Image Captioning: 이미지를 입력으로 넣었을 떄 어울리는 문장을 만들어내는 것
•
Classification : Whole Image + Single Label // ex) cat
•
Detection : Image Regions + Single Label // ex) cat, Skateboard
•
Captioning : Whole Image + Sequence // ex) A cat riding a skateboard
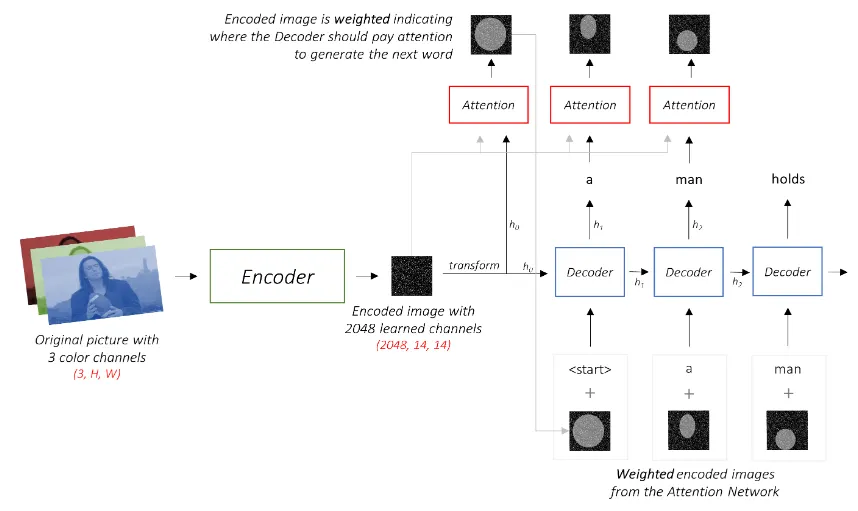
Main structure of Model
•
미리 학습된 CNN 모델은 사물의 종류와 질감, 관계 등 다양한 시각적 의미가 담긴 Feature vector를 추출할 수 있다.
◦
이 Feature vector는 디코더의 첫 입력이 된다.
•
디코더는 이미지의 Feature vector와 현재까지의 Word embedding으로부터 적절한 다음 단어를 예측하는 방식으로 문장을 구성
