


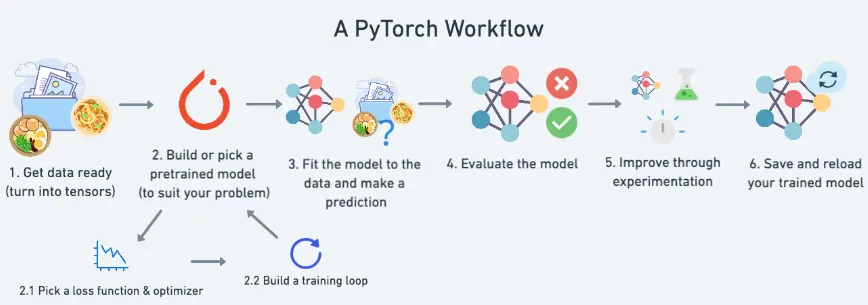
Pytorch Workflow
import torch
from torch import nn # nn contains all of PyTorch's building blocks for neural networks
import matplotlib.pyplot as plt
plt.ion()
# Check PyTorch version
> torch.__version__
2.4.0+cu121
Python
복사
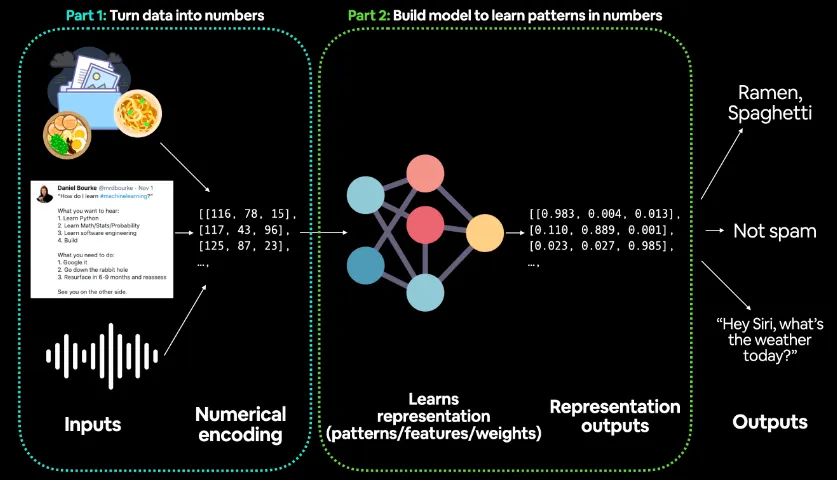
Part 1: 데이터를 숫자로 변환 (Turn data into numbers)
•
첫 번째 단계는 다양한 형태의 입력 데이터를 모델이 처리할 수 있는 숫자 형태로 변환하는 과정이다.
•
입력 데이터는 다음과 같은 형태로 들어올 수 있다:
◦
이미지 데이터: 음식 사진, 또는 다른 시각적 정보
◦
텍스트 데이터: 트윗, 뉴스 기사 등의 문장
◦
음성 데이터: 음성 명령, 대화 등
•
이러한 데이터는 각각 고유한 방식으로 **숫자 데이터(numerical encoding)**로 변환된다.
•
예를 들어:
◦
이미지의 경우, 픽셀값을 숫자로 표현할 수 있으며, 각 픽셀은 특정한 색상 값을 가진다.
◦
텍스트의 경우, 단어 또는 문장을 벡터화(벡터 임베딩)하여 숫자로 변환한다. 각 단어는 고유한 숫자 벡터로 변환되며, 이는 단어 간 유사성을 반영한다.
◦
음성 데이터는 진폭(amplitude) 값이나 주파수(frequency) 값으로 변환되어 수치 데이터로 표현된다.
•
그림에서는 이러한 입력 데이터가 숫자 배열(예: [[116, 78, 15], [117, 43, 96], [125, 87, 23]])로 변환되고 있음을 보여준다.
•
이 단계에서 중요한 것은, 모델이 학습할 수 있도록 모든 입력이 숫자로 인코딩된다는 점이다.
Part 2: 패턴을 학습하는 모델 구축 (Build model to learn patterns in numbers)
•
두 번째 단계는 딥러닝 모델이 숫자 데이터를 입력받아 패턴을 학습하는 과정이다. 그림의 중앙에는 신경망(neural network) 구조가 보이며, 이 네트워크는 데이터를 처리하고 학습한다.
•
이 과정에서 모델은 다음과 같은 작업을 수행한다:
◦
표현 학습(representation learning): 입력된 숫자 데이터를 바탕으로 패턴을 찾고, 중요한 특징(feature)을 추출한다. 이는 가중치(weights) 및 매개변수(parameters)를 학습하는 과정을 포함한다.
