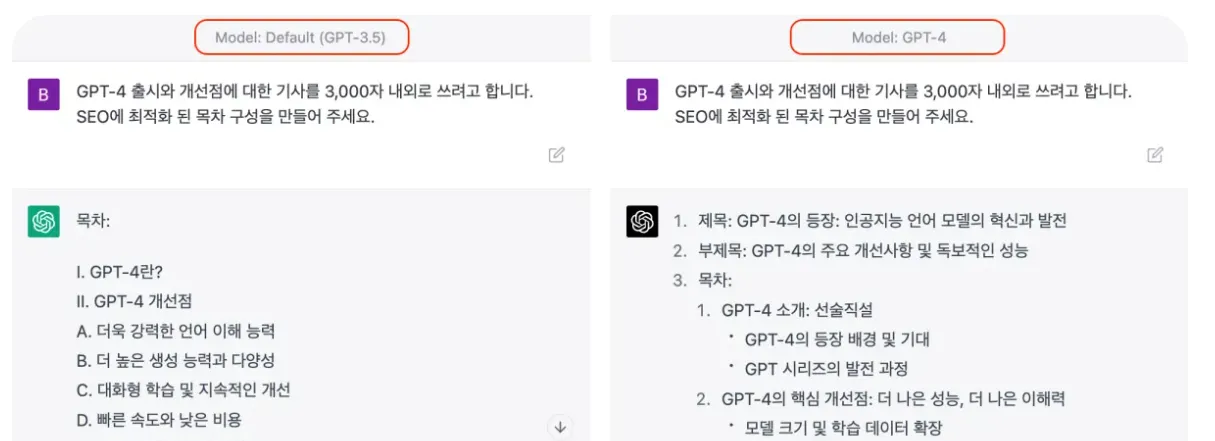
거대언어모델(Large Language Model, LLM)
•
LM (언어 모델, Language Model)
◦
인간의 언어를 이해하고 생성하도록 훈련된 일종의 인공지능 모델
◦
주어진 언어 내에서 패턴이나 구조, 관계를 학습하여 텍스트 번역과 같은 좁은 AI 작업에서 주로 활용
◦
언어 모델의 품질은 크기나 훈련된 데이터의 양 및 다양성, 훈련 중에 사용된 학습 알고리즘의 복잡성에 따라 달라짐.
•
LLM (거대 언어 모델, Large Language Model)
◦
대용량의 언어 모델
◦
LLM은 딥 러닝 알고리즘과 통계 모델링을 통해 자연어 처리(Natural Language Processing, NLP) 작업을 수행하는 데에 사용
◦
이 모델은 사전에 대규모의 언어 데이터를 학습하여 문장 구조나 문법, 의미 등을 이해하고 생성할 수 있다.
•
예를 들어, 주어진 문맥에서 다음 단어를 예측하는 문제에서 LLM은 문장 내의 단어들 사이의 유사성과 문맥을 파악하여 다음 단어를 생성할 수 있다.
◦
이러한 작업은 기계 번역, 텍스트 요약, 자동 작문, 질문 응답 등 다양한 NLP 과제에 활용된다.
•
LLM은 GPT(Generative Pre-trained Transformer)와 BERT(Bidirectional Encoder Representations from Transformers)와 같은 다양한 모델들이 있다.
◦
이러한 모델들은 수천억 개의 매개변수를 가지고 있다.
◦
최근에는 대용량의 훈련 데이터와 큰 모델 아키텍처를 사용하여 더욱 정교한 언어 이해와 생성을 달성하는데 주목을 받고 있다.
NLP vs LLM
•
NLP와 LLM은 관련이 있는 개념이지만, 서로 다른 개념이다.
