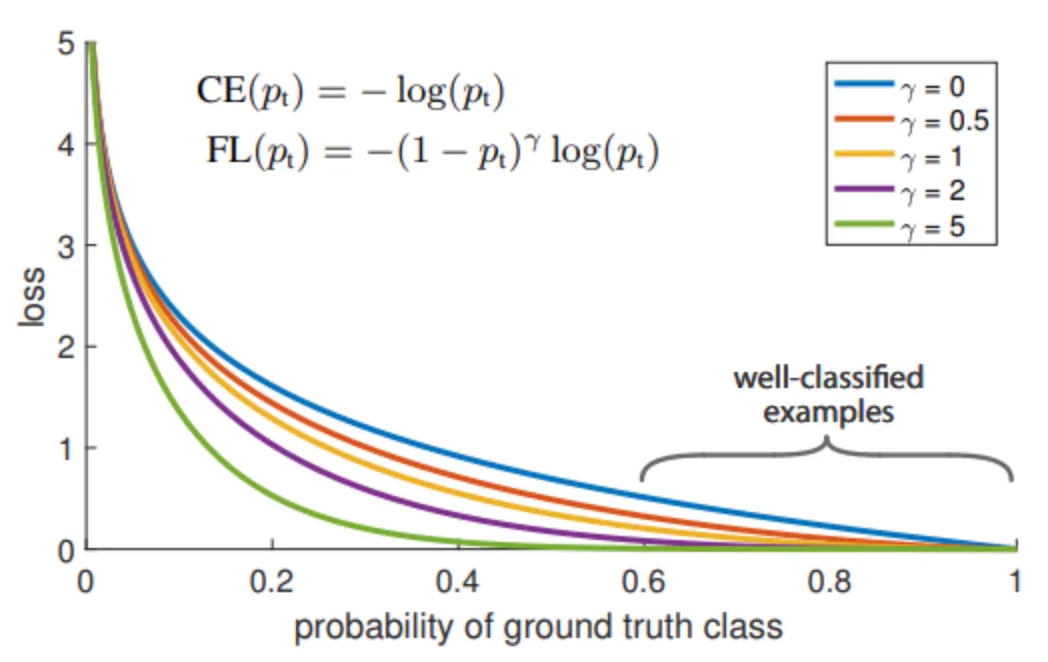
Object Detection이란?
•
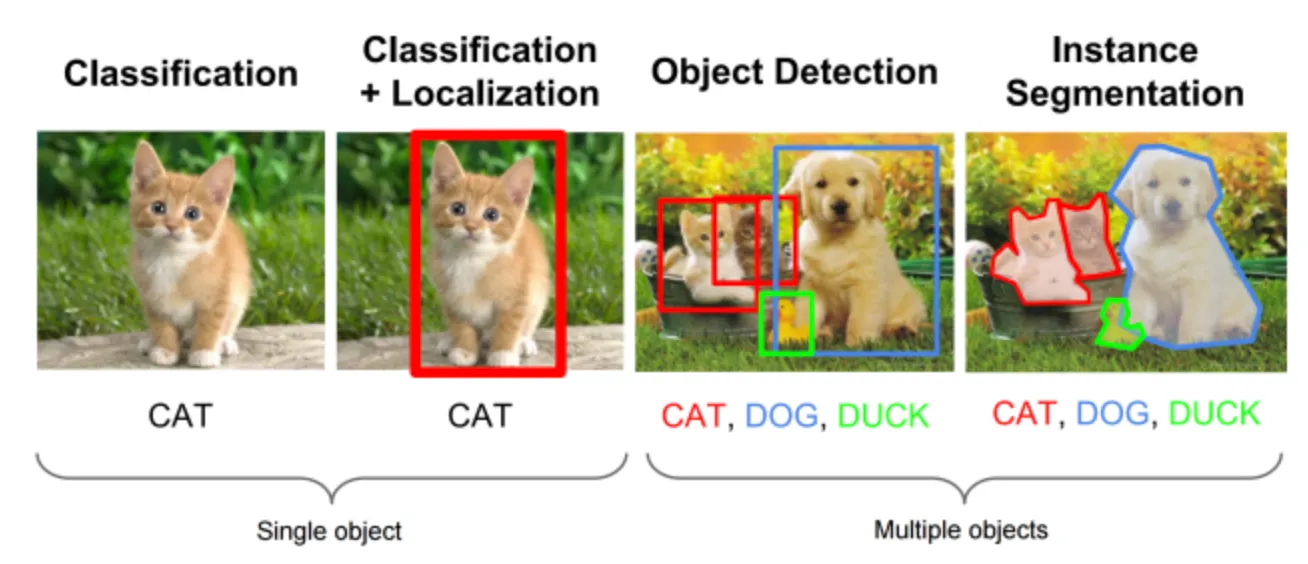
여러 물체에 대해 어떤 물체인지 분류하는 Classification 문제와 그 물체가 어디 있는지 박스를 통해(Bounding Box) 위치 정보를 나타내는 Localization 문제를 둘 다 해내야 하는 분야를 뜻한다.