◦
숫자 간의 관계 학습: 다양한 레이어(layer)를 거치며, 각 데이터가 가지는 의미 있는 패턴을 파악하게 된다. 예를 들어, 음식 사진을 통해 음식의 종류를 학습하거나, 텍스트를 통해 스팸 여부를 판별하는 과정을 학습한다.
•
그림에서 출력되는 Representation outputs는 모델이 입력 데이터를 바탕으로 학습한 패턴을 바탕으로 숫자 벡터로 출력한 결과이다.
•
예시로 [(0.983, 0.004, 0.013), (0.110, 0.889, 0.001), (0.023, 0.027, 0.985)] 같은 벡터가 표현된다.
Outputs (최종 출력)
•
최종적으로 모델은 학습된 패턴을 바탕으로 결과값을 출력한다. 예를 들어:
◦
이미지 데이터의 경우, "라면", "스파게티"와 같은 음식 종류를 분류할 수 있다.
◦
텍스트 데이터의 경우, 스팸 메시지를 분류하여 "스팸 아님(Not Spam)"이라고 판단할 수 있다.
◦
음성 데이터의 경우, "Hey Siri, what’s the weather today?"와 같은 명령을 이해하여 날씨 정보를 제공하는 것처럼, 모델이 적절한 응답을 반환한다.
1.데이터 준비
데이터 생성
•
선형 회귀식:
# Create *known* parameters
weight = 0.7
bias = 0.3
Python
복사
# Create data
start = 0
end = 1
step = 0.02
# torch.arange(start, end, step) -> [0, 0.02, 0.04, 0.06 ... ] -> (50,)
# (50,).unsqueeze(dim=1) -> (50,1)
X = torch.arange(start, end, step).unsqueeze(dim=1)
> X.shape
torch.Size([50, 1])
Python
복사
y = weight * X + bias
> y.shape
torch.Size([50, 1])
Python
복사
> X[:5], y[:5]
# X는 변환 전, y는 변환 후
(tensor([[0.0000],
[0.0200],
[0.0400],
[0.0600],
[0.0800]]),
tensor([[0.3000],
[0.3140],
[0.3280],
[0.3420],
[0.3560]]))
Python
복사
데이터 분리
# Create train/test split
train_split = int(0.8 * len(X)) # 80% of data used for training set, 20% for testing
X_train, y_train = X[:train_split], y[:train_split]
X_test, y_test = X[train_split:], y[train_split:]
> len(X_train), len(y_train), len(X_test), len(y_test)
(40, 40, 10, 10)
Python
복사
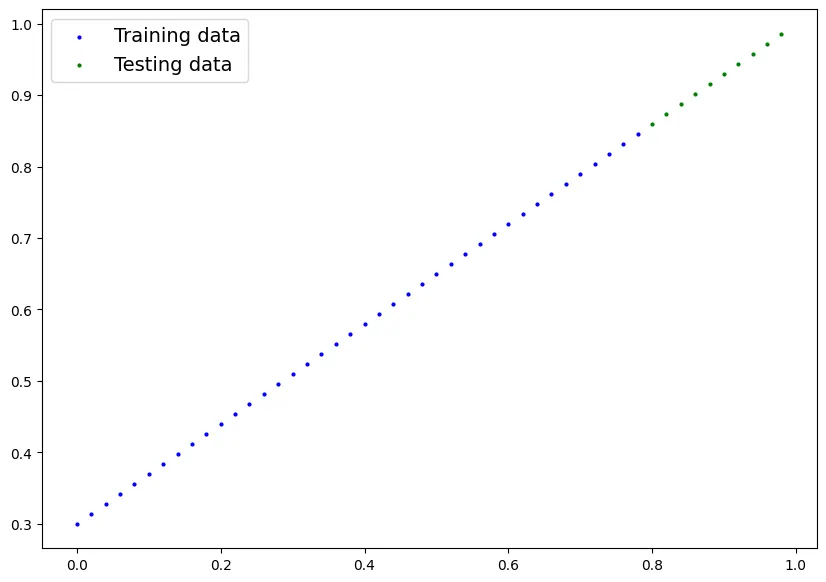
데이터 확인
def plot_predictions(
train_data=X_train,
train_labels=y_train,
test_data=X_test,
test_labels=y_test,
predictions=None):
"""
Plots training data, test data and compares predictions.
