


Hugging Face Transformer
•
인공신경망 알고리즘은 크게, 합성곱 신경망(CNN), 순환 신경망(RNN), 트랜스포머(Transformer) 3가지로 나눠진다.
•
이 중 트랜스포머는, 2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델로,
•
셀프 에텐션(Self-Attention)이라는 방식을 사용하는 모델이다.
•
트랜스포머는, 이러한 어텐션 방식을 사용해, 문장 전체를 병렬구조로 번역할 뿐만 아니라, 멀리 있는 단어까지도 연관성을 만들어 유사성을 높였으며, RNN의 한계를 극복했다.
•
또한, 이미지나 언어 번역에 폭넓게 쓰이고 있으며, GPT-3, BERT 등이 가장 관심을 많이 받고 있는 모델이다.
transformers.models
•
트랜스포머 기반의 다양한 모델을 pytorch, tensorflow 로 각각 구현해놓은 모듈이다.
•
각 모델에 맞는 tokenizer 도 구현되어 있다.
transformers.pipeline
•
pipeline()을 사용하면 언어, 컴퓨터 비전, 오디오 및 멀티모달 태스크에 대한 추론을 할 수 있다.
transformers.Trainer
•
딥러닝 학습 및 평가에 필요한 optimizer, weight updt, learning rate schedule, ckpt, tensorbord, evaluation 등을 수행하는 모듈
•
Trainer.train 함수를 호출하면, 이 모든 과정이, 사용자가 원하는 arguments에 맞게 실행된다.
•
pytorch lightning 과 비슷하게, 공통적으로 사용되는 학습 스크립트를 모듈화 하여 편하게 사용할 수 있다는 점이 장점이다.
Transformer
Transformer의 역사
•
Transformer architecture는 2017년 6월에 처음 소개되었다.
•
처음 연구 목적은 번역 작업 수행
•
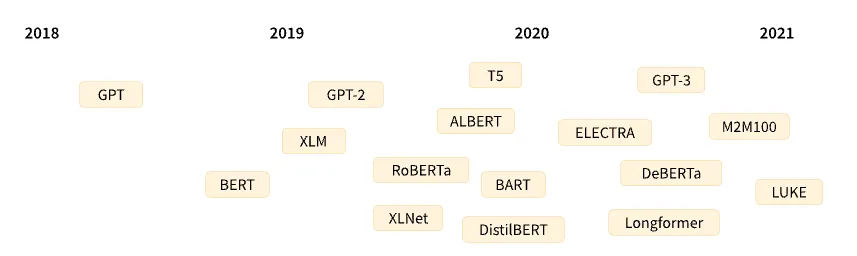
이후로 다음과 같이 줄줄이 막강한 모델들이 세상에 등장
•
주요 모델
◦
2018년 6월: GPT, 최초로 사전 학습된 트랜스포머 모델로 다양한 NLP 작업에 미세 조정(fine-tune)되도록 사용되었으며 SOTA(state-of-the-art) 성능 달성
◦
2018년 10월: BERT, 또 다른 거대 사전 학습 언어 모델로, 더 좋은 문장 요약을 위해 설계 (이번 단원과 다음 단원에서 더 자세히 알아보자)
◦
2019년 2월: GPT-2, 더 좋은 성능(그리고 더 큰) 버전의 GPT로, 윤리적 문제로 인해 즉시 공개되지 못하였음
◦
2019년 10월: DistilBERT, BERT의 60% 빠른 속도에 메모리 측면에서 40% 가볍지만 BERT 성능의 97%를 재현하는 경량화 버전의 BERT
◦
2019년 10월: BART 와 T5, 동일한 구조의 (처음으로) 원본 트랜스포머 모델의 구조를 그대로 따른 두 거대 사전학습 언어 모델
◦
2020년 5월: GPT-3, 미세 조정 없이도 (zero-shot learning이라 부름) 다양한 작업을 훌륭하게 수행하는 GPT-2의 더 큰 버전
트랜스포머 학습방법
•
위에 언급한 모델(GPT, BERT, BART, T5 등)들은 언어 모델(language model)로서 학습
== 이 모델들은 스스로 지도하는 방식으로 수많은 텍스트에 대해 학습된 모델들
이러한 자가 지도 학습(self-supervised learning)은 학습의 목적이 모델 입력으로부터 자동으로 계산되는 방식이다.
=> 결국 사람이 데이터에 레이블을 달지 않아도 학습이 가능하다!
•
이러한 종류의 모델은 학습한 언어에 대해 통계 기반의 방식으로 이해를 하지만, 이는 몇몇 실생활 문제에 적합하지 않다.
•
그렇기 때문에 사전 학습된 모델은 전이 학습(transfer learning)이라 불리는 과정을 거친다.
•
이 과정에서 모델은 특정 작업에 맞춰 지도적(supervised)인 방법, 즉 사람이 레이블을 추가한 데이터를 사용하는 방법으로 미세 조정(fine-tune)이 이루어지는 단계를 거친다.
