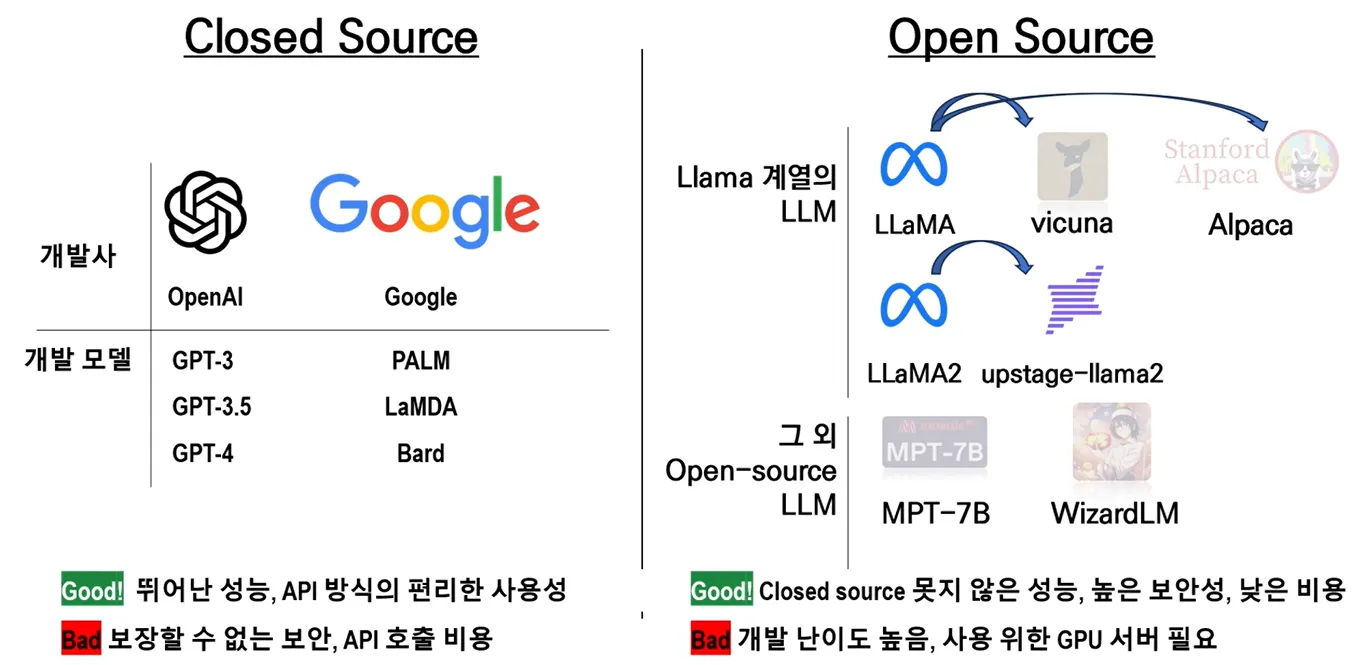
Open Source LLM
•
대규모 언어 모델은 전례 없는 정확성과 유창함으로 인간 언어를 이해하고, 생성하고, 상호 작용하는 놀라운 능력으로 인해 인기가 급상승했습니다.
•
OpenAI는 GPT-3.5 의 도입으로 LLM 환경을 크게 형성하여 현장에서 중요한 순간을 표시했습니다. 이전 버전과 달리 GPT-3.5는 완전한 오픈 소스가 아니었기 때문에 폐쇄 소스 대규모 언어 모델이 탄생했습니다.
Open Source LLM 특징
지역사회 기여
•
폭넓은 참여: 기여자 기반의 다양성은 프로젝트에 다양한 관점, 기술 및 요구 사항을 제공합니다.
•
혁신과 문제 해결: 다양한 기여자가 고유한 문제를 식별하거나 원래 개발자가 고려하지 않은 응용 프로그램에 대한 혁신적인 아이디어를 가지고 있을 수 있습니다.
광범위한 응용 분야
•
특수 사용 사례: 기여자는 종종 특수한 사용 사례에 맞게 오픈 소스 모델을 조정하고 확장합니다. 예를 들어, 개발자는 법률 문서의 언어 모델을 미세 조정하여 법률 연구 또는 의료 전문가를 지원하는 의학 문헌을 지원하는 도구를 만들 수 있습니다.
