


•
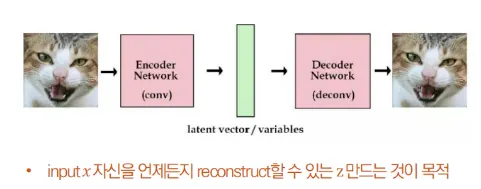
VAE는 Input image X를 잘 설명하는 feature를 추출하여 Latent vector z에 담고, 이 Latent vector z를 통해 X와 유사하지만 완전히 새로운 데이터를 생성하는 것을 목표로 한다.
•
이때 각 feature가 가우시안 분포를 따른다고 가정하고 latent z는각 feature의 평균과 분산값을 나타낸다.
◦
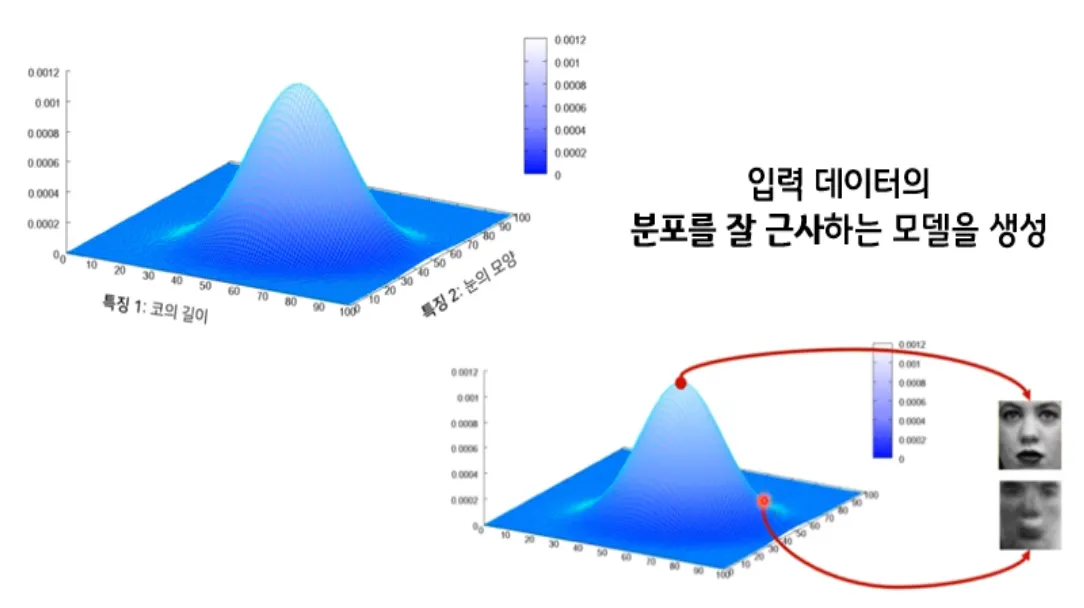
예를 들어 한국인의 얼굴을 그리기 위해 눈, 코, 입 등의 feature를 Latent vector z에 담고, 그 z를 이용해 그럴듯한 한국인의 얼굴을 그려내는 것이다.
◦
latent vector z는 한국인 눈 모양의 평균 및 분산, 한국인 코 길이의 평균 및 분산, 한국인 머리카락 길이의 평균 및 분산 등등의 정보를 담고 있다고 생각할 수 있다.
VAE 모델 구조
•
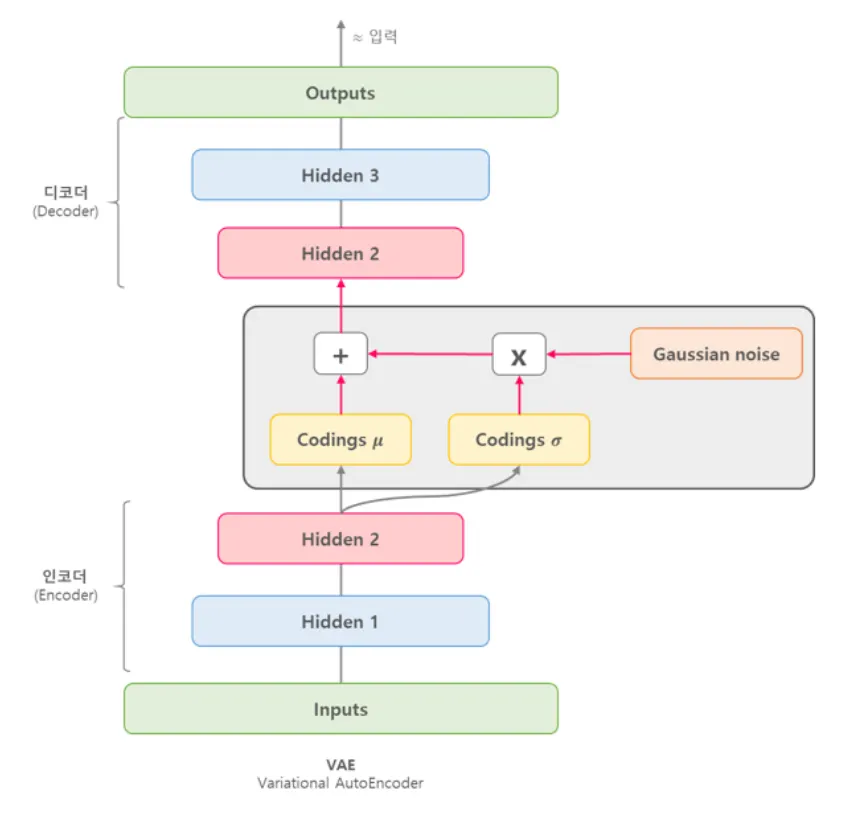
Input image X를 Encoder에 통과시켜 Latent vector z를 구하고, Latent vector z를 다시 Decoder에 통과시켜 기존 input image X와 비슷하지만 새로운 이미지 X를 찾아내는 구조
•
VAE는 input image가 들어오면 그 이미지에서의 다양한 특징들이 각각의 확률 변수가 되는 어떤 확률 분포를 만들게 된다.
