•
TensorBoard는 머신러닝 실험을 위한 시각화 툴킷(toolkit)
•
TensorBoard를 사용하면 손실 및 정확도와 같은 측정 항목을 추적 및 시각화하는 것, 모델 그래프를 시각화하는 것, 히스토그램을 보는 것, 이미지를 출력하는 것 등이 가능
PyTorch로 TensorBoard 사용하기
•
먼저 SummaryWriter 인스턴스를 생성
import torch
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
Python
복사
◦
Writer는 기본적으로 ./runs/ 디렉터리에 출력
# 입력 데이터 생성
x = torch.arange(-5, 5, 0.1).view(-1, 1) # 입력값 x를 -5에서 5까지 생성
y = -5 * x + 0.1 * torch.randn(x.size()) # y는 x에 노이즈를 더한 값
# 모델, 손실 함수, 옵티마이저 설정
model = torch.nn.Linear(1, 1) # 선형 회귀 모델
criterion = torch.nn.MSELoss() # 평균 제곱 오차 손실 함수
optimizer = torch.optim.SGD(model.parameters(), lr=0.1) # SGD 옵티마이저
# 모델 학습 함수
def train_model(iter):
for epoch in range(iter):
model.train() # 모델을 학습 모드로 설정
y1 = model(x) # 모델의 예측값 계산
loss = criterion(y1, y) # 손실 값 계산
# TensorBoard에 epoch, 손실 값(loss) 기록
writer.add_scalar("Loss/sample", loss.item(), epoch) # 손실을 TensorBoard에 기록 (그래프 이름, y축 데이터, x축 데이터)
optimizer.zero_grad() # 기울기 초기화
loss.backward() # 역전파를 통해 기울기 계산
optimizer.step() # 옵티마이저 스텝을 통해 파라미터 업데이트
# 모델 학습 (10번의 에포크 동안)
train_model(10)
# 기록된 데이터 저장
writer.flush()
writer.close()
Python
복사
%load_ext tensorboard
%tensorboard --logdir=runs