•
새로운 기능 및 개선 사항: 기여자는 모델 실험을 통해 보다 효율적인 훈련 알고리즘, 모델의 출력을 해석하는 새로운 방법 또는 다른 소프트웨어 도구와의 통합 기능과 같은 새로운 기능을 개발할 수 있습니다.
반복적인 개선과 진화
•
피드백 루프: 오픈 소스 모델은 지속적인 개선의 순환을 장려합니다. 커뮤니티에서는 모델을 사용하고 실험하면서 단점, 버그 또는 개선 기회를 식별할 수 있습니다.
•
협업 및 지식 공유: 오픈 소스 프로젝트는 커뮤니티 내에서 협업과 지식 공유를 촉진합니다. 기여 내용은 공개적으로 문서화되고 논의되는 경우가 많으므로 다른 사람들이 이를 통해 배우고, 이를 기반으로 하며, 새로운 상황에 적용할 수 있습니다.
Closed Source LLM 특징
통제된 품질과 일관성
•
중앙 집중식 개발: 비공개 소스 프로젝트는 전담 팀에 의해 개발, 유지 관리 및 업데이트되어 프로젝트의 일관된 품질과 방향을 보장합니다.
•
신뢰성 및 안정성: 집중적인 개발자 팀을 통해 비공개 소스 LLM은 종종 더 높은 신뢰성과 안정성을 제공하므로 일관성이 중요한 엔터프라이즈 애플리케이션에 적합합니다.
상업적 지원 및 혁신
•
공급업체 지원: 비공개 소스 모델에는 공급업체의 전문적인 지원과 서비스가 함께 제공되어 기업에 특히 유용할 수 있는 통합, 문제 해결 및 최적화에 대한 지원을 제공합니다.
•
독점 혁신: 비공개 소스 개발의 통제된 환경을 통해 고유한 독점 기능과 개선 사항을 도입할 수 있으며, 종종 특수 애플리케이션에서 기술의 한계를 뛰어넘습니다.
독점적 사용 및 지적 재산권
•
경쟁 우위: 비공개 소스 언어 모델의 독점적 특성을 통해 기업은 기본 기술을 경쟁업체에 공개하지 않고도 고급 AI 기능을 경쟁 우위로 활용할 수 있습니다.
•
지적 재산 보호: 비공개 소스 라이선스는 개발자의 지적 재산을 보호하여 개발자의 혁신이 독점적이고 상업적으로 가치가 있도록 보장합니다.
맞춤화 및 통합
•
맞춤형 솔루션: 비공개 소스 모델의 맞춤화는 오픈 소스 대안보다 더 제한적이지만 공급업체는 종종 맞춤형 솔루션을 제공하거나 특정 비즈니스 요구 사항을 충족하기 위해 특정 수준의 구성을 허용합니다.
•
원활한 통합: 폐쇄 소스 대규모 언어 모델은 기존 시스템 및 소프트웨어와 원활하게 통합되도록 설계되어 기업과 최종 사용자에게 원활한 환경을 제공합니다.
기업 입장에서의 LLM
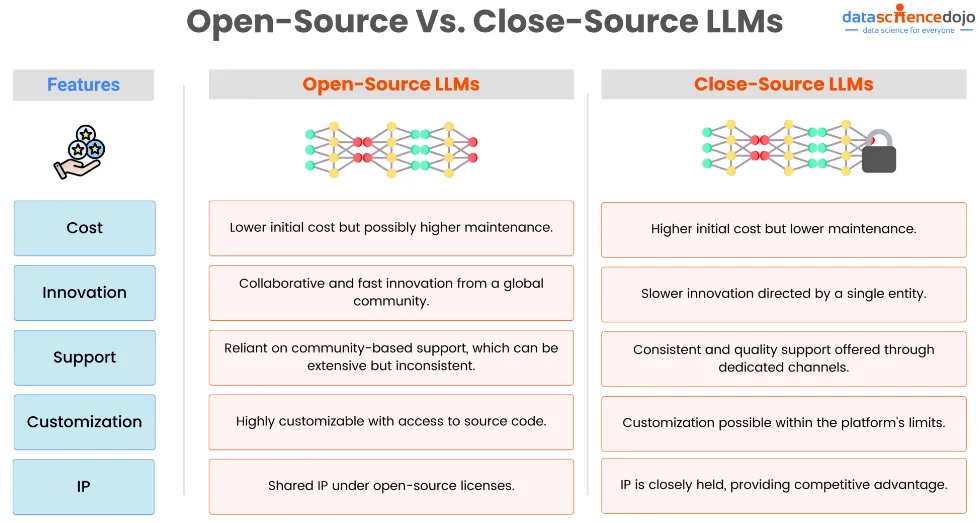
소송비용
•
오픈 소스: 일반적으로 소프트웨어 자체에 대한 라이선스 비용이 없기 때문에 초기 비용이 더 저렴합니다. 그러나 기업에서는 모델을 사용자 정의, 유지 관리 및 업데이트하기 위한 내부 전문 지식이 필요하기 때문에 인프라, 개발 및 잠재적으로 더 높은 운영 비용과 관련된 비용이 발생할 수 있습니다.
