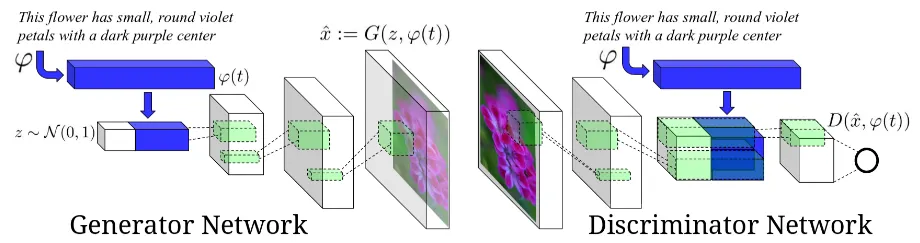
Network Architecture
•
Generator:
•
Discriminator:
◦
T: dim of text description embedding
◦
D: dim of text image embedding
◦
Z: dim of noise
DCGAN
•
DCGAN은 GAN에 Convolutional NN Layer를 적용하여 training을 안정화했고, GAN의 Generator와 Discriminator의 내부 네트워크를 이해할 수 있게 했다.
•
Convolutional RNN으로 encoding한 text features와 DCGAN을 활용해서 이미지를 합성한다.
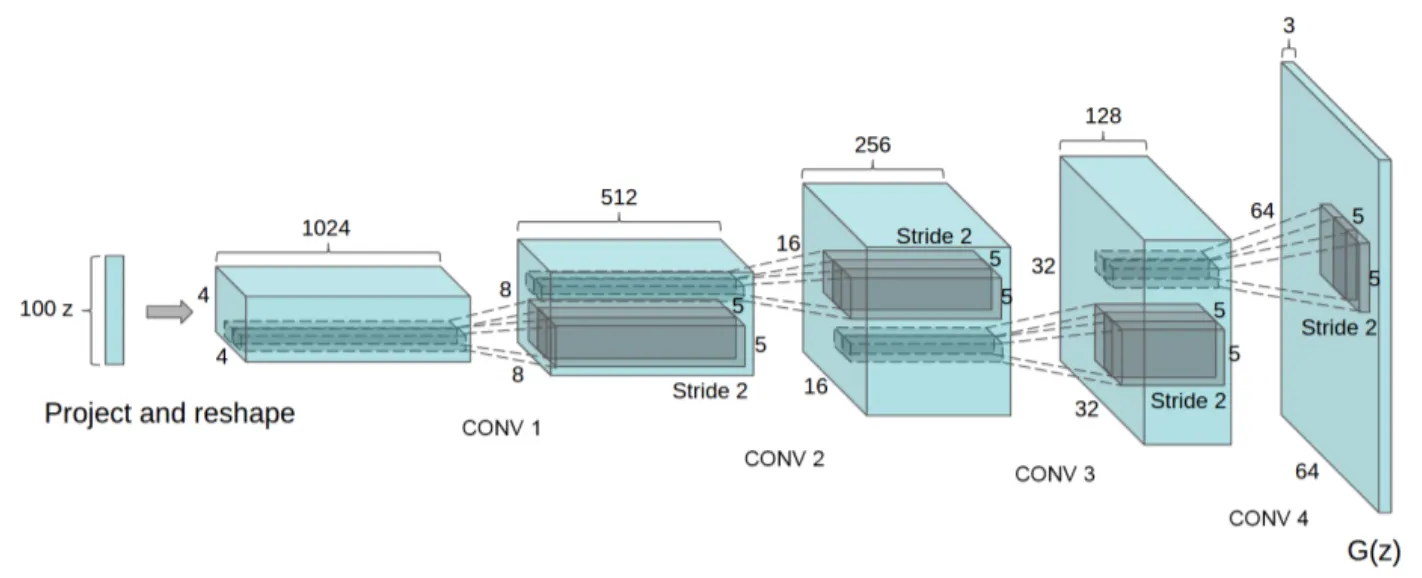
Generator
1.
text encoder φ를 사용해서 text query t를 encoding 한다.
2.
encoding의 결과값(φ(t))을 FC layer에 넣어 compress한 후 Leaky-ReLU를 사용해서 128-dim의 작은 차원으로 compression한다.
3.
이 값을 noise vector z와 concate한후 deconvolutional network를 통해 generate image를 얻는다.
Discriminator
1.
stride-2 convolution layer와 BN기법, leaky ReLU function을 이용해서 학습을 한다.
2.
1번의 과정을 4x4 conv layer가 될때까지 반복한다. (여러개의 layer를 쌓음)
3.
4x4 conv layer가 되면 compressiong된 embedding vector φ를 여러개 복사해서 conv layer 뒤에 이어붙인다.(depth concatenation)
4.
1x1 conv layer가 되도록 연산을 한 후 final score를 얻는다.
5.
이때 모든 conv layer에 대해서 BN을 해준다.
Matching-aware discriminator (GAN-CLS)
•
conditional GAN은 discriminator가 (text, images) pair가 진짜인지 가짜인지 판단하도록 학습한다.

이때 문제점은 discriminator는 real training image가 어떤 text embedding context와 match되는지 모른다는 점이다.
•
즉, real image가 자기를 설명하지 않은 text와 match될 수도 있다. (mismatch)
•
따라서 (real image, mismatched text term)을 추가하도록 GAN training algorithm을 수정하여 discriminator가 fake에 대해서도 학습을 할 수 있게 한다.

Learning with manifold interpolation (GAN-INT)
•
우리가 네트워크를 학습시킬 때에는 주어진 text만을 가지고 image를 만들지만, 실제로 이를 사용할 때에는 training dataset에 없는 text를 줘도 image를 생성할 수 있어야 한다.
•
즉, training dataset에 있는 text와 비슷한 text를 입력했을 때에도 image를 생성해야하기 때문에 interpolation의 방식을 사용하면 조금 더 효과적으로 학습을 할 수 있게 된다.
Inverting the generator for style transferPermalink
•
text encoding φ(t)는 image content(ex. flower shape, colors)를 찾아내는 역할을 한다.
•
(text에서 이미지로 표현할 만한 feature들을 추출) 이미지를 생성하려면 사물의 특징들을 잘 추출하여 생성하는 것도 중요하지만, 그 외의 정보들(ex.배경이나 자세)들을 생성하는 것도 중요하다.
Qualitative Results

•
XLNet은 당시 대부분의 NLP 테스크들에서 state-of-the-art 성능을 달성하고 있던 BERT를 큰 차이로 outperform 하면서 파장을 일으켰다.
•
XLNet은 GPT로 대표되는 auto-regressive(AR) 모델과 BERT로 대표되는 auto-encoder(AE) 모델의 장점만을 합한 generalized AR pretraining model이다.