•
이런 확률 분포를 잘 찾아내고, 확률값이 높은 부분을 이용하면 실제에 있을법한 이미지를 새롭게 만들 수 있을 것이다.
AE vs. VAE
•
VAE(Variational AutoEncoder)는 기존의 AutoEncoder와 탄생 배경이 다르지만 구조가 상당히 비슷해서 Variational AE라는 이름이 붙은 것
•
즉, VAE와 AE는 엄연히 다르다.모델 구조 비교
모델 구조 비교
•
AutoEncoder의 목적은 Encoder에 있다. AE는 Encoder 학습을 위해 Decoder를 붙인 것
•
반대로 VAE의 목적은 Decoder에 있다. Decoder 학습을 위해 Encoder를 붙인 것
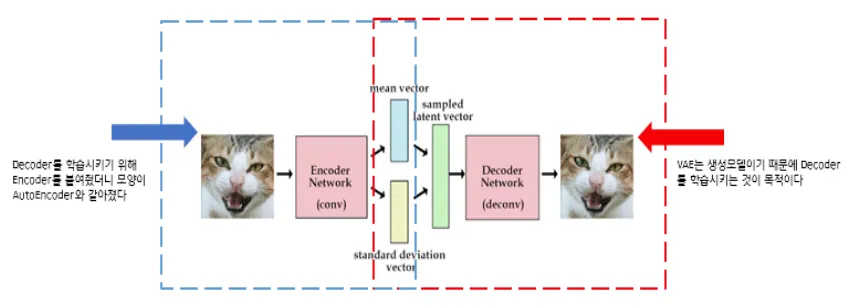
학습 방법 비교
•
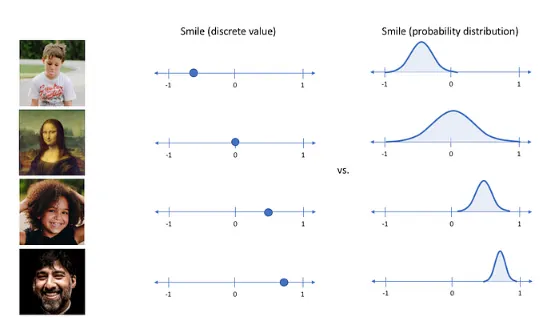
VAE는 단순히 입력값을 재구성하는 AE에서 발전한 구조로 추출된 잠재 코드의 값을 하나의 숫자로 나타내는 것이 아니라, 가우시안 확률 분포에 기반한 확률값 으로 나타낸다.
◦
AE : 잠재 코드 값이 어떤 하나의 값
◦
VAE : 잠재 코드 값이 평균과 분산으로 표현되는 어떤 가우시안 분포
결론
•
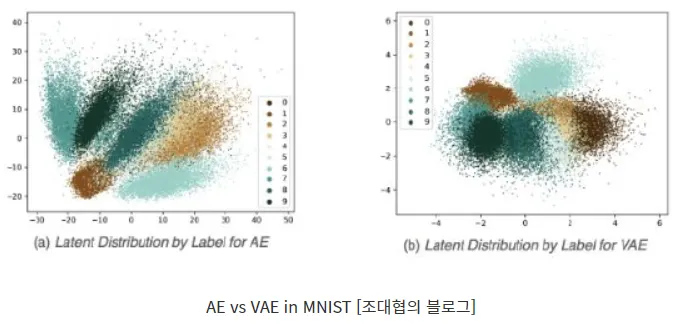
아래 그림은 MNist 데이터를 각각 AE와 VAE로 특징을 추출해 표현한 그림이다.
•
각 점의 색깔은 MNIST 데이터인 0~9의 숫자를 나타낸다.