•
폐쇄 소스: 사용에 따라 예측 가능하게 확장될 수 있는 라이센스 비용, 구독 비용 또는 사용량 기반 가격이 포함되는 경우가 많습니다. 초기 및 지속적인 비용은 더 높을 수 있지만 이러한 모델에는 공급업체 지원이 함께 제공되는 경우가 많아 광범위한 사내 전문 지식의 필요성이 줄어들고 잠재적으로 전체 유지 관리 및 운영 비용이 낮아집니다.
혁신과 업데이트
•
오픈 소스: 다양한 글로벌 커뮤니티의 기여 덕분에 혁신의 속도가 빨라질 수 있습니다. 기업은 기여자가 제공하는 지속적인 개선과 업데이트를 통해 이익을 얻을 수 있습니다. 그러나 혁신의 방향이 항상 기업의 특정 요구 사항과 일치하는 것은 아닙니다.
•
비공개 소스: 혁신은 공급업체에서 관리하므로 업데이트의 일관성과 고품질이 보장됩니다. 혁신의 속도는 오픈 소스 커뮤니티에 비해 느릴 수 있지만 특히 클라이언트 기반과 긴밀하게 협력하는 공급업체의 경우 더 예측 가능하고 기업 요구 사항에 부합하는 경우가 많습니다.
지원과 신뢰성
•
오픈 소스: 지원은 주로 커뮤니티, 포럼에서 제공되며 잠재적으로 전문 서비스를 제공하는 타사 공급업체에서도 제공됩니다. 풍부한 공유 지식이 있을 수 있지만 응답 시간과 도움 가용성은 다양할 수 있습니다.
•
비공개 소스: 일반적으로 고객 서비스, 기술 지원, 전담 계정 관리를 포함하여 공급업체의 전문적인 지원이 함께 제공됩니다. 이를 통해 엔터프라이즈 애플리케이션에 중요한 안정성과 빠른 문제 해결을 보장할 수 있습니다.
맞춤화 및 유연성
•
오픈 소스: 높은 수준의 사용자 정의 및 유연성을 제공하므로 기업은 특정 요구 사항에 맞게 모델을 수정할 수 있습니다. 이는 틈새 애플리케이션이나 모델을 복잡한 시스템에 통합할 때 특히 유용할 수 있습니다.
•
폐쇄 소스: 사용자 정의는 일반적으로 오픈 소스 모델에 비해 더 제한적입니다. 일부 공급업체는 사용자 정의 옵션을 제공하지만 변경 사항은 일반적으로 공급업체가 제공하는 매개변수 및 옵션으로 제한됩니다.
지적재산권과 경쟁우위
•
오픈 소스: 오픈 소스 모델을 사용하면 특히 수정 사항이 공개적으로 공유되는 경우 지적 재산(IP) 고려 사항이 복잡해질 수 있습니다. 그러나 이를 통해 기업은 개방형 기술을 기반으로 독점 솔루션을 구축할 수 있으며 잠재적으로 혁신을 통해 경쟁 우위를 제공할 수 있습니다.
•
폐쇄 소스: 폐쇄 소스 모델을 사용하면 IP 권리가 명확하게 정의되며 기업은 일반적으로 기본 기술을 소유하지 않습니다. 그러나 최첨단 독점 모델을 활용하면 독점 기술에 대한 접근을 통해 다른 유형의 경쟁 우위를 제공할 수 있습니다.