•
NLP는 자연어 처리 분야 전반을 아우르는 개념, 텍스트를 이해하고 처리하는 기술에 초점
•
LLM은 NLP의 한 부분으로, 대량의 언어 데이터를 바탕으로 학습된 언어 모델을 사용하여 특정 NLP 작업을 수행하는데 초점
•
NLP는 더 넓은 의미의 개념이며, LLM은 그 안에서 특정한 접근 방식과 모델을 가리키는 한 가지 형태
NLP
•
인간의 언어를 이해하고 처리하는 데 초점을 맞춘 인공지능 분야
•
컴퓨터가 자연어 텍스트를 이해하고 분석하는 기술을 개발하는 것이 목표
•
문장 구문 분석, 텍스트 분류, 기계 번역, 질의 응답 시스템, 감정 분석 등과 같은 다양한 작업에 활용
LLM
•
큰 데이터셋을 사용하여 훈련된 대용량의 언어 모델
•
딥 러닝 기술과 통계 모델링을 사용하여 자연어 처리 작업 수행 가능
LLM 용어 정리
•
단어 임베딩: 단어들을 고차원 벡터로 표현하여 각 단어 간의 유사성과 관계를 캡처하는 기술
•
어텐션 메커니즘: 입력 시퀀스의 다양한 부분에 가중치를 부여하여 모델이 중요한 정보에게 집중할 수 있도록 하는 기술
•
Transformer: 어텐션 메커니즘을 기반으로 한 인코더와 디코더 구조의 신경망 모델로, 길이가 다른 시퀀스를 처리하는 데 탁원한 성능을 보인다.
•
Fine-tuning LLMs: 사전 학습된 대규모 언어 모델을 특정 작업에 적용하기 위해 추가 학습하는 과정
•
Prompt Enginnering: 모델에 입력하는 질문이나 명령을 구조화하여 모델의 성능을 향상시키는 과정
•
Bias(편향): 모델이 학습 데이터의 분륜형이나 잘못된 패턴을 포착하여 실제 세계의 현실과 일치하지 않는 결과를 내놓는 경향
•
해석 가능성: LLM이 가진 복잡성을 극복하고 AI 시스템의 결과와 결정을 이해하고 설명할 수 있는 능력
LLM 역사와 주요 모델
•
언어 모델은 크게 Encoder 기반 / Encoder-Decoder 기반 / Decoder 기반 3가지 구조로 나뉘는데, 최근 주목받고 있는 ChartGPT나 LLaMA 들은 Decoder 기반 언어 모델들이다.
•
최근 가장 주목 받는 LLM의 핵심 모델은 다음과 같다.
◦
GPT-3.5(OpenAI): GPT-3보다 약간의 성능과 안정성을 개선했으며, 광범위한 학습 데이터를 활용해 언어 이해 및 생성 능력을 향상시켜 SOTA를 달성
◦
GPT-4(OpenAI): GPT-3의 후속 모델로, 이전 버전보다 더 큰 모델 크기와 더 정교한 언어 이해와 생성 능력을 갖추고 있음
◦
PaLM2(Google): Pre-trained Automatic Metrics를 사용한 언어 모델로, 사전 훈련된 언어 모델을 사용하여 기계번역, 요약, 질문응답 등의 다양한 NLP 작업에서 성능 평가를 위해 사용됨
◦
LlaMA(Meta AI): Language Model Benchmark에서 개발한 작업 중심 언어 모델로 SOTA를 달성함
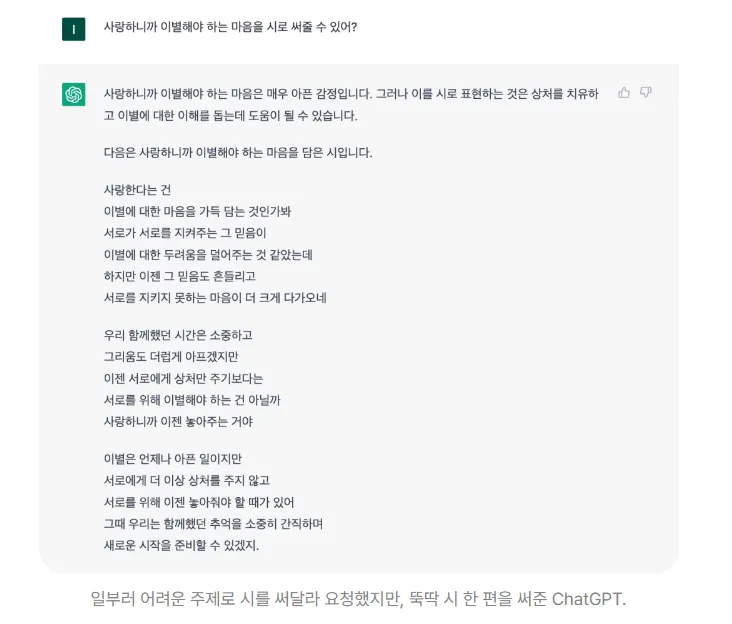
ChatGPT
•
미국의 AI 연구재단 OpenAI(오픈에이아이)가 2022년 11월 공개한 초거대 언어 모델 GPT-3.5 기반 대화형 인공지능 챗봇
•
•
GPT는 ‘Generative Pre-trained Transformer’의 약자
•
머신러닝으로 방대한 데이터를 ‘미리 학습(Pre-trained)’해 이를 문장으로 ‘생성(Generative)’하는 생성 AI
•
사용자가 채팅 하듯 질문을 입력하면 ChatGPT는 학습한 데이터를 기반으로 ‘사람처럼’ 문장으로 답을 해준다.
