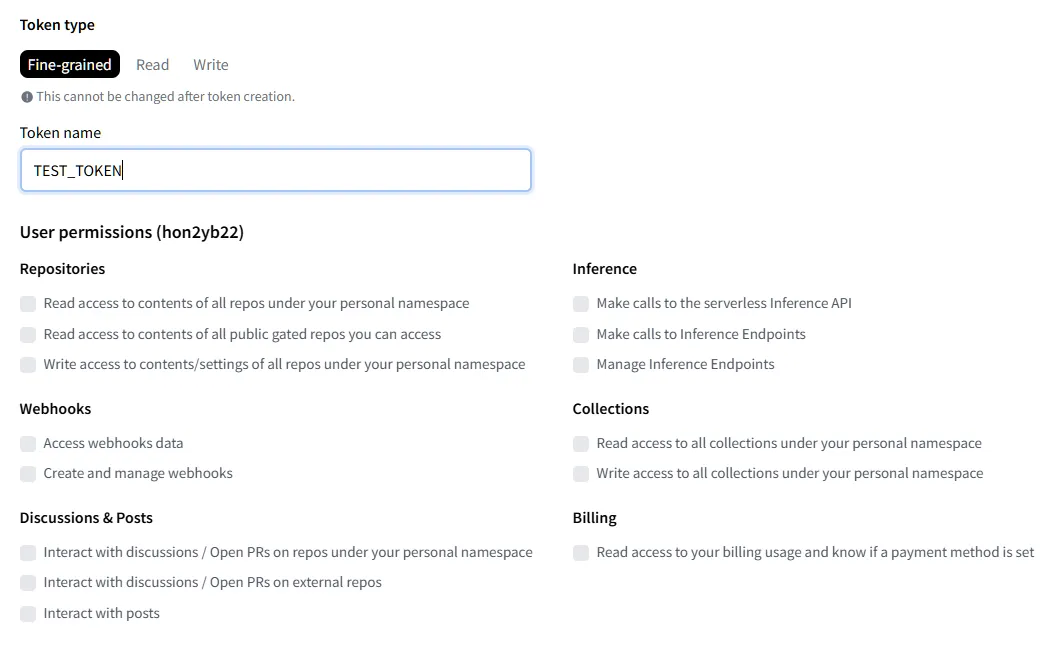
2.
토큰 이름 및 권한 설정
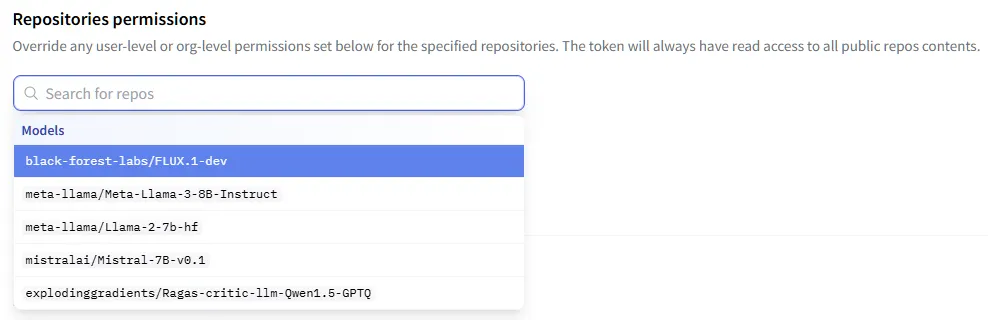
3.
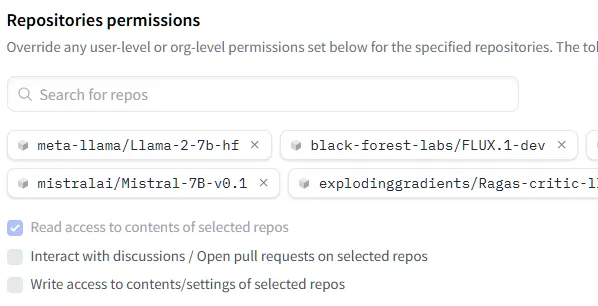
사용한 모델(들)을 선택한다.
