


Accelerate

머신러닝 및 딥러닝 모델을 다양한 하드웨어 환경에서 효율적으로 학습하고 배포할 수 있도록 도와주는 라이브러리
여러 GPU나 TPU를 사용하는 분산 학습 환경을 간편하게 설정할 수 있게 해주어, 복잡한 설정 없이도 높은 성능을 발휘할 수 있도록 지원
•
모델이 커지면서 병렬 처리는 제한된 하드웨어에서 더 큰 모델을 훈련하고 훈련 속도를 몇 배로 가속화하기 위한 전략으로 등장했다.
•
Hugging Face에서는 사용자가 하나의 머신에 여러 개의 GPU를 사용하든 여러 머신에 여러 개의 GPU를 사용하든 모든 유형의 분산 설정에서 Transformers 모델을 쉽게 훈련할 수 있도록 돕기 위해 Accelerate 라이브러리를 만들었다.
Transformers 모델을 쉽게 훈련할 수 있도록 돕기 위해 Accelerate 라이브러리를 만들었다.기본 Multi-GPU 학습의 문제
•
PyTorch Distributed Data Parallel(DDP) 방식으로 Multi-GPU를 사용하면, 0번 GPU는 100% 활용되지만 나머지 GPU는 대체로 60~70% 수준으로 활용되어 자원 활용의 불균형이 발생.
•
이는 각 GPU에서 계산된 loss를 0번 GPU에서 집계하는 과정에서 0번 GPU에 부하가 집중되기 때문.
•
이 문제는 학습 속도를 저하시킬 뿐 아니라, GPU 리소스 활용의 효율성을 감소시킴.
특징
•
Hugging Face Accelerate 라이브러리를 활용하면 4줄의 추가 코드로 기존 PyTorch 코드를 수정하지 않고도 Multi-GPU 활용도를 100%로 극대화 가능.
•
Accelerate는 각 GPU가 독립적으로 loss를 계산하고, 합산 작업을 분산 처리하여 nvidia-smi 기준으로 모든 GPU가 100% 활용됨을 확인할 수 있음.
•
추가 기능:
◦
TPU 및 CPU 학습 지원.
◦
다양한 학습 설정을 쉽게 관리할 수 있는 직관적인 API 제공.
•
단 4줄의 코드만 추가하면 Multi GPU 분산 구성을 똑같이 100%로 활용할 수 있다.
•
기본 pytorch 코드를 통해 multi gpu를 사용하면(DDP) 0번 gpu만 100퍼센트 사용되고 나머지 GPU는 예를 들어 60% 정도씩 덜 활용된다.
•
각 GPU에서 loss를 계산하고 각 결과를 합해서 최종 loss를 구해야 하는데 합하는 연산을 0번 device에서 하기 때문에 0번의 소모만 커지기 때문이다.
•
accelerate을 사용하면 이러한 문제를 해결할 수 있다. nvidia-smi를 찍어보면 모든 GPU가 100% 활용되고 있는 것을 확인할 수 있다.
Accelerate 적용 전 Code
for batch in dataloader:
optimizer.zero_grad()
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss.backward()
optimizer.step()
scheduler.step()
Python
복사
Accelerate 적용 후 Code (Base Integration)
+ from accelerate import Accelerator
+ accelerator = Accelerator()
+ dataloader, model, optimizer, scheduler = accelerator.prepare(
+ dataloader, model, optimizer, scheduler
+ )
for batch in dataloader:
inputs, targets = batch
- inputs = inputs.to(device)
- targets = targets.to(device)
outputs = model(inputs)
loss = loss_function(outputs, targets)
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
Python
복사
•
accelerator 관련된 모든 것은 Accelerator() 클래스를 통해 이루어진다.
•
이를 사용하려면 먼저 객체를 만든다.
•
그런 다음 일반적으로 훈련하는 PyTorch 객체를 전달하여 .prepare를 호출한다.
•
이렇게 하면 동일한 객체가 반환되지만 필요한 경우 올바른 디바이스에 배포된다.