•
즉, Object Detection = 여러가지 물체에 대한 Classification + 물체의 위치정보를 파악하는 Localization
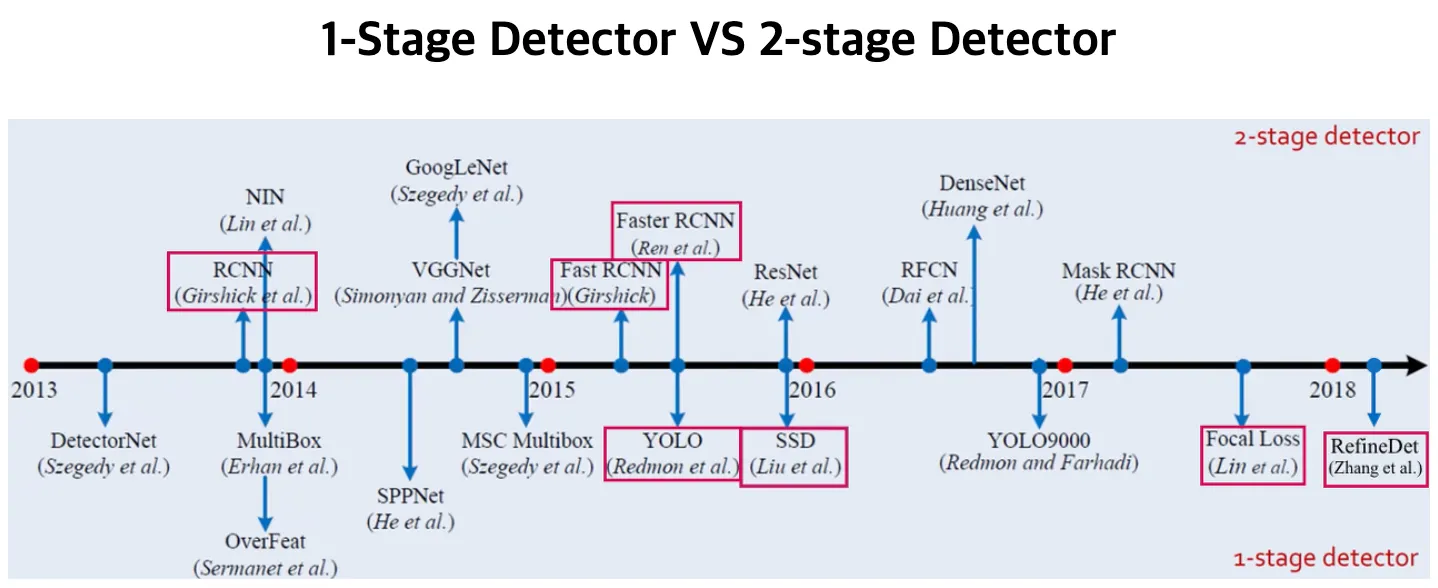
Object Detection 발전 흐름
•
Deep Learning을 이용한 Object Detection은 크게 1-stage Detector와 2-stage Detector로 나눌 수 있습니다.