4.
자동으로 권한이 부여되어 진다. (Read : 다운로드 가능)
5.
키가 생성되고 하단에 키를 복사할 수 있는 칸이 생긴다.
1.
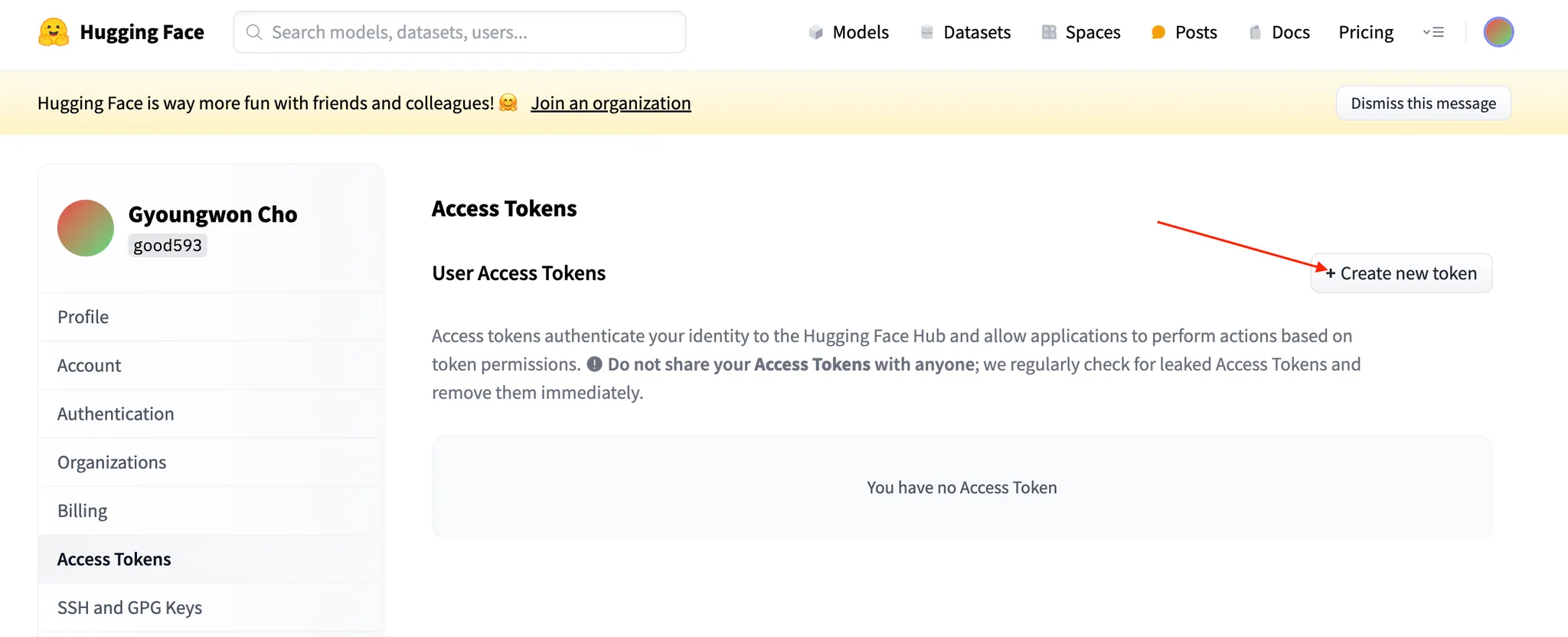
설정 → Access Tokens
2.
