



•
마이크로소프트에서 개발한 오픈 소스 딥러닝 최적화 라이브러리
•
이 라이브러리는 대규모 모델, 특히 자연어 처리(NLP)를 위한 대규모 언어 모델 학습의 효율성과 속도를 대폭 개선시킨다.
•
모델 학습을 더 빠르고 비용 효율적으로 만들기 위해 설계되었으며, 이를 통해 개발자와 연구자들은 기존 하드웨어에서도 매우 큰 모델을 효율적으로 학습할 수 있다.
•
고유한 효율성 및 효율성 이점을 활용하여 PyTorch 모델에 대한 몇 줄의 코드 변경만으로 속도와 확장성을 높일 수 있다.

Model Scale
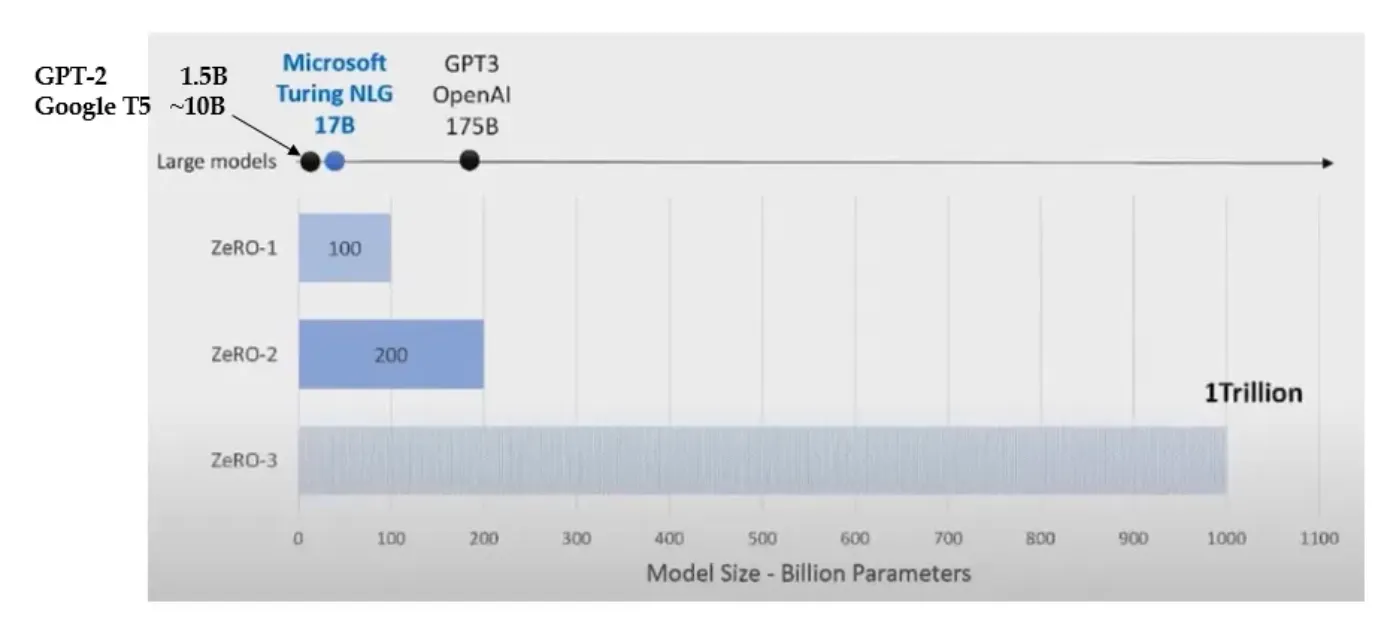
모델 분할: DeepSpeed는 모델 분할을 통해 단일 GPU 메모리 한계를 넘어서는 매우 큰 모델을 학습할 수 있도록 지원합니다.
•
ZeRO-1은 100B 모델까지 학습가능하며, ZeRO-2는 200B 모델까지 학습 가능하다.
•
ZeRO-3(ZeRO-Offload)는 V100당 13B 파라미터를 학습할 수 있다.
Speed
효율적인 데이터 병렬 처리: GPU에서의 데이터 병렬 처리를 최적화하여, 학습 속도를 개선한다.
•
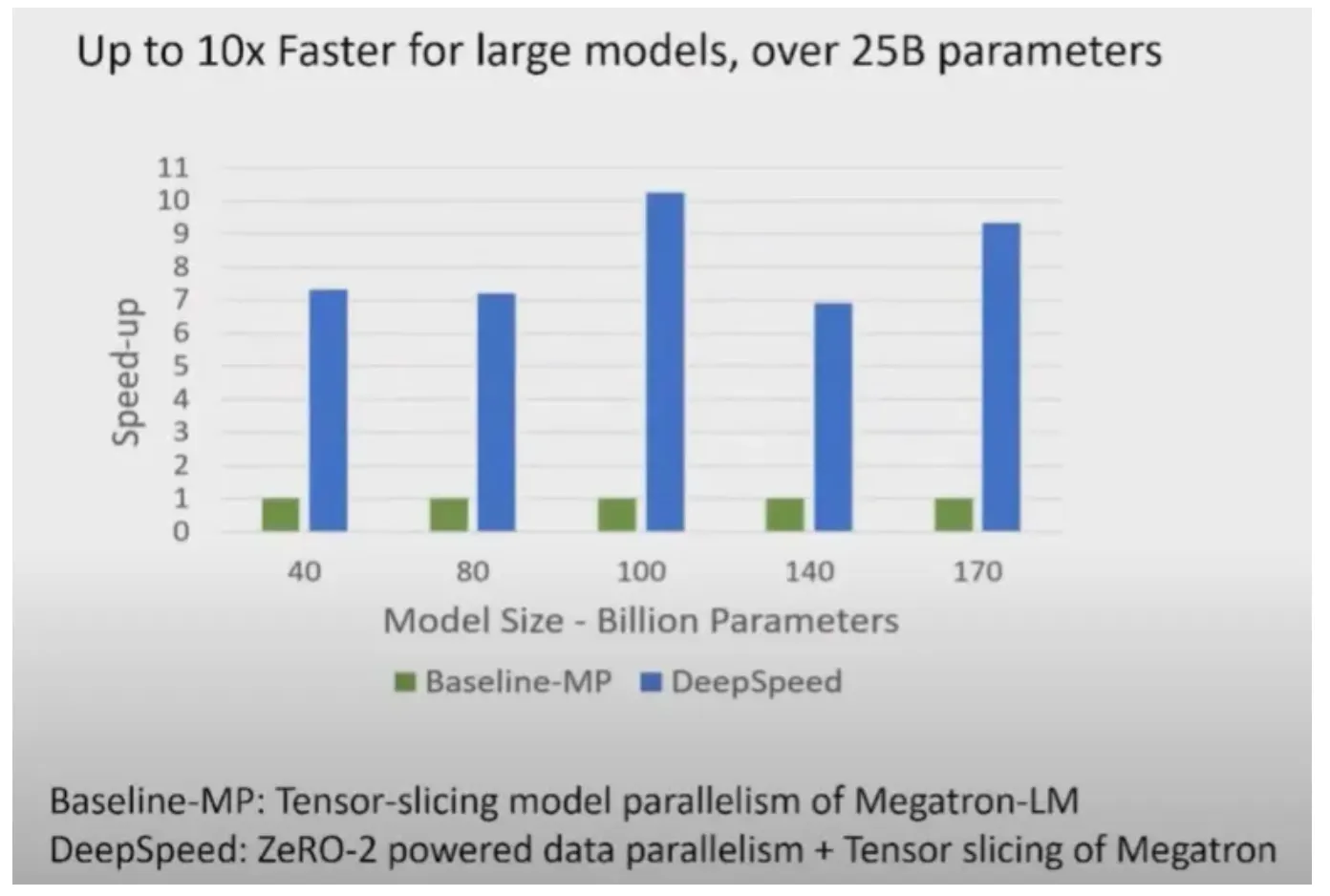
Megatron-LM은 tensor-slicing model parallelism를 사용한다.
•
Megatron-LM의 tensor-slicing model parallelism에 DeepSpeed ZeRO-2의 data parallelism을 추가하면 DeepSpeed가 Megatron-LM보다 10x 더 빠르다.
Scalability
모델 학습 가속: 커널 최적화와 효율적인 커뮤니케이션을 통해 모델 학습 속도를 높힌다.