LLM 발전과정
Transformer Architecture
•
Encoder와 Decoder로 구성
◦
Encoder : 문장을 이해하는 부분
◦
Decoder : 문장을 생성하는 부분
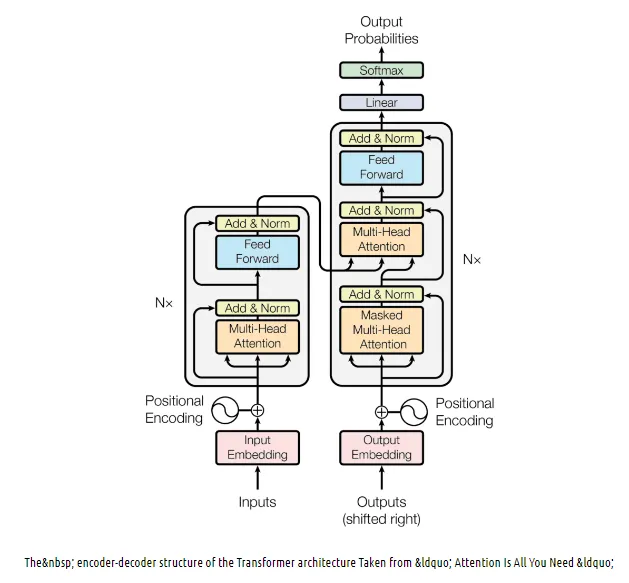
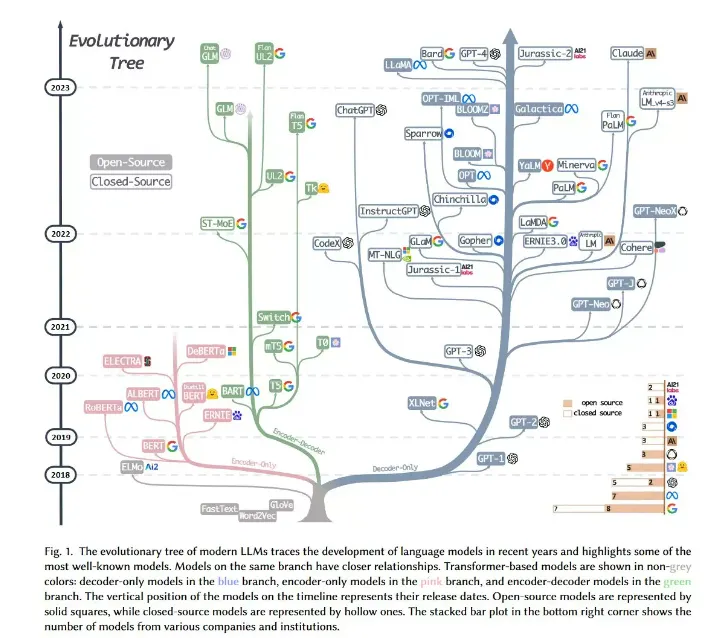
Tree of GPTs & LLMs
•
Encoder
◦
BERT가 대표 모델
•
Decoder
◦
GPT, Bard, LaMDA, LLaMA 등
•
Encoder & Decoder
◦
TS, BART가 대표 모델
•
Meta는 자체 개발한 초대형 언어 모델(LLM)인 LLaMA의 소스코드를 공개하는 방식으로 오픈소스 전략을 적극적으로 추진하고 있다.
•
이를 통해 다양한 프로젝트에서 LLaMA를 원하는 목적에 맞게 커스터마이징하여 사용할 수 있게 되었다.
•
현재까지 LLM의 소스코드를 공개하고 있는 기업은 메타가 유일하며, 이런 개방성과 투명성 덕분에 메타는 인공지능 분야의 LLM 개발 프로젝트에서 가장 주목받고 있는 빅테크 기업 중 하나로 자리매김하고 있다.
sLLM(small Large Language Model)
•
매개변수와 훈련 데이터를 늘려가며 성능을 개선해오던 기존의 ‘언어모델 초거대화’ 트렌드가 바뀌고 있다.
•
적은 매개변수와 훈련 데이터만 가지고도 최대한의 가격대비 성능을 낼 수 있는 sLLM(small Large Language Model)의 출현과 함께 언어모델이 점점 더 경량화 되고 있다.
