


•
학습률(Learning Rate)은 모델을 학습하기 위해서 필수적인 요소
•
학습률을 너무 크게 설정한다면, 최솟값에 도달하는 것이 어려우며, 너무 작게 설정하면, local minimum에 빠지거나 학습에 진전이 없을 수 있다.
•
Scheduler는 학습률을 감쇠(Decay)하는 역할을 한다.
LAMBDA LR
•
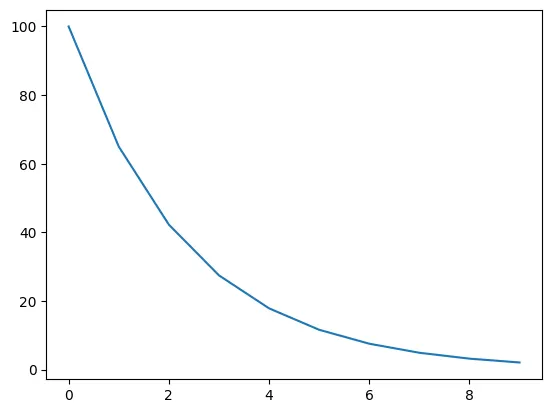
Epoch에 따른 가중치로 lr 를 점점 감소 시키는 Scheduler
◦
LambdaLR은 가장 유연한 learning rate scheduler이다.
◦
어떻게 scheduling을 할 지 lambda 함수 또는 함수를 이용하여 정하기 때문
◦
LmabdaLR을 사용할 때 필요한 파라미터는 optimizer, lr_lambda이다.
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
lambda1 = lambda epoch: 0.65 ** epoch
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1)
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(range(10),lrs)
Python
복사
StepLR
•
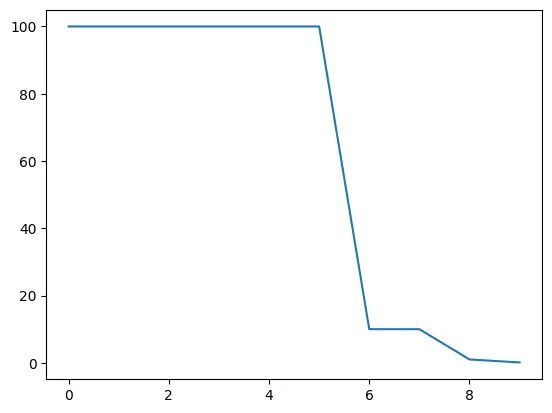
특정 Step에 따라 lr 를 감소시키는 Scheduler
◦
StepLR도 가장 흔히 사용되는 learning rate scheduler 중 하나
◦
일정한 Step 마다 learning rate에 gamma를 곱해주는 방식
◦
StepLR에서 필요한 파라미터는 optimizer, step_size, gamma이다.
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=2, gamma=0.1)
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",0.1 if i!=0 and i%2!=0 else 1," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(range(10),lrs)
Python
복사

MultiStepLR
•
특정 Step에 따른 감소가 아닌 사용자가 지정한 milestones에 따라 lr를 감소시키는 Scheduler
◦
StepLR이 균일한 step size를 사용한다면 MultiStepLR은 step size를 여러 기준으로 적용할 수 있는 StepLR의 확장 버전이다.
◦
StepLR과 사용방법은 비슷하며 StepLR에서 사용한 step_size 대신, milestones에 리스트 형태로 step 기준을 받는다.
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[6,8,9], gamma=0.1)
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",0.1 if i in [6,8,9] else 1," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(range(10),lrs)
Python
복사
ExponentialLR
•
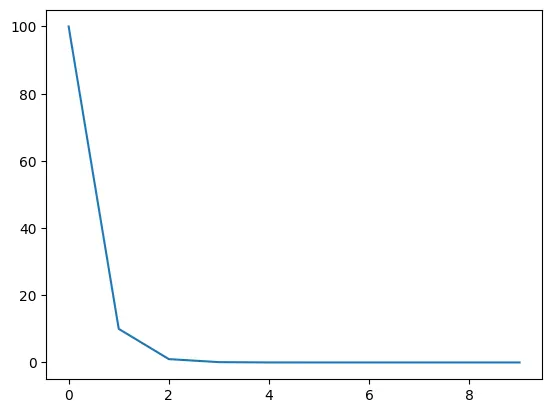
지수적으로 learning rate가 감소하는 방법
•
지수적으로 감소하기 때문에 하이퍼 파라미터는 감소율 gamma 하나이다.
