


생성적 적대 신경망(GAN, Generative Adversarial Networks)
•
GAN은 단순히 특정한 이미지를 이해하고 분류하는 것을 넘어서 실제 데이터와 흡사한 가짜 데이터를 생성하는 알고리즘
•
GAN은 생성자(Generator) 모델과 구분자(Discriminator) 모델로 두 개의 모델이 학습하는 방식으로 동작한다.
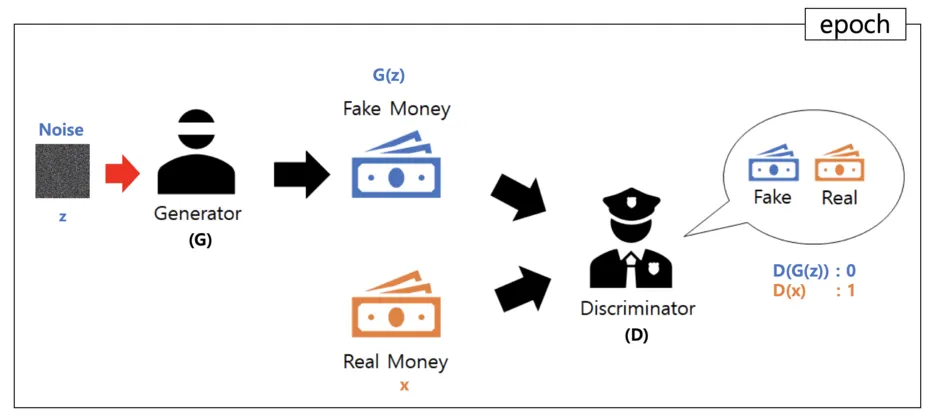
GAN 학습 과정
1.
구분자 모델은 먼저 진짜 데이터를 진짜로 분류하도록 학습시킨다.
2.
다음으로 생성자 모델이 생성한 데이터를 가짜로 분류하도록 학습시킨다.
3.
마지막으로 학습된 구분자 모델을 속이는 방향으로 생성자 모델을 학습시킨다.
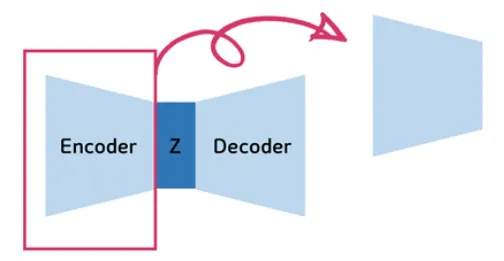
Encoder 부분이 구분자(Discriminator)부분이며, Decoder 부분이 생성자(Generator)가 되는 구조이다.
•
따라서 Generator는 이미 압축된 저차원의 latent variable의 z가 Generator 네트워크를 통과하게 되면 이미지가 나오게 된다. -> 복원이 되는 것!
•
그러면 방금 복원된 가짜 이미지랑 진짜 이미지(x)가 discriminator network로 들어간다.
•
이때 D(x)라는 것은 진짜 이미지가 들어간 것이고, D(G(z))는 만들어진 가짜 이미지가 들어간 것이다.
•
Discriminator의 output이 1이면 real, 0이면 fake라고 예측을 한 것이다.
•
즉 Discriminator가 정확하다면 D(x)는 항상 1이어야하고 D(G(z))는 항상 0이라고 답해야 한다. -> 그게 Discriminator 목적!
•
GAN의 학습은 두 네트워크가 서로 경쟁하는 2인 게임(two-player game) 방식으로 이루어진다.
◦
Generator 학습: 생성자는 판별자를 속이기 위해 점점 더 진짜처럼 보이는 이미지를 생성한다. 그 과정에서 판별자가 생성자의 이미지를 가짜로 판단할수록 생성자는 더 나은 이미지를 만들기 위해 학습된다.
◦
Discriminator 학습: 판별자는 진짜 이미지와 가짜 이미지를 더 잘 구분할 수 있도록 학습된다. 판별자의 목표는 가짜 이미지를 진짜 이미지로 속지 않도록 학습하는 것이다.
두 네트워크는 서로 경쟁하면서 동시에 학습하게 된다. 생성자는 판별자를 속이려고 하고, 판별자는 속지 않으려고 하면서 두 모델이 점점 더 강력해진다.
GAN 모델 구조
•
Generator: 가짜 사진을 만드는 네트워크
•
Discriminator: 진짜와 가짜를 구분할 수 있는 네트워크
이 두가지 네트워크가 서로 경쟁하는 구조이다.