•
마치 사람과 대화하는 것처럼 자연스럽게 질문과 답변을 주고받을 수 있다.
•
단순 정보 짜깁기를 넘어 에세이・소설・시 등 다양한 창작물을 만들고, 철학적인 대화도 가능하며 심지어 프로그래밍 코드까지 생성해 더욱 주목받음.

ChatGPT 활용법 및 활용 사례
정보 얻기
•
ChatGPT는 방대한 데이터를 학습했기 때문에 많은 다양한 지식과 정보를 얻기에 좋습니다.
•
현재는 인터넷에 연결되지 않아 실시간으로 업데이트 되는 정보를 확인할 수는 없지만 일반적인 주제에 대해서는 충분한 데이터를 갖고 있어 정보를 얻기에 충분합니다.
•
단순하게 지식, 정보를 얻을 수도 있지만 새로운 아이디어를 도출해야 할 때 영감을 받는 데에 도움을 받을 수도 있습니다.

글쓰기
•
ChatGPT는 자연어 처리 기술을 바탕으로 문장을 생성할 수 있기 때문에, 글쓰기 분야에서도 유용하게 사용된다.
•
다양한 분야의 지식을 갖고 있고, 다양한 상황에 적응할 수 있도록 학습했기 때문에 생성 가능한 글의 스펙트럼이 넓다.
•
논문, 보고서, 에세이 등 팩트 기반의 글부터 시, 소설, 광고 카피 등 창의력과 상상력이 필요한 형태의 글쓰기도 가능하다.
코딩하기
•
“파이썬으로 간단한 계산기를 만들어 달라”고 질문을 던지면, ChatGPT는 파이썬으로 계산기를 만드는 방법을 친절하게 알려준다.
•
이를 통해 새로운 프로그래밍 기술을 배울 수도 있고, 더 나아가 프로그램을 만들 수도 있을 것이다.
•
개발자의 경우 다른 개발 언어로 쓰여진 라이브러리를 내가 쓰는 개발 언어로 변환할 수도 있고, 코딩할 내용을 자연어로 명령해 코드를 수정하고 보완할 수 있다.
•
또 ChatGPT에게 자신이 쓴 코드 리뷰나 주석 달기 등을 명령할 수도 있다.
ChatGPT 학습 과정