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.1)
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",0.1," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
Python
복사
CosineAnnealingLR
•
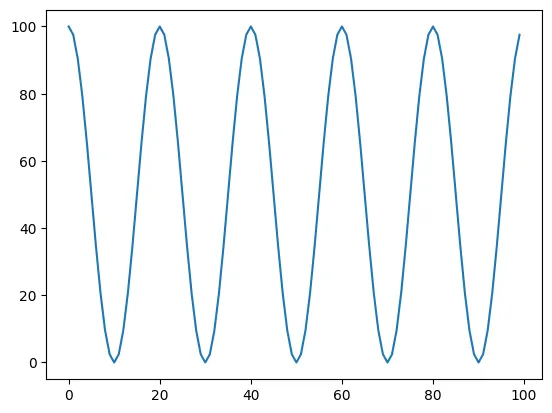
Cosine 파형을 사용하는 Scheduler
•
cosine 그래프를 그리면서 learning rate가 진동하는 방식
•
최근에는 learning rate가 단순히 감소하기 보다는 진동하면서 최적점을 찾아가는 방식을 많이 사용하고 있다.
•
이러한 방법 중 가장 간단하면서도 많이 사용되는 방법이 CosineAnnealingLR 방식이다.
•
CosineAnnealingLR에 사용되는 파라미터는 T_max 라는 반주기의 단계 크기값과 eta_min 이라는 최소값이다.
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=0)
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",i," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
Python
복사
CyclicLR
•
앞에서 설명한 CosineAnnealingLR은 단순한 cosine 곡선인 반면에 CyclicLR은 3가지 모드를 지원하면서 변화된 형태로 주기적인 learning rate 증감을 지원한다.
•
이 때 사용하는 파라미터로 base_lr, max_lr, step_size_up, step_size_down, mode가 있다.
•
base_lr은 learning rate의 가장 작은 점인 lower bound가 된다.
•
max_lr은 반대로 learning rate의 가장 큰 점인 upper bound가 된다.
•
step_size_up은 base_lr → max_lr로 증가하는 epoch 수가 되고 step_size_down은 반대로 max_lr → base_lr로 감소하는 epoch 수가 된다.
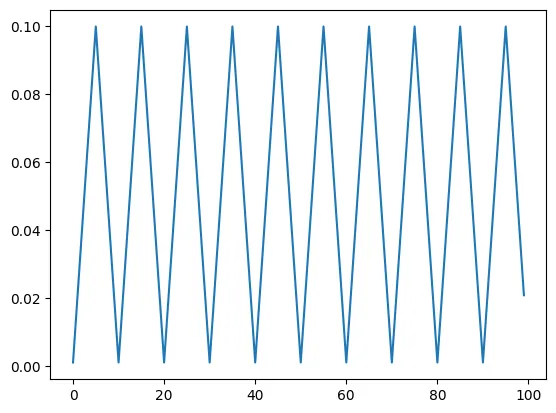
CyclicLR - triangular
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.001, max_lr=0.1,step_size_up=5,mode="triangular")
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",i," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
Python
복사
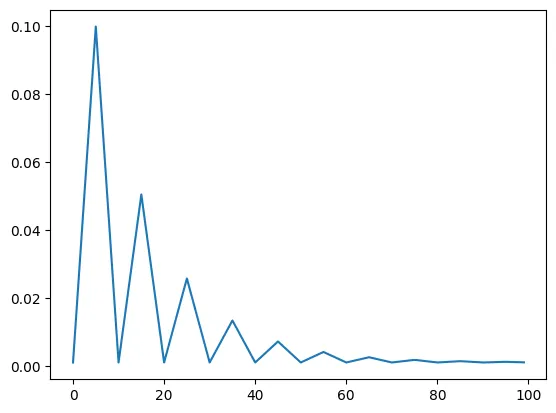
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.001, max_lr=0.1,step_size_up=5,mode="triangular2")
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",i," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
Python