•
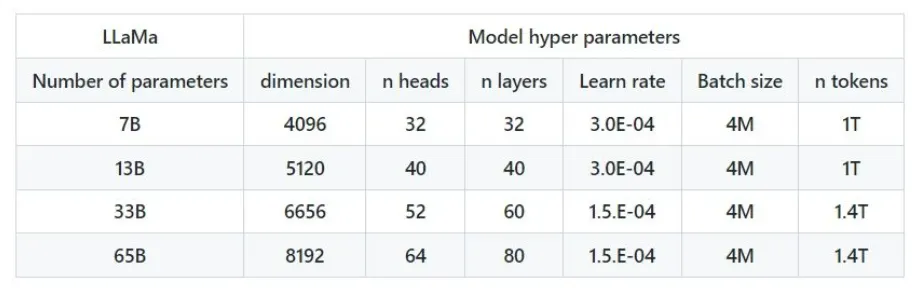
메타의 LLaMA는 70억, 130억, 330억, 650억개의 매개변수를 가지는 네 가지 모델로 구성되어 있다.
•
이 모델들은 1750억개의 매개변수를 가진 GPT-3.5와 비교했을 때 매개변수 수가 적지만, 그럼에도 불구하고 높은 성능과 모델 학습의 유연성을 자랑하며 개발자들 사이에서 인기를 끌고 있다.
LLaMA의 활용성과 유연성
•
LLaMA의 큰 장점은 모델의 크기이다.
•
이 모델은 용량이 다른 모델의 10분의 1 수준에 불과하기 때문에 고성능 GPU뿐만 아니라 다양한 엣지 디바이스, 예를 들어 스마트폰 등에서도 AI 생성을 구현할 수 있다는 점에서 매력적이다.
•
이런 특징은 특정 목적에 맞게 개발되는 소규모 초대형 언어 모델(sLLM)의 개발에도 큰 도움이 된다.
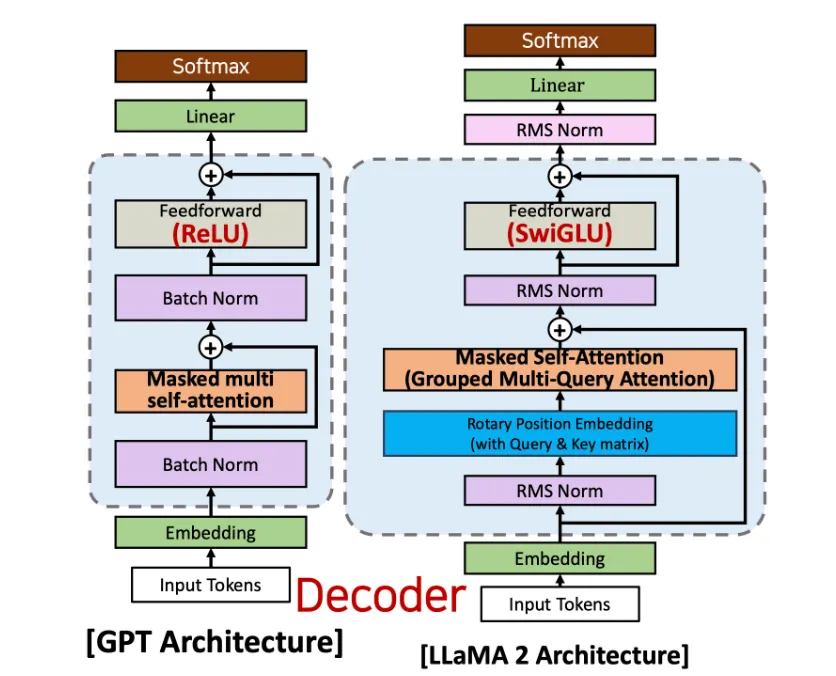
LLaMA Architecture
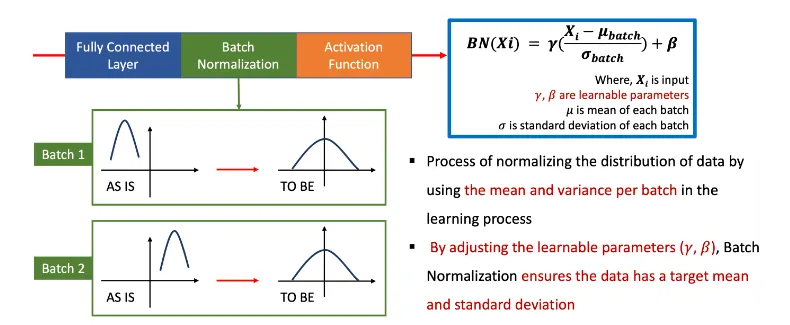
Batch Normalization
•
학습과정에서 배치당 평균과 분산을 이용하여 데이터의 분포를 정규화하는 과정
•
학습 파라미터(γ,β)를 조정함으로써 Batch Normalization(배치 정규화)는 데이터가 목표 평균(target mean) 및 표준 편차(standart deviation)를 갖도록 보장합니다
•
GPT 에서 사용
RMS(Root Mean Square) Normalization
•
RMS 정규화는 layer 내의 평균 제곱근(root mean square)을 계산하고 이 값을 사용하여 정규화한다.