•
그런 다음 정상적으로 훈련할 수 있지만 loss.backward()를 호출하는 대신 accelerator.backward(loss) 를 호출한다.
또한 accelerator.prepare() 에 의해 자동으로 수행되므로 더 이상 model.to(device) 또는 inputs.to(device) 를 호출할 필요가 없다.
배치사이즈 선택
•
최적 배치 크기의 중요성
◦
배치 크기는 학습 속도와 메모리 활용 효율성에 직접적인 영향을 미침.
◦
배치 크기와 입력/출력 뉴런 수는 일반적으로 2의 승수를 선택하는 것이 최적화에 유리.
▪
이는 GPU 하드웨어의 구조적 특성과 관련 있으며, 계산 효율성을 극대화함.
•
NVIDIA 권장 사항
◦
GEMM(General Matrix Multiplication) 및 Fully Connected Layer 최적화를 위해 배치 크기 및 뉴런 수에 대해 NVIDIA 권장 사항을 참고.
◦
Tensor Core 기반 GPU(A100, H100 등)에서:
▪
fp16 데이터: A100에서는 64의 배수를 권장.
▪
fp32 데이터: 일반적으로 8의 배수.
◦
작은 파라미터의 경우 타일링 현상을 고려하여 정확한 승수를 선택하면 성능이 향상될 수 있음.
▪
타일링은 연산이 GPU 코어를 최적으로 활용하지 못할 때 발생하며, 적절한 설정으로 이를 방지 가능.
•
실무 팁
◦
모델과 하드웨어 특성에 따라 배치 크기를 점진적으로 조정하여 메모리 과부하 없이 최대 성능을 달성.
◦
GPU 메모리 사용량이 높은 경우 Gradient Accumulation과 병행하여 효율성을 높일 수 있음.
Gradient Accumulation
•
원리 및 장점
◦
그래디언트 누적은 GPU 메모리가 작아 대규모 배치 크기를 처리할 수 없을 때 유효 배치 크기를 늘리기 위해 사용.
◦
작은 배치 크기로 여러 번 forward 및 backward pass를 실행하며, 그래디언트를 누적하여 큰 배치 크기의 효과를 모방.
◦
충분한 그래디언트가 누적되면 Optimization Step을 수행하여 모델을 업데이트.
•
주요 이점
1.
메모리 효율성:
•
GPU 메모리 용량의 제약을 극복하여 대규모 데이터 학습 가능.
2.
대규모 배치의 성능 이점:
•
대규모 배치 학습은 모델이 안정적으로 수렴하고 학습 속도를 높이는 데 유리.
•
주의점
◦
추가적인 forward/backward pass로 인해 학습 시간이 증가할 수 있음.
◦
적절한 Gradient_accumulation_steps 값을 설정하여 최적의 학습 속도와 메모리 사용 간의 균형을 맞춰야 함.
•
Gradient_accumulation_steps 인수를 TrainingArguments에 추가하여 그라디언트 누적을 활성화할 수 있다.
◦
Hugging Face의 TrainingArguments에서 gradient_accumulation_steps를 설정하여 쉽게 적용 가능.
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=16,
gradient_accumulation_steps=4,
save_steps=10_000,
save_total_limit=2,
)
Python
복사
gradient_accumulation_steps=4로 설정하면, 각 배치가 16개 샘플로 구성되었을 때 4번 누적하여 유효 배치 크기 64로 학습.
Gradient Checkpointing
•
문제와 해결책
◦
대규모 모델 학습에서는 배치 크기를 1로 줄이고 그래디언트 누적을 사용하더라도 메모리 문제가 발생할 수 있음.
◦
이는 모델이 forward pass 동안 모든 activation 값을 저장해야 하며, backward pass 중에는 이 값들을 기반으로 그래디언트를 계산하기 때문.
◦
Gradient Checkpointing은 활성화 값을 일부만 저장하고, 나머지는 필요할 때 재계산함으로써 메모리 사용량을 줄이는 방법.
▪
이 접근법은 메모리와 계산 비용 간의 절충점을 제공.