•
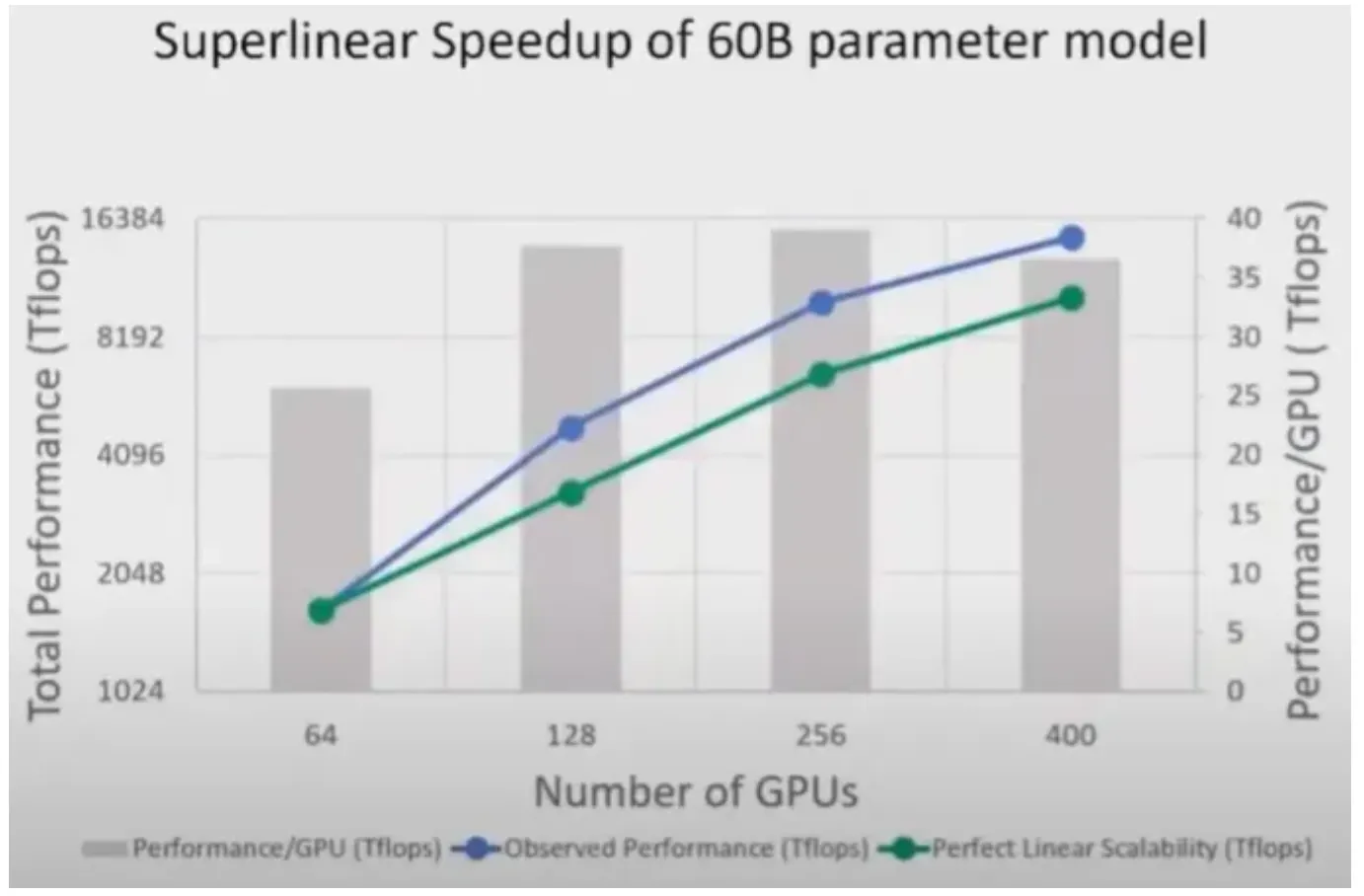
디바이스 개수의 증가에 따라 super-linear speed-up을 달성할 수 있다.
•
녹색 그래프는 perfect linear scalability로 실제로 디바이스 개수에 따른 산술적인 성능이라면, DeepSpeed를 사용하면 perfect linear scalability보다 더 높은 성능을 보인다.
Usability
ZeRO 최적화: ZeRO(ZeRO-Redundancy Optimizer) 기술을 사용해 메모리 사용량을 줄이면서 대규모 모델의 학습을 가능하게 한다.
•
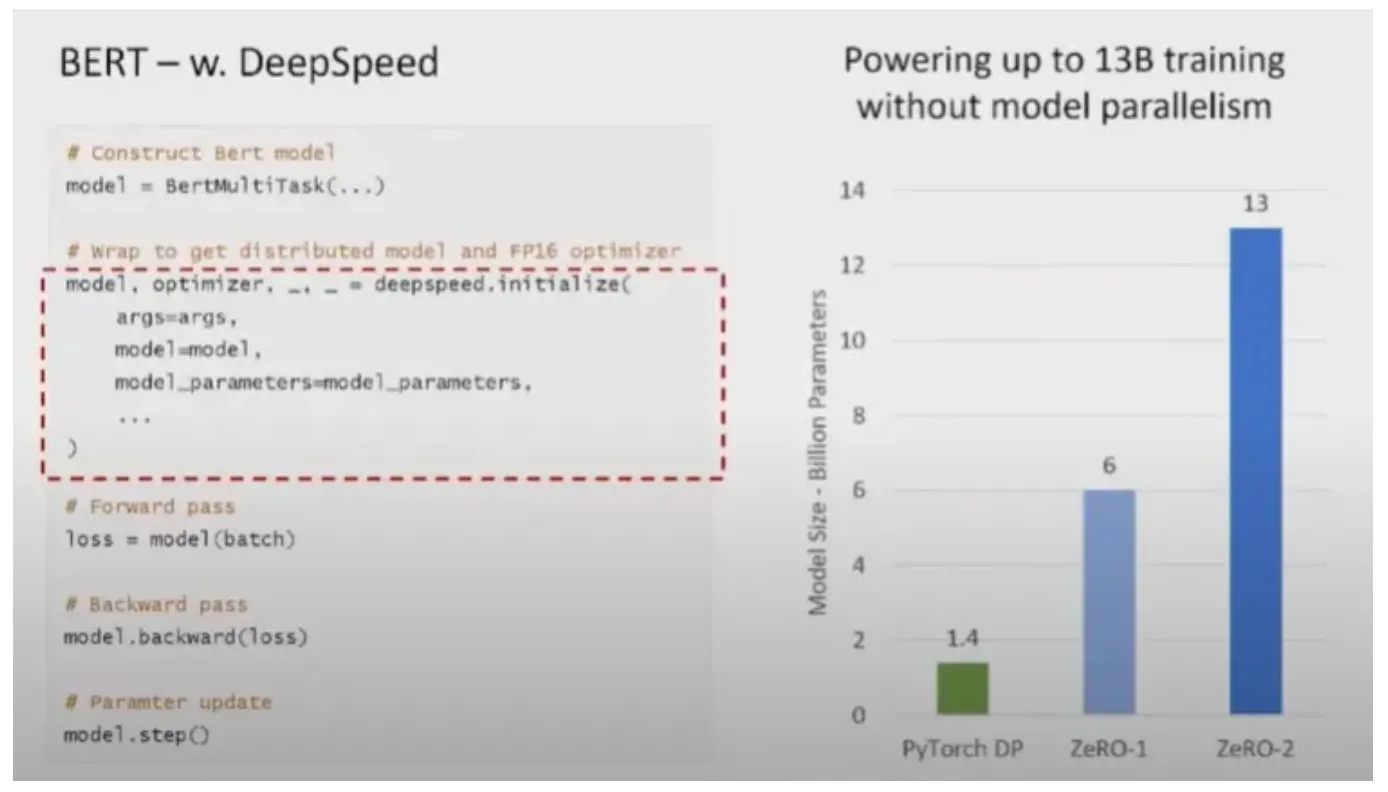
DeepSpeed는 Pytorch 기반이며 몇 줄의 코드를 추가하면 DeepSpeed를 사용가능하다.
•
또한 1.4B 파라미터 이상의 Pytorch기반 모델은 Data Parallelism만을 사용할 때 OOM이 발생하지만 ZeRO-2는 13B까지 Model parallelism 없이 Data Parallelism을 사용할 수 있다.
DeepSpeed의 ZeRO(Zero Redundancy Optimizer)
•
기존의 딥러닝 모델의 분산 학습(DDP)에서는 모든 GPU가 모델을 가지고 있어야 했기 때문에 모델을 학습시키기 위한 값(Optimizer State, Gradient, Parameter)을 GPU마다 복제해서 가지고 있어야 했다.
