•
OCR이란, Optical Character Recognition의 줄임말, 이미지 내의 글자를 자동으로 인식하는 인공지능 기술
◦
예를 들어, 카메라를 통해 자동차 번호를 인식한다거나, 신분증에서 개인 정보 텍스트를 인식하는 등의 기술
◦
최근 OCR은 딥러닝으로 인해 큰 발전을 이루고 있다.
딥러닝과 OCR
•
딥러닝의 발전은 OCR에 큰 영향을 끼쳤다.
•
딥러닝의 핵심이라고 할 수 있는 CNN(Convolutional neural networks)에서 그 이유를 찾을 수 있다.
◦
CNN에서는 이미지의 특징을 추출하여 분류하는데, 이를 통해 기존의 전통적인 OCR 구조에서 개발자가 직접 설정해 주어야 했던 feature 인식 모듈은 더 이상 필요하지 않게 된 것
◦
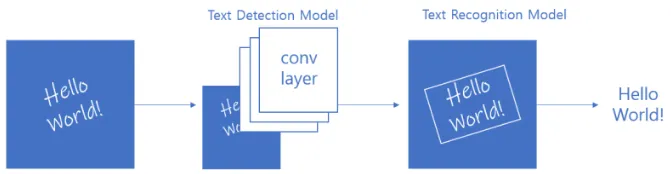
그 결과, 현재의 OCR은 딥러닝을 적용한 OCR은 글자의 영역을 탐지하는 모델(Text Detection Model)과 해당 영역에서 글자를 인식하는 모델(Text Recognition Model) 두 가지 단계로 구성되어 있다.
◦
이처럼 OCR의 과정을 두 단계로 나누는 이유는 데이터를 다양하게 활용하여 원활한 학습이 가능하고, 자원의 효율성과 언어별 정확도 등을 향상시킬 수 있기 때문

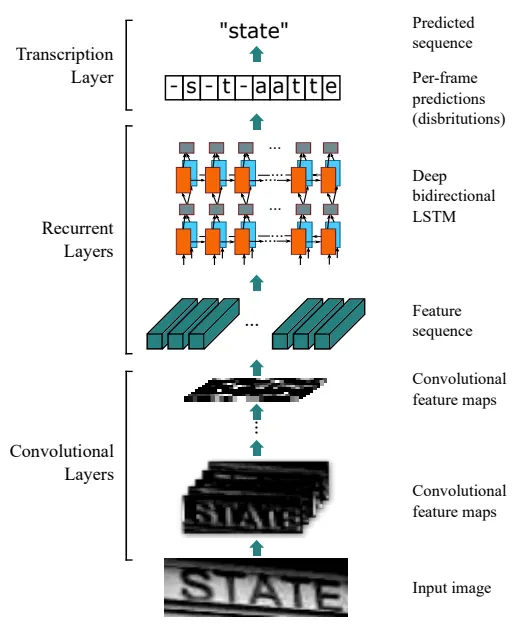
CNN과 RNN, CTC loss를 사용하여 input으로 부터 시퀀스를 인식하는 것
•
시퀀스를 인식하는 다양한 부분에 적용할 수 있으나 본 논문에서는 이미지(input)로부터 텍스트(output) 시퀀스를 추출하는 것에 대해서 설명하고 있다.
네트워크 구조
•
Convolutional Layer
◦
입력 이미지로부터 특징 시퀀스를 추출.
◦
CNN을 통해서 input 이미지로 부터 feature sequence를 추출한다.
•
Recurrent Layers
◦
각 프레임마다 라벨을 예측.
◦
추출한 feature sequence들을 RNN의 input으로 하여 이미지의 택스트 시퀀스를 예측한다.
•
Transcription Layers
◦
프레임마다의 예측을 최종 라벨 시퀀스로 변경.
◦
예측된 텍스트 시퀀스를 텍스트로 변환한다.