▪
메모리 절약 효과는 크지만, 계산 비용 증가로 인해 학습 속도가 20%가량 감소할 수 있음.
•
활용
◦
그라디언트 체크포인팅을 사용하기 위해서는 해당 플래그를 TraningArguments에 전달하면 된다.
◦
Hugging Face의 TrainingArguments에서 gradient_checkpointing 플래그를 활성화하여 손쉽게 사용 가능.
training_args = TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
**default_args
)
Python
복사
•
주의사항
◦
메모리 절약 효과: GPU 메모리 제한이 있는 환경에서 유용.
◦
학습 속도 감소: 계산 부하 증가로 인해 느려질 수 있으므로 필요 시 선택적으로 활용.
◦
대규모 모델 학습에 필수적: GPT, BERT 등과 같은 모델 학습에서 필수적인 기법.
혼합 정밀 학습(Mixed precision training)
•
혼합 정밀 학습은 모든 변수가 32비트 부동소수점(fp32)로 계산될 필요가 없다는 점을 활용.
•
일부 계산을 16비트 부동소수점(fp16) 또는 bfloat16(bf16)으로 처리하여 계산 속도와 메모리 효율성을 최적화.
•
작동 원리
◦
모델의 가중치와 활성화 값 중 일부를 fp16으로 계산.
◦
중요 계산(예: 손실 함수 계산, 그래디언트 업데이트 등)은 여전히 fp32로 수행.
◦
혼합 정밀도를 사용하여 정확도와 효율성 사이의 균형을 맞춤.
정밀도(精密度, precision) : 여러 번 측정하거나 계산하여 그 결과가 서로 얼만큼 가까운지를 나타내는 기준
•
주요 이점
1.
계산 속도 향상:
•
fp16은 fp32보다 연산 속도가 최대 2~3배 빠름.
•
특히 Ampere 아키텍처 GPU(A100, H100 등)는 Tensor Core를 활용하여 추가 성능 향상 제공.
2.
메모리 절약:
•
메모리 사용량이 감소하여 더 큰 배치 크기와 모델을 처리 가능.
3.
호환성:
•
대부분의 딥러닝 프레임워크(PyTorch, TensorFlow)에서 지원.
•
Ampere 아키텍처 GPU는 bf16 및 tf32를 지원하여 더 유연한 정밀도 옵션 제공.
•
적용 방법
◦
PyTorch에서는 torch.cuda.amp 모듈을 통해 쉽게 적용 가능.
scaler = torch.cuda.amp.GradScaler()
for data, target in dataloader:
with torch.cuda.amp.autocast():
output = model(data)
loss = criterion(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
Python
복사
•
정밀도 옵션
◦
fp16(float16): 대부분의 GPU에서 지원, 가장 널리 사용.
◦
bf16(bfloat16): Ampere GPU에서 지원, fp16 대비 더 큰 범위를 처리 가능.
◦
tf32(Tensor Float 32): CUDA 내부 데이터 유형으로, FP32와 호환되며 속도 향상 제공.
•
주의사항
◦
모델 안정성:
▪
일부 모델에서는 정밀도를 낮출 경우 수렴 문제가 발생할 수 있음.
▪
GradScaler를 활용하여 안정성을 보장.
◦
하드웨어 지원:
▪
GPU 아키텍처에 따라 사용할 수 있는 정밀도 옵션이 다름(NVIDIA Ampere 아키텍처 권장).
•
NVIDIA 자료
◦
BF16
•
Ampere 이상의 하드웨어에서는 bf16을 사용해 혼합 정밀도 학습 및 평가를 할 수 있다.
•
bf16은 fp16보다 정밀도가 떨어지지만 동적 범위는 훨씬 크다.
•
fp16에서 가질 수 있는 가장 큰 수는 65535이며 그 이상의 수는 오버플로우를 일으킨다.
•
bf16 수는 fp32와 거의 동일한 3.39e+38(!)만큼 가질 수 있는데, 둘 다 수치 범위에 사용되는 8비트를 가지고 있기 때문이다.