Causal Language Modeling
•
하나의 예시로 문장 내에서 이전 n개의 단어를 읽고 다음에 올 단어를 에측하는 문제를 들 수 있다.
•
이를 과거와 현재의 입력 정보를 이용하는 방식(미래에 올 입력 정보는 이용하지 않는다)이기 때문에 인과적 언어 모델링(causal language modeling)이라고 부른다.

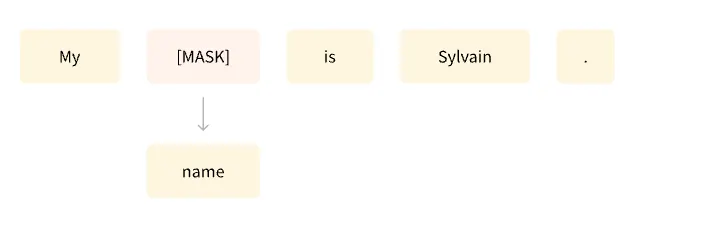
Masked Language Modeling
•
다른 예시로 마스크 언어 모델링(masked language modeling)을 들 수 있다.
•
여기서 모델은 문장 내에 마스킹 된 단어를 예측한다.
Pretraining
•
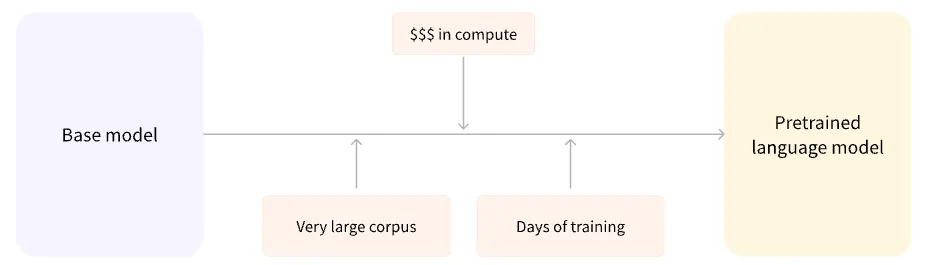
사전 학습(Pretraining)시에는 모델을 밑바닥부터 학습시키게 된다.
•
모델 가중치를 랜덤하게 초기화하고 사전 지식 없이 학습을 시작한다.
•
이러한 사전 학습 과정은 엄청난 양의 데이터로 이루어지기 때문에 방대한 양의 코퍼스 데이터와 수 주 씩 걸리는 학습 시간을 필요로 하기도 한다.
코퍼스 데이터 = 말뭉치 데이터
분석하려는 대상, 문서, 데이터셋이라 할 수 있다.
한가지 언어로 이루어진 코퍼스 = 단일 언어 코퍼스 (monolingual)
한가지 이상 언어로 이루어진 코퍼스 = 이중 언어 코퍼스 (billingual)
Fine-tuning
•
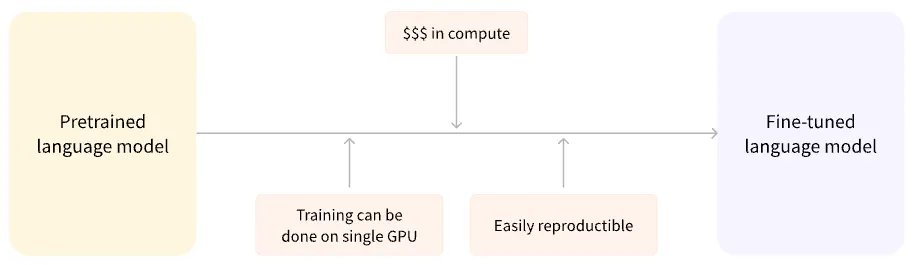
반면 미세 조정(Fine-tuning)이란 모델이 모두 사전 학습을 마친 이후에 하는 학습을 의미.
•
미세 조정을 하기 위해서 우선 사전 학습된 언어 모델을 가져오고, 우리가 할 작업에 특화된 데이터셋을 이용해 추가 학습을 수행한다.

Wait, 그냥 한번에 최종 태스크에 맞춰 학습시키면 안될까요?
댓츠 노노, 이렇게 하는 데에는 몇 가지 이유가 있단다.
•
사전 학습된 모델은 이미 미세 조정 데이터셋과 유사한 데이터셋으로 학습이 이루어진 상태
•
결국 모델이 사전 학습시에 얻은 지식(이를테면, NLP 문제에서 사전 학습된 모델이 얻게 되는 언어의 통계적 이해)을 십분 활용해 미세 조정에 활용할 수 있게 된다.
•
사전 학습된 모델은 이미 방대한 데이터로 학습되었기 때문에 미세 조정에서는 원하는 성능을 얻기까지 적은 양의 데이터만 필요로 하게 된다.
•
위와 같은 이유로, 원하는 성능을 얻기까지 적은 시간과 리소스만 필요하게 된다.