"""
plt.figure(figsize=(10, 7))
# Plot training data in blue
plt.scatter(train_data, train_labels, c="b", s=4, label="Training data")
# Plot test data in green
plt.scatter(test_data, test_labels, c="g", s=4, label="Testing data")
if predictions is not None:
# Plot the predictions in red (predictions were made on the test data)
plt.scatter(test_data, predictions, c="r", s=4, label="Predictions")
# Show the legend
plt.legend(prop={"size": 14});
plot_predictions();
Python
복사
2.모델링 정의
모델 정의
# 선형 회귀 모델 클래스를 생성
class LinearRegressionModel(nn.Module):
# <- PyTorch에서 거의 모든 것은 nn.Module을 상속받아 만듦
# (신경망의 기본 블록이라고 생각할 수 있음)
def __init__(self):
# super().__init__() -> 부모 클래스를 인스턴스화
super().__init__()
# 가중치(weights)를 초기화 -> 랜덤 값으로 생성
self.weights = nn.Parameter(torch.randn(1,
# <- 학습이 진행되면서 조정될 가중치를 무작위 값으로 설정
dtype=torch.float),
# <- PyTorch는 기본적으로 float32 형식을 사용
requires_grad=True)
# <- 이 값을 경사하강법(gradient descent)으로 업데이트할 수 있는가?
# 편향(bias)을 초기화 -> 랜덤 값으로 생성
self.bias = nn.Parameter(torch.randn(1,
# <- 학습이 진행되면서 조정될 편향을 무작위 값으로 설정
dtype=torch.float),
# <- PyTorch는 기본적으로 float32 형식을 사용
requires_grad=True)
# <- 이 값을 경사하강법으로 업데이트할 수 있는가?
# forward는 모델에서 계산 과정을 정의
def forward(self, x: torch.Tensor) -> torch.Tensor:
# <- "x"는 입력 데이터 (예: 훈련 또는 테스트 데이터의 특징)
# 선형 회귀 공식
pred = self.weights * x + self.bias # <- 이것은 선형 회귀 공식 (y = m*x + b)
return pred # 선형 회귀 모델의 예측값을 반환
Python
복사

# 생성한 nn.Module 서브클래스 내의 nn.Parameter들을 확인한다
> list(model_0.parameters())
[Parameter containing:
tensor([0.3367], requires_grad=True),
Parameter containing:
tensor([0.1288], requires_grad=True)]
# List named parameters
> model_0.state_dict()
OrderedDict([('weights', tensor([0.3367])), ('bias', tensor([0.1288]))])
Python
복사
학습하기 전 모델 예측
# Make predictions with model
# with torch.no_grad()와 의미가 같다!!!
# -> 모델의 파라미터가 변경되는 것을 방지한다.
with torch.inference_mode():
y_preds = model_0(X_test)
Python
복사
# Check the predictions
> print(f"Number of testing samples: {len(y_test)}")
> print(f"Number of predictions made: {len(y_preds)}")
Number of testing samples: 10
Number of predictions made: 10
> plot_predictions(predictions=y_preds)
Python
복사
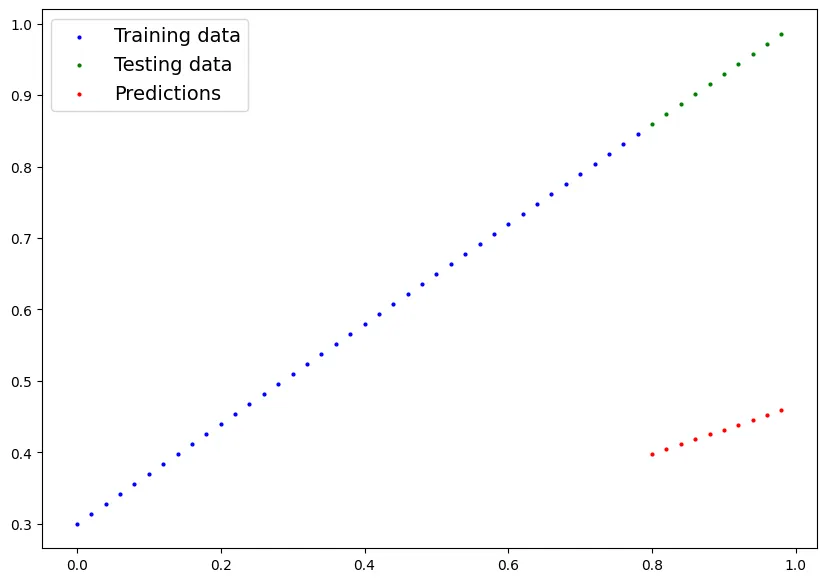
•
아래 그래프와 같이 모델 학습을 하기 전에는 예측과 살제가 많이 차이나는 것을 확인할 수 있다.