•
GPT-2 모델은 3GB 정도의 메모리를 차지하지만 32GB GPU에서 학습이 안되는 것이 이러한 낭비 문제 때문이었다.
•
ZeRO는 이러한 모델(파라미터) 복제로 인한 낭비를 해결한다.
아래는 BERT training 결과
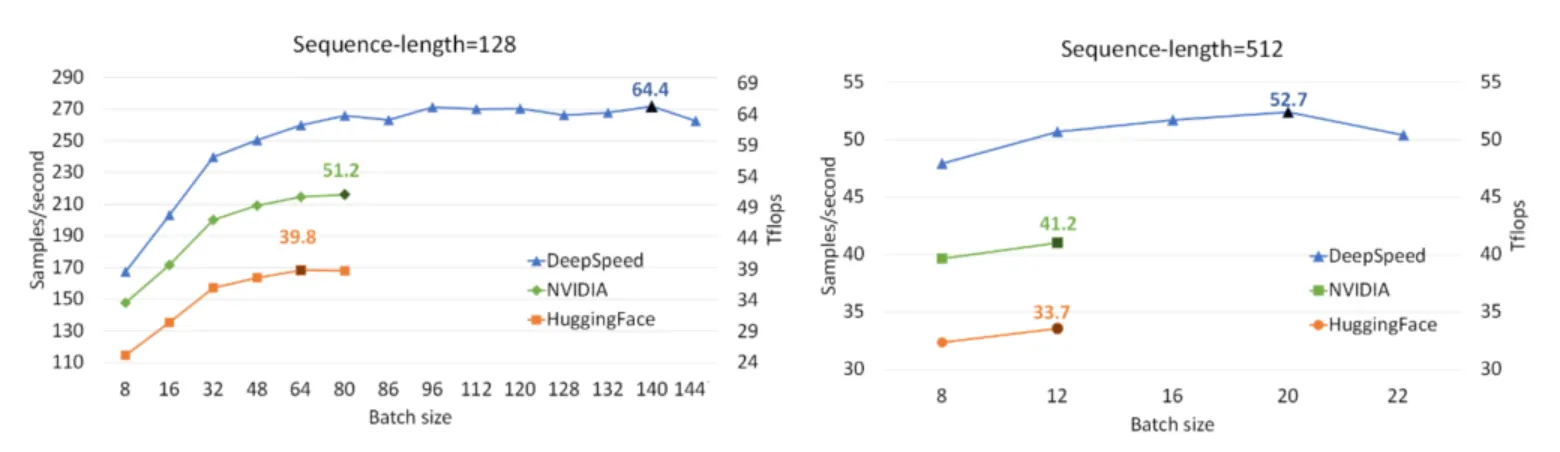
ZeRO
•
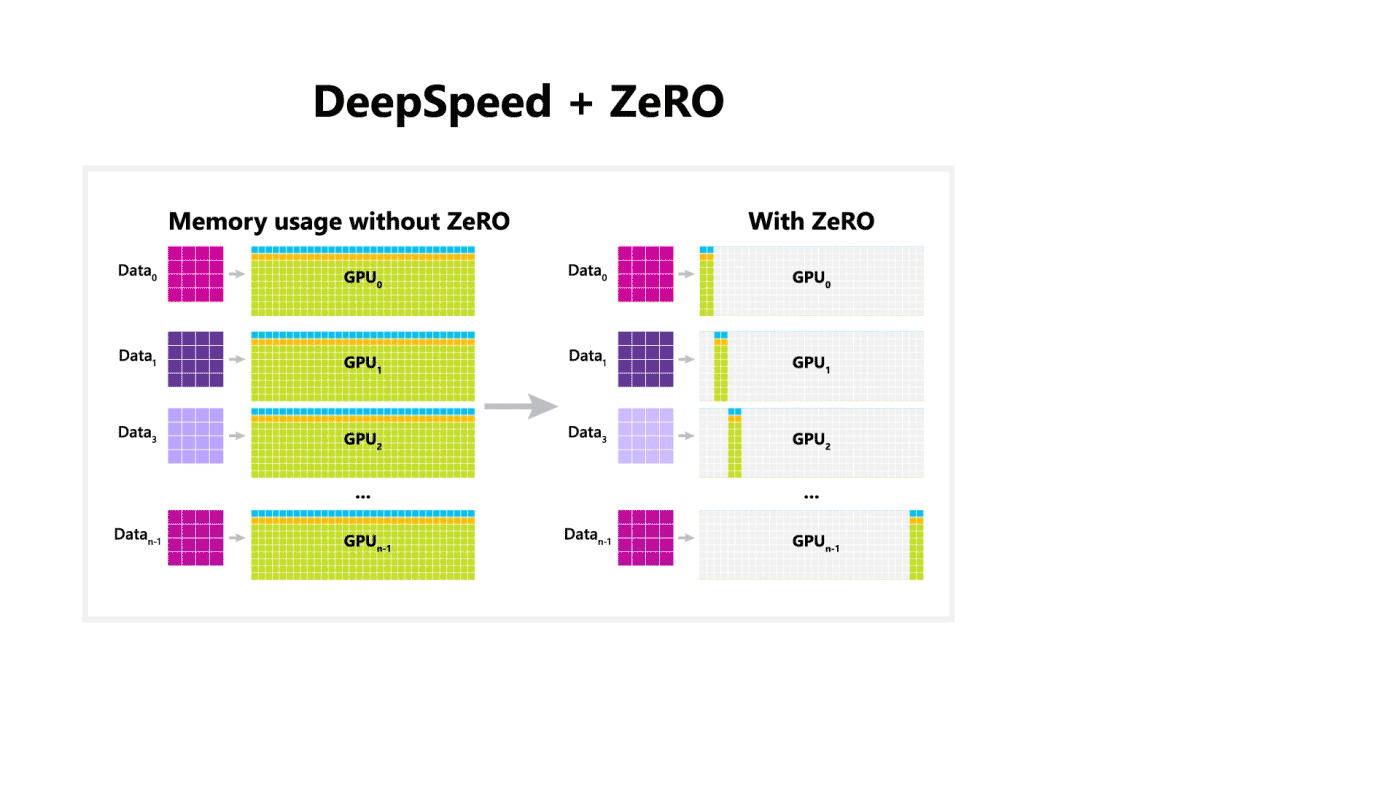