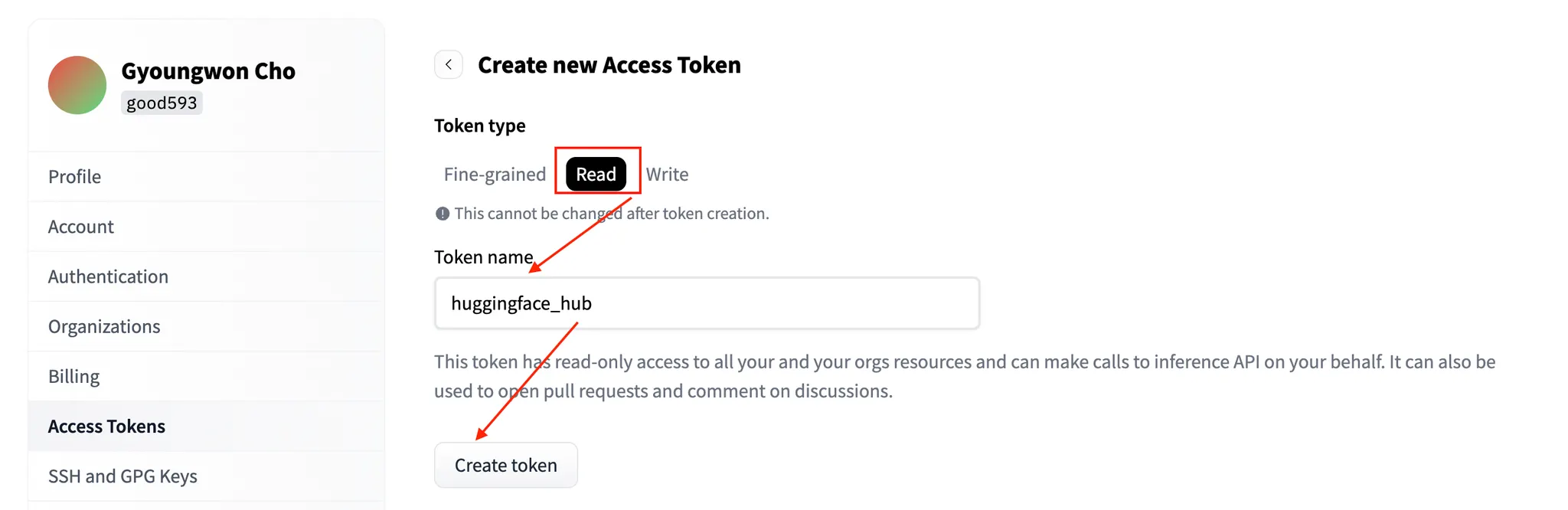
Type을 Read로 설정
Leaderboard
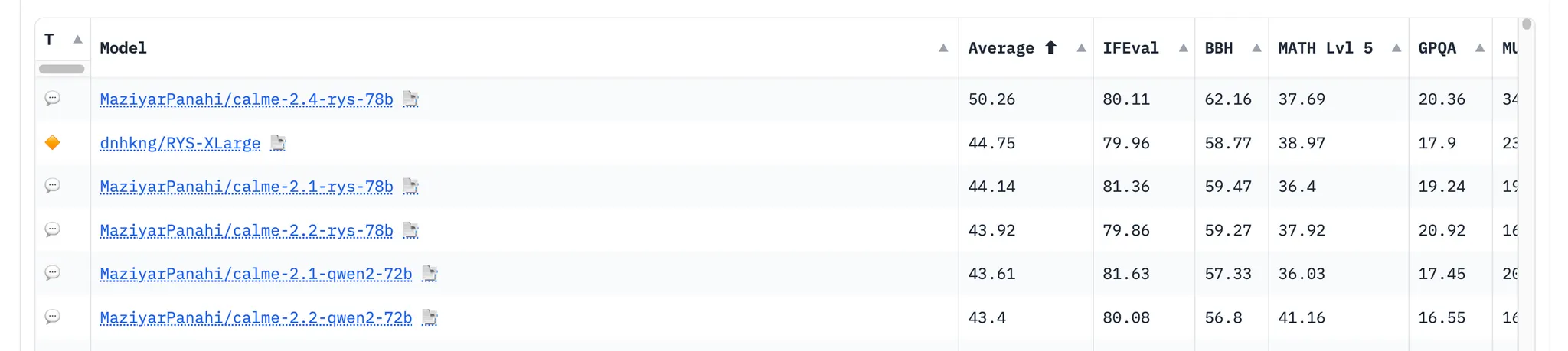
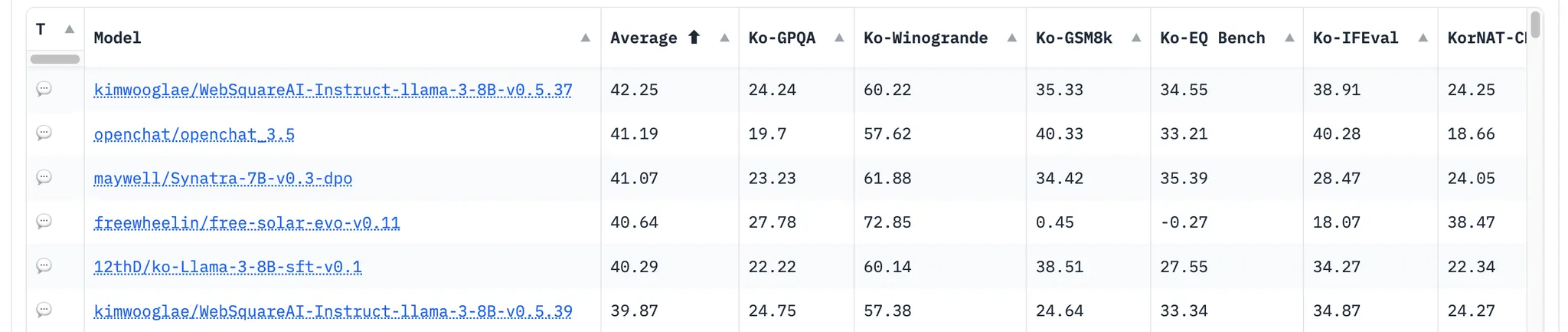
•
허깅페이스 서버에서 선택된 모델로 추론하고, 이에 대한 답변을 반환받는 방식
PromptTemplate
# 템플릿
template = """
Question: {question}
Answer: """
# 프롬프트 템플릿 생성
# -> LLM에게 우리가 궁금한 질문(question) 물어보고, 그리고 답변을 받는 포맷
prompt = PromptTemplate(template=template, input_variables=["question"])
> prompt
PromptTemplate(input_variables=['question'], input_types={}, partial_variables={}, template='\nQuestion: {question}\n\nAnswer: ')
Python
복사
LLM (사전 학습 모델)
# HuggingFace Repository ID
repo_id = 'mistralai/Mistral-7B-v0.1'
# HuggingFaceHub 객체 생성
llm = HuggingFaceHub(
repo_id=repo_id,
model_kwargs={"temperature": 0.2, # 자유도
"max_length": 128} # 최대 답변 길이
)
Python
복사
Chain 생성 (Promt + LLM)
•
LLM 모델이 응답을 하는 원리
◦
input -> Question: {question} Answer:
◦
model(1.예측) -> Question: {question} Answer: + token
◦
input -> Question: {question} Answer: + token
◦
model(2.예측) -> Question: {question} Answer: + token + token
◦
...
# LLM Chain 객체 생성
llm_chain = LLMChain(prompt=prompt, llm=llm)
> llm_chain
LLMChain(verbose=False, prompt=PromptTemplate(input_variables=['question'], input_types={}, partial_variables={}, template='\nQuestion: {question}\n\nAnswer: '), llm=HuggingFaceHub(client=<InferenceClient(model='mistralai/Mistral-7B-v0.1', timeout=None)>, repo_id='mistralai/Mistral-7B-v0.1', task='text-generation', model_kwargs={'temperature': 0.2, 'max_length': 128}), output_parser=StrOutputParser(), llm_kwargs={})
Python
복사
질의 응답
•
Huggingface 서버를 통해서 예측
# 질의내용
my_question = "Who is Son Heung Min?"
# 실행
> print(llm_chain.run(question=my_question))
Question: Who is Son Heung Min?
Answer: 1. Son Heung Min is a South Korean professional footballer who plays as a winger for Premier League club Tottenham Hotspur and the South Korea national team.
2. He has been named the South Korean Footballer of the Year three times and has been included in the K League Best XI three times.
3. He is the first Asian player to score 100 goals in Europe’s top five leagues.
4. He is the
Python
복사
# 질의내용 -> 한국어 불가능;;;;
my_question = "Please explain about King Sejong in Korean."