복사
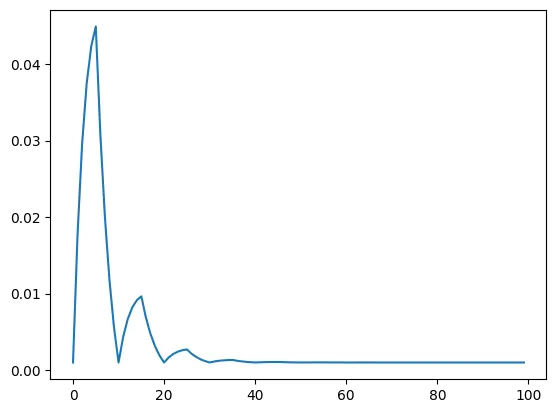
CyclicLR - exp_range
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.001, max_lr=0.1,step_size_up=5,mode="exp_range",gamma=0.85)
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",i," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
Python
복사
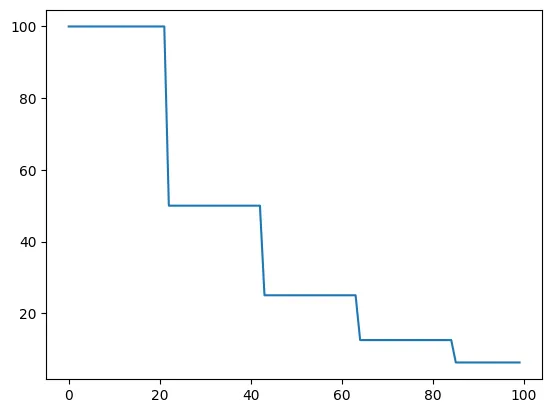
•
ReduceLROnPlateau는 더이상 학습이 진행되지 않을 때 learning rate를 감소시키는 scheduler
•
scheduler에 input으로 metric을 주면, 일정 epoch 동안 변화가 없을 때 learning rate를 감소시킨다.
•
주요 Parameter
◦
mode: [min, max] 중 하나. Input으로 주는 metric이 낮을수록 좋은지, 높을수록 좋은지를 의미한다. 'min' option을 주면, metric의 감소가 멈출 때마다 learning rate를 감소시킨다.
◦
factor: Learning rate를 감소시키는 비율. new_lr = lr * factor이 된다.
◦
patience: Metric이 얼마 동안 변화가 없을 때 learning rate를 감소시킬지 결정한다. 만약 patient=2라면, metric이 2 epoch 동안 변화가 없으면 learning rate를 감소시킨다.
◦
threshold: Metric이 '변화가 없다'라고 판단하는 threshold. Metric의 변화가 threshold 이하일 시 변화가 없다라고 판단한다.
◦
cooldown: 처음 몇 epoch 동안은 변화가 없어도 learning rate를 감소시키지 않는다. 몇 epoch만큼을 기다릴지를 지정한다.
◦
eps: Learning rate 감소의 최소치를 지정한다. new_lr과 old_lr의 차이가 eps 이하이면 더이상 learning rate를 감소시키지 않는다.
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=20, verbose=1)
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",i," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step(1)
plt.plot(lrs)
Python
복사
Ray Tune
•
하이퍼파라미터 튜닝은 보통의 모델과 매우 정확한 모델간의 차이를 만들어 낼 수 있다.
•
종종 다른 학습률(Learnig rate)을 선택하거나 layer size를 변경하는 것과 같은 간단한 작업만으로도 모델 성능에 큰 영향을 미치기도 한다.
•
다행히, 최적의 매개변수 조합을 찾는데 도움이 되는 도구가 있다.
•
Ray Tune 은 분산 하이퍼파라미터 튜닝을 위한 업계 표준 도구이다.
•
Ray Tune은 최신 하이퍼파라미터 검색 알고리즘을 포함하고 TensorBoard 및 기타 분석 라이브러리와 통합되며 기본적으로 Ray 의 분산 기계 학습 엔진 을 통해 학습을 지원한다.