3.모델 학습
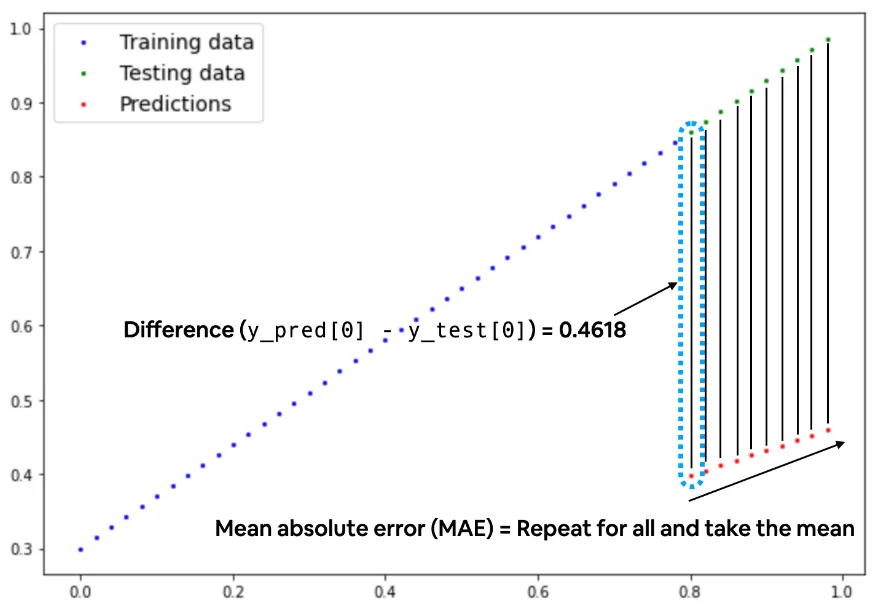
•
아래 그래프와 같이 실제값과 예측값의 차이를 줄이는 방향으로 모델이 학습을 하게 된다.
Loss function & Optimizer
•
Loss function: 실제값과 예측값의 차이를 계산하는 함수
•
Optimizer: 모델이 학습하는 방법
Loss function
•
회귀 작업 (Regression Tasks)
◦
▪
이 손실 함수는 예측 값과 실제 값의 차이를 제곱하여 평균을 낸 값이다.
▪
오차가 클수록 큰 패널티를 부과하며, 회귀 문제에서 가장 흔히 사용된다.
▪
공식:
◦
▪
예측 값과 실제 값 사이의 차이를 절대값으로 구해 평균을 낸 값이다.
▪
오차에 대한 패널티가 MSE보다 덜 극단적이다.
▪
공식:
•
이진 분류 작업 (Binary Classification Tasks)
◦
nn.BCELoss (Binary Cross Entropy Loss)
▪
이 손실 함수는 이진 분류 문제에서 사용되며, 예측된 확률과 실제 클래스 값(0 또는 1) 간의 차이를 측정한다.
▪
주로 시그모이드 함수와 함께 사용되어 예측 값을 0과 1 사이의 확률로 변환한 후 손실을 계산한다.
▪
공식:
◦
▪
nn.Sigmoid와 nn.BCELoss를 결합한 형태
▪
따로 시그모이드 함수를 적용할 필요 없이 바로 사용 가능하다.
▪
내부적으로 시그모이드를 적용한 후 BCE 손실을 계산한다.
▪
이 방식은 수치적으로 더 안정적이며, 따로 시그모이드를 적용하는 것보다 성능이 좋다.
•
다중 클래스 분류 작업 (Multi-class Classification Tasks)
◦
nn.CrossEntropyLoss (교차 엔트로피 손실)
◦
nn.LogSoftmax와 nn.NLLLoss(Negative Log Likelihood Loss)를 결합한 형태
◦
LogSoftmax는 각 클래스의 예측 확률을 구하고, NLLLoss는 예측 확률과 실제 클래스 간의 차이를 기반으로 손실을 계산한다.