•
BF16은 HF Trainer에서 활성화할 수 있다.
training_args = TrainingArguments(bf16=True, **default_args)
Python
복사
TF32
•
Ampere 하드웨어는 tf32라는 데이터 형식을 사용한다.
•
fp32(8비트)와 같은 숫자 범위를 갖지만 23비트 정밀도 대신 10비트(fp16과 동일)만 사용하며, 총합 19비트 만을 사용한다.
•
일반 fp32 훈련 및/또는 추론 코드를 사용할 수 있고 tf32 지원을 활성화하면 최대 3배의 처리량 향상을 얻을 수 있다는 점에서 "magical"하다.
•
코드에 다음을 추가하기만 하면 된다.
import torch
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
Python
복사
•
CUDA는 사용된 Ampere 시리즈 GPU를 사용할 경우, 자동으로 fp32 대신 tf32를 사용한다.
•
엔비디아의 연구에 따르면, 머신 러닝 트레이닝 워크로드의 대부분은 fp32와 마찬가지로 tf32 트레이닝과 동일한 복잡도와 수렴성을 보인다.
•
이미 fp16 또는 bf16 혼합 정밀도를 사용하고 있다면 throughput에 도움이 될 수 있다.
•
TF32는 HF Trainer에서 활성화할 수 있다
TrainingArguments(tf32=True, **default_args)
Python
복사
◦
tf32는 내부 CUDA 데이터 유형이기 때문에 tensor.to (dtype=torch.tf32)을 통해 직접 액세스할 수 없다.
◦
tf32 데이터 유형을 사용하려면 torch>=1.7이 필요하다.
Optimizer 선택
•
트랜스포머 모델을 훈련하는 데 사용되는 가장 일반적인 옵티마이저는 Adam 또는 AdamW(Adam with weight decay)이다.
•
Adam은 이전 그래디언트의 롤링 평균을 저장하여 수렴성이 좋지만, 모델 매개변수 수만큼 메모리 사용량을 추가한다.
•
이를 해결하기 위해 다른 옵티마이저를 사용할 수 있다.
•
허깅페이스 Trainer은 즉시 사용할 수 있는 다양한 옵티마이저를 제공한다.
(adamw_hf, adamw_torch, adamw_torch_fused, adamw_apex_fused, adamw_anyprecision, adafactor, adamw_bnb_8bit)
Data preloading
•
학습 속도를 최적화하기 위해서는 GPU가 처리할 수 있는 최대 속도를 공급하는 능력이다.
•
기본적으로 모든 것이 main process에서 발생하며, 디스크에서 데이터를 충분히 빨리 읽지 못하면 병목 현상이 발생하여 GPU 활용도가 떨어진다.
•
이러한 병목을 줄이기 위해서는 다음과 같은 인수를 구성하는 것이 좋다.
◦
DataLoader(pin_memory=True, ...) - 데이터가 CPU의 고정 메모리에 미리 로드되고 일반적으로 CPU에서 GPU 메모리로 훨씬 더 빠르게 전송된다.
◦
DataLoader(num_workers=4, ...) - 여러 worker에 데이터를 할당하여 더 빠르게 데이터를 사전 로드한다.
◦
학습 중에 GPU 사용률 통계를 보고 100%와 거리가 멀면 작업자 수를 늘리는 것을 고려해 볼 만하다.
(물론 문제가 다른 곳에 있을 수 있기 때문에 더 많은 worker가 더 좋은 성능으로 이어지지는 않을 수 있다.)
•
Trainer을 사용할 경우, TrainingArguments에서 dataloader_pin_memory는 default로 True이고, dataloader_num_workers는 default로 0을 가진다.
•
DeepSpeed는 HF Transformers 및 HF Accelerate와 통합된 오픈 소스 딥러닝 최적화 라이브러리로, 대규모 딥러닝 학습의 효율성과 확장성을 향상시키기 위해 설계된 광범위한 기능과 최적화를 제공한다.