Train
from functools import partial
import os
import tempfile
from pathlib import Path
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import random_split
import torchvision
import torchvision.transforms as transforms
from ray import tune
from ray import train
from ray.train import Checkpoint, get_checkpoint
from ray.tune.schedulers import ASHAScheduler
import ray.cloudpickle as pickle
Python
복사
def train_cifar(config, data_dir=None):
# 네트워크 생성: config에서 첫 번째와 두 번째 레이어 크기를 가져와 모델을 생성한다
net = Net(config["l1"], config["l2"])
# 학습에 사용할 디바이스 설정
device = "cpu"
if torch.cuda.is_available(): # GPU가 사용 가능한 경우 GPU 사용
device = "cuda:0"
if torch.cuda.device_count() > 1: # GPU가 여러 개인 경우, 모델을 데이터 병렬로 설정한다
net = nn.DataParallel(net)
net.to(device) # 모델을 설정한 디바이스로 이동한다
# 손실 함수와 옵티마이저 설정
criterion = nn.CrossEntropyLoss() # 분류 문제를 위한 손실 함수 (교차 엔트로피)
optimizer = optim.SGD(net.parameters(), lr=config["lr"], momentum=0.9) # SGD 옵티마이저 사용
# 체크포인트 로드: 이전 학습 상태가 저장된 경우 로드한다
checkpoint = get_checkpoint()
if checkpoint:
with checkpoint.as_directory() as checkpoint_dir:
data_path = Path(checkpoint_dir) / "data.pkl"
with open(data_path, "rb") as fp:
checkpoint_state = pickle.load(fp)
start_epoch = checkpoint_state["epoch"] # 로드한 체크포인트의 에포크 번호
net.load_state_dict(checkpoint_state["net_state_dict"]) # 모델 파라미터 로드
optimizer.load_state_dict(checkpoint_state["optimizer_state_dict"]) # 옵티마이저 상태 로드
else:
start_epoch = 0 # 처음부터 시작하는 경우 에포크는 0부터 시작
# 학습 및 테스트 데이터셋을 로드한다
trainset, testset = load_data(data_dir)
# 학습 데이터셋을 학습 및 검증용 데이터셋으로 분할한다 (80%는 학습, 20%는 검증)
test_abs = int(len(trainset) * 0.8)
train_subset, val_subset = random_split(trainset, [test_abs, len(trainset) - test_abs])
# 학습 및 검증용 데이터로더 생성
trainloader = torch.utils.data.DataLoader(
train_subset, batch_size=int(config["batch_size"]), shuffle=True, num_workers=8
)
valloader = torch.utils.data.DataLoader(
val_subset, batch_size=int(config["batch_size"]), shuffle=True, num_workers=8
)
# 학습 루프: 전체 데이터셋을 여러 번 반복하며 학습
for epoch in range(start_epoch, 10):
running_loss = 0.0
epoch_steps = 0
for i, data in enumerate(trainloader, 0):
# 입력과 레이블을 가져와 디바이스로 이동한다
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# 파라미터의 기울기를 초기화한다
optimizer.zero_grad()
# 순전파, 역전파, 최적화를 수행한다
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 통계를 출력한다
running_loss += loss.item()
epoch_steps += 1
if i % 2000 == 1999: # 2000 미니배치마다 손실을 출력한다
print(
"[%d, %5d] loss: %.3f"
% (epoch + 1, i + 1, running_loss / epoch_steps)
)
running_loss = 0.0
# 검증 루프: 학습 루프가 완료되었을 때 실행
val_loss = 0.0
val_steps = 0
total = 0
correct = 0
for i, data in enumerate(valloader, 0):
with torch.no_grad(): # 기울기를 계산하지 않음
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1) # 가장 높은 확률의 클래스 예측
total += labels.size(0)
correct += (predicted == labels).sum().item()
loss = criterion(outputs, labels)
val_loss += loss.cpu().numpy()
val_steps += 1
# 체크포인트 데이터를 설정하고 임시 디렉토리에 저장한다
checkpoint_data = {
"epoch": epoch,
"net_state_dict": net.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
}
with tempfile.TemporaryDirectory() as checkpoint_dir:
data_path = Path(checkpoint_dir) / "data.pkl"
with open(data_path, "wb") as fp:
pickle.dump(checkpoint_data, fp)
checkpoint = Checkpoint.from_directory(checkpoint_dir)
# 현재 에포크의 손실과 정확도를 보고한다
train.report(
{"loss": val_loss / val_steps, "accuracy": correct / total},
checkpoint=checkpoint,
)
print("Finished Training")
Python
복사
체크포인트(checkpoint)
net = Net(config["l1"], config["l2"])
checkpoint = get_checkpoint()
if checkpoint:
with checkpoint.as_directory() as checkpoint_dir:
data_path = Path(checkpoint_dir) / "data.pkl"
with open(data_path, "rb") as fp:
checkpoint_state = pickle.load(fp)
start_epoch = checkpoint_state["epoch"]
net.load_state_dict(checkpoint_state["net_state_dict"])
optimizer.load_state_dict(checkpoint_state["optimizer_state_dict"])
else:
start_epoch = 0
Python
복사
•
학습 스크립트를 train_cifar(config, data_dir=None) 함수로 감싸둔다.