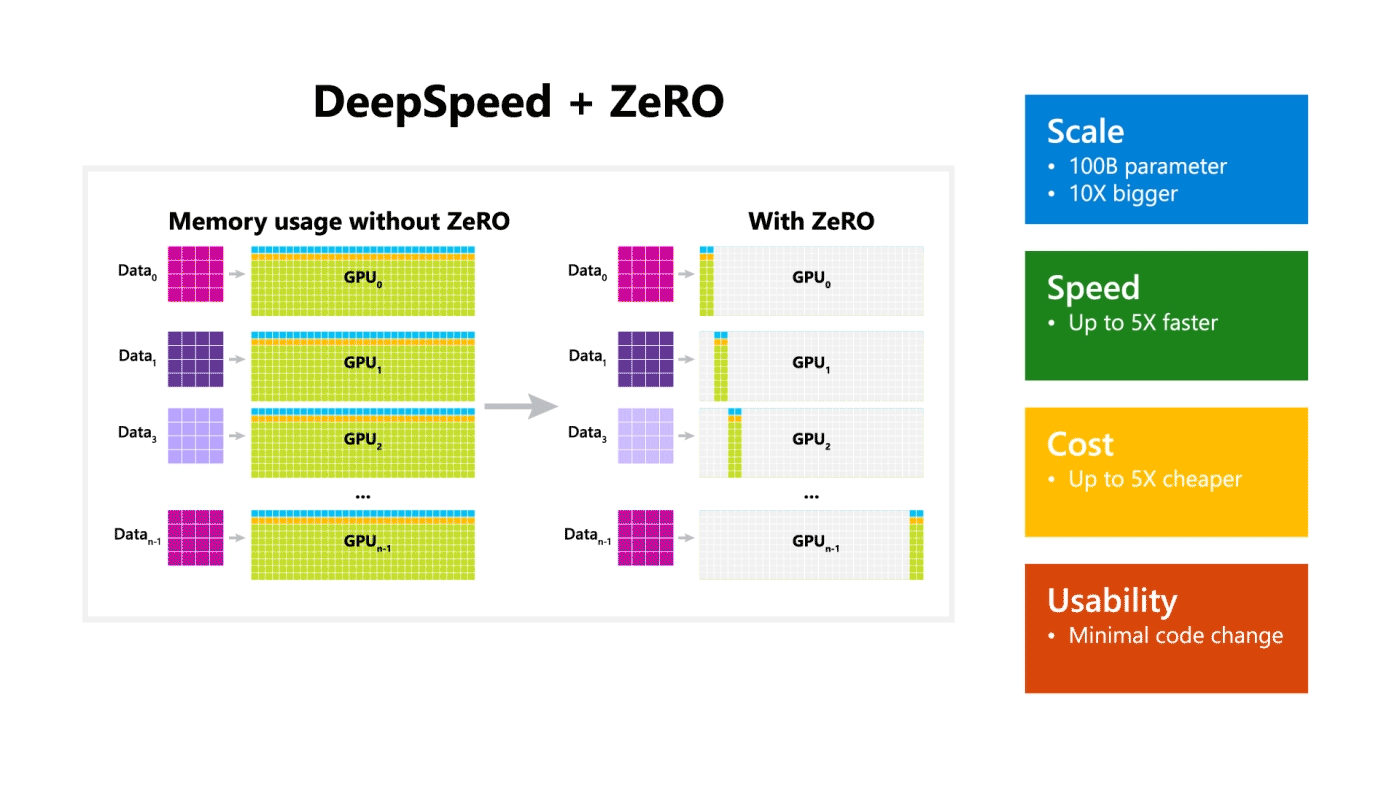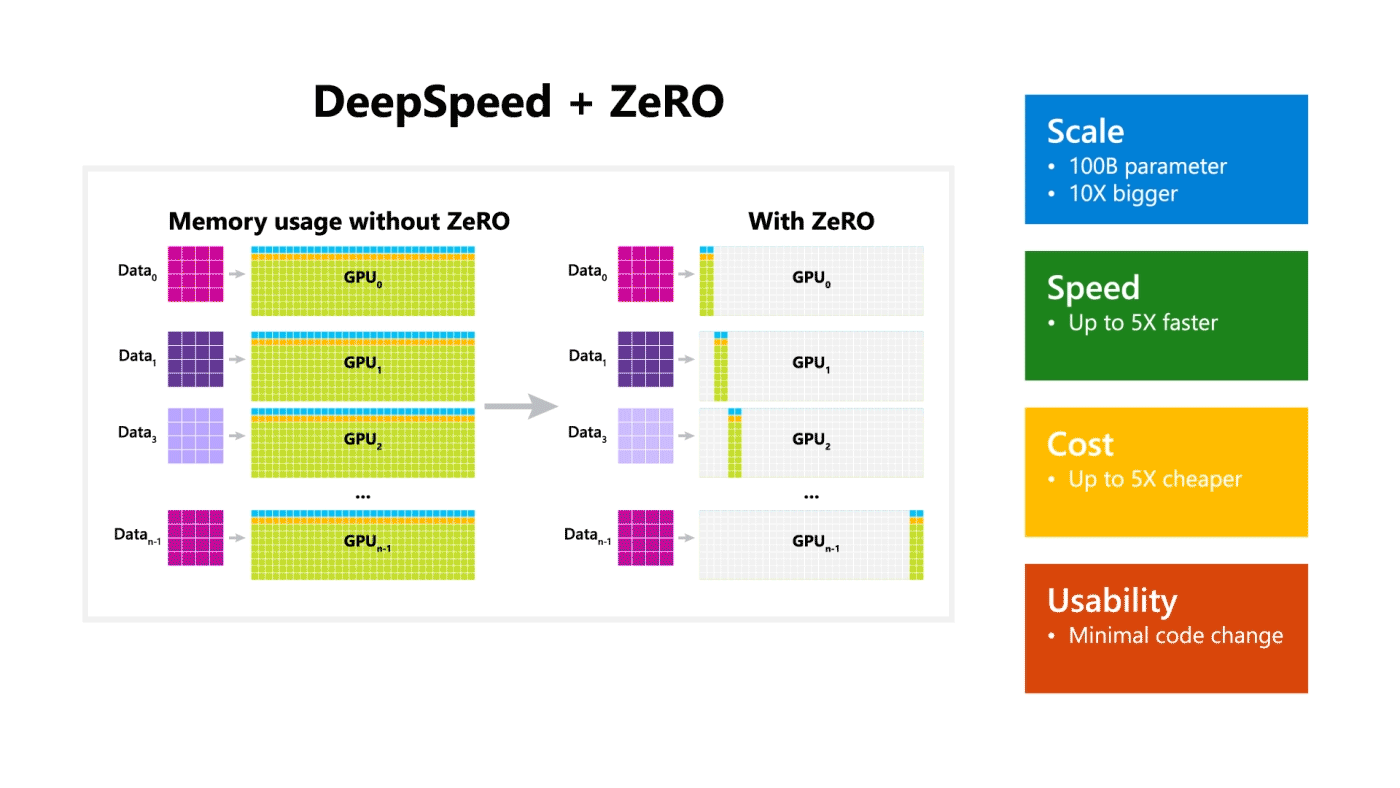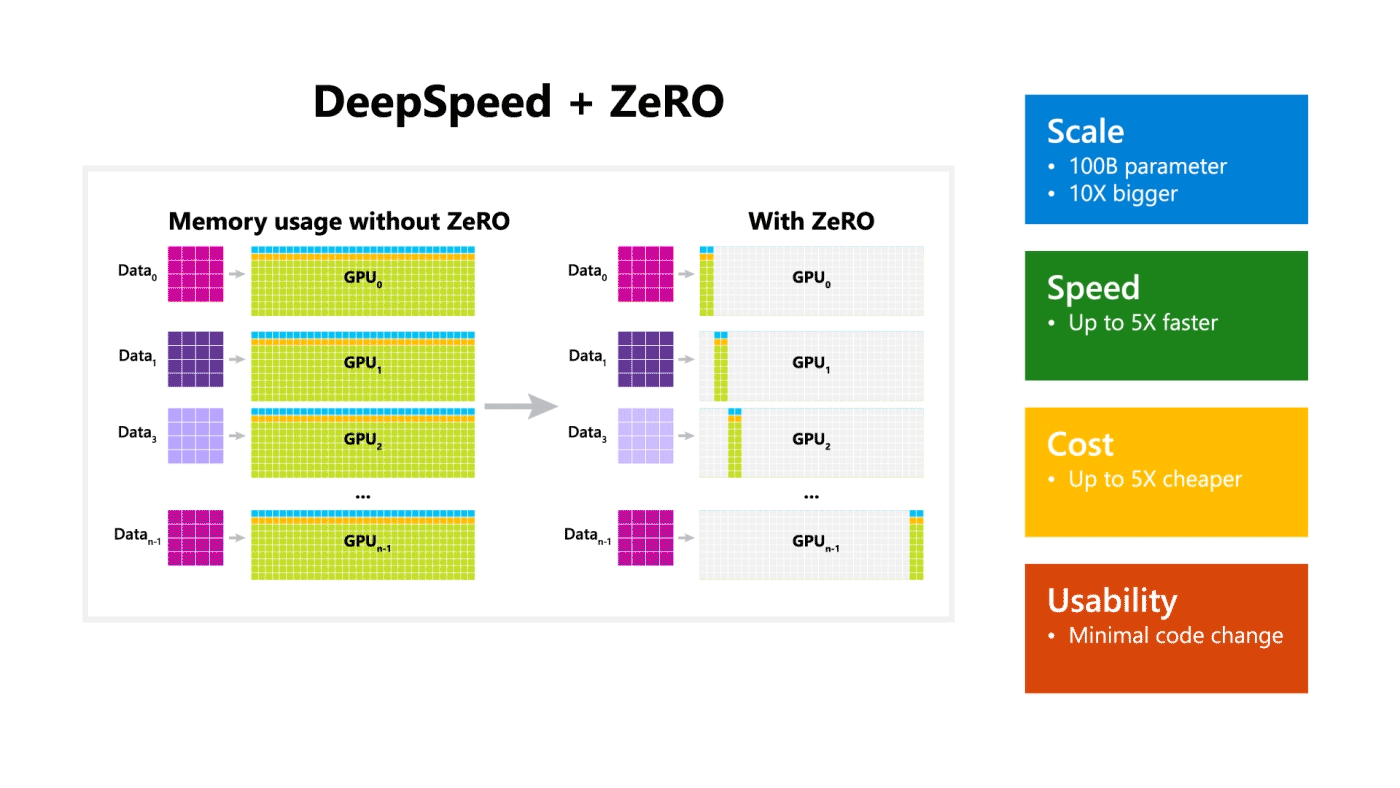
기존 딥러닝 모델의 분산 학습에서는 데이터는 분산되지만 모델을 학습시키기 위한 값(Optimizer State, Gradient, Paramter)은 각 GPU마다 복제해서 가지고 있어야 했다.