•
모델을 단일 GPU에 올릴 수 있고 작은 배치 크기에 맞는 충분한 공간이 있다면 DeepSpeed를 사용할 필요가 없다. 그러나 모델이 단일 GPU에 적합하지 않거나 작은 배치조차 학습할 수 없다면 DeepSpeed ZeRO + CPU Offload 또는 NVMe Offload를 사용하여 훨씬 더 큰 모델을 사용할 수 있다.
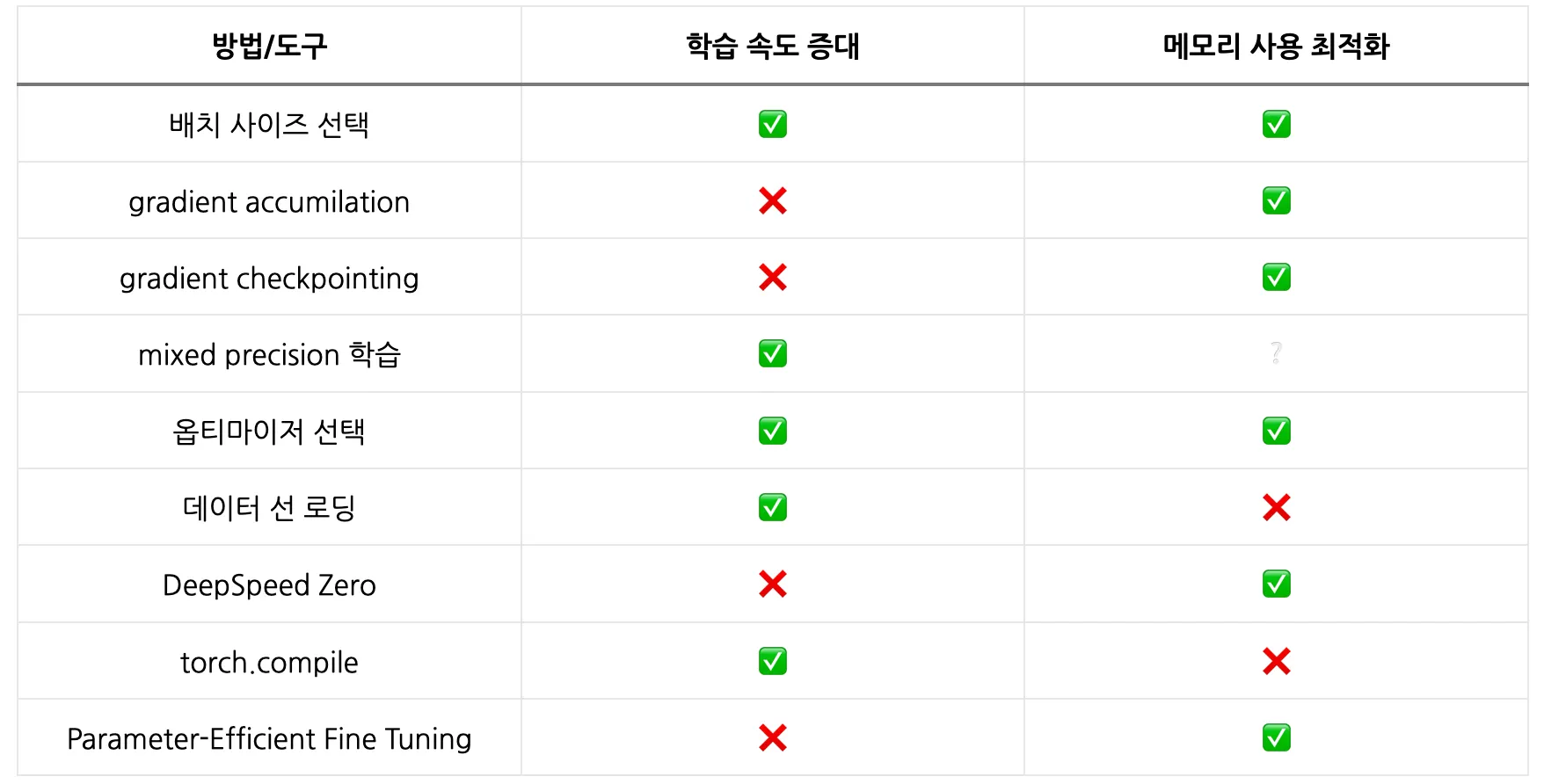
ZeRO - 2
ZeRO - 3
torch.compile 사용하기
•
PyTorch 2.0은 기존 PyTorch 코드를 수정할 필요가 없지만 한 줄의 코드(model = torch.compile(model))를 추가하여 코드를 최적화할 수 있는 새로운 컴파일 기능을 도입하였다.