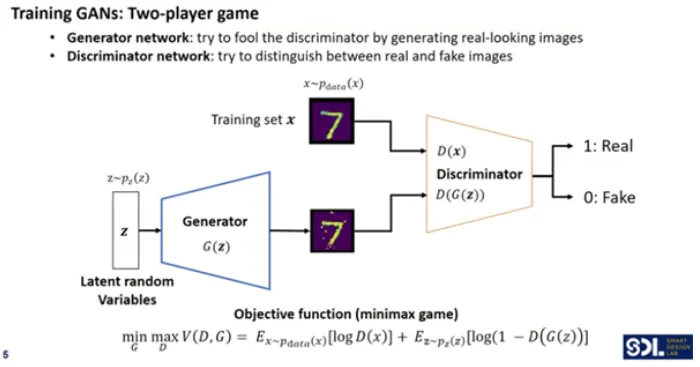
1. Generator (생성자 네트워크)
•
설명
◦
생성자는 무작위 잠재 변수(latent random variable) z를 입력으로 받아, 이를 통해 가짜 이미지(fake image)를 생성한다.
◦
이 가짜 이미지는 진짜 이미지처럼 보이도록 설계된다.
•
목표: 생성자는 판별자를 속여, 가짜 이미지를 진짜 이미지로 분류하게 만드는 것이 목표이다.
◦
생성자는 판별자의 출력이 1(진짜)로 나오도록 이미지를 생성하려고 한다.
2.
Discriminator (판별자 네트워크)
•
설명
◦
판별자는 진짜 이미지와 가짜 이미지를 구분하는 역할을 한다.
◦
진짜 이미지(Training set x)와 생성자가 만든 가짜 이미지를 입력으로 받아서, 해당 이미지가 진짜인지 가짜인지 판단한다.
•
목표: 판별자는 진짜 이미지를 1(진짜), 가짜 이미지를 0(가짜)으로 정확하게 분류하는 것이 목표이다.
◦
진짜 이미지에 대해선 1을 출력하고, 가짜 이미지에 대해선 0을 출력하려고 한다.
3.
Objective Function (목표 함수)
•
GAN의 목표 함수는 minimax 게임으로 표현되며, 생성자와 판별자의 경쟁을 수학적으로 표현한 것이다.
•
수식
◦
: 판별자가 진짜 이미지를 얼마나 진짜로 판단하는지(진짜 이미지에 대해 높은 확률을 주기 원함).
◦
: 판별자가 생성자가 만든 가짜 이미지를 얼마나 가짜로 판단하는지(가짜 이미지에 대해 낮은 확률을 주기 원함).
◦
생성자는 값을 최대화하려고 하고, 판별자는 값을 최대화하고 를 최소화하려고 한다.
Objective function / loss function
Discriminator 학습
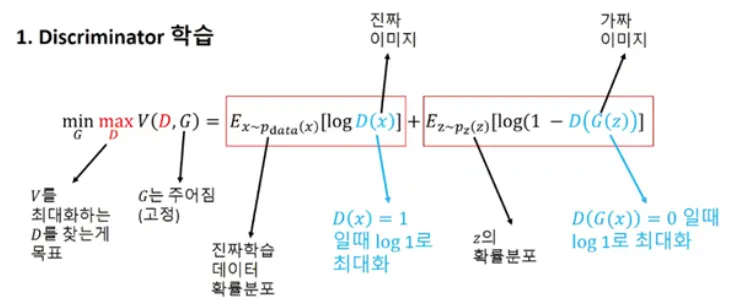
목표 함수 (Objective Function)
•
수식:
◦
: 판별자가 진짜 이미지를 진짜로 인식할 확률.
◦
: 판별자가 가짜 이미지를 진짜로 인식할 확률.
Discriminator(판별자)의 목표
•
:
◦
설명: Discriminator(판별자)는 진짜 이미지를 진짜(1)로, 가짜 이미지를 가짜(0)로 정확히 구분하는 것이 목표다.
◦
일 때 이 최대값이므로, 진짜 이미지를 진짜로 잘 구분했을 때 판별자는 높은 점수를 얻게 된다.
◦
반대로, 일 때 이 최대값이므로, 가짜 이미지를 잘 구분할 때 높은 성능을 보인다.
첫 번째 항목: 진짜 이미지 판별 (Real Image)
•
◦
설명: 첫 번째 항목은 진짜 이미지를 입력으로 했을 때, 판별자가 그 이미지를 진짜로 판단하는 로그 확률을 최대로 만든다.
◦
목표: 진짜 이미지 x에 대해 D(x)를 1로 만들어, log(1) 값을 최대로 만들어야 한다. 즉, 진짜 이미지에 대한 예측을 최대화하는 것이 목표다.
두 번째 항목: 가짜 이미지 판별 (Fake Image)
•
◦
설명: 두 번째 항목은 생성자(G)에서 생성한 가짜 이미지를 판별자가 가짜로 인식할 확률을 높이는 부분이다.