아래 그림의 Baseline을 참고
•
MS에서는 약 1.5억 개의 파라미터로 구성된 GPT-2 모델은 3GB 정도의 메모리를 차지함에도 불구하고, 32GB GPU에서도 학습이 불가능하다는 것에서 의문을 가지고 상세 분석을 진행한 결과 나머지 메모리는 복제된 파라미터에 의해서 낭비된다는 점을 알아냈다.
•
따라서 ZeRO는 분산 학습 과정에서의 불필요한 메모리의 중복을 제거하여 같은 환경 내에서 대용량의 모델을 학습을 가능하도록 한다.
•
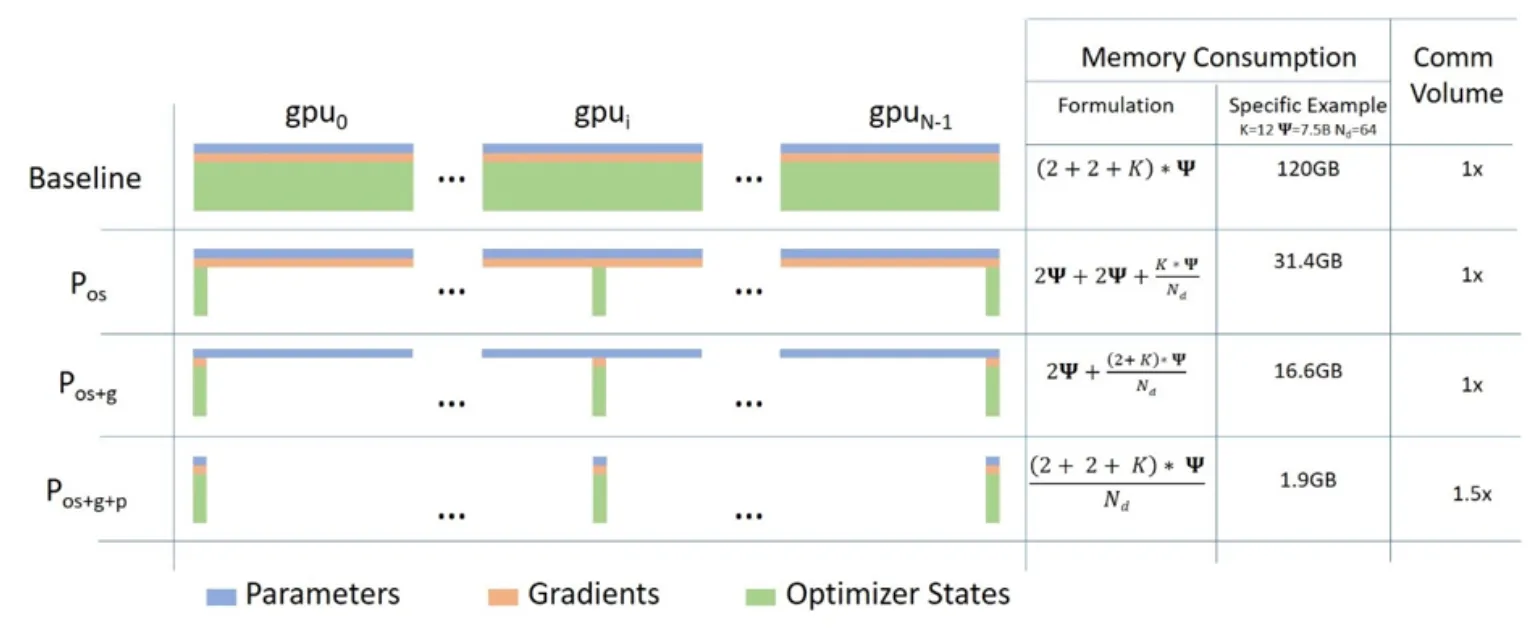
3가지 주요 최적화 단계
◦
Stage 1. Optimizer State Partitioning(): 메모리 4배 감소
◦
Stage 2. Add Gradient Partitioning(): 메모리 8배 감소
◦
Stage 3. Add Parameter Partitioning(): GPU의 개수와 메모리 감소 정도는 비례.(예를 들어, 64개의 GPU를 사용한다면 메모리 64배 감소)
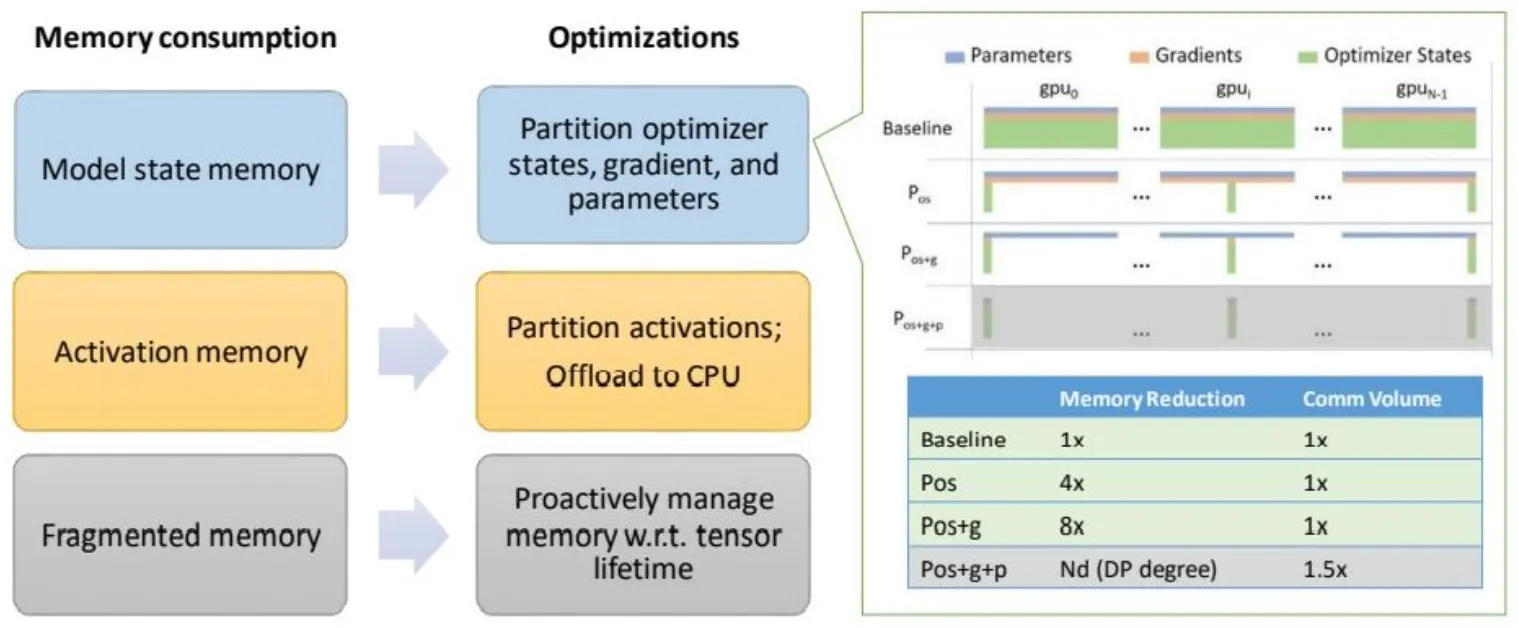
ZeRO-2
•
ZeRO-2는 기존 ZeRO-1에서 Optimizer Stage Partitioning 외에도 gradient, activation memory, fragmented memory의 메모리 공간을 줄이는 새로운 기술을 도입하여 메모리 최적화 범위를 확장
Model state memory
•
ZeRO-2는 첫 번째 단계() 외에도 두 번째 단계인 partitioning gradients()를 지원함으로써 GPU 당 메모리 소비를 2배 더 줄인다.
•
이는 기존 데이터 병렬 처리와 비교하면 동일한 통신 볼륨으로 최대 8배의 메모리를 절약한다.
Activation memory
•
activation partitioning을 통해 기존 모델 병렬화 방식에서 activation memory의 복제를 제거하는 기술을 도입한다.