•
인코더(Encoder) (왼쪽)
◦
인코더는 입력에 대한 표현(representation) 혹은 자질(feature)을 도출한다.
◦
이는 모델이 입력으로부터 이해를 얻도록(acquire understanding from the input), 다시 말해서, 최종 목적 태스크를 위해서 입력에 대한 표현 형태가 최적화되었음을 의미
•
디코더(Decoder) (오른쪽)
◦
디코더는 인코더가 구성한 표현(representation) 혹은 자질(feature)을 다른 입력과 함께 사용하여 대상 시퀀스를 생성한다.
◦
이는 모델이 출력 생성(generating outputs)에 최적화되어 있음을 의미.
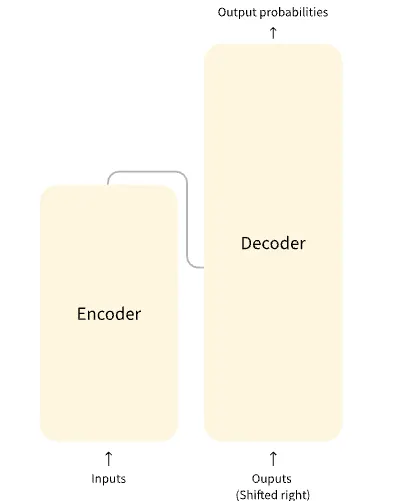
•
가장 중요한 핵심은 대상 작업의 종류에 따라 전체 아키텍처(full architecture)를 사용하거나 인코더(encoder) 또는 디코더(decoder)만 사용할 수 있다는 것이다.
요새는 디코더만 사용하는 추세이다.
Tokenizer
•
자연어(string)를 다차원 벡터(vector)로 변환하기 위해 먼저 토큰 단위로 잘라주는 작업
•
토큰으로 변환하는 기준은 다양하다.
◦
영어는 띄어쓰기를 기준으로 토큰화
◦
한국어는 형태소(morpheme)를 이용한 토큰화
{'input_ids': [101, 1045, 2293, 17953, 2361, 999, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1]}
Python
복사
◦
input_ids
▪
tokenize된 token의 ID값
▪
즉, 미리 만들어진 단어 사전 리스트에서 해당 단어의 인덱스
◦
token_type_ids
▪
tokenizer에 넣는 문장은 여러개 넣을 수 있다.
▪
그래서 token_type_ids는 매개변수로 넣어진 문장 중 몇 번째 문장에 포함되어 있는지를 나타낸다.
▪
하나의 문장만 넣으면 모두 첫번째 문장이므로 0(첫번째 문장을 의미)으로 표시된다.
▪
문장을 두개 넣는다면 0,0,0,0...1,1,1,1 이런식으로 표현될 것이다.
◦
attention_mask
▪
0은 무시해도 되는 token, 1은 의미있는 token을 의미
▪
이때 무시해도 될 token이란 문장을 여러개 넣어줄 경우 문장들의 길이를 맞춰주기 위해 padding을 사용한다.
▪
즉, 문장1이 3글자, 문장2이 5글자라면 문장1에 의미없는 padding을 2개 넣어준다는 것이다.
▪
이런 padding이 attention_mask 0이다.
special token
['[CLS]', 'i', 'love', 'nl', '##p', '!', '[SEP]']
I love NLP!
Python
복사
•
padding token : PAD
•
unknown token : UNK
•
classifier token : CLS
•
seperator token : SEP
•
mask token : MASK
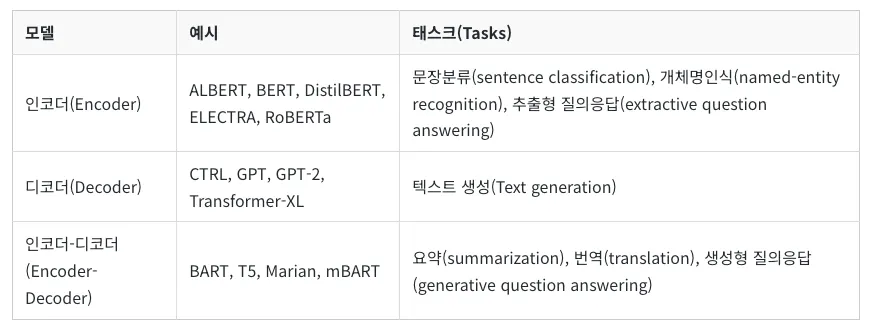
Encoder Models
•
인코더 전용 모델(Encoder-only models): 문장 분류(sentence classification) 및 개체명 인식(named-entity recognition)과 같이 입력에 대한 분석 및 이해(understanding)가 필요한 태스크에 적합하다.
•
BERT의 메모리 소비를 낮추고 학습 속도를 높이기 위한 두 가지 매개변수 감소 기술을 제시된 모델
◦
임베딩 행렬을 두 개의 작은 행렬로 분할한다.