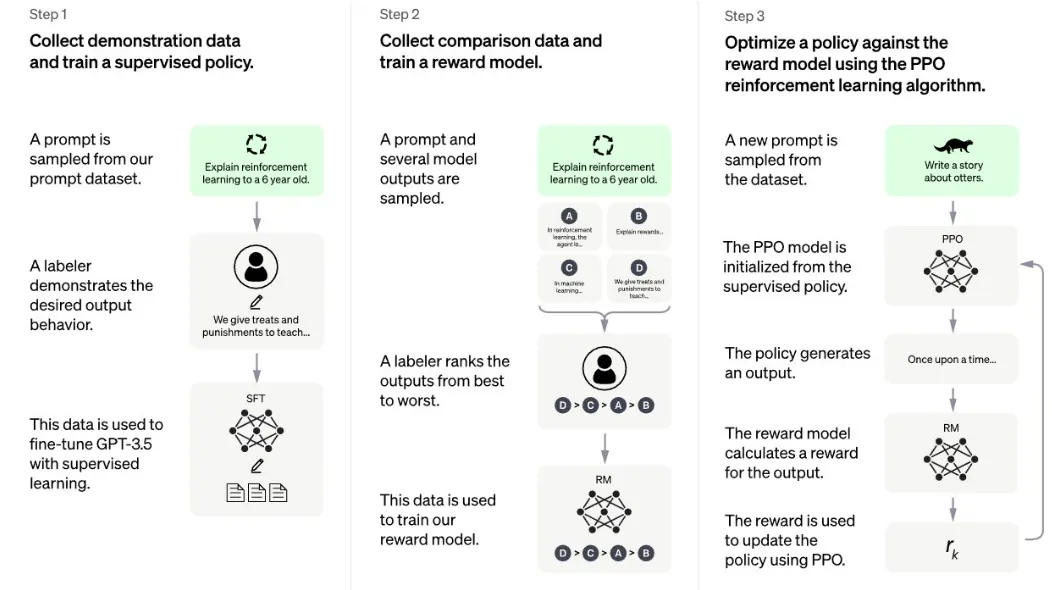
1단계: 데모 데이터 수집 및 지도 학습(Supervised Learning)
•
Reddit, Wikipedia, 전자문서화 되어 있는 수 많은 책, 논문 등을 통해 질문-대답이 쌍을 이루고 있는 데이터셋을 생성
•
생성된 데이터셋을 사용하여 지도학습(Supervised Learning)을 수행

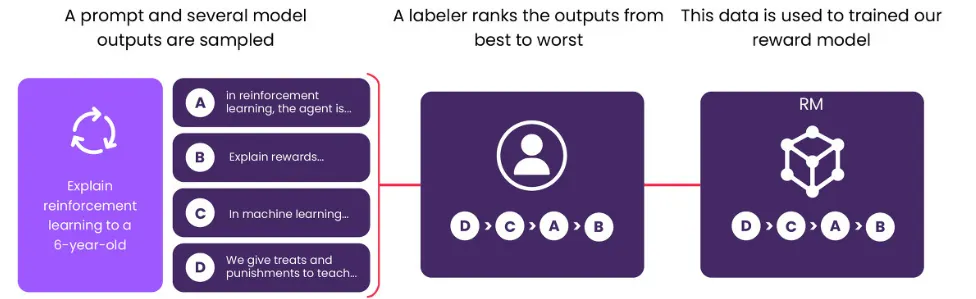
2단계: 비교 데이터 수집 및 보상 모델 훈련
•
예상 질문(Prompt)에 대한 다양한 예상 답안(Model Output) 데이터셋을 수집
•
그후, 인간(Labeler)이 예상 답안에 대한 순위를 매긴다.
•
이 데이터셋은 보상 모델(Reward Model)을 훈련하는 데 사용
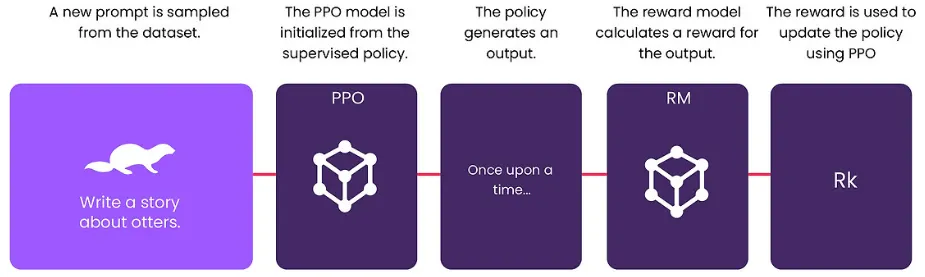
3단계: PPO 강화 학습 알고리즘을 사용하여 보상 모델 정책 최적화
•
Proximal Policy Optimization(PPO) 강화 학습 알고리즘을 사용하여 보상 모델에 대한 정책을 최적화한다.
•
2023년 3월 14일 GPT-4 출시
1. 멀티 모달 도입
•
GPT-4의 가장 눈에 띄는 개선점은 이미지를 인식한다는 것
•
멀티 모달 기능으로 이미지를 인식/이해하고 처리할 수 있게 되었다.
•
예를 들어, OpenAI는 리포트를 통해 차트 이미지를 해석해 답을 구하거나 프랑스어로 된 물리학 문제를 이미지로 읽어 풀 수 있다고 한다.

2. 지능과 지식향상
•
GPT-4의 가장 큰 특징 중 하나는 더욱 정교한 언어 이해와 처리 능력을 가지게 된 것
•
이전 모델 GPT-3.5에서는 한 번에 영어 기준 3,000개 정도 단어를 처리 수 있었다면, GPT-4는 25,000개까지 가능하다.