•
또한, 상황에 따라서 activation memory를 CPU로 보냅니다.(모델 사이즈가 매우 크거나, 메모리가 극도로 제한된 경우)
Fragmented memory
•
다양한 tensor의 수명 주기로 인해서 학습 중에 메모리 단편화가 발생한다는 것을 발견했다.
•
이로 인해 사용 가능한 메모리가 충분하더라도 메모리 할당에 실패할 때가 있기 때문에, ZeRO-2에서는 텐서의 서로 다른 수명을 기반으로 메모리를 관리하여 메모리 단편화를 방지한다.
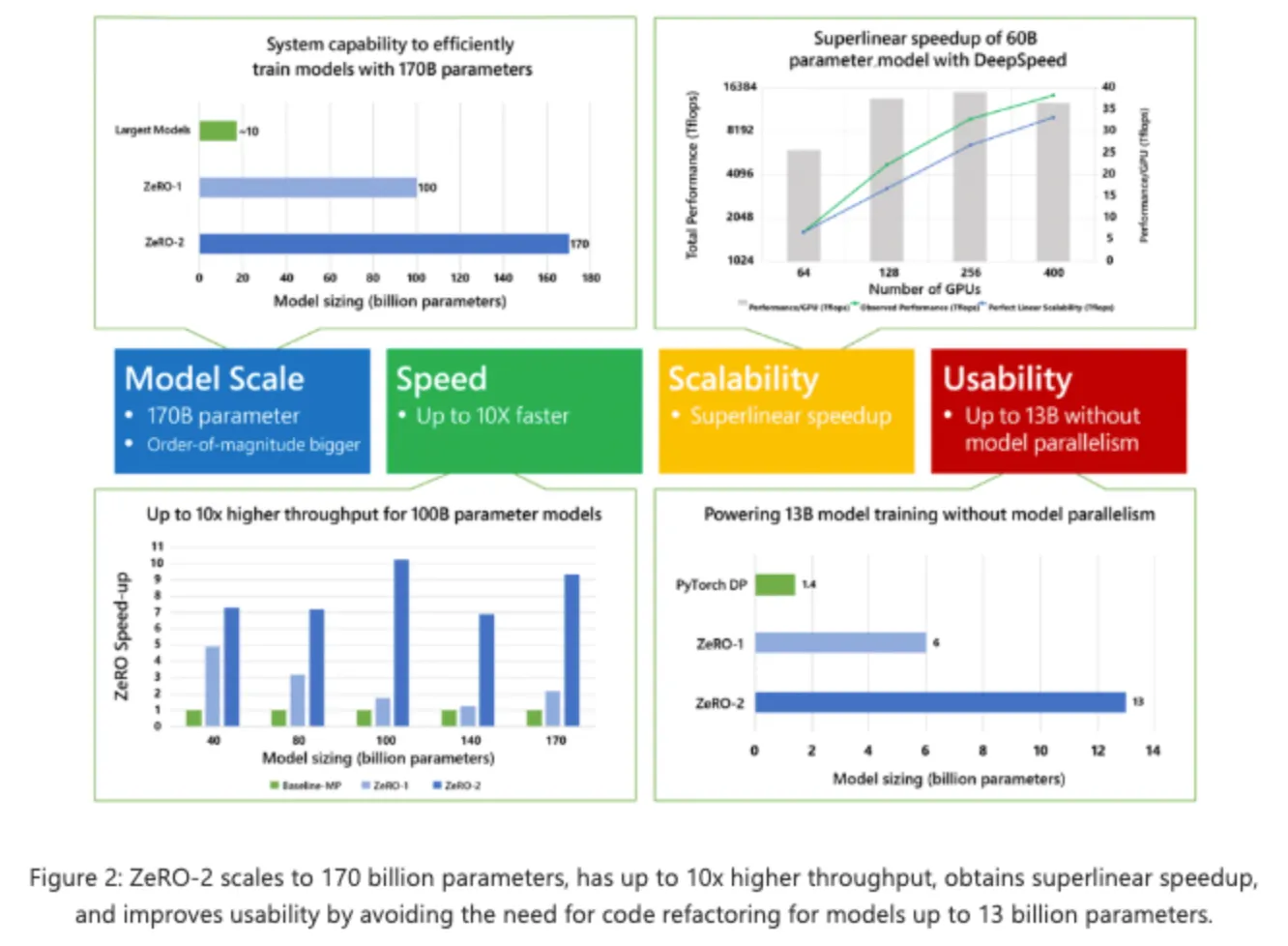
ZeRO-1 vs ZeRO-2
•
ZeRO-2는 4가지 측면에서 탁월(크기, 속도, 확장성 및 사용성)하다.
•
더 큰 규모의 모델을 지원하고 최대 10배 빠른 학습 속도, 확장성과 향상된 사용성을 통해 대규모 모델 학습을 가능하게 한다.
ZeRO-3
•
ZeRO-Offload라고 불리우는 ZeRO-3는 gradients, optimizer states를 CPU 메모리로 *offloading하고 optimizer 연산을 CPU로 offloading한다.
offloading : 컴퓨팅 자원 및 계산 속도의 한계를 극복하기 위해 로컬 컴퓨터에서 수행하는 어플리케이션의 일부를 컴퓨팅 자원과 처리능력이 우수한 원격지 컴퓨터에 전달하여 처리한 후 결과를 반환받는 방식
•
Parameters와 forward & backward 연산은 GPU에서 유지한다.
CPU 연산 제약
•
CPU 연산 throughput은 GPU 연산 throughput이 훨씬 느리기 때문에 CPU에 compute-intensive 연산을 offloading하는 것을 피해야 한다.
•
ZeRO-Offload는 optimizer 연산 및 weight updates를 CPU가 수행한다.
•
M: Model Size, B:Batch size
◦
Compute Complexity of DL training per iteration: O(MB) → GPU
◦
Norm calculations, weight updates: O(M) → CPU으로 offload
메모리 절감 최대화
•
GPU: FWD-BWD, parameter (FP16)
•
CPU: gradient (FP16)과 optimizer states(Super Node: parameter FP32, momentum FP32, variance FP32)를 CPU로 offload한다.
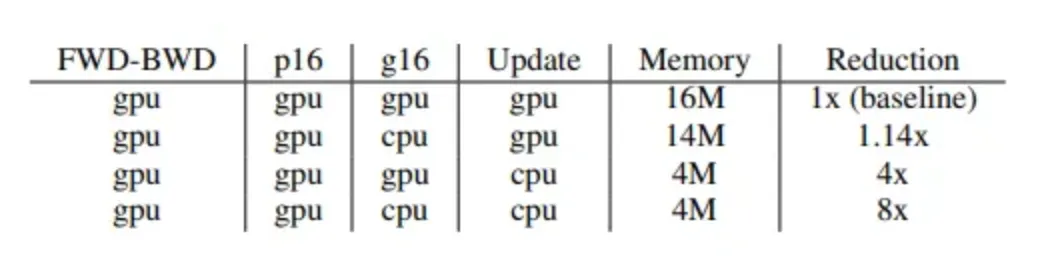
ZeRO-Offload 스케줄링
ZeRO-Offload의 Single GPU 스케줄링 전략은 다음과 같다.
•
GPU에서 연산된 gradient FP16를 GPU 에서 CPU Memory로 전달함 (Transferring이 backward propagation과 함께 중첩되어 comm. cost가 숨겨지는 것이 가능함)
•
CPU는 optimizer 연산을 실행하며 parameter FP32를 업데이트함
•
CPU가 업데이트한 parameter는 FP32 → FP16 변환 후 GPU로 복사됨
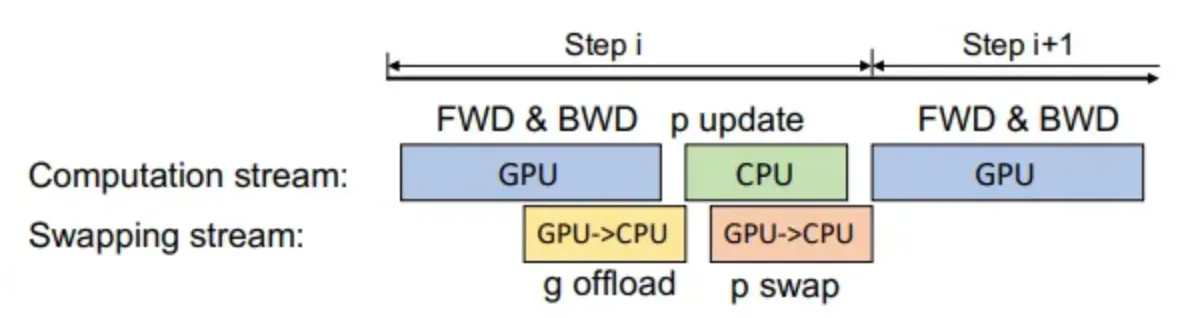
최적화된 CPU 실행
•
Adam optimizer를 CPU에 최적화하기 위해
1.