◦
그룹 간에 반복되는 레이어를 분할하여 사용한다.
•
사용 팁
◦
ALBERT는 절대 위치 임베딩을 사용하는 모델이므로 일반적으로 왼쪽보다는 오른쪽의 입력을 채우는 것이 좋다.
◦
ALBERT는 반복 계층을 사용하므로 메모리 사용량이 적지만, 동일한 수의 은닉 계층을 사용하는 BERT 유사 아키텍처와 계산 비용이 비슷하다.
▪
이는 동일한 수의 (반복) 계층을 반복해야 하기 때문
◦
임베딩 크기 E는 숨겨진 크기 H와 정렬된 것과 다르다.
◦
임베딩은 컨텍스트에 독립적(한 임베딩 벡터는 한 토큰을 나타냄)인 반면 숨겨진 상태는 컨텍스트에 따라 다르다(한 숨겨진 상태는 토큰 시퀀스를 나타냄).
→ 따라서 H >> E인 것이 더 논리적이다.
또한 임베딩 행렬은 (V는 어휘 크기)이므로 크다. E < H이면 매개변수가 적다.
◦
레이어는 매개변수를 공유하는 그룹으로 나뉩니다(메모리를 절약하기 위해). 다음 문장 예측은 문장 순서 예측으로 대체된다.
◦
입력에서 두 문장 A와 B(연속)가 있고 A 다음에 B 또는 B 다음에 A를 공급한다.
◦
모델은 이들이 교환되었는지 여부를 예측해야 한다.
•
스케일드 도트 프로덕트 어텐션(SDPA) 사용
Decoder Models
•
디코더 전용 모델(Decoder-only models): 텍스트 생성(text generation) 등과 같은 생성 태스크(generative tasks)에 좋다.
Greedy search
•
타임스텝 t에서 가장 높은 확률을 가지는 토큰을 다음 토큰으로 선택하는 전략
•
Greedy Search 전략은 직관적이며, 짧은 텍스트를 생성할 때 괜찮은 전략이다.
•
이 전략을 통해 생성한 문장은 그럴듯하지만, 모델은 어느 순간 (꽤 빠른 시점부터) 같은 단어를 생성하기 시작한다.
•
이러한 동어 반복 문제는 자연어 생성에서 자주 발생하는 문제이지만, greedy & beam search에서 특히 자주 발생한다.
•
또한, 매 스텝에서 최고 확률의 토큰을 선택하는 이 전략은 최종 문장의 관점에서 최적이 아닐 수 있다.
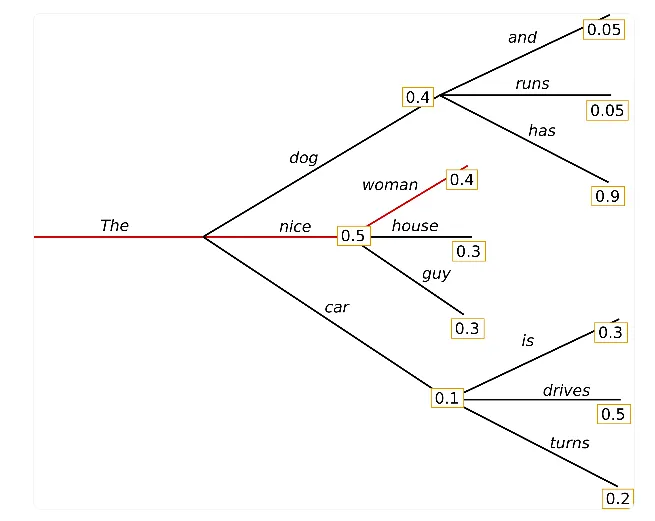
Beam search
•
각 타임스텝에서 가장 가능성 있는 num_beams개의 시퀀스를 유지하고, 최종적으로 가장 확률이 높은 가설을 선택하는 방법
•
Greedy search가 숨겨 있는 높은 확률의 토큰을 놓칠 수 있다는 단점을 보완하기 위해 고안된 방법
•
언제나 Greedy search보다 높은 확률의 시퀀스를 찾게 되지만, 여전히 최선의 아웃풋을 보장하지는 않는다.
n-gram 패널티 주기
•
동어 반복을 피하고 좀더 자연스러운 문장을 생성하기 위해 n-grams 페널티 전략을 적용할 수 있다.
•
n-gram 단위의 어구가 두 번 등장할 일이 없도록, 이러한 일이 발생할 확률을 0으로 만드는 전략이다.
•
코드상에서는 아래와 같이 no_repeat_ngram_size 옵션을 설정함으로써 구현할 수 있다.