◦
공식:
▪
C : 클래스의 수
▪
: 모델이 예측한 각 클래스에 대한 확률
# Create the loss function
loss_fn = nn.L1Loss() # MAE loss is same as L1Loss >> L2Loss(Mean Squared Error): nn.MSELoss
Python
복사
학습
•
학습전 준비물
◦
데이터: features, target
▪
train data, test data
◦
lose function
◦
Optimization
◦
model
Training loop
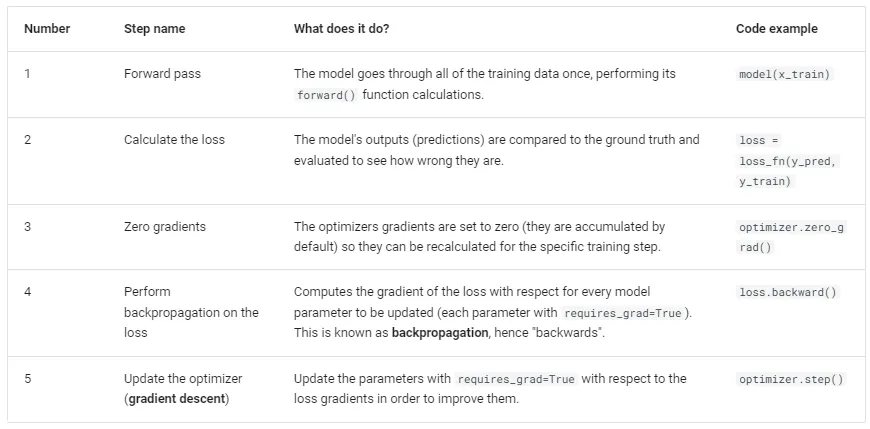
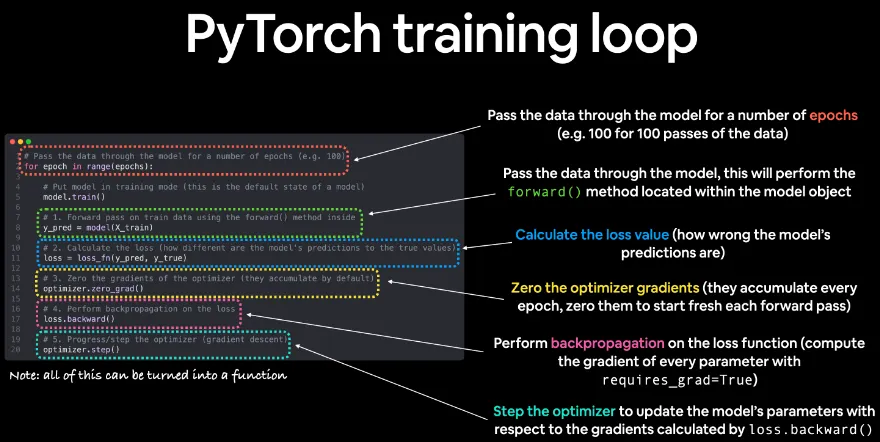
1.
Forward Pass (순방향 전파)
•
역할
◦
모델이 입력 데이터를 받아 forward() 메서드를 통해 계산을 수행한다.
◦
이를 통해 모델은 입력 데이터를 기반으로 예측값을 생성한다.
•
설명
◦
이 단계에서는 모델이 학습 데이터를 통과시키면서 예측 값을 계산한다.
◦
이 계산은 모델이 학습할 특징(feature)과 현재까지의 파라미터(weights, bias)를 기반으로 이루어진다.
•
코드 예시: model(x_train)
◦
x_train은 훈련 데이터를 의미하며, 모델은 이 데이터를 사용해 예측 값을 만든다.
2.
Calculate the Loss (손실 계산)
•
역할
◦
모델의 예측값과 실제 정답(레이블)을 비교하여 손실을 계산한다.
◦
이 손실 값은 모델이 얼마나 잘못 예측했는지를 나타낸다.
•
설명
◦
손실 함수는 예측 값과 실제 값 사이의 차이를 측정한다.
◦
회귀 작업에서는 주로 MSE, 분류 작업에서는 CrossEntropy 등이 사용된다.
•
코드 예시: loss = loss_fn(y_pred, y_train)
◦
y_pred는 모델이 예측한 값이고, y_train은 실제 값(정답 레이블)이다.
◦
loss_fn은 손실 함수(예: MSELoss, CrossEntropyLoss 등)를 의미한다.
3.
Zero Gradients (기울기 초기화)
•
역할
◦
매번 학습 스텝을 시작할 때, 이전 스텝에서 계산된 기울기(gradient)를 0으로 초기화한다.
◦
기울기는 자동으로 축적되기 때문에, 이를 초기화하지 않으면 잘못된 값이 누적될 수 있다.