•
RMS 정규화에는 배치 정규화(γ,β)와 같은 학습 가능한 파라미터가 없다.

왜 LLaMA 는 RMS 정규화를 적용하는가
•
계산 효율성
◦
RMS 정규화에서는 입력의 합의 제곱근(square root of the sum of the input)만 계산하면 되지만, 배치 정규화에서는 입력의 평균과 분산(mean and variance of the input)을 계산해야 한다.
◦
RMS 정규화는 배치 정규화보다 훨씬 빠르고 계산 비용이 적게 든다.
•
안정성
◦
배치 정규화(Batch Normalization)는 매우 크거나 매우 작은 숫자를 다룰 때 수치 불안정으로 인해 어려움을 겪을 수 있습니다
▪
그래서 감마와 베타의 파라미터를 도입한 것이다
◦
RMS Normalization은 이 문제를 덜 발생시킵니다
▪
RMS 는 투트를 씌우고 n으로 나눠주고 그것을 실제 입력 값에다가도 나눠주기 떄문에 안정적이다
•
비선형성
◦
RMS 정규화는 모델에 비선형성을 제공하여 데이터에서 더 복잡한 패턴을 포착할 수 있습니다
◦
배치 정규화는 이러한 패턴을 효과적으로 포착하지 못할 수 있는 선형 변환입니다
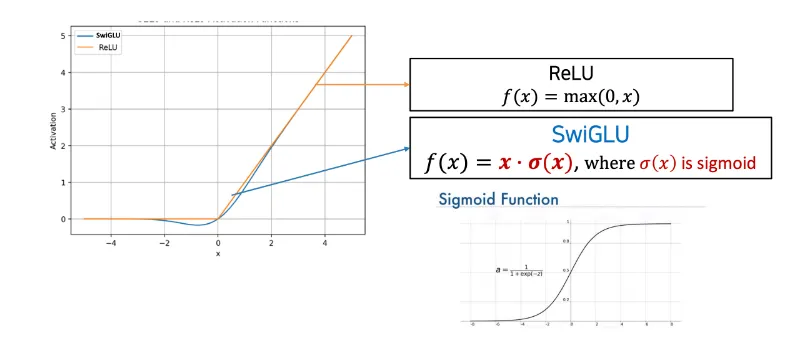
SwiGLU Activation Function
•
SwiGLU는 시그모이드 컴포넌트를 사용하여 음수 입력에 대해 원활한 transition을 제공한다.
◦
그러나, SwiGLU는 ReLU에 비해 시그모이드 컴포넌트로 인해 계산적으로 더 비싸다.
•
활성화 함수을 SwiGLU로 변경하여 LlaMA의 성능을 향상시킬 수 있었다.
수식
•
SwiGLU : 인풋에다가 시그모이드를 곱해줌
◦
(-) 값을 잃어버리는 단점을 해결한다.