•
이 전략을 이용하면 훨씬 자연스러운 문장을 생성할 수 있지만, 텍스트 전체에서 n-gram으로 설정한 단어가 한 번만 등장할 수 있기 때문에 주의해서 사용해야 한다. 예를 들어 '서울 시청'에 대한 주제로 글을 쓰는데, no_repeat_ngram_size = 2로 설정하면 전체 글에서 '서울 시청'이라는 말은 한 번밖에 사용하지 못하기 때문이다!
beam search에서 k개의 beam을 모두 리턴하기
•
beam을 유지하며 디코딩한 시퀀스 중 가장 높은 확률을 가지는 k의 시퀀스를 모두 리턴해 마음에 드는 것을 사용하는 전략
•
코드에서는 num_return_sequences 옵션을 통해 구현 가능. 이 때 이 값은 num_beams보다 작거나 같아야 한다.
•
하지만, 모델이 자유롭게 글을 생성하는 <open-ended 생성>에서는 beam search가 최선의 전략은 아닐 수 있다:
◦
beam search는 기계번역이나 요약정도에는 잘 작동하지만, 생성해야 하는 텍스트의 길이가 긴 대화 혹은 스토리를 생성해야 하는 open-ended 생성에서는 좋지 않다는 연구 결과가 있다.
◦
beam search는 동어반복 문제가 심한 편인데, n-gram 페널티 전략으로는 '반복 없음'과 '적절한 시점에 동일한 단어를 재사용'하는 중간 지점을 찾기 어렵다.
◦
인간이 사용하는 언어를 놓고 보면, 모델이 생각하기에 가장 높은 확률을 가지는 단어가 늘 다음에 오는 것은 아니다.
◦
마치 사람이 쓴 것과 같이 자연스럽기 위해서는 너무 예측 가능한 나머지 뻔하지만은 않은, '놀라운' 단어를 생성해낼 필요도 있다.
do_sample
•
모델이 생각하는 다음에 올 토큰에 대한 확률분포에 따라 단어를 샘플링하는 방식으로 디코딩하는 전략
•
이 전략을 사용하면 각 타임스텝에서 모델이 예측한 토큰의 확률분포를 이용해 토큰을 샘플링해 문장을 완성한다.
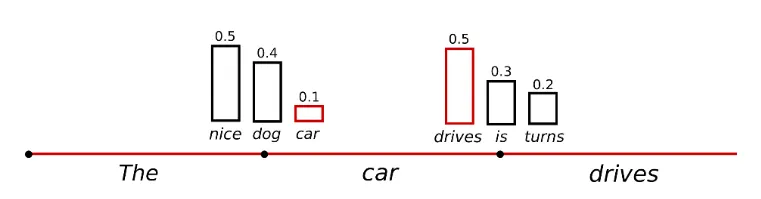
◦
하지만 모델이 만들어낸 확률은 smooth한 나머지, 낮은 확률의 토큰이 "지나치게 잘" 샘플링될 수 있고, 이렇게 되면 어색한 문장이 만들어질 수 있다.
◦
따라서 모델이 배출한 분포에서 높은 값을 가지는 확률을 더 뾰족하게 만드는 temperature 스케일링을 사용한다.
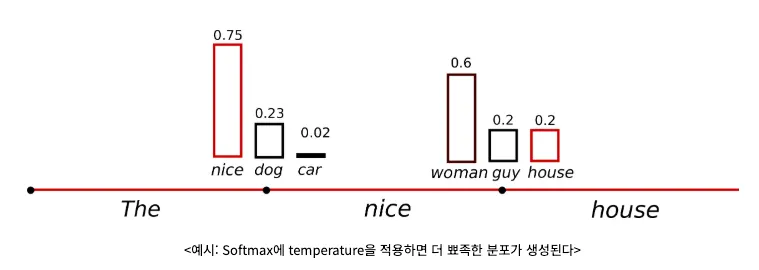
Top-k Sampling
•
가장 확률이 높은 K개의 '다음 단어들'을 필터링하고, 확률 질량을 해당 K개의 '다음 단어들'에 대해 재분배하는 전략
•
이는 GPT-2에서 선택한 디코딩 전략으로, 스토리 생성에서 큰 효과를 보인 방법이다.
•
예를 들어 아래 그림은 K=6으로 셋팅한 top-k샘플링을 보여준다.
•
각 샘플링 스텝에서 샘플링할 풀이 6개로 제한된다.
•
이때 6개의 가장 확률이 높은 단어 집합을 로 표현하면, 첫 번째 타임스텝에서는 전체 확률에서 0.68정도에 해당하는 단어에서 디코딩하지만, 두 번째 타임스텝에서는 가능한 대부분의 토큰(0.99)을 아우르는 동시에, 너무 이상한 토큰들(a, not, the 등..)은 아예 제외할 수 있다.