◦
목표: 가짜 이미지에 대해 이 될 때, 이 최대값을 가지므로, 가짜 이미지를 잘 구분할수록 판별자의 성능이 높아진다.
최종 목표: V를 최대화하는 D 찾기
•
Discriminator 학습
◦
이 목표 함수는 Discriminator가 진짜 이미지를 진짜로, 가짜 이미지를 가짜로 최대한 정확하게 구분하는 방향으로 학습하는 과정이다.
◦
따라서 판별자는 진짜와 가짜 이미지를 최대한 구분할 수 있도록 최적화된다.
Generator 학습

1. 목표 함수 설명
이 식에서 Discriminator와 Generator는 서로 반대의 목표를 가진다.
•
◦
Discriminator(판별자)는 진짜 이미지를 잘 구분하고, 가짜 이미지를 거부하면서 자신이 진짜와 가짜를 얼마나 잘 구분할 수 있는지를 최대화하려고 한다.
•
◦
Generator(생성자)는 Discriminator가 생성한 가짜 이미지를 진짜로 인식하도록 목적 함수를 최소화하려고 학습한다.
◦
Generator는 Discriminator를 속여야 성공적인 학습을 한 것으로 간주된다.
2. Generator 학습 목표
•
Generator의 학습 목표는 Discriminator가 가짜 이미지를 진짜로 인식하게 하는 것이다.
•
구체적으로, 수식의 두 번째 항목 :
◦
이 항목에서 Generator는 Discriminator가 가짜 이미지를 진짜로 잘못 판별할 수 있도록 만드는 방향으로 학습한다.
◦
: 랜덤한 노이즈 를 Generator가 받아서 생성한 가짜 이미지를 의미한다.
◦
: Discriminator가 이 가짜 이미지를 진짜로 판별할 확률을 나타낸다.
◦
목표
▪
Generator는 를 1로 만들고 싶어 한다.
▪
즉, Discriminator가 가짜 이미지를 진짜라고 판별하도록 만드는 것이 목표다.
▪
이를 통해 Discriminator를 점점 더 어렵게 속이는 가짜 이미지를 만들어낸다.
3. 가짜 이미지 판별 항목 설명
•
두 번째 항목 는 Generator가 학습할 때 중요한 역할을 한다.
◦
이 항목은 가짜 이미지에 대해 Discriminator가 진짜로 판별하는 확률을 최소화하려고 한다.
◦
즉, Generator는 값을 최소화하려고 학습한다.
◦
여기서 이 되도록 만들고 싶어 하므로, 의 상황이 최종적으로 이루어져야 한다.
4. 전체 학습 전략
•
Generator는 Discriminator를 속이는 것이 목표다.
◦
진짜처럼 보이는 가짜 이미지를 생성하여 Discriminator가 이를 진짜라고 판별하도록 만든다.
•
Discriminator의 실수를 유도하며, Generator는 가짜 이미지의 품질을 지속적으로 개선하여, 결국 Discriminator가 더 이상 진짜와 가짜를 정확히 구분할 수 없도록 만든다.
Conditional GAN
•
CGAN은 생성자와 판별자가 훈련하는 동안 추가 정보를 사용해 조건이 붙는 생성적 적대 신경망
•
CGAN을 이용하면 우리가 원하는 class가 담긴 데이터를 생성할 수 있다.
•
생성자와 판별자를 훈련하는 데 모두 label을 사용한다.
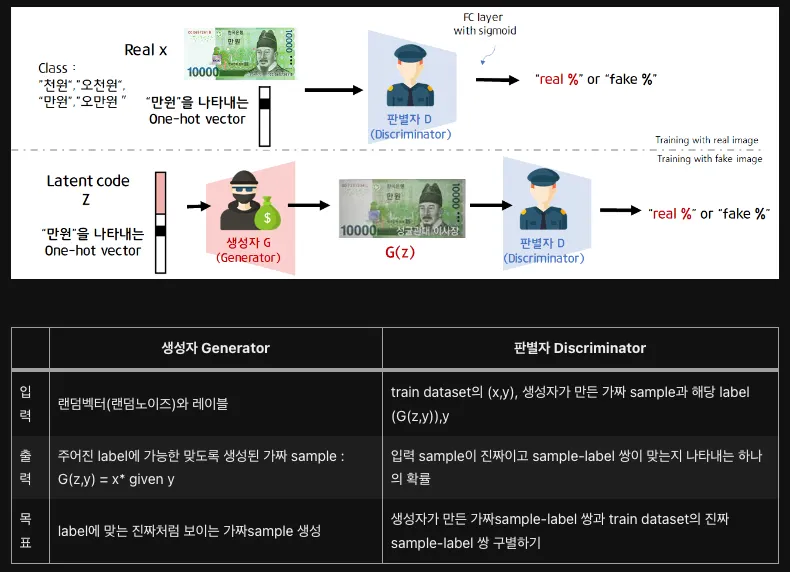
CGAN 모델 구조
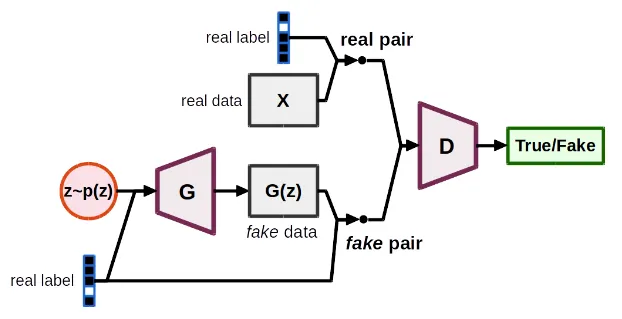
입력 노이즈 ():
•
왼쪽 상단의 주황색 원은 랜덤한 노이즈 벡터 z를 생성하는 과정
•
이 벡터는 잠재 공간에서 샘플링한 값으로, 생성기(G)가 이 노이즈를 이용해 새로운 데이터를 만들기 위한 입력값으로 사용한다.