Python
복사
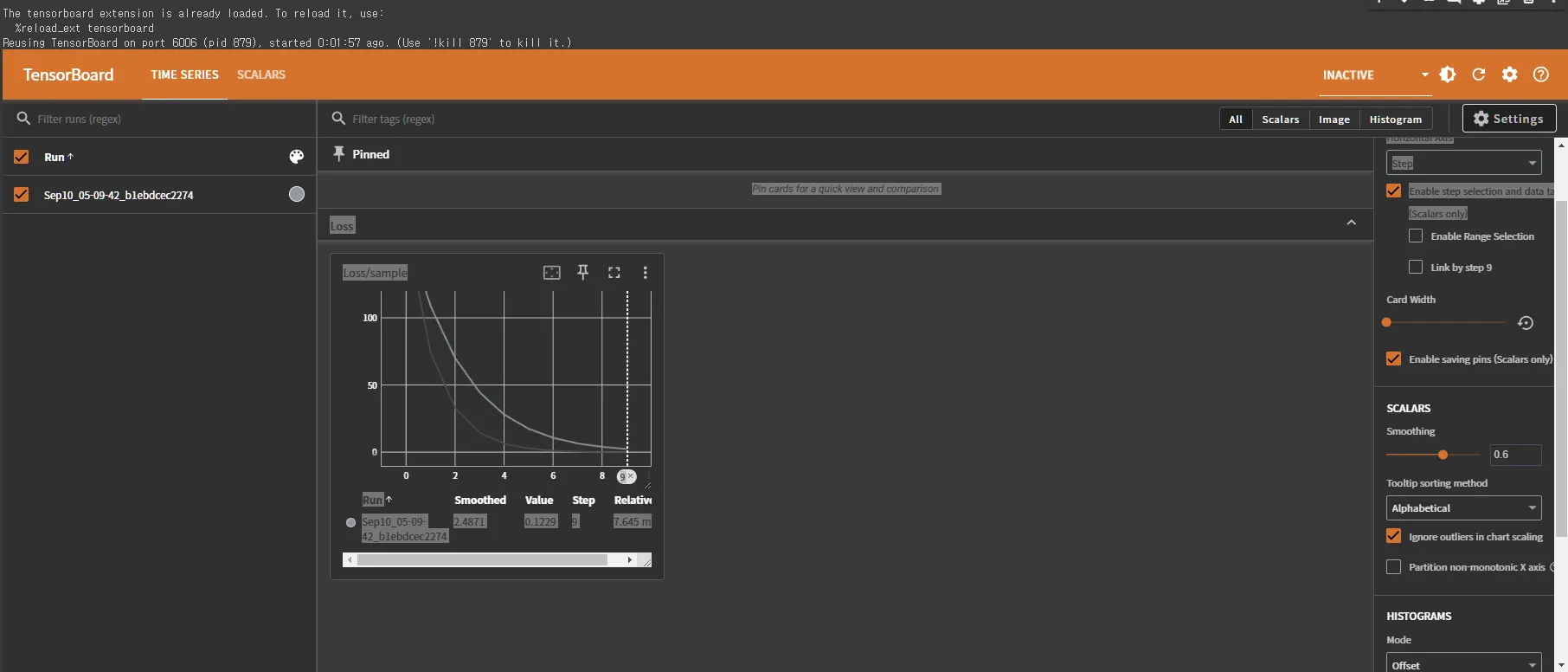
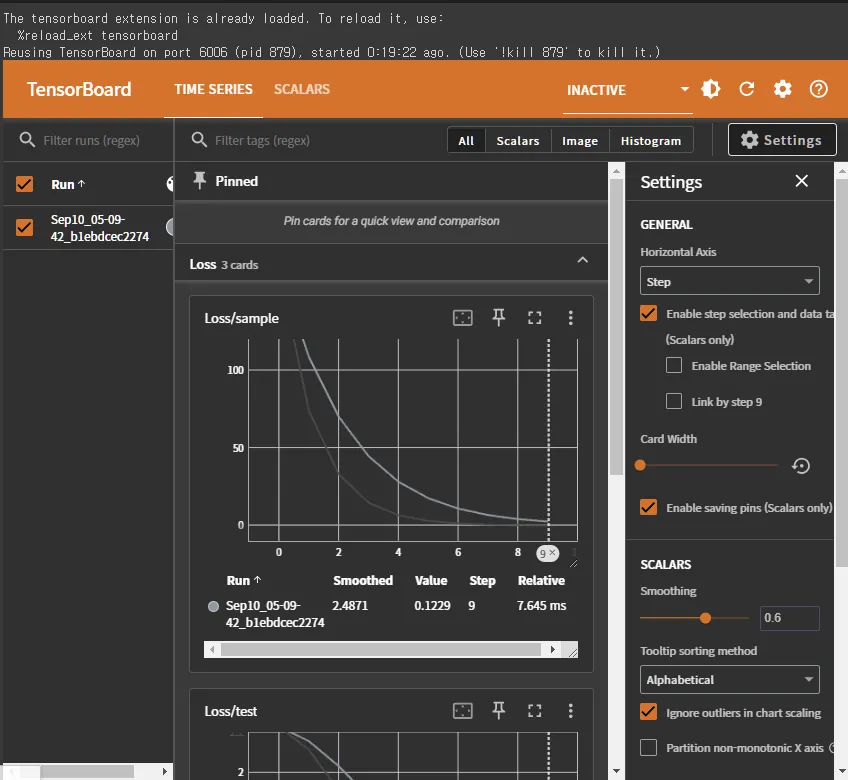
나오는 화면
Full implementation
•
사전에 필요한 작업들
1.
데이터 불러오기
2.
모델 설정
3.
하이퍼파라미터 설정
4.
Backpropagation
•
optimizer.zero_grad()
역전파 단계를 실행하기 전에 각 파라미터들의 변화도(gradient)를 0으로 재설정
•
loss.backward()
역전파 단계: 모델의 학습 가능한 모든 매개변수에 대해 손실의 변화도 계산
•
optimizer.step()
변화도를 계산한 뒤에 optimizer.step()을 호출하여 역전파 단계에서 수집된 변화도로 매개변수 조정
def train_loop(dataloader, model, loss_fn, optimizer, epoch):
size = len(dataloader.dataset) # 데이터셋의 전체 크기를 저장한다.
for batch, (X, y) in enumerate(dataloader): # dataloader에서 데이터를 배치 단위로 가져온다.
# Compute prediction and loss (예측과 손실 계산)
pred = model(X) # 모델을 사용하여 입력 X에 대한 예측을 수행한다.
loss = loss_fn(pred, y) # 예측 결과와 실제 값(y)을 비교하여 손실을 계산한다.
writer.add_scalar("Loss/train", loss, epoch) # 현재 에포크에서의 훈련 손실 값을 기록한다.
# Backpropagation (역전파)
optimizer.zero_grad() # 이전 배치에서의 기울기를 초기화한다.
loss.backward() # 손실에 대한 기울기를 계산한다.
optimizer.step() # 계산된 기울기를 사용하여 모델의 파라미터를 업데이트한다.
if batch % 100 == 0: # 100 배치마다 출력
loss, current = loss.item(), batch * len(X) # 손실 값을 가져오고, 현재 배치까지의 데이터 양을 계산한다.
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]") # 손실 값과 진행 상황을 출력한다.