SIMD vector instruction
2.
Loop unrolling
3.
OMP Multithreading
를 개선하여 SOTA pytorch 구현에 비해 더 빠른 Adam optimizer를 구현하였다.
•
또한 One-Step Delayed Parameter Update(DPU)를 구현하였다.
•
CPU 연산은 다음과 같은 경우 병목 현상이 발생할 수 있다.
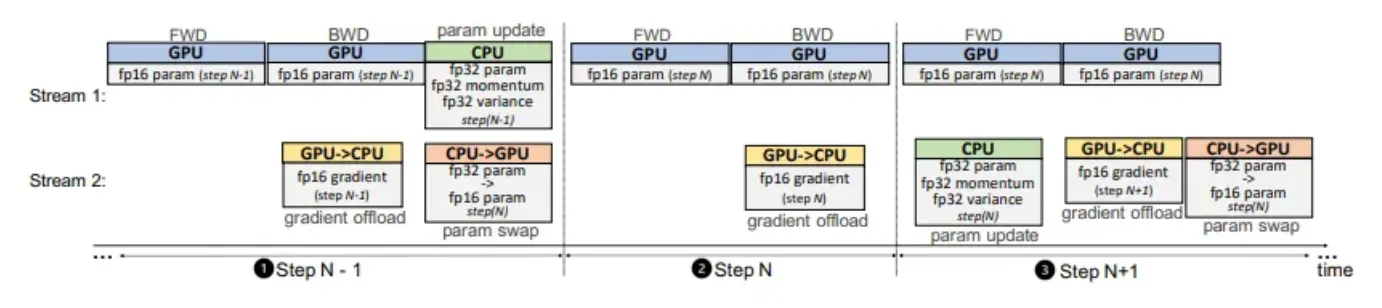
1.
Step N-1: 불안정한 학습을 피하기 위해 DPU 없이 학습함
2.
Step N: GPU → CPU로 gradient FP16를 복사. CPU는 parameter 업데이트를 하지 않고 skip함
3.
Step N+1: GPU가 forward 연산 시 CPU는 Step N으로부터 확보된 gradient FP16을 이용하여 optimizer 연산과 parameter를 업데이트함.
예제 - CIFAR-10 Tutorial
Install
import argparse
import deepspeed
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from deepspeed.accelerator import get_accelerator
from deepspeed.moe.utils import split_params_into_different_moe_groups_for_optimizer
Python
복사
CIFAR-10
•
이 튜토리얼에서는 CIFAR10 데이터셋을 사용.
•
데이터 분류:
◦
비행기(airplane), 자동차(automobile), 새(bird), 고양이(cat), 사슴(deer), 개(dog), 개구리(frog), 말(horse), 배(ship), 트럭(truck)
•
CIFAR10에 포함된 이미지의 크기: 3x32x32
→ 이는 32x32 픽셀 크기의 이미지가 3개 채널(channel)의 색상으로 이뤄져 있다는 것을 뜻함.
주요 기능
•
CIFAR-10 데이터 세트는 60,000개의 이미지로 구성되어 있으며, 10개의 클래스로 나뉜다.
•
각 클래스에는 교육용 이미지 5,000개와 테스트용 이미지 1,000개로 나뉜 6,000개의 이미지가 포함되어 있다.
•
이미지는 컬러이며 크기는 32x32픽셀
•
10가지 클래스는 비행기, 자동차, 새, 고양이, 사슴, 개, 개구리, 말, 배, 트럭을 상징
•
CIFAR-10은 일반적으로 머신러닝 및 컴퓨터 비전 분야의 교육 및 테스트에 사용
데이터 세트 구조
•
CIFAR-10 데이터 세트는 두 개의 하위 집합으로 나뉩니다:
•
훈련 세트: 이 하위 집합에는 머신러닝 모델 학습에 사용되는 50,000개의 이미지가 포함됨.
•
테스트 세트: 이 하위 집합은 학습된 모델을 테스트하고 벤치마킹하는 데 사용되는 10,000개의 이미지로 구성
Deepspeed - Argument ParsingPermalink
•
딥스피드를 적용하기 위한 첫 번째 단계는 딥스피드를 사용하여 CIFAR-10 모델에 딥스피드 인수를 추가하는 것이다.
•
add_config_arguments() 함수를 아래와 같이 추가한다.
# Include DeepSpeed configuration arguments.
parser = deepspeed.add_config_arguments(parser)
Python
복사
def add_argument():
parser = argparse.ArgumentParser(description="CIFAR")
# For train.
parser.add_argument(
"-e",
"--epochs",
default=30,
type=int,
help="number of total epochs (default: 30)",
)
parser.add_argument(
"--local_rank",
type=int,
default=-1,
help="local rank passed from distributed launcher",
)
parser.add_argument(
"--log-interval",
type=int,
default=2000,
help="output logging information at a given interval",
)
# For mixed precision training.
parser.add_argument(
"--dtype",
default="fp16",
type=str,
choices=["bf16", "fp16", "fp32"],
help="Datatype used for training",
)
# For ZeRO Optimization.
parser.add_argument(
"--stage",
default=0,
type=int,
choices=[0, 1, 2, 3],
help="Datatype used for training",
)
# For MoE (Mixture of Experts).
parser.add_argument(
"--moe",
default=False,
action="store_true",
help="use deepspeed mixture of experts (moe)",
)
parser.add_argument(
"--ep-world-size", default=1, type=int, help="(moe) expert parallel world size"
)
parser.add_argument(
"--num-experts",
type=int,
nargs="+",
default=[
1,
],
help="number of experts list, MoE related.",
)
parser.add_argument(
"--mlp-type",
type=str,
default="standard",
help="Only applicable when num-experts > 1, accepts [standard, residual]",
)
parser.add_argument(
"--top-k", default=1, type=int, help="(moe) gating top 1 and 2 supported"
)
parser.add_argument(
"--min-capacity",
default=0,
type=int,
help="(moe) minimum capacity of an expert regardless of the capacity_factor",
)
parser.add_argument(
"--noisy-gate-policy",
default=None,
type=str,
help="(moe) noisy gating (only supported with top-1). Valid values are None, RSample, and Jitter",
)
parser.add_argument(
"--moe-param-group",
default=False,
action="store_true",
help="(moe) create separate moe param groups, required when using ZeRO w. MoE",
)
# Include DeepSpeed configuration arguments.
parser = deepspeed.add_config_arguments(parser)
# args = parser.parse_args()
args, unknown = parser.parse_known_args() # jupyter notebook인 경우
return args
Python
복사
MoE (Mixture of Experts)
•
모델 파라미터 수가 많을수록, 모델 성능이 올라간다는 것은 이미 여러 연구를 통해 Scaling-Law가 입증되었다.
•
그래서 모델의 성능을 파악할때 파라미터 수는 가장 중요한 요소중 하나이다.
•
하지만 모두가 OpenAI, Google, Meta 같은 빅테크 기업들처럼 컴퓨팅 자원을 자유롭게 사용할수는 없기에, 현실적으로 제한된 컴퓨팅 자원으로 모델 학습/서빙을 해야한다.
•
모델 사이즈가 커질수록 학습/서빙 비용은 늘어날 수 밖에 없는데, MoE는 학습/서빙 비용은 유지하면서도 모델 사이즈를 키울 수 있는 방법이다.
•
구성요소
◦
Sparse MoE Layers: 기존 트랜스포머의 feed-forward network (FFN) 레이어를 N개의 expert로 나눠서 사용하는 개념, 이 expert는 FFN이지만, 특정 토큰들을 담당한다고 생각하면 된다.
◦
Gate Network (Router): 각 토큰이 어떤 expert에 소속되는지를 결정하는 network.