•
설명
◦
경사 하강법(gradient descent)을 사용해 모델을 업데이트할 때, 매번 새로운 기울기를 계산할 수 있도록 기존의 기울기 값을 0으로 설정한다.
•
코드 예시: optimizer.zero_grad()
◦
옵티마이저(optimizer)가 모든 파라미터의 기울기를 0으로 초기화한다.
4.
Perform Backpropagation (역전파 수행)
•
역할
◦
손실 함수를 기준으로 모든 학습 가능한 파라미터에 대한 기울기를 계산한다.
◦
이를 통해 파라미터가 어느 방향으로 얼마나 업데이트되어야 하는지 결정한다.
•
설명
◦
역전파(backpropagation)는 손실에 대한 각 파라미터의 기울기를 계산하는 과정이다.
◦
PyTorch는 이를 자동으로 처리하며, 이를 통해 가중치와 편향을 업데이트할 수 있는 정보가 제공된다.
•
코드 예시: loss.backward()
◦
backward() 함수는 손실 함수의 값이 각 파라미터에 미치는 영향을 계산한다.
5.
Update the Optimizer (옵티마이저 업데이트)
•
역할
◦
앞서 계산된 기울기를 기반으로 파라미터를 업데이트한다.
◦
이는 경사 하강법 등의 최적화 기법을 통해 이루어진다.
•
설명
◦
옵티마이저는 모델의 파라미터(weights, bias)를 업데이트하여 손실을 줄이는 방향으로 모델을 학습시킨다.
◦
가장 일반적으로 사용되는 옵티마이저는 Adam 또는 SGD이다.
•
코드 예시: optimizer.step()
◦
옵티마이저는 계산된 기울기를 바탕으로 모델의 파라미터를 업데이트한다.
Testing Loop

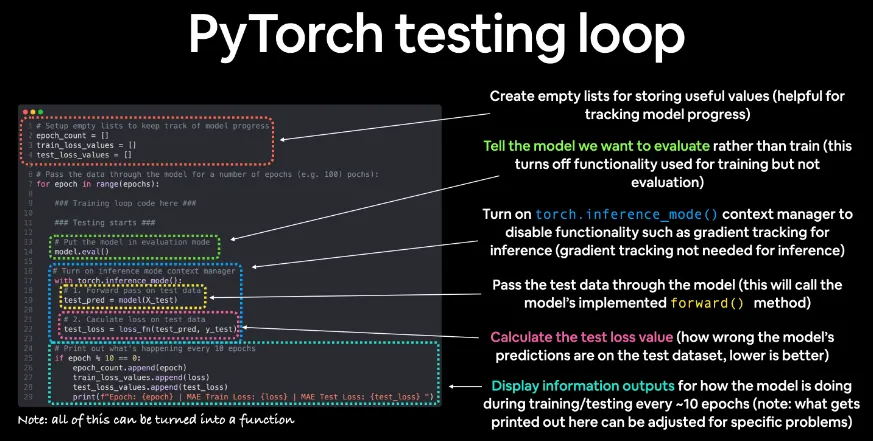
학습 실행(with 코드)
# 재현성을 위해 랜덤 시드를 설정한다
torch.manual_seed(42)
# 에폭 수를 설정한다 (모델이 학습 데이터를 몇 번 반복해서 학습할지 결정한다)
epochs = 100
# 손실 값을 추적하기 위해 빈 리스트를 생성한다
train_loss_values = []
test_loss_values = []
epoch_count = []
for epoch in range(epochs):
#########################################################################
### 학습 루프
#########################################################################
# 모델을 학습 모드로 전환한다 (모델의 기본 상태이다)
model_0.train()
# 1. 학습 데이터에 대해 순전파를 수행한다 (forward() 메서드를 사용한다)
y_pred = model_0(X_train)
# print(y_pred)
# 2. 손실을 계산한다 (모델의 예측과 실제 값의 차이를 측정한다)
loss = loss_fn(y_pred, y_train)
# 3. 옵티마이저의 기울기를 초기화한다
optimizer.zero_grad()
# 4. 손실에 대해 역전파를 수행한다
loss.backward()
# 5. 옵티마이저를 업데이트한다
optimizer.step()
#########################################################################
### 테스트 루프
#########################################################################
# 모델을 평가 모드로 전환한다
model_0.eval()
with torch.inference_mode():
# 1. 테스트 데이터에 대해 순전파를 수행한다
test_pred = model_0(X_test)
