



•
딥러닝 모델의 크기가 증가함에 따라, 기존과 같이 태스크에 따른 모델 튜닝에 있어 기존과 같이 모든 파라미터를 미세조정하는 full-fine-tuning 방식은 자원 측면에서 점점 불가능해지고 있다.
•
이에 파라미터 효율적으로 fine-tuning 하는 PEFT 방법이 활발하게 연구되고 있다.
•
PEFT는 다운스트림 작업의 성능을 유지하거나 심지어 향상시키면서 학습에 필요한 계산량, 혹은 모델의 크기를 줄이는 것을 목표로 한다.
PEFT 장점
•
필요한 계산량의 감소: 모델 크기를 줄이고, 중복된 파라미터를 제거하며 정밀도를 낮춤으로써 연산량을 줄인다.
•
추론 속도의 향상: 모델 크기가 작아지고 계산 복잡도가 줄어듬에 따라 추론 속도가 감소하여 실시간 애플리케이션에 적합해진다.
•
리소스가 제한된 디바이스에서의 배포 개선: 모바일 디바이스나 엣지 디바이스와 같이 제한적인 시소스에의 배포가 용이해진다.
•
비용 절감: fine-tuning 및 추론에 드는 모든 비용이 절감된다
•
선능 유지 혹은 향상: 모델 크기가 줄어들면서도 다운스트림 태스크에의 성능을 유지하거나 향상하는 것이 가능하다.
양자화(Quantization)
•
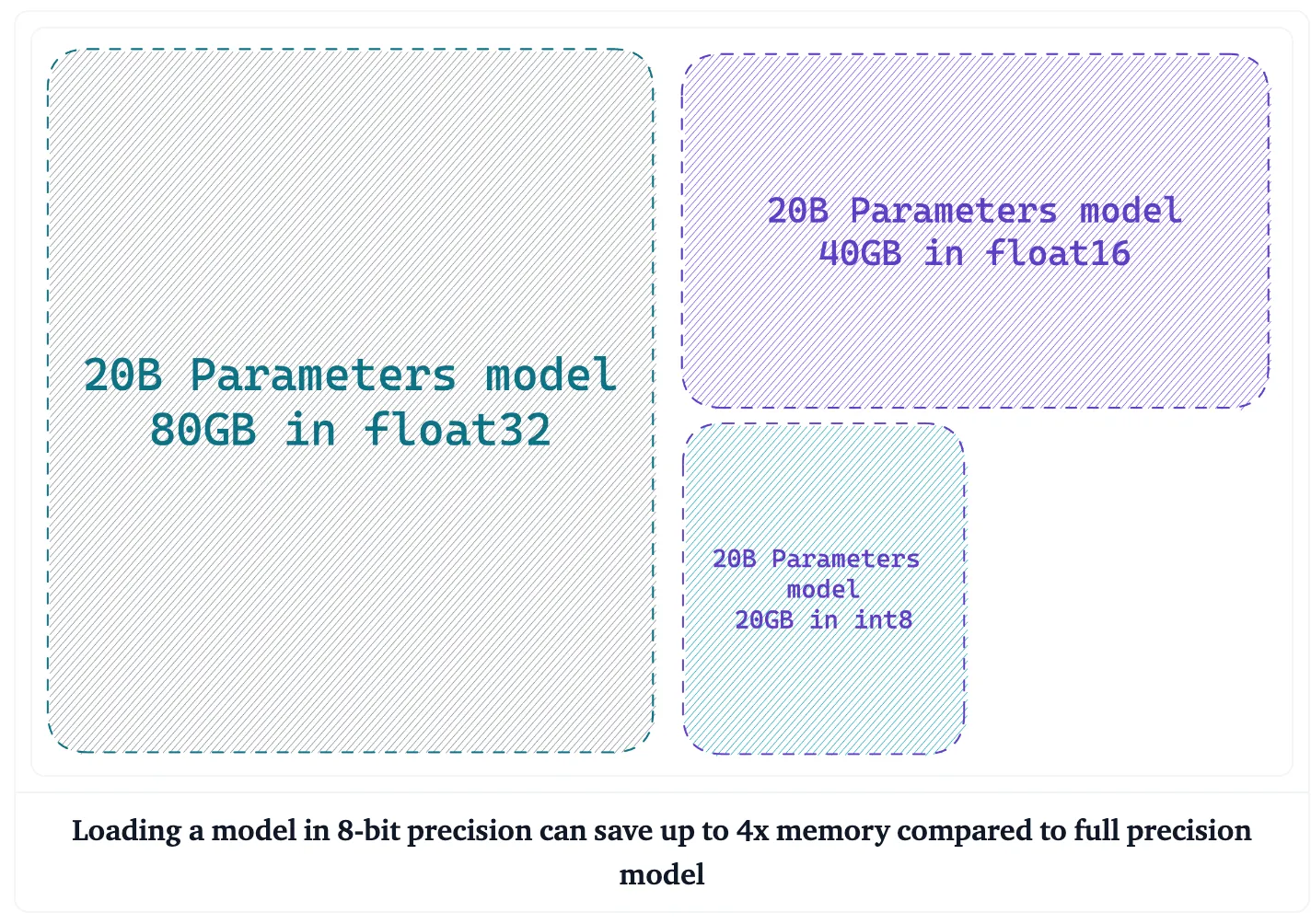
모델 매개변수(가중치)의 정밀도를 낮춰 메모리 및 계산 요구 사항을 낮추는 기술
•
기존 딥러닝 모델에서 매개변수는 일반적으로 32비트 부동 소수점 숫자로 저장된다.
•
하지만 양자화를 사용하면 이러한 매개변수를 8비트 정수와 같이 더 낮은 비트 정밀도로 표현할 수 있다.
•
이렇게 정밀도를 낮추면 메모리 사용량이 크게 줄어들고 계산 속도가 빨라진다.
Adapater Modules
•
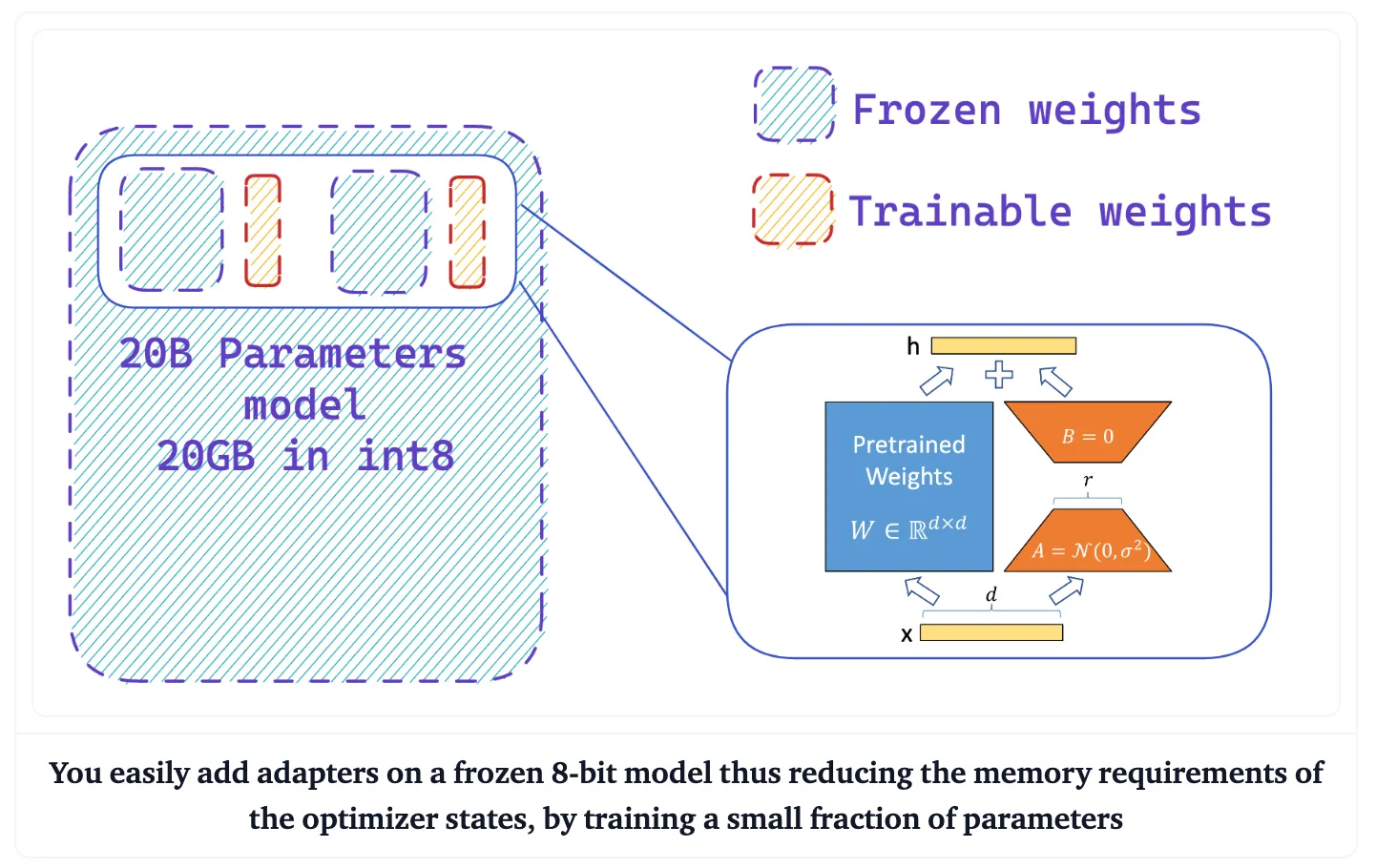
원래의 파라미터를 수정하지 않고 특정 작업을 위해 사전 학습된 모델에 추가하는 경량 모듈
•
어댑터 모듈은 사전 학습된 파라미터의 대부분을 그대로 유지(freeze)하면서 모델이 작업별 정보를 학습할 수 있도록 함으로써 효율적인 미세 조정이 가능하도록 한다.
•
이 접근 방식은 전체 모델을 재학습하지 않고(freeze)도 어댑터를 다른 태스크들에 대해 쉽게 추가하거나 제거할 수 있으므로 유연성과 효율성을 제공한다.
•
어댑터 모듈은 모델의 성능을 유지하면서 학습 파라미터의 개수를 줄여, 훈련 시간과 학습에 소요하는 메모리 비용을 줄일 수 있다는 장점이 있다.
•
Low-rank factorization 방법을 활용하여 LLM의 linear layer에 대한 업데이트를 근사화하는 기술
•
이는 훈련 가능한 매개 변수의 수를 크게 줄이고 모델의 최종 성능에 거의 영향을 주지 않으면서 훈련 속도를 높인다.