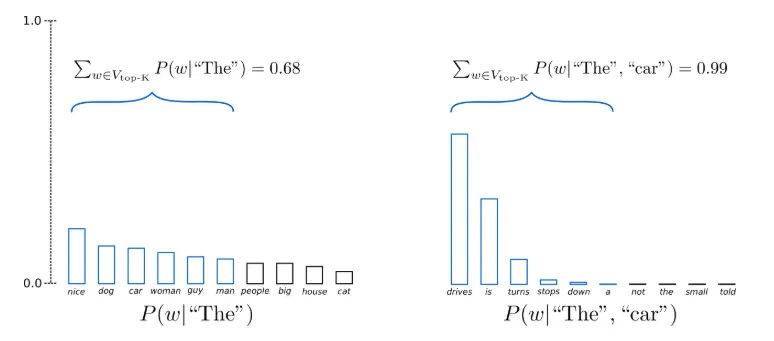
•
코드상에서는 top_k 옵션을 0이 아닌 50과 같은 숫자로 주어 top-k 샘플링을 쉽게 구현할 수 있다.
•
단, 이 방법은 다음 토큰으로 필터링된 k의 단어를 아주 효과적으로 활용하지 못 할 수 있다는 우려가 있다.
•
그림에서 보여주는 예시만 보아도, 첫 번째 단어는 꽤나 평평한 분포에서 샘플링을 하지만 두 번째 토큰은 sharp한 분포에서 샘플링을 하게 된다.
•
이로 인해 첫 번째 타임스텝에서는 꽤나 괜찮아보이는 (people, big, house, cat) 등의 후보는 전혀 고려되지 못하고, 두 번째 타임스텝에서는 낮은 확률이라도 뽑게 되면 어색해지는 (down, a) 등의 토큰이 샘플링 풀에 포함되게 된다.
•
즉, 이 방법은 모델의 창의성을 지나치게 저하하면서도 모델이 이상한 단어를 샘플링할 위험이 있는 것이다.
# set seed to reproduce results. Feel free to change the seed though to get different results
set_seed(42)
# set top_k to 50
sample_output = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True, #샘플링 전략 사용
top_k=50 # 확률 순위가 50위 밖인 토큰은 샘플링에서 제외
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Python
복사
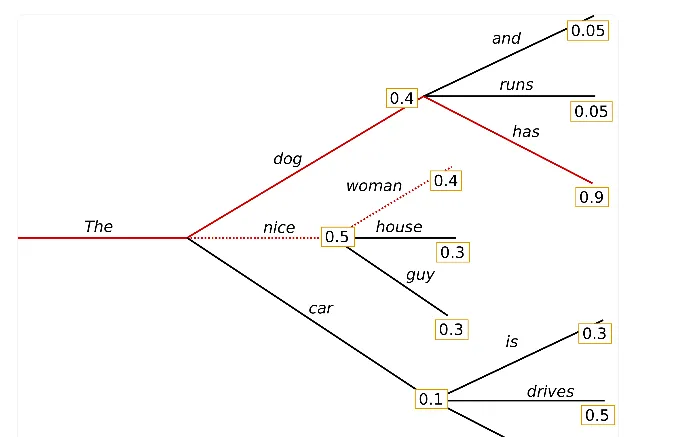
Top-p (nucleus) sampling
•
가능도 있는 k개의 단어로부터 샘플링하는 대신, 누적 확률이 확률 p에 다다르는 최소한의 단어 집합으로부터 샘플링
•
가장 높은 확률을 가지는 토큰부터 시작해, 확률 값의 합이 top-p로 설정한 값을 넘을 때까지 샘플링 풀에 토큰을 추가한다.
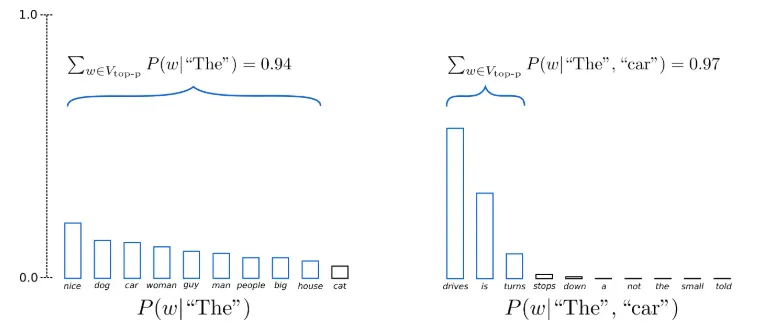
◦
확률이 비교적 평평했던 첫 번째 타임스텝에서는 가능성 있는 (nice, dog, ..., big, house)까지 총 9개의 토큰을 샘플링 풀에 넣어야 누적확률 0.94를 채울 수 있었다.
◦
하지만 분포가 가팔랐던 두 번째 타임스텝에서는 확률이 굉장히 높은 (drives, is, turns)에서만 샘플링하게 되고, 이상한 토큰을 샘플링할 확률이 훨씬 적어진다.
◦
코드에서는 top_p 값을 0과 1 사이의 값으로 설정하면 된다.