조건 레이블 (real label):
•
노이즈 외에도 CGAN은 추가적인 조건을 입력으로 받는다.
•
여기서 조건 레이블은 실제 데이터를 나타내는 레이블
◦
특정 클래스를 나타내거나 생성할 데이터를 제어하는 데 사용한다.
•
이 조건 레이블은 생성기(G)와 판별기(D) 모두에 입력으로 들어간다.
생성기 (Generator, G):
•
노이즈 벡터 z와 조건 레이블을 입력으로 받아 가짜 데이터를 생성한다.
•
이때 생성기는 입력된 노이즈와 조건을 기반으로 실제 데이터와 비슷한 가짜 데이터를 만들어야 한다.
•
생성된 데이터는 로 표현되고, 이 데이터는 이후 판별기()로 전달된다.
진짜 데이터 (Real Data, X):
•
생성된 가짜 데이터 외에도, 판별기에는 실제 데이터 도 입력으로 주어진다.
•
이때 진짜 데이터에도 조건 레이블이 함께 제공되어 판별기에 입력된다.
판별기 (Discriminator, D):
•
진짜 데이터와 가짜 데이터를 구분하는 역할
•
진짜 데이터와 가짜 데이터가 모두 조건 레이블과 함께 입력으로 들어가고, 판별기는 해당 데이터가 진짜(real)인지 가짜(fake)인지 예측하게 된다.
•
최종적으로 판별기는 "진짜/가짜"에 대한 결과를 출력
True/Fake 판정:
•
판별기는 입력으로 들어온 데이터가 진짜(real)인지 가짜(fake)인지를 판단하여 최종적으로 "True" 또는 "Fake"로 결과를 내어준다.
Deep Convolutional GAN
•
DCGAN은 CNN 구조로 판별자 D와 생성자 G를 구성한 GAN
•
판별자 D는 이미지를 입력으로 받아 binary classification을 수행하는 CNN 구조이다.
•
생성자 G는 random vector z를 입력으로 받아 이미지를 생성하는 deconvolutional entwork 구조를 갖게 된다.
•
DCGAN의 특징으로는 pooling layer를 사용하지 않고 stride 2이상인 convolution, deconvolution을 사용하였다.
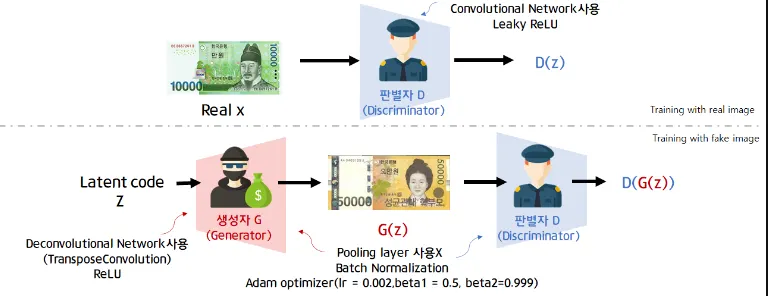
DCGAN 모델 구조
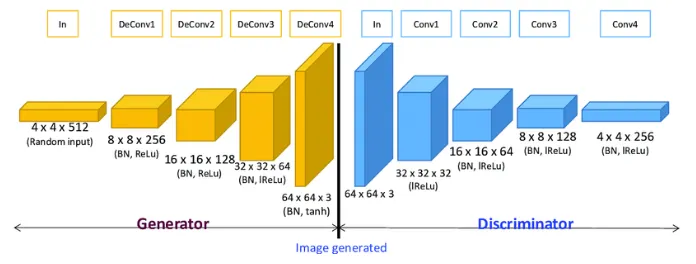
생성자(Generator):
1.