•
non linear 의 장점도 있다 (좀 더 많은 패턴을 반영할 수 있다)
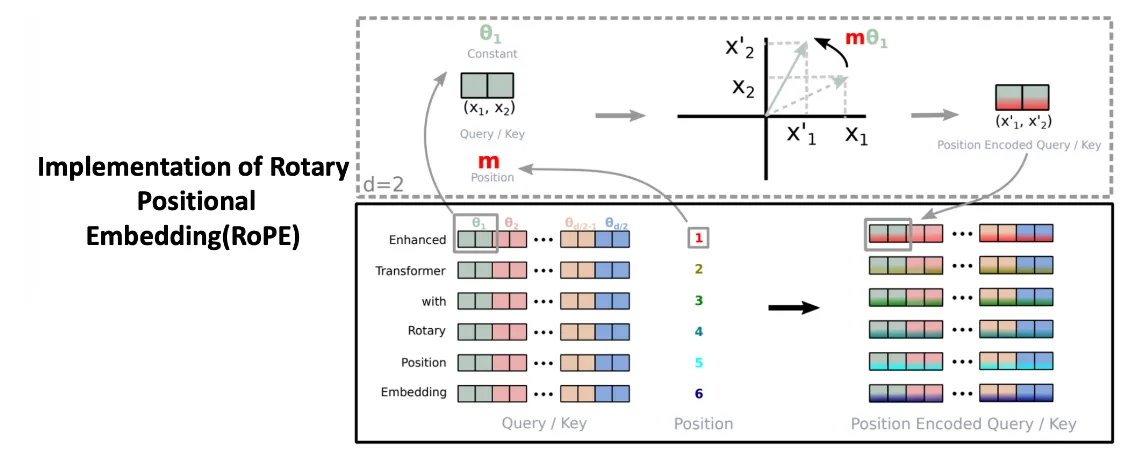
Rotary Positional Embedding (RoPE)
•
RoPE는 Relative Position Embedding based method 이며, 가산법(Additive method)이 아니라 곱셈법(Multiplicative method) + sinusoid method(Absolute Position을 사전에 주입)이다.
•
Attention Layer 에서 Query와 Key의 Inner product를 수행할 때, rotation matrix를 곱하여 위치 정보(postional information) 반영
◦
Query 와 Key 에 대해서만 Rotary Positional Embedding을 적용하는 것이다.
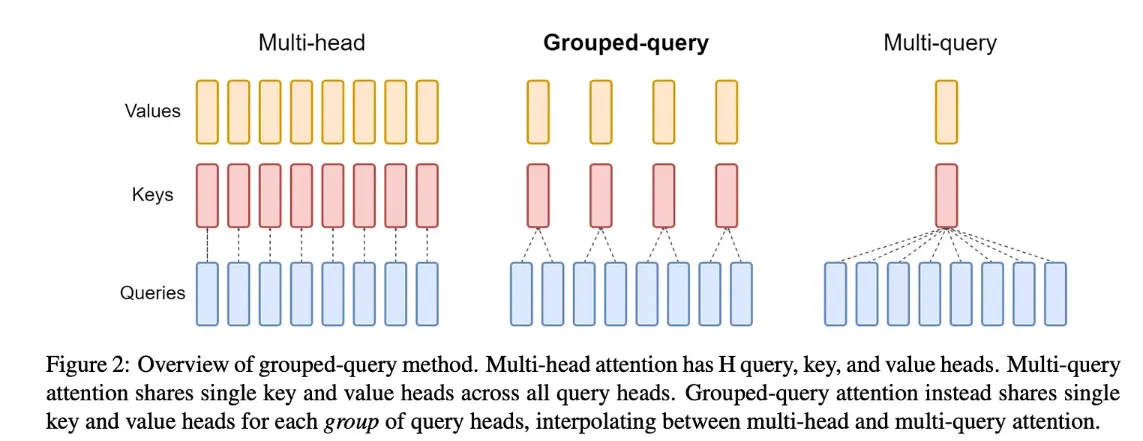
Grouped Query Attention (GQA)
•
Multi-head Attention(MHA)은 H(어텐션 헤드 개수)개의 QKV(Query, Key, Value)를 가진다.
◦
각각의 KV 텐서를 로드하기 위해서는 많은 메모리가 필요하다.
•
Multi-query Attention(MQA)은 H개의 Q(Query)와 1개의 KV(Key, Value)를 가진다.
◦
Multi-head Attention에 비해 모델의 성능을 저하시키고 모델의 학습을 불안정하게 만들 수 있다.