•
config 매개변수는 학습할 하이퍼파라미터(hyperparameter)를 받는다.
•
data_dir 은 여러 번의 실행(run) 시 동일한 데이터 소스를 공유할 수 있도록 데이터를 읽고 저장하는 디렉토리를 지정한다.
•
또한, checkpoint가 지정되는 경우에는 실행 시작 시점의 모델과 옵티마이저 상태(optimizer state)를 불러올 수 있다.
DataParallel을 이용한 GPU(다중)지원 추가
•
이미지 분류는 GPU를 사용할 때 이점이 많다.
•
운좋게도 Ray Tune에서 파이토치의 추상화를 계속 사용할 수 있다.
•
따라서 여러 GPU에서 데이터 병렬 훈련을 지원하기 위해 모델을 nn.DataParallel 으로 감쌀 수 있다.
device = "cpu"
if torch.cuda.is_available():
device = "cuda:0"
if torch.cuda.device_count() > 1:
net = nn.DataParallel(net)
net.to(device)
for i, data in enumerate(trainloader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
Python
복사
◦
device 변수를 사용하여 사용 가능한 GPU가 없을 때도 학습이 가능한지 확인
◦
파이토치는 다음과 같이 데이터를 GPU메모리에 명시적으로 보내도록 요구
◦
이 코드는 이제 CPU들, 단일 GPU 및 다중 GPU에 대한 학습을 지원한다.
◦
Ray Tune으로 통신
checkpoint_data = {
"epoch": epoch,
"net_state_dict": net.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
}
with tempfile.TemporaryDirectory() as checkpoint_dir:
data_path = Path(checkpoint_dir) / "data.pkl"
with open(data_path, "wb") as fp:
pickle.dump(checkpoint_data, fp)
checkpoint = Checkpoint.from_directory(checkpoint_dir)
train.report(
{"loss": val_loss / val_steps, "accuracy": correct / total},
checkpoint=checkpoint,
)
Python
복사
•
먼저 체크포인트를 저장한 다음 일부 메트릭을 Ray Tune에 다시 보낸다.
•
특히, validation loss와 accuracy를 Ray Tune으로 다시 보낸다.
•
그 후 Ray Tune은 이러한 메트릭을 사용하여 최상의 결과를 유도하는 하이퍼파라미터 구성을 결정할 수 있다.
•
이러한 메트릭들은 또한 리소스 낭비를 방지하기 위해 성능이 좋지 않은 실험을 조기에 중지하는 데 사용할 수 있다.
•
•
또한, 체크포인트를 저장해두면 나중에 학습된 모델을 로드하고 평가 세트(test set)에서 검증할 수 있다.
테스트셋 정확도(Test set accuracy)
•
일반적으로 머신러닝 모델의 성능은 모델 학습 시 사용하지 않은 데이터를 테스트셋으로 따로 떼어낸 뒤, 이를 사용하여 테스트한다.
