


RLHF 단점
•
RLHF는 Supervised Fine-Tuning(SFT)과 달리 네거티브 신호를 줄 수 있다는 점에서 부적절한 답변을 생성하는 확률을 줄이는 등 여러 장점을 갖고 있지만, 몇가지 단점 또한 있다.
1.
방법이 복잡하다.
•
PPO (Proximal Policy Optimization) 등의 강화학습 기반으로 학습을 진행하는 RLHF 방법론은 실제 학습을 하는 생성 모델 (Actor) 뿐만 아니라 리워드 모델, Critic 모델, 레퍼런스 모델까지 총 4가지 모델이 필요하다.
2.
생성 모델(Actor)이 RLHF 기반으로 학습할 때에는 리워드 모델(reward model) 및 Critic 모델(LM policy)과 상호 작용을 하게 되는데, 이 때문에 학습이 안정적이지 못한 측면이 있다.
•
그렇기 때문에 학습이 hyperparameter들에 굉장히 민감해서 조금만 다른 값이어도 학습 결과가 크게 차이가 날 수 있다.
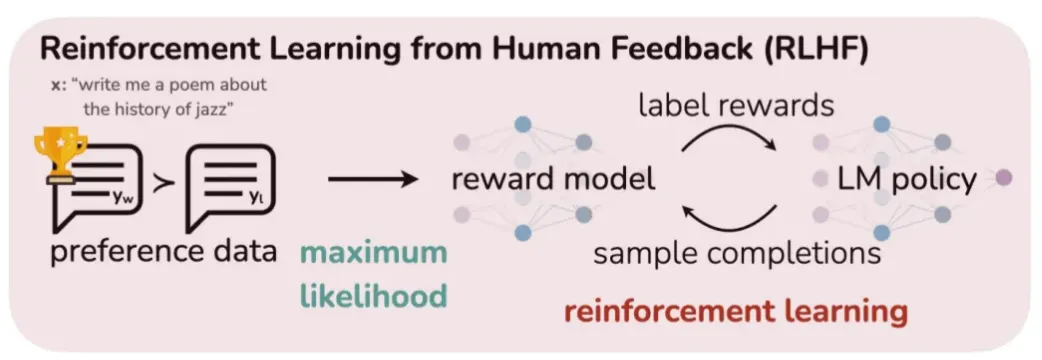
대체 방법론
RRHF
•
RRHF(Rank Responses to Align Language Models with Human Feedback without tears)는 현재 학습 시점의 모델(Policy 혹은 Actor)이 학습에 사용할 답변을 생성하는 Online 방식의 RLHF와 달리 아래 그림과 같이 Offline 방식으로 학습하기 전에 답변 후보들과 그 답변에 대한 스코어 정보들을 미리 구축해 놓는다.
•
이러한 Offline 방식은 Online 학습 방식에 비해 학습 방식이 간단하고, 학습이 좀 더 안정적인 장점이 있다.
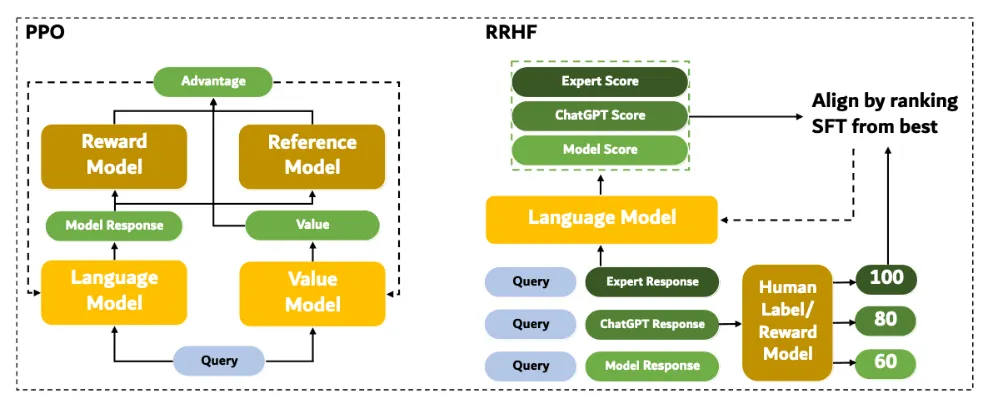
SLiC-HF
•
SLiC-HF는 SLiC-HF: Sequence Likelihood Calibration with Human Feedback [12]에서 제안한 방법으로 RRHF와 비슷한 방식으로 리워드 스코어를 계산하고 랭킹을 가리게 된다.