Python
복사
def test_loop(dataloader, model, loss_fn, epoch):
size = len(dataloader.dataset) # 테스트 데이터셋의 전체 크기를 저장한다.
test_loss, correct = 0, 0 # 총 손실과 맞춘 예측 수를 초기화한다.
with torch.no_grad(): # 기울기 계산을 하지 않도록 설정 (테스트에서는 필요 없음)
for X, y in dataloader: # dataloader에서 테스트 데이터를 배치 단위로 가져온다.
pred = model(X) # 모델을 사용하여 입력 X에 대한 예측을 수행한다.
loss = loss_fn(pred, y) # 예측 결과와 실제 값(y)을 비교하여 손실을 계산한다.
writer.add_scalar("Loss/test", loss, epoch) # 현재 에포크에서의 테스트 손실 값을 기록한다.
test_loss += loss.item() # 손실 값을 누적하여 총 손실을 계산한다.
correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 맞춘 예측의 수를 계산한다.
test_loss /= size # 평균 손실 값을 계산한다.
correct /= size # 정확도를 계산한다.
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n") # 테스트 결과를 출력한다.
Python
복사
loss_fn = nn.CrossEntropyLoss() # 손실 함수로 CrossEntropyLoss를 사용한다. 다중 클래스 분류 문제에서 자주 사용된다.
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) # 옵티마이저로 SGD(확률적 경사하강법)를 사용한다. 학습률(lr)을 설정하여 파라미터 업데이트 속도를 조절한다.
epochs = 10 # 전체 학습할 에포크 수를 설정한다.
for epoch in range(epochs): # 각 에포크에 대해 반복한다.
print(f"Epoch {epoch+1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer, epoch) # 훈련 루프를 실행한다.
test_loop(test_dataloader, model, loss_fn, epoch) # 테스트 루프를 실행하여 모델을 평가한다.
writer.flush() # 텐서보드에 기록된 데이터를 저장 및 출력한다.
print("Done!") # 학습이 완료되었음을 알린다.
Python
복사
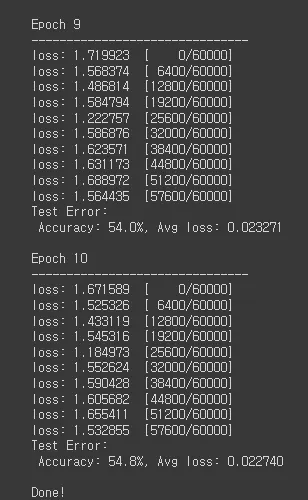
TensorBoard
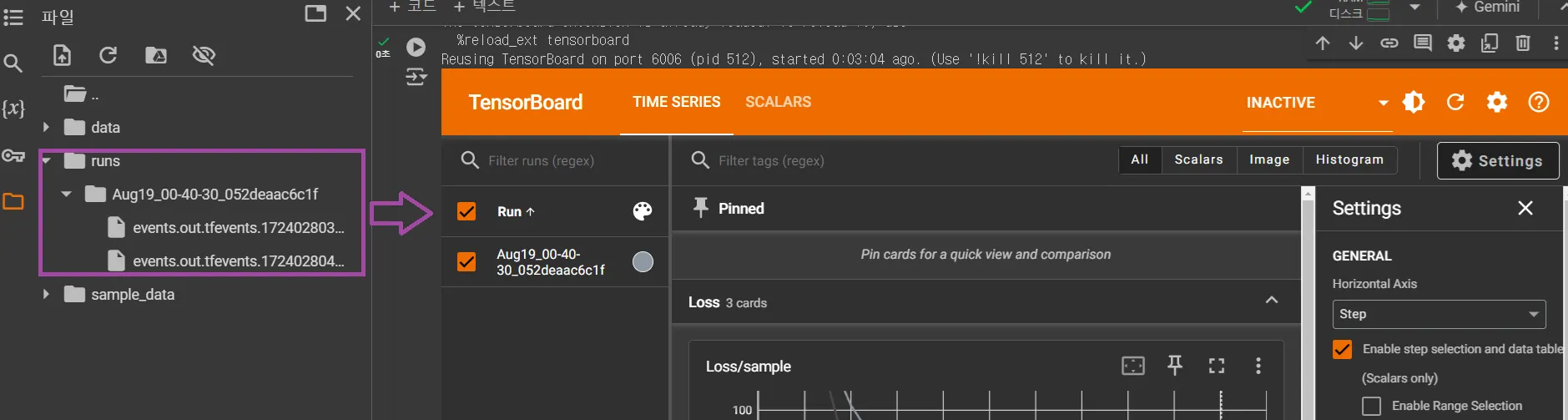
writer.close()
%load_ext tensorboard
%tensorboard --logdir=runs
Python
복사