•
Grouped-query attention(GQA)은 하나의 key로 계산, 하나의 value로 계산하여 컴퓨팅 타임을 줄이는 대안
◦
Multi-query Attention같이 KV 헤드들의 숫자(K와 V에 대응하는 헤드개수)를 하나로 줄이는 것 대신, G개 만큼의 그룹을 짜서 축소하는 함으로써 불안정한 학습 해결
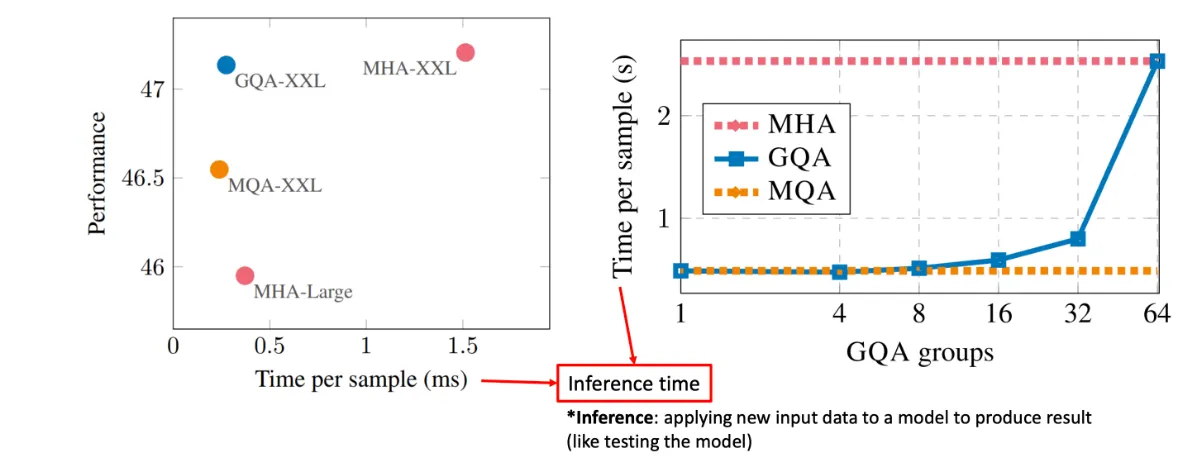
샘플당 컴퓨팅 비교
•
GQA는 Multi-query Attention 만큼 빠르며 성능은 Multi-head Attention과 비슷하다.
•
GQA, MHA, MQA 비교
◦
그룹의 개수를 증가시키면서 시가닝 점점 올라가면서 64개 올리니까 확 올라감
◦
모든 각각의 MHA 는 가장 많은 시간이 소요됨
•
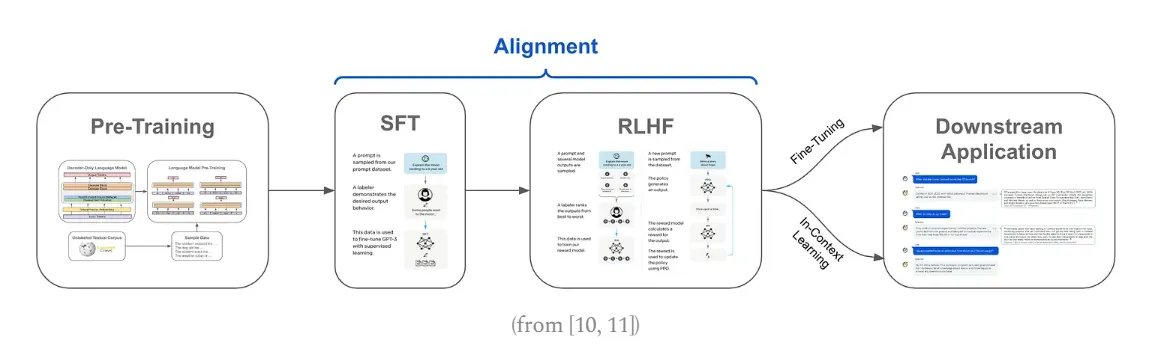
Inference : 새로운 입력 데이터를 모델에 적용하여 결과를 산출합니다
•
Unsupervised Learning (Pre-training)
◦
사전 학습을 통해서 대형 생성 모델(PLM)을 만듭니다. 대형 생성 모델은 길들여지지 않은 괴물과 같이 거대하고 강력하지만 사람이 원하는 의도대로 동작하기 어려운 경우가 많기 때문에 서비스에 바로 적용하기에는 어렵습니다.
•
Supervised Fine-Tuning (SFT)
◦
특정 도메인의 데이터 혹은 크라우드 소싱 등을 통해 구축한 양질의 (Prompt, Response) 데이터를 구축하여 fine-tuning하는 과정입니다. 이를 통해 입력 프롬프트에 대해 사람의 의도에 맞는 문장을 생성하는 방법을 학습합니다.
•
Reinforcement Learning from Human Feedback (RLHF)
◦
SFT 모델에 추가적으로 강화 학습을 적용하여 사람의 의도에 맞게 파인튜닝을 하는 과정입니다.