training_args = TrainingArguments(torch_compile=True, **default_args)
Python
복사
•
Torch.compile은 파이썬의 frame evaluation API를 사용하여 기존 PyTorch 프로그램에서 자동으로 그래프를 만든다.
•
그래프를 캡처한 후 다양한 백엔드를 배포하여 최적화된 엔진으로 그래프를 낮출 수 있다.
•
torch.compile에는 백엔드 리스트가 증가하고 있으며, 이 목록은 torchdynamo.list_backends (),를 호출하여 찾을 수 있다.
HF PEFT 사용하기
•
PEFT(Parameter-Efficient Fine Tuning) 방법은 fine-tuning 중에 사전 훈련된 모델 파라미터를 동결하고 그 위에 소수의 훈련 가능한 파라미터(어댑터)를 추가한다.
•
결과적으로 옵티마이저 상태 및 그래디언트와 관련된 메모리가 크게 감소한다.
•
예를 들어 바닐라 AdamW의 경우 옵티마이저 상태에 대한 메모리 요구 사항은 다음과 같다.
◦
파라미터들에 대한 fp32 copy: 파라미터당 4byte
◦
모멘텀: 파라미터 당 4byte
◦
Variance: 파라미터당 4 byte
•
Low Rank Adapters를 사용하여 7B 파라미터 모델에 대해 2000만 개의 LoRA를 주입하여 모델을 학습하는 상황을 생각해 보자.
일반 모델의 옵티마이저 상태에 대한 메모리 요구 사항은 7B 파라미터 모델에 대해 12 * 7 = 84 GB다. Lora를 추가하면 모델 가중치와 관련된 메모리가 약간 증가하고 옵티마이저 상태에 대한 메모리 요구량이 12 * 0.2 = 2.4GB로 크게 줄어든다.
HF Accelerate 사용하기
•
Accelerate를 사용하면 학습 루프를 완전히 제어하면서 위에서 언급한 방법들을 사용할 수 있으며, 약간의 수정을 통해 순수 PyTorch로 루프를 작성할 수 있다.
•
Training Arguments에서 다음과 같이 gradient_accumulation, gradient_chechpointing, FP16 학습을 세팅했다고 생각해 보자
training_args = TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
fp16=True,
**default_args,
)
Python
복사
•
Accelarate에서는 다음과 같이 코드를 작성한다
from accelerate import Accelerator
from torch.utils.data.dataloader import DataLoader
dataloader = DataLoader(ds, batch_size=training_args.per_device_train_batch_size)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
accelerator = Accelerator(fp16=training_args.fp16)
model, optimizer, dataloader = accelerator.prepare(model, adam_bnb_optim, dataloader)
model.train()
for step, batch in enumerate(dataloader, start=1):
loss = model(**batch).loss
loss = loss / training_args.gradient_accumulation_steps
accelerator.backward(loss)
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
Python
복사
Mixture of Experts
•
Mixture of Expert를 트랜스포머 모델에 사용하면 학습 속도와 추론 속도를 4-5배 높일 수 있다고 발표된 바가 있다.
•
더 많은 파라미터를 사용하는 것이 더 좋은 성능으로 이어질 수 있기 때문에, 이 기법을 사용하면 학습 비용을 늘리지 않고도 파라미터를 몇 배 늘릴 수 있다.
•
MoE에서는 모든 FFN을 MoE 레이어로 대체하는데, MoE는 여러 전문가들로 구성되어 각 전문가는 일련의 입력 토큰 위치에 따라 균형 잡힌 방식으로 학습하는 게이트 기능을 가지고 있다.