•
가운데 수평 화살표를 기준으로 위 쪽 논문들이 2-stage Detector 논문들
1-stage Detector 특징
•
Localization 문제와 Classification 문제를 동시에 행하는 방법
•
비교적 빠르지만 정확도가 낮음
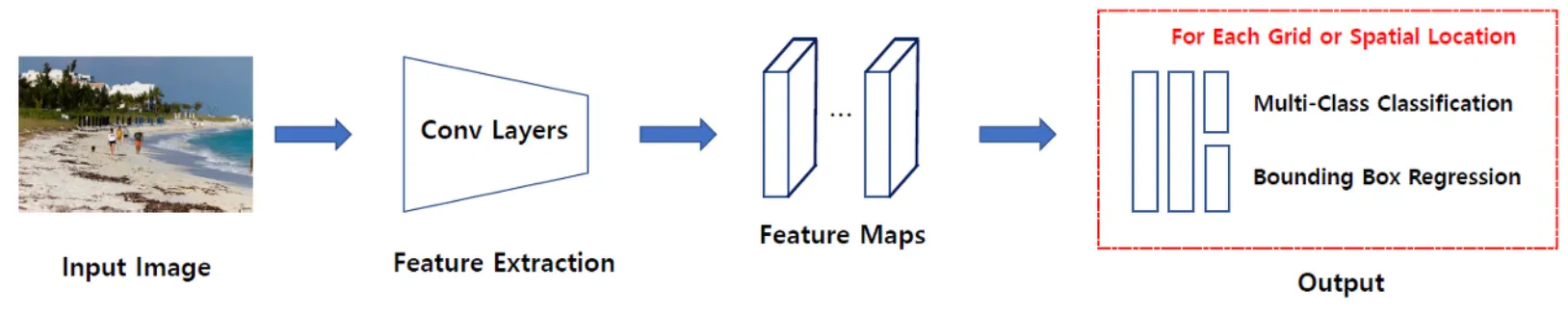
2-stage Detector 특징
•
Localization 문제와 Classification 문제를 순차적으로 행하는 방법
•
비교적 느리지만 정확도가 높음
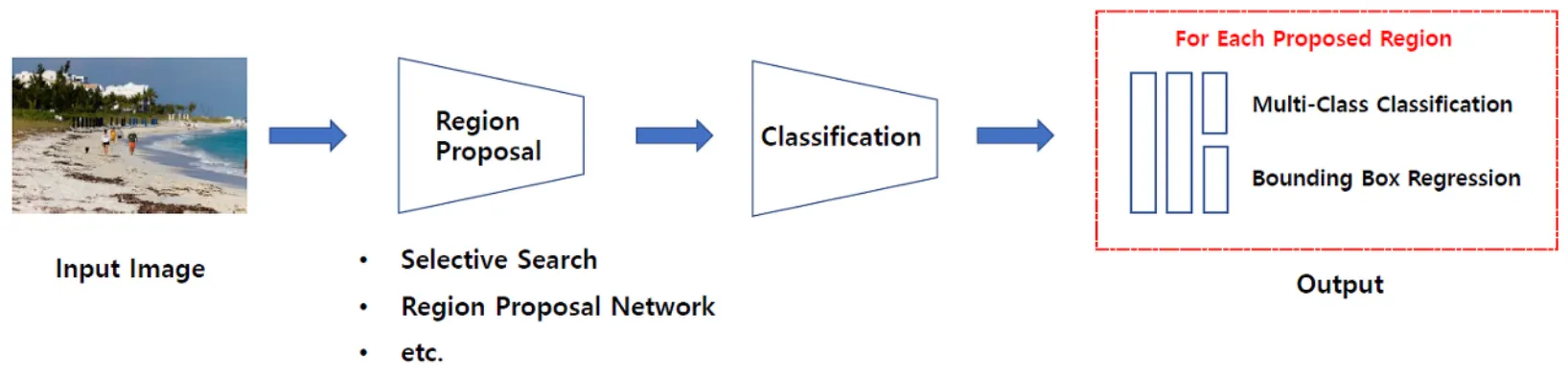
R-CNN
•
R-CNN은 Selective Search를 이용해 이미지에 대한 후보영역(Region Proposal)을 생성
•
생성된 각 후보영역을 고정된 크기로 wrapping하여 CNN의 input으로 사용
•
CNN에서 나온 Feature map으로 SVM을 통해 분류, Regressor을 통해 Bounding-box를 조정
•
강제로 크기를 맞추기 위한 wrapping으로 이미지의 변형이나 손실이 일어나고 후보영역만큼 CNN을 돌려야하하기 때문에 큰 저장공간을 요구하고 느리다는 단점이 있다.