# 실행
> print(llm_chain.run(question=my_question))
Question: Please explain about King Sejong in Korean.
Answer: 세종대왕 (Sejong Daewang)
King Sejong was the fourth king of the Joseon Dynasty. He was born in 1397 and died in 1450. He was the son of King Taejong and Queen Soheon. He was the third son of King Taejong.
King Sejong was a great king. He was the one who created the Korean alphabet,
Python
복사
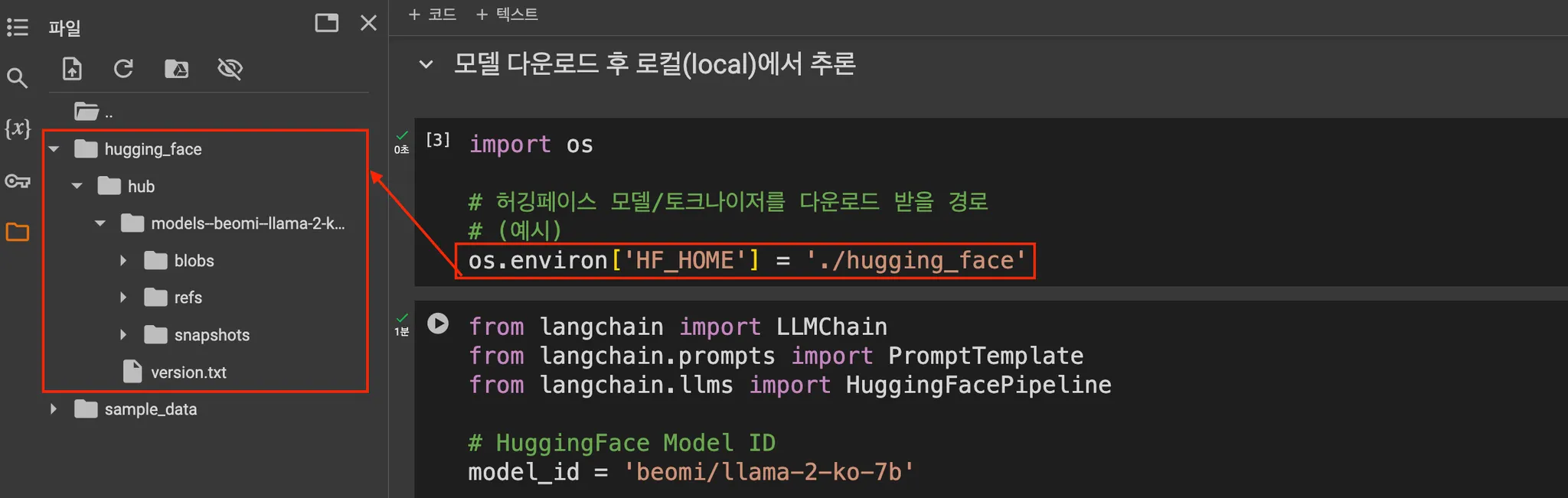
모델 다운로드 후 로컬(local)에서 추론
LLM
from langchain import LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import HuggingFacePipeline
# HuggingFace Model ID
model_id = 'beomi/llama-2-ko-7b'
# HuggingFacePipeline 객체 생성
llm = HuggingFacePipeline.from_model_id(
model_id=model_id,
device=0, # -1: CPU(default), 0번 부터는 CUDA 디바이스 번호 지정시 GPU 사용하여 추론
task="text-generation", # 텍스트 생성
model_kwargs={"temperature": 0.1,
"max_length": 64},
)
Python
복사
PromptTemplate
# 템플릿
template = """
질문: {question}
답변: """
# 프롬프트 템플릿 생성
prompt = PromptTemplate.from_template(template)
Python
복사
LLMChain
# LLM Chain 객체 생성
llm_chain = LLMChain(prompt=prompt, llm=llm)
# 실행
> question = "대한민국의 수도는 어디야?"
> print(llm_chain.run(question=question))
질문: 대한민국의 수도는 어디야?
답변: 서울입니다.
Python
복사