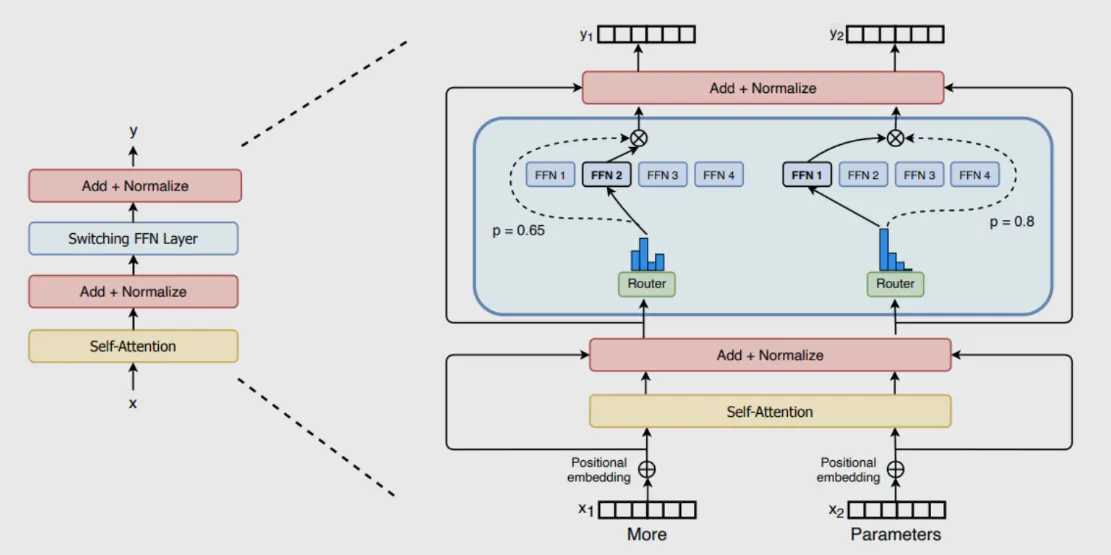
구성 퍼머넌트 (ConfigurationPermalink)
•
DeepSpeed를 사용하기 위한 다음 단계는 구성 JSON 파일(ds_config.json)을 생성하는 것이다.
•
이 파일은 배치 크기, 최적화 프로그램, 스케줄러 및 기타 매개변수 등 사용자가 정의한 DeepSpeed 관련 매개변수를 제공한다.
def get_ds_config(args):
"""Get the DeepSpeed configuration dictionary."""
ds_config = {
"train_batch_size": 16,
"steps_per_print": 2000,
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.001,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7,
},
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.001,
"warmup_num_steps": 1000,
},
},
"gradient_clipping": 1.0,
"prescale_gradients": False,
"bf16": {"enabled": args.dtype == "bf16"},
"fp16": {
"enabled": args.dtype == "fp16",
"fp16_master_weights_and_grads": False,
"loss_scale": 0,
"loss_scale_window": 500,
"hysteresis": 2,
"min_loss_scale": 1,
"initial_scale_power": 15,
},
"wall_clock_breakdown": False,
"zero_optimization": {
"stage": args.stage,
"allgather_partitions": True,
"reduce_scatter": True,
"allgather_bucket_size": 50000000,
"reduce_bucket_size": 50000000,
"overlap_comm": True,
"contiguous_gradients": True,
"cpu_offload": False,
},
}
return ds_config
Python
복사
Model - CNN 2D Layer
class Net(nn.Module):
def __init__(self, args):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.moe = args.moe
if self.moe:
fc3 = nn.Linear(84, 84)
self.moe_layer_list = []
for n_e in args.num_experts:
# Create moe layers based on the number of experts.
self.moe_layer_list.append(
deepspeed.moe.layer.MoE(
hidden_size=84,
expert=fc3,
num_experts=n_e,
ep_size=args.ep_world_size,
use_residual=args.mlp_type == "residual",
k=args.top_k,
min_capacity=args.min_capacity,
noisy_gate_policy=args.noisy_gate_policy,
)
)
self.moe_layer_list = nn.ModuleList(self.moe_layer_list)
self.fc4 = nn.Linear(84, 10)
else:
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
if self.moe:
for layer in self.moe_layer_list:
x, _, _ = layer(x)
x = self.fc4(x)
else:
x = self.fc3(x)
return x
Python
복사
Deepspeed
분산학습
•
아래 Torch 분산학습 코드를 사용하는 경우
torch.distributed.init_process_group(...)
Plain Text
복사
•
아래 코드로 교체해야 한다.
deepspeed.init_distributed()
Plain Text
복사
초기화
•
deepspeed.initialize()는 분산학습이나 혼합 정밀도 학습을 할 수 있도록 초기화 해준다.
•
Parameters
◦
args : local_rank 및 deepspeed_config를 포함
◦
model : torch.nn.module class 기반의 모델(transformers model 포함)
◦
model_parameters : model.parameters()
•
Returns
◦
tuple of engine, optimizer, train_dataloader, lr_scheduler
model_engine, optimizer, _, _ = deepspeed.initialize(args=cmd_args,
model=model,
model_parameters=params)
Python
복사
학습
•
deepspeed engine 초기화 후에 3가지 단계로 모델 학습이 가능
for step, batch in enumerate(data_loader):
#1. forward() method
loss = model_engine(batch)
#2. runs backpropagation
model_engine.backward(loss)
#3. weight update
model_engine.step()
Python
복사
•
Main 코드
def main(args):
# Initialize DeepSpeed distributed backend.
deepspeed.init_distributed()
########################################################################
# Step1. Data Preparation.
#
# The output of torchvision datasets are PILImage images of range [0, 1].
# We transform them to Tensors of normalized range [-1, 1].
#
# Note:
# If running on Windows and you get a BrokenPipeError, try setting
# the num_worker of torch.utils.data.DataLoader() to 0.
########################################################################
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
if torch.distributed.get_rank() != 0:
# Might be downloading cifar data, let rank 0 download first.
torch.distributed.barrier()
# Load or download cifar data.
trainset = torchvision.datasets.CIFAR10(
root="./data", train=True, download=True, transform=transform
)
testset = torchvision.datasets.CIFAR10(
root="./data", train=False, download=True, transform=transform
)
if torch.distributed.get_rank() == 0:
# Cifar data is downloaded, indicate other ranks can proceed.
torch.distributed.barrier()
########################################################################
# Step 2. Define the network with DeepSpeed.
#
# First, we define a Convolution Neural Network.
# Then, we define the DeepSpeed configuration dictionary and use it to
# initialize the DeepSpeed engine.
########################################################################
net = Net(args)
# Get list of parameters that require gradients.
parameters = filter(lambda p: p.requires_grad, net.parameters())
# If using MoE, create separate param groups for each expert.
if args.moe_param_group:
parameters = create_moe_param_groups(net)
# Initialize DeepSpeed to use the following features.
# 1) Distributed model.
# 2) Distributed data loader.
# 3) DeepSpeed optimizer.
ds_config = get_ds_config(args)
model_engine, optimizer, trainloader, __ = deepspeed.initialize(
args=args,
model=net,
model_parameters=parameters,
training_data=trainset,
config=ds_config,
)
# Get the local device name (str) and local rank (int).
local_device = get_accelerator().device_name(model_engine.local_rank)
local_rank = model_engine.local_rank
# For float32, target_dtype will be None so no datatype conversion needed.
target_dtype = None
if model_engine.bfloat16_enabled():
target_dtype = torch.bfloat16
elif model_engine.fp16_enabled():
target_dtype = torch.half
# Define the Classification Cross-Entropy loss function.
criterion = nn.CrossEntropyLoss()
########################################################################
# Step 3. Train the network.
#
# This is when things start to get interesting.
# We simply have to loop over our data iterator, and feed the inputs to the
# network and optimize. (DeepSpeed handles the distributed details for us!)
########################################################################
for epoch in range(args.epochs): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader):
# Get the inputs. ``data`` is a list of [inputs, labels].
inputs, labels = data[0].to(local_device), data[1].to(local_device)
# Try to convert to target_dtype if needed.
if target_dtype != None:
inputs = inputs.to(target_dtype)
# 모델 학습
outputs = model_engine(inputs)
# 오차 계산
loss = criterion(outputs, labels)
# 모델 역전파
model_engine.backward(loss)
# 모델 파라미터 업데이트
model_engine.step()
# Print statistics
running_loss += loss.item()
if local_rank == 0 and i % args.log_interval == (
args.log_interval - 1
): # Print every log_interval mini-batches.
print(
f"[{epoch + 1 : d}, {i + 1 : 5d}] loss: {running_loss / args.log_interval : .3f}"
)
running_loss = 0.0
print("Finished Training")
########################################################################
# Step 4. Test the network on the test data.
########################################################################
test(model_engine, testset, local_device, target_dtype)
Python
복사
Training
if __name__ == "__main__":
# deepspeed를 통해 만들어진 args 객체
args = add_argument()
main(args)
Python
복사
결과값