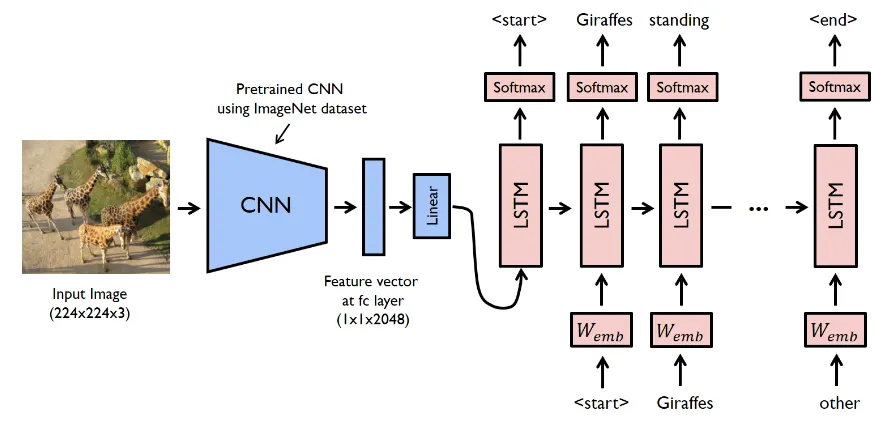
Encoder
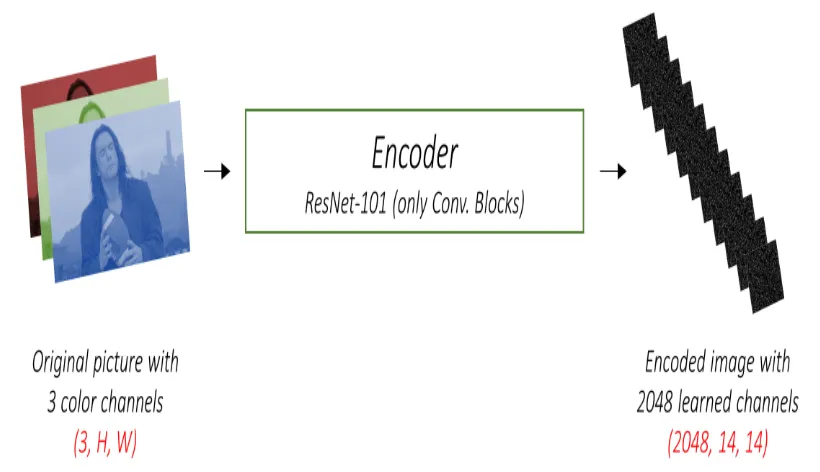
Decoder
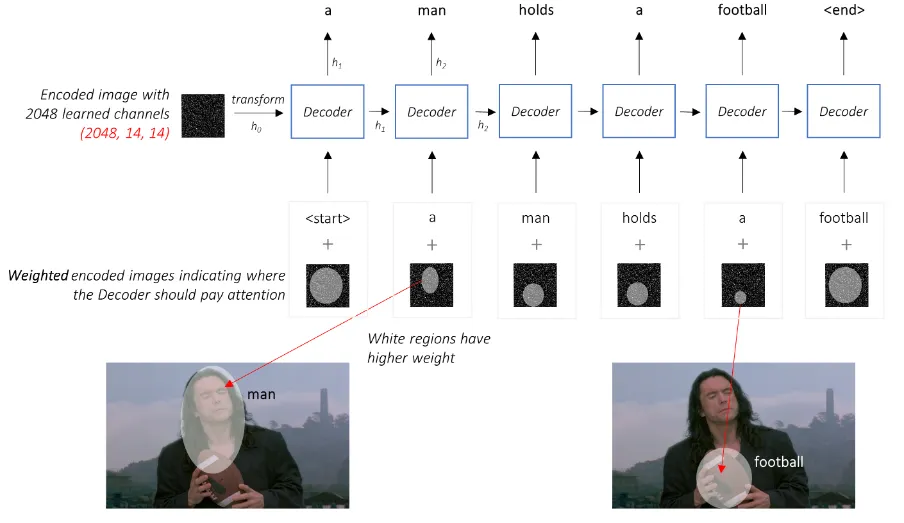
Embed Attention Mechanism
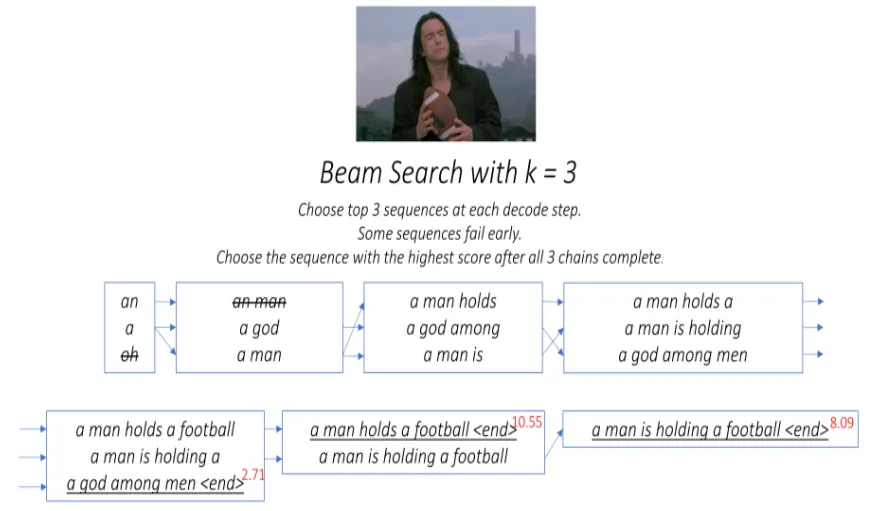
Inference
•
첫 번째 디코드 단계에서는 상위 k개의 후보를 고려한다.
◦
이러한 k개의 첫 번째 단어 각각에 대해 k개의 두 번째 단어를 생성한다.
•
가산점수를 고려하여 상위 k개 [첫 번째 단어, 두 번째 단어] 조합을 선택
•
k개의 두 번째 단어 각각에 대해 k개의 세 번째 단어를 선택하고, 상위 k개의 [첫 번째 단어, 두 번째 단어, 세 번째 단어] 조합을 선택
•
각 디코드 단계에서 반복
◦
k개의 시퀀스가 종료된 후 전체 점수가 가장 높은 시퀀스를 선택한다.