•
이러한 테스트셋 또한 함수로 감싸둘 수 있다.
def test_accuracy(net, device="cpu"):
trainset, testset = load_data()
testloader = torch.utils.data.DataLoader(
testset, batch_size=4, shuffle=False, num_workers=2
)
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return correct / total
Python
복사
Main
def trial_str_creator(trial):
return "{}_{}_123".format(trial.trainable_name, trial.trial_id)
Python
복사
def main(num_samples=10, max_num_epochs=10, gpus_per_trial=2):
data_dir = os.path.abspath("./data")
load_data(data_dir)
config = {
"l1": tune.choice([2**i for i in range(9)]),
"l2": tune.choice([2**i for i in range(9)]),
"lr": tune.loguniform(1e-4, 1e-1),
"batch_size": tune.choice([2, 4, 8, 16]),
}
scheduler = ASHAScheduler(
metric="loss",
mode="min",
max_t=max_num_epochs,
grace_period=1,
reduction_factor=2,
)
reporter = tune.JupyterNotebookReporter(
metric_columns=["loss", "accuracy", "training_iteration"])
result = tune.run(
partial(train_cifar, data_dir=data_dir),
resources_per_trial={"cpu": 2, "gpu": gpus_per_trial},
config=config,
num_samples=num_samples,
scheduler=scheduler,
trial_dirname_creator=trial_str_creator)
return result
Python
복사
검색 공간 구성
•
Ray Tune의 검색 공간을 정의
config = {
"l1": tune.choice([2 ** i for i in range(9)]),
"l2": tune.choice([2 ** i for i in range(9)]),
"lr": tune.loguniform(1e-4, 1e-1),
"batch_size": tune.choice([2, 4, 8, 16])
}
Python
복사
◦
tune.choice() 함수는 균일하게 샘플링된 값들의 목록을 입력으로 받는다.
◦
위 예시에서 l1 및 l2 파라미터는 4와 256 사이의 2의 거듭제곱 값인 4, 8, 16, 32, 64, 128, 256이다.
◦
lr (학습률)은 0.0001과 0.1 사이에서 균일하게 샘플링 되어야 한다.
◦
마지막으로, 배치 크기는 2, 4, 8, 16중에서 선택할 수 있다.
•
각 실험에서, Ray Tune은 이제 이러한 검색 공간에서 매개변수 조합을 무작위로 샘플링한다.
•
그런 다음 여러 모델을 병렬로 훈련하고 이 중에서 가장 성능이 좋은 모델을 찾는다.
•
또한 성능이 좋지 않은 실험을 조기에 종료하는 ASHAScheduler 를 사용한다.
tune.run
•
상수 data_dir 파라미터를 설정하기 위해 functools.partial 로 train_cifar 함수를 감싼다.
•
또한 각 실험에 사용할 수 있는 자원들(resources)을 Ray Tune에 알릴 수 있다.
gpus_per_trial = 2
# ...
result = tune.run(
partial(train_cifar, data_dir=data_dir),
resources_per_trial={"cpu": 8, "gpu": gpus_per_trial},
config=config,
num_samples=num_samples,
scheduler=scheduler,
checkpoint_at_end=True)
Python
복사
◦
DataLoader 인스턴스의 num_workers 을 늘리기 위해 CPU 수를 지정하고 사용할 수 있다.
◦
각 실험에서 선택한 수의 GPU들은 파이토치에 표시된다.
◦
실험들은 요청되지 않은 GPU에 액세스할 수 없으므로 같은 자원들을 사용하는 중복된 실험에 대해 신경쓰지 않아도 된다.
◦
부분 GPUs를 지정할 수도 있으므로, gpus_per_trial=0.5 와 같은 것 또한 가능
◦
이후 각 실험은 GPU를 공유한다.
▪
사용자는 모델이 여전히 GPU메모리에 적합한지만 확인하면 됨.
◦
모델을 훈련시킨 후, 가장 성능이 좋은 모델을 찾고 체크포인트 파일에서 학습된 모델을 로드
◦
이후 test set 정확도(accuracy)를 얻고 모든 것들을 출력하여 확인할 수 있다.
Train
result = main(num_samples=4, max_num_epochs=5, gpus_per_trial=0)
Python
복사