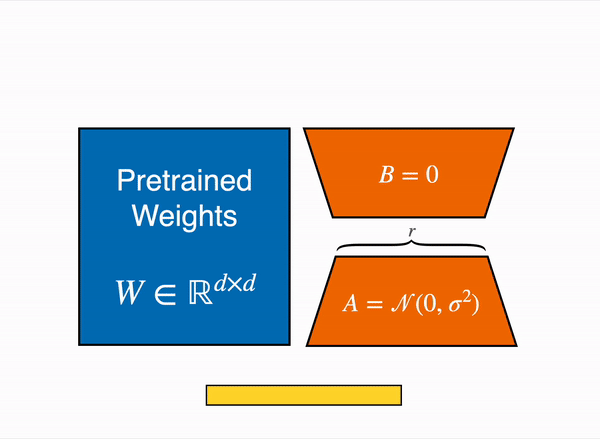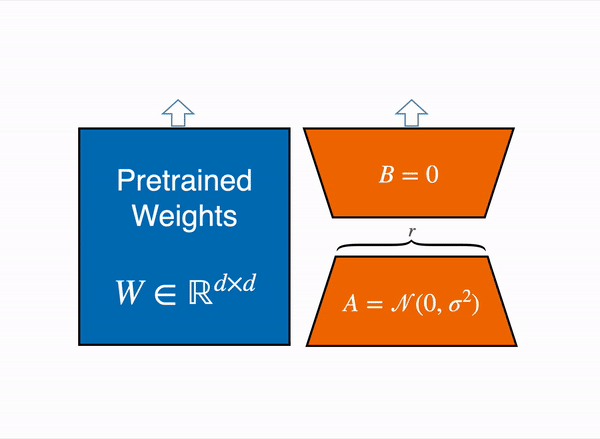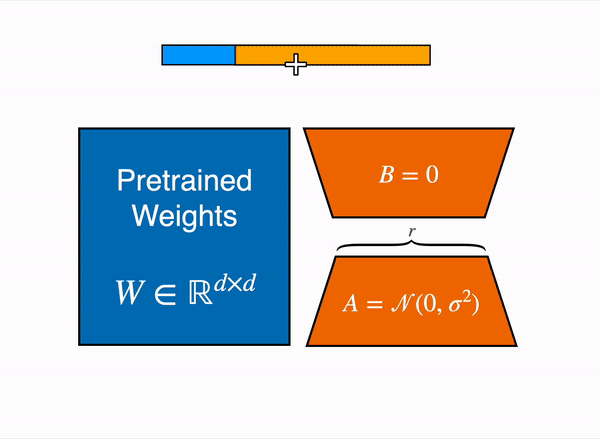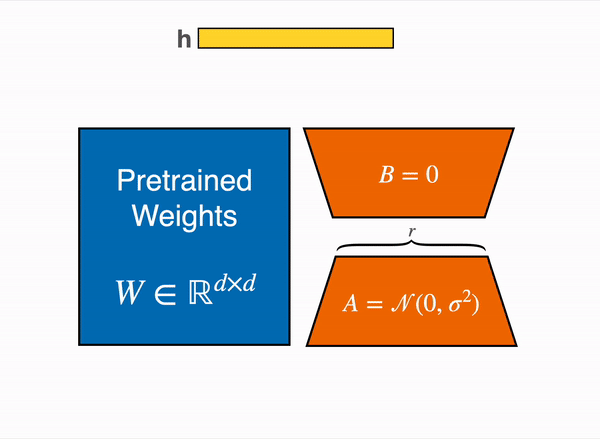
◦
왼쪽에 있는 파란색 box는 Pretrained Model 의 Weight 이다.
▪
Transformer layer의 Query, Key, Value, Output(=self attention) layer 의 차원은 (d x k)이다.
▪
d는 hidden_size, k는 웬만하면 d와 같다.
▪
Fully Freeze되어 학습 시 weight update가 되지 않는다.
•
gradient, optimize 관련된 tensor 값이 gpu에 load되지 않는다.
•
즉, vram을 save 할 수 있다.
◦
오른쪽에 있는 주황색 A 가 LoRA_A layer 이다.
▪
LoRA_A는 nn.linear이다.
▪
{d x r}의 차원을 가지고 있다.
▪
d는 hidden_size , r은 사용자가 설장한 낮은 차원(r << d)이다.
◦
오른쪽에 있는 주황색 B 가 LoRA_B layer이다.
▪
LoRA_B는 nn.linear이다.
▪
{r x k}의 차원을 가지고 있다. (k 는 웬만하면 d와 같다.)
▪
k는 웬만하면 d 와 같고, r 은 사용자가 설장한 낮은 차원(r << d)이다.
즉, Model weight를 freeze 하지만 Inference 시 사용되는 weight 값은 update가 된다. Model weight에 ( LoRA_B x LoRA_A )를 더해줬기 때문이다.