입력(Input): 4x4x512 크기의 랜덤 벡터가 잠재 공간(latent space)에서 입력된다. 이 랜덤 노이즈 벡터는 점진적으로 복원되어 이미지를 생성하게 된다.
2.
Deconvolution Layers (전치 합성곱 층):
•
첫 번째 층: 랜덤 벡터가 8x8x256 크기의 특징 맵(feature map)으로 변환되며, 배치 정규화(Batch Normalization, BN)와 ReLU 활성화 함수가 적용된다.
•
두 번째 층: 16x16x128 크기로 확장되며, 동일하게 BN과 ReLU 활성화 함수가 적용된다.
•
세 번째 층: 32x32x64 크기로 변환되며, BN과 ReLU가 사용된다.
•
네 번째 층: 마지막으로 64x64x3 크기의 이미지가 생성되며, 이 단계에서는 배치 정규화와 tanh 활성화 함수가 사용되어 픽셀 값을 [-1, 1] 사이로 조정한다. 이 출력은 최종적으로 생성된 이미지이다.
판별자(Discriminator):
1.
입력(Input): 64x64x3 크기의 이미지가 입력되며, 이는 생성자에서 나온 이미지이거나 실제 데이터셋에서 추출된 이미지일 수 있다.
2.
Convolution Layers (합성곱 층):
•
첫 번째 층: 64x64x3 이미지가 32x32x64 크기의 특징 맵으로 다운샘플링된다. 이때 배치 정규화가 적용되지 않으며, Leaky ReLU 활성화 함수가 사용된다.
•
두 번째 층: 16x16x128 크기로 변환되며, 배치 정규화(BN)와 Leaky ReLU가 적용된다.
•
세 번째 층: 8x8x128 크기로 축소되며, BN과 Leaky ReLU가 사용된다.
•
네 번째 층: 마지막으로 4x4x256 크기로 축소되며, 동일하게 BN과 Leaky ReLU 활성화 함수가 적용된다.
3.
출력(Output): 마지막에 1x1 출력으로 축소되어 해당 이미지가 실제(real)인지 가짜(fake)인지 여부를 판별하는 값이 생성된다. 이를 통해 판별자는 입력된 이미지가 진짜인지 가짜인지 학습하게 된다.
모델
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def convlayer(n_input, n_output, k_size=4, stride=2, padding=0):
block = [
nn.ConvTranspose2d(n_input, n_output, kernel_size=k_size, stride=stride, padding=padding, bias=False),
nn.ReLU(inplace=True),
nn.BatchNorm2d(n_output),
]
return block
self.project = nn.Sequential(
nn.Linear(opt.latent_dim, 256 * 4 * 4),
nn.BatchNorm1d(256 * 4 * 4),
nn.ReLU(inplace=True),
)
# pytorch doesn't have padding='same' as keras does.
# hence we have to pad manually to get the desired behavior.
# from the manual:
# o = (i−1)∗s−2p+k, i/o = in/out-put, k = kernel size, p = padding, s = stride.
self.model = nn.Sequential(
*convlayer(opt.latent_dim, 256, 4, 1, 0), # Fully connected layer via convolution.
*convlayer(256, 128, 4, 2, 1), # 4->8, (4-1)*2-2p+4 = 8, p = 1
*convlayer(128, 64, 4, 2, 1), # 8->16, p = 1
nn.ConvTranspose2d(64, opt.channels, 4, 2, 1),
nn.Tanh()
)
# Tanh > Image values are between [-1, 1]
def forward(self, z):
# p = self.project(z)
# p = p.view(-1, 256, 4, 4) # Project and reshape (notice that pytorch uses NCHW format)
img = self.model(z)
img = img.view(z.size(0), *img_dims)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# Again, we must ensure the same padding.
# From the manual:
# o = (i+2p−d∗(kernel_size−1)−1)/s+1, d = dilation (default = 1).
self.model = nn.Sequential(
nn.Conv2d(opt.channels, 64, 4, 2, 1, bias=False), # 32-> 16, (32+2p-3-1)/2 + 1 = 16, p = 1
nn.LeakyReLU(0.2, inplace=True),
# nn.BatchNorm2d(64), # IS IT CRUCIAL TO SKIP BN AT FIRST LAYER OF DISCRIMINATOR?
nn.Conv2d(64, 128, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.BatchNorm2d(128),
nn.Conv2d(128, 256, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.BatchNorm2d(256),
nn.Conv2d(256, 1, 4, 1, 0, bias=False), # FC with Conv.
nn.Sigmoid()
)
# we used 3 convolutional blocks, hence 2^3 = 8 times downsampling.
semantic_dim = opt.img_size // (2**3)
self.l1 = nn.Sequential(
nn.Linear(256 * semantic_dim**2, 1),
nn.Sigmoid()
)
def forward(self, img):
prob = self.model(img)
# prob = self.l1(prob.view(prob.size(0), -1))
return prob
Python
복사
Information Maximizing GAN
•
기존 GAN의 생성 모델의 input의 latent variable z 하나인 것에 비해 InfoGAN은 code라는 의미의 latent variable c가 추가되어 G(z,c) 형태로 만들어진다.