# 2. 테스트 데이터에 대한 손실을 계산한다
test_loss = loss_fn(test_pred, y_test.type(torch.float))
# 예측값은 torch.float 데이터 타입으로 나오므로, 비교는 동일한 타입의 텐서로 수행해야 한다
# 진행 상황을 출력한다
if epoch % 10 == 0:
epoch_count.append(epoch)
# loss.detach() -> loss가 포함된 텐서를 현재 디바이스에서 분리한다
# loss.detach().numpy() -> torch 텐서를 numpy 배열로 변환한다
train_loss_values.append(loss.detach().numpy())
test_loss_values.append(test_loss.detach().numpy())
print(f"Epoch: {epoch} | MAE Train Loss: {loss} | MAE Test Loss: {test_loss} ")
Python
복사
학습 결과
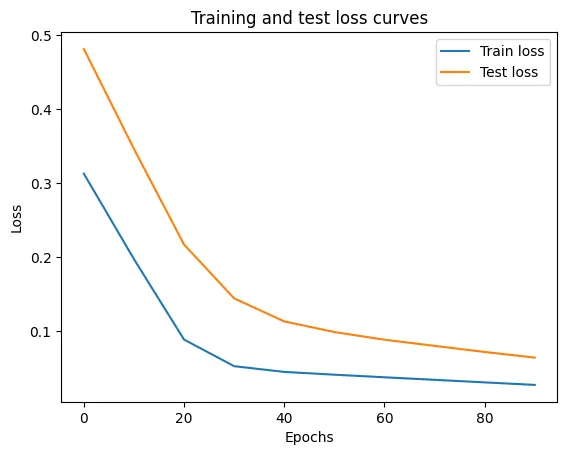
# Plot the loss curves
plt.plot(epoch_count, train_loss_values, label="Train loss")
plt.plot(epoch_count, test_loss_values, label="Test loss")
plt.title("Training and test loss curves")
plt.ylabel("Loss")
plt.xlabel("Epochs")
plt.legend();
Python
복사
# Find our model's learned parameters
print("The model learned the following values for weights and bias:")
print(model_0.state_dict())
print("\nAnd the original values for weights and bias are:")
print(f"weights: {weight}, bias: {bias}")
Python
복사
The model learned the following values for weights and bias:
OrderedDict([('weights', tensor([0.5784])), ('bias', tensor([0.3513]))])
And the original values for weights and bias are:
weights: 0.7, bias: 0.3
Python
복사
4.모델 평가
# 1. 모델을 평가 모드로 전환한다
model_0.eval()
# 2. 추론 모드 컨텍스트 매니저를 설정한다
with torch.inference_mode():
# 3. 모델과 데이터가 동일한 디바이스에서 계산되도록 한다
# 현재는 디바이스에 독립적인 코드를 설정하지 않았으므로, 데이터와 모델은 기본적으로 CPU에 있다
# model_0.to(device)
# X_test = X_test.to(device)
y_preds = model_0(X_test)
> y_preds[:5]
tensor([[0.8141],
[0.8256],
[0.8372],
[0.8488],
[0.8603]])
> plot_predictions(predictions=y_preds)
Python
복사
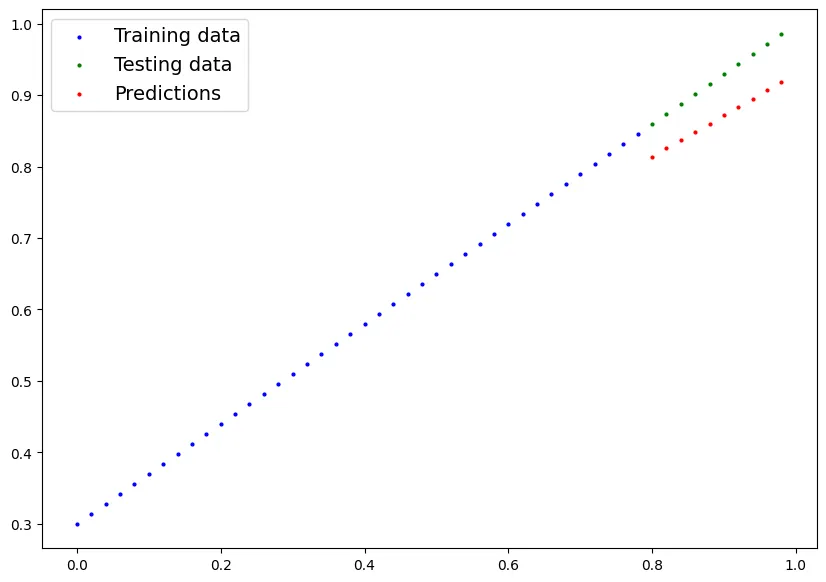
5.모델 저장
주요 메서드
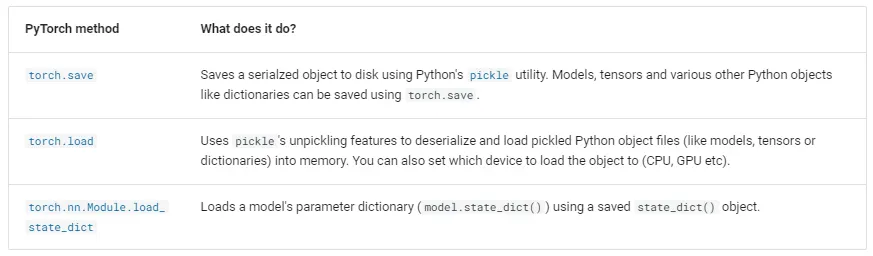
torch.save
•
역할: 모델, 텐서, 또는 기타 파이썬 객체(예: 딕셔너리 등)를 디스크에 저장한다. 이 메서드는 파이썬의 pickle 유틸리티를 사용해 객체를 직렬화하여 저장한다.