Sequence-to-sequence Models
•
인코더-디코더 모델(Encoder-Decoder models) 혹은 시퀀스-투-시퀀스 모델(sequence-to-sequence model)
•
번역(translation)이나 요약(summarization)과 같이 입력이 수반되는 생성 태스크(generative tasks)에 적합
•
•
•
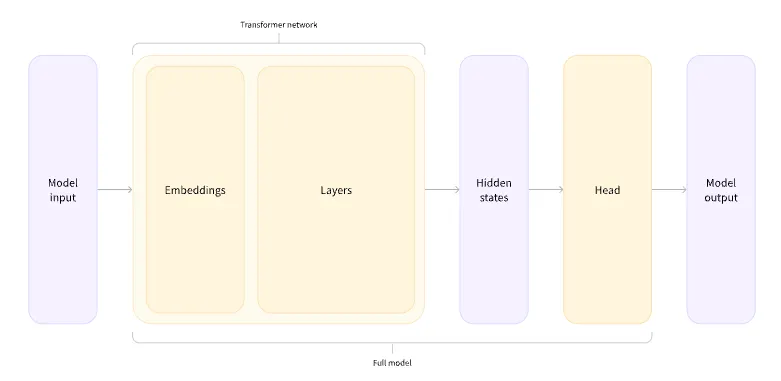
모델 헤드는 hidden state의 고차원 벡터를 입력으로 받아 다른 차원으로 투영한다.
•
모델 헤드는 보통 하나 이상의 선형 레이어로 이루어져 있다.
•
Transformer 모델의 출력은 처리할 모델 헤드로 바로 전달
•
이 다이어그램에서, 모델은 모델의 임베딩 레이어와 후속 레이어로 표현
•
임베딩 레이어는 토큰화된 각각의 입력 ID를 연관된 토큰을 나타내는 벡터로 변환
•
후속 레이어는 문장의 최종 표현을 만들기 위해 어텐션 메커니즘을 이용해 이 벡터들을 처리
•
Transformer에는 다양한 아키텍처가 있으며, 각각의 아키텍처는 특정 작업을 처리하도록 설계되었다.
•
ForSequenceClassification: 텍스트 분류는 텍스트에 레이블이나 클래스를 지정하는 Task
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")
text = "This was a masterpiece. Not completely faithful to the books, but enthralling from beginning to end. Might be my favorite of the three."
inputs = tokenizer(text, return_tensors="pt")
> inputs
{'input_ids': tensor([[ 101, 2023, 2001, 1037, 17743, 1012, 2025, 3294, 11633, 2000,
1996, 2808, 1010, 2021, 4372, 2705, 7941, 2989, 2013, 2927,
2000, 2203, 1012, 2453, 2022, 2026, 5440, 1997, 1996, 2093,
1012, 102]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1]])}
Python
복사
import torch
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model")
# 모델 예측
with torch.no_grad():
logits = model(**inputs).logits
Python
복사
> predicted_class_id = logits.argmax().item()
> model.config.id2label[predicted_class_id]
'LABEL_1'
Python
복사
•
ForTokenClassification: 토큰 분류는 문장의 개별 토큰에 라벨을 지정하는 Task
text = "The Golden State Warriors are an American professional basketball team based in San Francisco."
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
inputs = tokenizer(text, return_tensors="pt")
from transformers import AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
with torch.no_grad():
logits = model(**inputs).logits
predictions = torch.argmax(logits, dim=2)
predicted_token_class = [model.config.id2label[t.item()] for t in predictions[0]]
> predicted_token_class
Python
복사
['O',
'O',
'B-location',
'I-location',
'B-group',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'B-location',
'B-location',
'O',
'O']
Python
복사
•
ForQuestionAnswering: 질문 답변 작업은 질문에 대한 답변을 반환하는 Task
question = "How many programming languages does BLOOM support?"
context = "BLOOM has 176 billion parameters and can generate text in 46 languages natural languages and 13 programming languages."
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
inputs = tokenizer(question, context, return_tensors="pt")
import torch
from transformers import AutoModelForQuestionAnswering
model = AutoModelForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
with torch.no_grad():
outputs = model(**inputs)
answer_start_index = outputs.start_logits.argmax()
answer_end_index = outputs.end_logits.argmax()
> answer_start_index, answer_end_index
(tensor(9), tensor(0))
> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
> tokenizer.decode(predict_answer_tokens)
''
Python
복사
•
ForCausalLM: 텍스트 생성 Task
prompt = "Somatic hypermutation allows the immune system to"
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilgpt2")
inputs = tokenizer(prompt, return_tensors="pt").input_ids
> inputs
tensor([[ 50, 13730, 8718, 76, 7094, 3578, 262, 10900, 1080, 284]])
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
# generate -> 문장 생성
outputs = model.generate(inputs,
max_new_tokens=100,
do_sample=True,
top_k=50,
top_p=0.95)
> outputs
tensor([[ 50, 13730, 8718, 76, 7094, 3578, 262, 10900, 1080, 284,
39119, 2512, 257, 3108, 6644, 884, 355, 281, 395, 3202,
1143, 1582, 66, 7230, 13, 6660, 11, 262, 4165, 3061,
286, 428, 2050, 373, 284, 4659, 262, 5408, 286, 262,
7532, 290, 262, 3108, 15147, 2882, 284, 262, 8718, 76,
7094, 13, 3423, 11, 356, 12565, 262, 5408, 286, 7514,
15539, 291, 7408, 357, 5662, 32, 8, 290, 7514, 30584,
10641, 1460, 357, 47, 4090, 828, 543, 389, 6241, 287,
3294, 7652, 1141, 257, 2060, 6772, 286, 8718, 76, 7094,
13, 12280, 30584, 10641, 1460, 326, 3802, 262, 2685, 2884,
262, 279, 382, 547, 13906, 416, 350, 4090, 11, 543]])
Python
복사
> result = tokenizer.batch_decode(outputs, skip_special_tokens=True)
> result
['Somatic hypermutation allows the immune system to selectively block a pathogen such as anesthetized parcumin. Thus, the primary goal of this study was to assess the expression of the protein and the pathogenic response to the hypermutation. Here, we investigated the expression of polycyclic acid (PCA) and polysaccharides (PSA), which are expressed in multiple regions during a single cycle of hypermutation. Polysaccharides that enter the cell via the pore were activated by PSA, which']
Python
복사
•
ForMaskedLM: 마스킹된 Token 예측하는 Task
text = "The Milky Way is a <mask> galaxy."