◦
z: 더이상 압축할 수 없는 noise.
◦
c: latent code라고 부르며 data distribution의 semantic feature를 표현
•
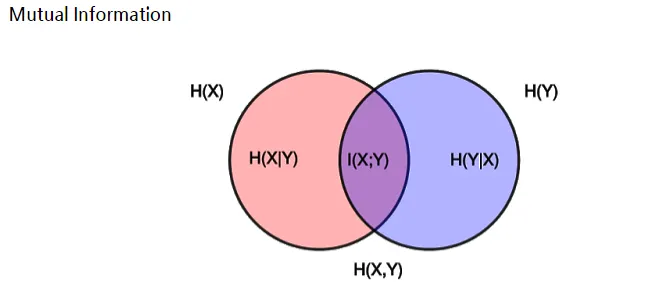
여기서 z와 c의 Mutual Information(MI)를 최대화시켜, 기존 GAN과는 차별화된 모습을 보여준다.
Model
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def convlayer(n_input, n_output, k_size=5, stride=2, padding=0, output_padding=0):
block = [
nn.ConvTranspose2d(n_input, n_output, kernel_size=k_size, stride=stride, padding=padding, bias=False, output_padding=output_padding),
nn.BatchNorm2d(n_output),
nn.ReLU(inplace=True),
]
return block
self.conv_block = nn.Sequential(
*convlayer(opt.latent_dim, 1024, 1, 1), # 1024 x 1 x 1
*convlayer(1024, 128, 7, 1, 0), # 128 x 7 x 7
*convlayer(128, 64, 4, 2, 1), # 64 x 14 x 14
nn.ConvTranspose2d(64, opt.channels, 4, 2, 1, bias=False), # 1 x 28 x 28
nn.Tanh()
)
def forward(self, z):
z = z.view(-1, opt.latent_dim, 1, 1)
img = self.conv_block(z)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def convlayer(n_input, n_output, k_size=4, stride=2, padding=0, normalize=True):
block = [nn.Conv2d(n_input, n_output, kernel_size=k_size, stride=stride, padding=padding, bias=False)]
if normalize:
block.append(nn.BatchNorm2d(n_output))
block.append(nn.LeakyReLU(0.1, inplace=True))
return block
self.model = nn.Sequential( # 1 x 28 x 28
*convlayer(opt.channels, 64, 4, 2, 1, normalize=False), # 64 x 14 x 14
*convlayer(64, 128, 4, 2, 1), # 128 x 7 x 7
*convlayer(128, 1024, 7, 1, 0), # 1024 x 1 x 1
)
# Regular probability of pertaining to real distribution.
self.d_head = nn.Sequential(
nn.Linear(1024, 1),
nn.Sigmoid(),
)
# Continuous.
self.q_head_C = nn.Sequential(
nn.Linear(1024, 128),
nn.BatchNorm1d(128),
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(128, 2)
)
# Discrete (digits).
self.q_head_D = nn.Sequential(
nn.Linear(1024, 128),
nn.BatchNorm1d(128),
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(128, 10),
nn.Softmax(dim=1)
)
def forward(self, img):
conv_out = self.model(img)
conv_out = conv_out.squeeze(dim=3).squeeze(dim=2)
prob = self.d_head(conv_out)
# Continuous output parameters.
q = self.q_head_C(conv_out)
# mu, std = self.q_head_C_mu(q), self.q_head_C_std(q).exp()
# Discrete outputs.
digit_probs = self.q_head_D(conv_out)
return prob, digit_probs, q # mu, std
Python
복사
Mutual Information for Inducing Latent Codes
•
기존의 GAN모델이 entangled(얽혀있는) representation들을 학습해왔는데, InfoGAN에서는 disentangled(엉킨것이 풀어진) representation들을 학습하는 방법을 제시한다.

일반적인 GAN은 input에서 noise에 대한 아무런 제약이 없으므로 noise에 대한 정보를 알 수 없다.
즉, noise input 에서 어느부분이 어떤 representation을 조절하는지를 알기 힘들다.
하지만 이것을 disentangle하게 , 다시말하면 해석가능하게(어느부분이 의미를 가지도록) 만들어 핵심적인 representation을 학습 할 수 있게 해준다는 것이다.