•
AE가 만들어낸 잠재 공간은 군집이 비교적 넓게 퍼져있고, 중심으로 잘 뭉쳐있지 않지만, VAE가 만들어낸 잠재 공간은 중심으로 더 잘 뭉쳐져 있는 것을 확인 할 수 있다.
→ 따라서 원본 데이터를 재생하는데 AE에 비해서 VAE가 더 좋은 성능을 보인다는 것을 알 수 있다. 즉 VAE를 통해서 데이터의 특징을 파악하는게 더 유리하다.

•
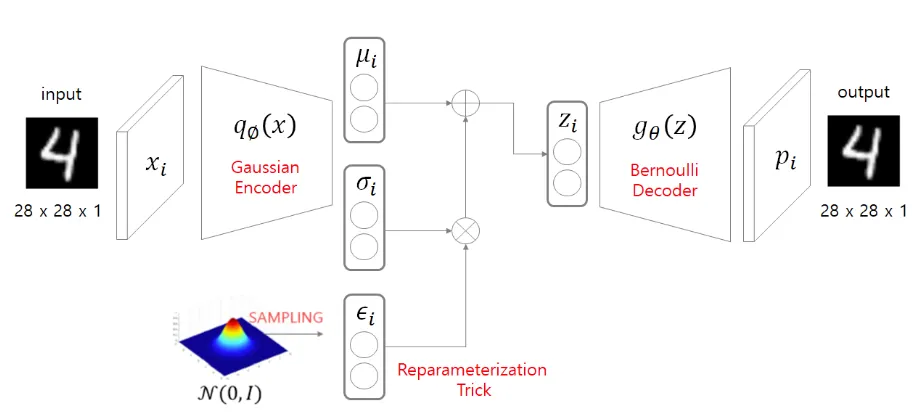
입력 (Input):
◦
입력 데이터로는 이미지(예: 고양이 이미지)와 해당 이미지의 라벨(label)이 함께 들어간다.
◦
이 라벨은 조건으로 작용하며, 모델이 데이터를 생성할 때 특정한 속성을 반영하도록 돕는다.
•
Encoder Neural Network (인코더 신경망):
◦
인코더는 입력 데이터(이미지와 라벨)를 받아 이를 잠재 공간(latent space)으로 변환한다.
◦
이때, 인코더는 잠재 변수 z에 대한 두 가지 중요한 값을 출력한다:
▪
μ (뮤): 잠재 공간에서 각 차원의 평균 값을 나타낸다.
▪
σ (시그마): 잠재 공간에서 각 차원의 표준편차 값을 나타낸다.
•
Reparameterization Trick:
◦
인코더에서 출력된 μ와 σ는 잠재 변수 z를 만들기 위해 사용된다.
◦
이 과정에서 가우시안 분포 에서 샘플링된 ε (엡실론)이 σ와 곱해지고, μ와 더해진다.
◦
이 과정을 통해 잠재 변수 z를 샘플링하게 된다.
◦
수식적으로는 다음과 같다:
▪
▪
▪
◦
이 과정은 샘플링 과정에서의 불확실성을 반영하면서도 미분 가능한 방식으로 설계된 것으로, VAE에서 중요한 재매개변수화 트릭(Reparameterization Trick)이다.
•
잠재 변수 Z:
◦
위 과정에서 생성된 잠재 변수 Z는 이후에 Decoder로 전달된다.
◦
이 잠재 변수는 이미지의 주요 특징을 압축하여 나타낸 정보이다.
◦
이 잠재 변수는 조건 라벨과 결합되어, 디코더가 이를 기반으로 특정 조건을 가진 이미지를 생성할 수 있게 한다.
•
Decoder Neural Network (디코더 신경망):
◦
디코더는 인코더의 반대 역할을 하며, 잠재 변수 z와 조건 정보를 입력받아 원래의 이미지를 복원하려고 시도한다.
◦
이를 통해 VAE는 입력과 유사한 데이터를 생성하게 된다.
•
출력 (Output):
◦
최종적으로 디코더를 통해 생성된 이미지가 출력된다.
◦
이 출력 이미지는 주어진 조건(라벨)에 맞는 특징을 갖추고 있으며, 인코더의 입력 이미지와 비슷한 형태를 띠게 된다.
Model
•
Encoder
class Encoder(nn.Module):
def __init__(self, x_dim, h_dim1, h_dim2, z_dim, c_dim):
super().__init__()
# encoder part
self.fc1 = nn.Linear(x_dim + c_dim, h_dim1)
self.fc2 = nn.Linear(h_dim1, h_dim2)
self.fc31 = nn.Linear(h_dim2, z_dim)
self.fc32 = nn.Linear(h_dim2, z_dim)
def forward(self, x, c):
concat_input = torch.cat([x, c], 1)
h = F.relu(self.fc1(concat_input))
h = F.relu(self.fc2(h))
return self.fc31(h), self.fc32(h)
Python
복사
•
Decoder
•
CVAE