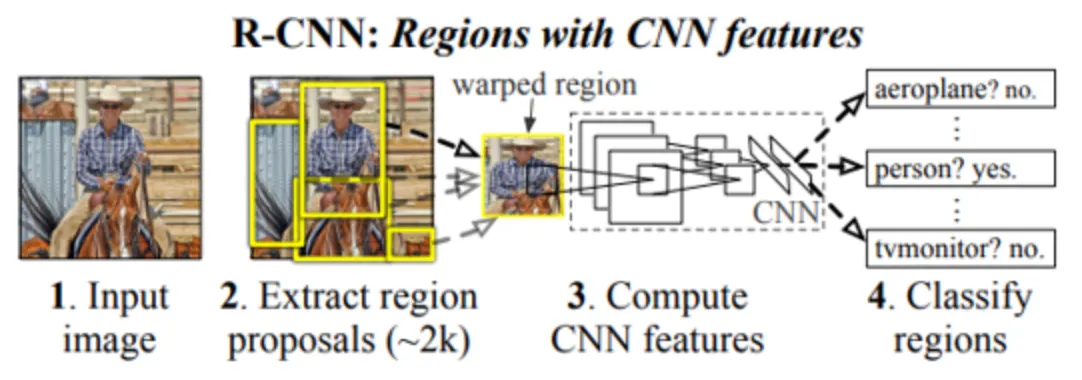
Fast R-CNN
•
각 후보영역에 CNN을 적용하는 R-CNN과 달리 이미지 전체에 CNN을 적용하여 생성된 Feature map에서 후보영역을 생성
•
생성된 후보영역은 RoI Pooling을 통해 고정 사이즈의 Feature vector로 추출
•
Feature vector에 FC layer를 거쳐 Softmax를 통해 분류, Regressor를 통해 Bounding-box를 조정
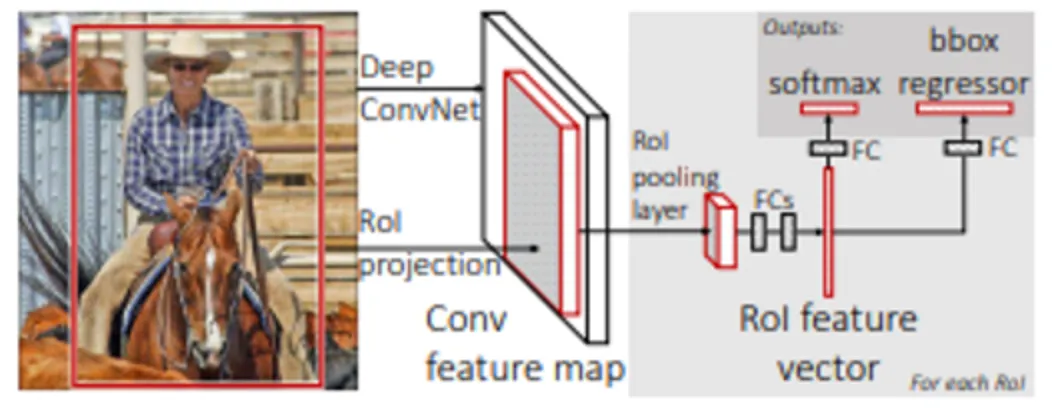
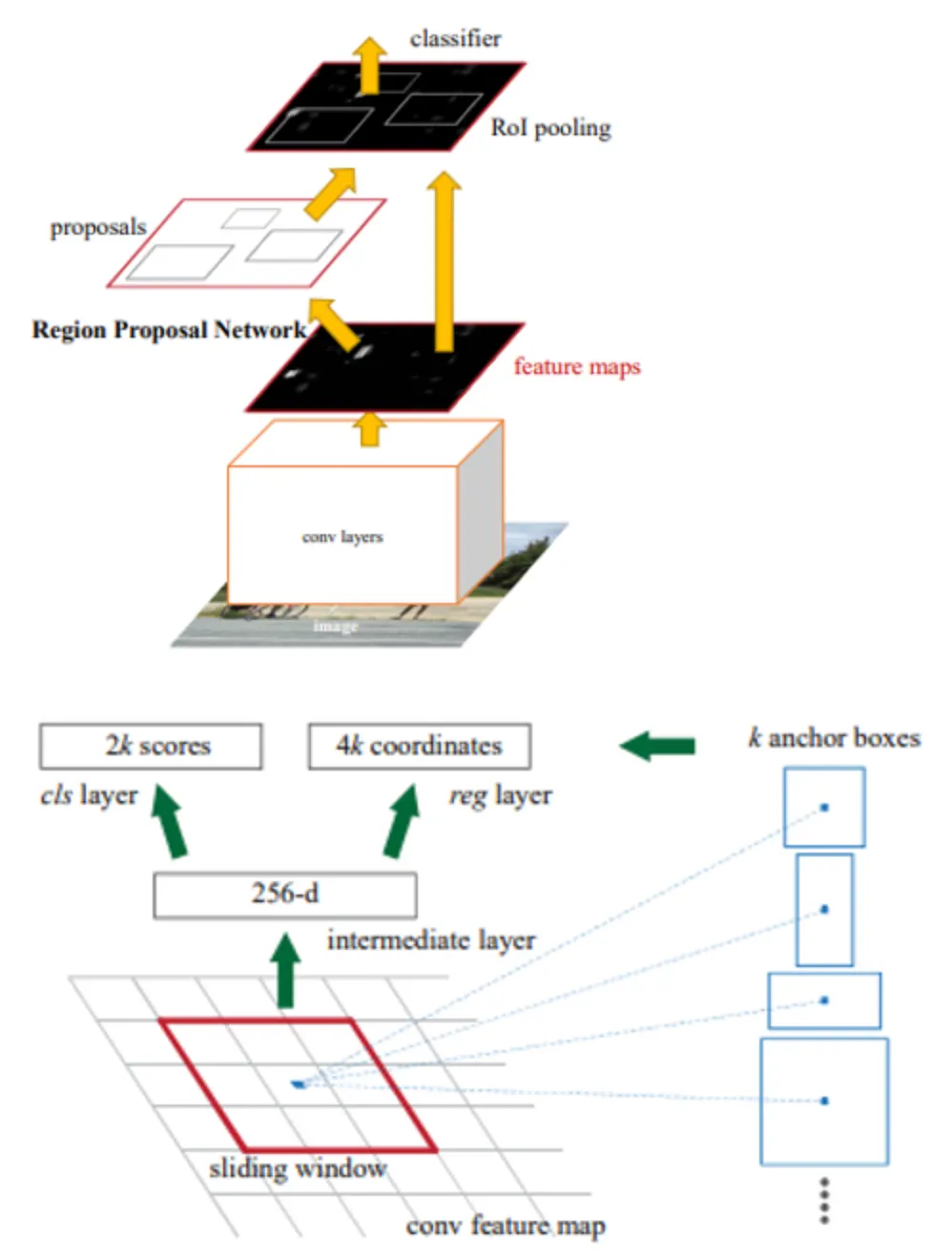
Faster R-CNN
•
Selective Search 부분을 딥러닝으로 바꾼 Region Proposal Network(RPN)을 사용
•
RPN은 Feature map에서 CNN 연산시 sliding-window가 찍은 지점마다 Anchor-box로 후보영역을 예측
•
Anchor-box : 미리 지정해놓은 여러 개의 비율과 크기의 Bounding-box
•
RPN에서 얻은 후보영역을 IoU순으로 정렬하여 Non-Maximum Suppression(NMS) 알고리즘을 통해 최종 후보영역을 선택
•
선택된 후보영역의 크기를 맞추기 위해 RoI Pooling을 거치고 이후 Fast R-CNN과 동일하게 진행
YOLO
•
Bouning-box와 Class probability를 하나의 문제로 간주하여 객체의 종류와 위치를 한번에 예측
•
이미지를 일정 크기의 그리드로 나눠 각 그리드에 대한 Bounding-box를 예측
•
Bounding-box의 confidence score와 그리드셀의 class score의 값으로 학습하게 된다.