InfoGAN 모델 구조
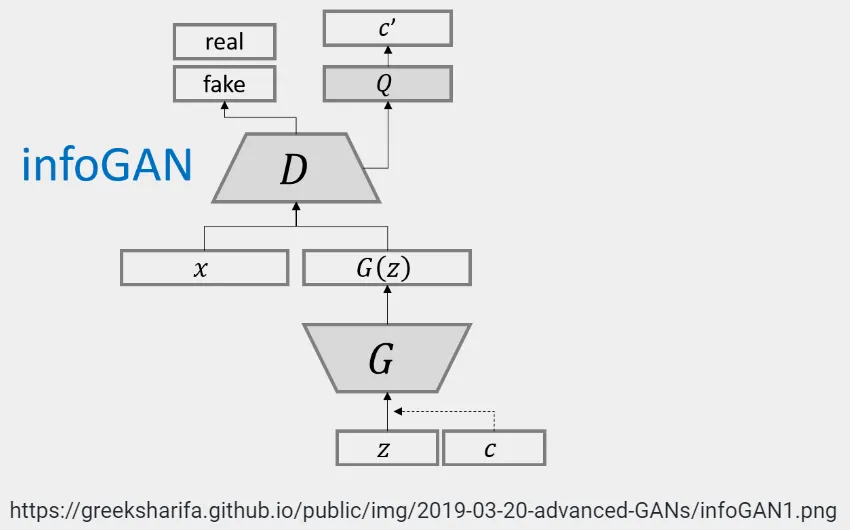
생성자(Generator, G):
•
입력 z와 c: 일반적인 GAN에서의 잠재 변수 z와 더불어 InfoGAN에서는 조건 변량 가 추가된다. 이 c는 특정한 속성(예: 숫자의 종류, 이미지의 스타일 등)을 컨트롤하는 정보성 변량이다.
•
G는 z와 c를 입력받아 이미지 를 생성한다. 여기서 c를 통해 생성된 데이터의 특징을 제어할 수 있다.
판별자(Discriminator, D):
•
입력 와 : 판별자는 생성자에서 만들어진 이미지가 실제(real)인지 가짜(fake)인지를 판단하는 기존 GAN과 동일한 역할을 한다. 생성된 이미지나 실제 이미지를 받아 이진 분류를 수행하여 결과를 출력한다.
Q 네트워크:
•
InfoGAN의 중요한 부분은 Q 네트워크이다
◦
이 네트워크는 D와 함께 학습되며, 생성된 이미지에서 원래의 정보성 변량 c를 추정하는 역할을 한다.
•
즉, Q는 생성된 이미지에서 c'를 추출하여 원래 입력된 c와 비교하게 된다.
◦
이를 통해 생성자가 이미지의 특정 속성(정보성 변량)을 잘 반영하는지를 학습할 수 있게 한다.
작동 원리
•
정보성 변량 c를 추가함으로써, 단순히 이미지를 생성하는 것이 아니라 특정한 속성을 가진 이미지를 생성할 수 있다.
•
예를 들어, 숫자 이미지를 생성하는 경우 c가 '숫자의 종류'라면, InfoGAN은 특정 숫자를 생성하도록 학습될 수 있다.
Model
class ResidualBlock(nn.Module):
def __init__(self, n_input, n_output, k_size, resample='up', bn=True, spatial_dim=None):
super(ResidualBlock, self).__init__()
self.resample = resample
if resample == 'up':
self.conv1 = UpsampleConv(n_input, n_output, k_size)
self.conv2 = nn.Conv2d(n_output, n_output, k_size, padding=(k_size-1)//2)
self.conv_shortcut = UpsampleConv(n_input, n_output, k_size)
self.out_dim = n_output
elif resample == 'down':
self.conv1 = nn.Conv2d(n_input, n_input, k_size, padding=(k_size-1)//2)
self.conv2 = ConvMeanPool(n_input, n_output, k_size)
self.conv_shortcut = ConvMeanPool(n_input, n_output, k_size)
self.out_dim = n_output
self.ln_dims = [n_input, spatial_dim, spatial_dim] # Define the dimensions for layer normalization.
else:
self.conv1 = nn.Conv2d(n_input, n_input, k_size, padding=(k_size-1)//2)
self.conv2 = nn.Conv2d(n_input, n_input, k_size, padding=(k_size-1)//2)
self.conv_shortcut = None # Identity
self.out_dim = n_input
self.ln_dims = [n_input, spatial_dim, spatial_dim]
self.model = nn.Sequential(
nn.BatchNorm2d(n_input) if bn else nn.LayerNorm(self.ln_dims),
nn.ReLU(inplace=True),
self.conv1,
nn.BatchNorm2d(self.out_dim) if bn else nn.LayerNorm(self.ln_dims),
nn.ReLU(inplace=True),
self.conv2,
)
def forward(self, x):
if self.conv_shortcut is None:
return x + self.model(x)
else:
return self.conv_shortcut(x) + self.model(x)
Python
복사
•
Pix2Pix는 image를 image로 변환하도록 generator을 학습한다.