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilroberta-base")
inputs = tokenizer(text, return_tensors="pt")
mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
from transformers import AutoModelForMaskedLM
model = AutoModelForMaskedLM.from_pretrained("distilbert/distilroberta-base")
# 모델 예측
logits = model(**inputs).logits
# 결과 확인
mask_token_logits = logits[0, mask_token_index, :]
> mask_token_logits.shape
torch.Size([1, 50265])
top_3_tokens = torch.topk(mask_token_logits, 3, dim=1).indices[0].tolist()
> for token in top_3_tokens:
> print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))
The Milky Way is a spiral galaxy.
The Milky Way is a dwarf galaxy.
The Milky Way is a massive galaxy.
Python
복사
•
ForSeq2SeqLM: 번역 Task
text = "translate English to French: Legumes share resources with nitrogen-fixing bacteria."
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google-t5/t5-small")
inputs = tokenizer(text, return_tensors="pt").input_ids
inputs
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("google-t5/t5-small")
outputs = model.generate(inputs,
max_new_tokens=40,
do_sample=True, top_k=30, top_p=0.95)
> tokenizer.decode(outputs[0], skip_special_tokens=True)
Les lègumes ont accès à des ressources avec des bactéries fixateurs d'azote.
Python
복사
•
ForSeq2SeqLM: 요약 Task
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google-t5/t5-small")
inputs = tokenizer(text, return_tensors="pt").input_ids
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("google-t5/t5-small")
outputs = model.generate(inputs, max_new_tokens=100, do_sample=False)
> tokenizer.decode(outputs[0], skip_special_tokens=True)
the inflation reduction act lowers prescription drug costs, health care costs, and energy costs. it's the most aggressive action on tackling the climate crisis in american history. it will ask the ultra-wealthy and corporations to pay their fair share.
Python
복사
•
ForMultipleChoice: 객관식 과제는 질의 응답과 비슷하지만, 몇 가지 후보 답변이 맥락과 함께 제공되고 모델이 올바른 답변을 선택하는 Task
prompt = "France has a bread law, Le Décret Pain, with strict rules on what is allowed in a traditional baguette."
candidate1 = "The law does not apply to croissants and brioche."
candidate2 = "The law applies to baguettes."
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
inputs = tokenizer([[prompt, candidate1], [prompt, candidate2]], return_tensors="pt", padding=True)
labels = torch.tensor(0).unsqueeze(0)
> inputs
{'input_ids': tensor([[ 101, 2605, 2038, 1037, 7852, 2375, 1010, 3393, 11703, 13465,
3255, 1010, 2007, 9384, 3513, 2006, 2054, 2003, 3039, 1999,
1037, 3151, 4524, 23361, 2618, 1012, 102, 1996, 2375, 2515,
2025, 6611, 2000, 13675, 10054, 22341, 2015, 1998, 7987, 3695,
5403, 1012, 102],
[ 101, 2605, 2038, 1037, 7852, 2375, 1010, 3393, 11703, 13465,
3255, 1010, 2007, 9384, 3513, 2006, 2054, 2003, 3039, 1999,
1037, 3151, 4524, 23361, 2618, 1012, 102, 1996, 2375, 12033,
2000, 4524, 23361, 4570, 1012, 102, 0, 0, 0, 0,
0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]])}
> labels
tensor([0])
from transformers import AutoModelForMultipleChoice
model = AutoModelForMultipleChoice.from_pretrained("google-bert/bert-base-uncased")
outputs = model(**{k: v.unsqueeze(0) for k, v in inputs.items()}, labels=labels)
logits = outputs.logits
predicted_class = logits.argmax().item()
> predicted_class
0
Python
복사