•
설명: 모델을 학습한 후, 나중에 사용할 수 있도록 모델을 파일로 저장할 때 사용된다. 이때 텐서, 모델, 또는 딕셔너리 형태의 객체 모두 저장 가능하다.
torch.load
•
역할: **pickle*을 사용해 저장된 파이썬 객체(예: 모델, 텐서, 딕셔너리 등)를 디스크에서 불러온다. 불러온 객체를 메모리에 로드하며, 어느 디바이스(CPU, GPU)로 로드할지도 설정할 수 있다.
•
설명: 모델을 저장한 후, 이를 다시 불러와서 추론 또는 추가 학습을 할 때 사용된다. 또한, 저장된 텐서나 딕셔너리도 동일한 방식으로 불러올 수 있다.
torch.nn.Module.load_state_dict
•
역할: 모델의 파라미터 딕셔너리를 불러온다. 이 파라미터 딕셔너리는 모델의 가중치와 편향을 저장하는데 사용되며, 저장된 state_dict() 객체를 이용해 모델을 복원할 수 있다.
•
설명: state_dict()는 PyTorch 모델의 모든 학습 가능한 파라미터(가중치 및 편향 등)를 저장한 딕셔너리 객체이다. 이 메서드는 저장된 파라미터를 불러와서 모델을 동일한 상태로 복원하는 데 사용된다.
save model
from pathlib import Path
# 1. 모델 디렉토리를 생성한다
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, exist_ok=True) # mkdir: 디렉토리를 생성한다
# 2. 모델 저장 경로를 생성한다
MODEL_NAME = "01_pytorch_workflow_model_0.pth"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
# 3. 모델의 상태 사전을 저장한다
print(f"모델을 다음 경로에 저장한다: {MODEL_SAVE_PATH}")
torch.save(obj=model_0.state_dict(),
# state_dict()만 저장하면 모델이 학습한 파라미터들만 저장된다
f=MODEL_SAVE_PATH)
Python
복사
> model_0.state_dict()
OrderedDict([('weights', tensor([0.5784])), ('bias', tensor([0.3513]))])
Python
복사
load model
# Instantiate a new instance of our model (this will be instantiated with random weights)
# 학습하지 않은 모델 생성
loaded_model_0 = LinearRegressionModel()
# 학습하지 않은 모델의 파라미터 확인
> loaded_model_0.state_dict()
OrderedDict([('weights', tensor([0.3367])), ('bias', tensor([0.1288]))])
Python
복사
# Load the state_dict of our saved model (this will update the new instance of our model with trained weights)
# 이미 학습된 모델의 파라미터 적용
loaded_model_0.load_state_dict(torch.load(f=MODEL_SAVE_PATH))
# 이미 학습된 모델 파라미터 적용 확인
> loaded_model_0.state_dict()
OrderedDict([('weights', tensor([0.5784])), ('bias', tensor([0.3513]))])
Python
복사
# 1. 로드한 모델을 평가 모드로 전환한다
loaded_model_0.eval()
# 2. 추론 모드 컨텍스트 매니저를 사용하여 예측을 수행한다
with torch.inference_mode():
loaded_model_preds = loaded_model_0(X_test)
# 로드한 모델로 테스트 데이터에 대해 순전파를 수행한다
# Compare previous model predictions with loaded model predictions (these should be the same)
> y_preds == loaded_model_preds
tensor([[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True]])
Python
복사