•
예를 들어, generator의 입력값으로 스케치 그림을 입력하면 완성된 그림이 나오도록 학습할 수 있다.
•
기존 GAN과 비교하여 설명하자면, Pix2Pix는 기존 GAN의 noise 대신에 스케치 그림을 입력하여 학습을 하는 것이다.
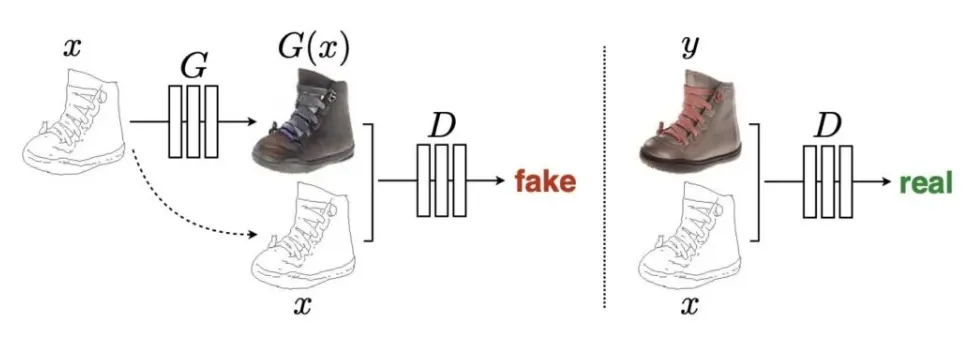
•
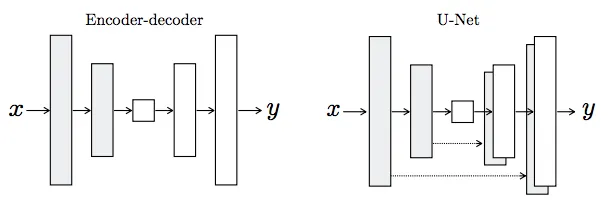
pix2pix의 특징은 일반적인 인코더-디코더(Encoder-Decoder)보다는 U-NET을 사용한다.
•
U-NET의 특징은 일반적인 인코더-디코더와 달리 스킵 커넥션 (Skip Connections)이 있어, 인코더 레이어와 디코더 레이어 간의 연결을 보다 로컬라이징(localization)을 잘 해주는 특징이 있다.
•
예를 들어, 첫 인코더 레이어 크기가 256 x 256 x 3이라면, 마지막 디코더 레이어 크기도 똑같이 256 x 256 x 3이게 된다.
•
이렇게 같은 크기의 인코더-디코더 레이어가 결합하여, 보다 효과적이고 빠른 성능을 발휘할 수 있게 하는게 U-NET의 특징이다.
class GeneratorUNet(nn.Module):
def __init__(self, in_channels=3, out_channels=3):
super(GeneratorUNet, self).__init__()
self.down1 = UNetDown(in_channels, 64, normalize=False)
self.down2 = UNetDown(64, 128)
self.down3 = UNetDown(128, 256)
self.down4 = UNetDown(256, 512, dropout=0.5)
self.down5 = UNetDown(512, 512, dropout=0.5)
self.down6 = UNetDown(512, 512, dropout=0.5)
self.down7 = UNetDown(512, 512, dropout=0.5)
self.down8 = UNetDown(512, 512, normalize=False, dropout=0.5)
self.up1 = UNetUp(512, 512, dropout=0.5)
self.up2 = UNetUp(1024, 512, dropout=0.5)
self.up3 = UNetUp(1024, 512, dropout=0.5)
self.up4 = UNetUp(1024, 512, dropout=0.5)
self.up5 = UNetUp(1024, 256)
self.up6 = UNetUp(512, 128)
self.up7 = UNetUp(256, 64)
self.final = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(128, out_channels, 4, padding=1),
nn.Tanh(),
)
def forward(self, x):
# U-Net generator with skip connections from encoder to decoder
d1 = self.down1(x)
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
d6 = self.down6(d5)
d7 = self.down7(d6)
d8 = self.down8(d7)
u1 = self.up1(d8, d7)
u2 = self.up2(u1, d6)
u3 = self.up3(u2, d5)
u4 = self.up4(u3, d4)
u5 = self.up5(u4, d3)
u6 = self.up6(u5, d2)
u7 = self.up7(u6, d1)
return self.final(u7)
class Discriminator(nn.Module):
def __init__(self, in_channels=3):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, normalization=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalization:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(in_channels * 2, 64, normalization=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1, bias=False)
)
def forward(self, img_A, img_B):
# Concatenate image and condition image by channels to produce input
img_input = torch.cat((img_A, img_B), 1)
return self.model(img_input)
Python
복사