•
간단한 처리과정으로 속도가 매우 빠르지만 작은 객체에 대해서는 상대적으로 정확도가 낮다.

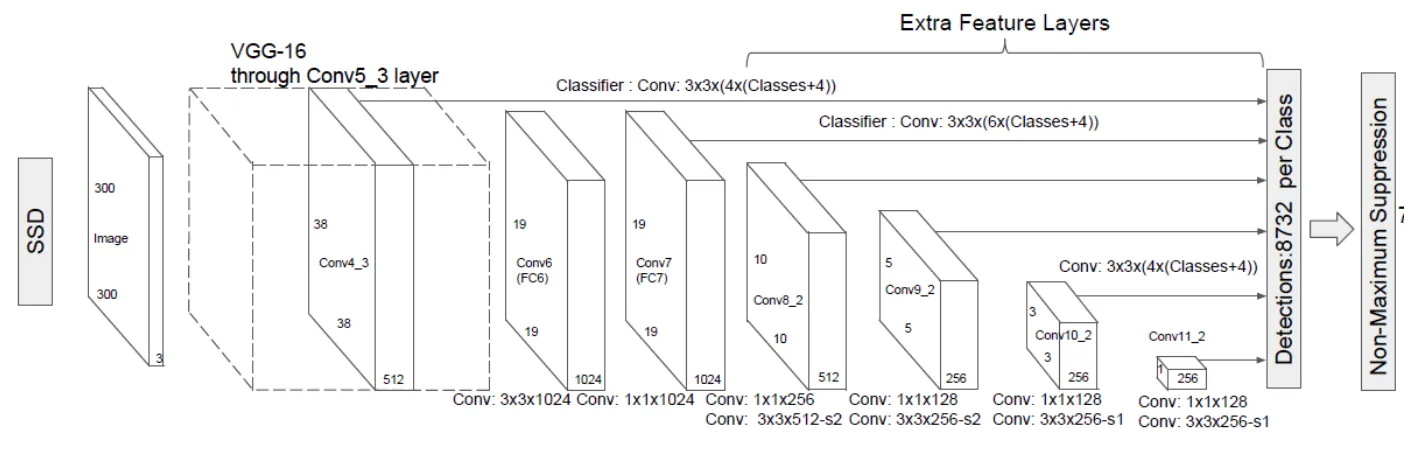
SSD
•
각 Covolutional Layer 이후에 나오는 Feature map마다 Bounding-box의 Class 점수와 Offset(위치좌표)를 구하고, NMS 알고리즘을 통해 최종 Bounding-box를 결정
•
이는 각 Feature map마다 스케일이 다르기 때문에 작은 물체와 큰 물체를 모두 탐지할 수 있다는 장점이 있다.
RetinaNet
•
RetinaNet은 모델 학습시 계산하는 손실 함수(loss function)에 변화를 주어 기존 One-Stage Detector들이 지닌 낮은 성능을 개선했다.
•
One-Stage Detector는 많게는 십만개 까지의 후보군 제시를 통해 학습을 진행
•
그 중 실제 객체인 것은 일반적으로 10개 이내 이고, 다수의 후보군이 background 클래스로 잡힌다.
•
상대적으로 분류하기 쉬운 background 후보군들에 대한 loss값을 줄여줌으로써 분류하기 어려운 실제 객체들의 loss 비중을 높이고, 그에 따라 실제 객체들에 대한 학습에 집중하게 한다.
•
RetinaNet은 속도 빠르면서 Two-Stage Detector와 유사한 성능을 보인다.