•
다만 SLiC-HF에서 사용한 리워드 모델은 단일 답변 후보를 인풋으로 받는 방식(Point-wise Reward Model)이 아니라, 다음 그림과 같이 형식으로 두 답변 후보를 동시에 입력으로 받아서 그 중 어떤 답변이 더 좋은 답변인지를 계산(Pair-wise Reward Model)하게 된다.
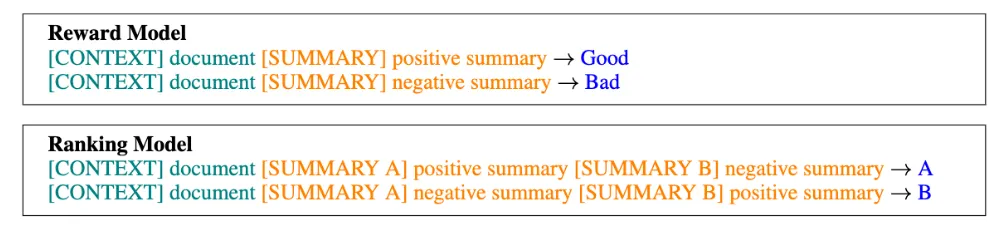
•
이렇게 우열을 메긴 답변 후보 쌍들을 기반으로 다음과 같은 Rank Calibration Loss를 구하게 된다.
•
이러한 Rank Calibration Loss를 통해 RRHF와 마찬가지로 랭킹이 보다 높은 답변의 확률이 높아지게 모델을 학습하게 된다.
•
DPO는 보상 모델(Reward Model)의 필요성을 모두 제거한다.
•
이를 통해 비용이 많이 드는 별도의 보상 모델(Reward Model)을 훈련하는 것을 피할 수 있으며, 우연히 DPO가 PPO만큼 작동하는 데 훨씬 적은 데이터가 필요하다는 것을 발견했다.
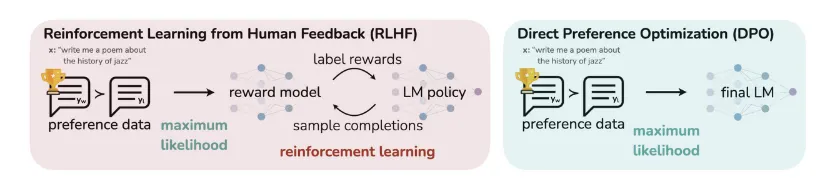
DPO 특징
1.
DPO에는 보상 모델이 필요하지 않는다!
모델이 좋은 것과 나쁜 것에 대한 명확한 방향을 갖고 이를 개선하려면 고품질 데이터가 필요하다.
2.
DPO는 역동적이다.
•
새로운 데이터를 사용할 때마다 올바른 방향을 파악하는 방식 덕분에 즉시 적응
•
새로운 데이터가 있을 때마다 보상 모델을 재교육해야 하는 PPO와 비교하면 이는 큰 승리다.
3.
DPO를 사용하면 모델이 다른 주제에 대해 좋은 답변을 제공하는 방법을 배우는 것만큼 특정 주제를 피하도록 모델을 교육할 수 있다.
•
입력 컨텍스트로부터 답변 문장이 생성될 확률을 기존 레퍼런스 모델과 현재 학습 중인 모델에 대해 각각 계산 후 그 비율을 계산하게 된다.
•
즉, DPO Loss는 선호 답변에 대한 원래 모델과 현재 학습 중인 모델의 확률 비율을 비선호 답변에 대한 비율보다 더 커지도록 학습되도록 한다.
•
DPO는 선호도 데이터를 직접적으로 사용하기 때문에 리워드 모델을 필요로 하지 않고 별도의 답변 후보들을 샘플링하는 과정이 생략되지만, 대신 학습 중에 레퍼런스 모델이 필요하다.
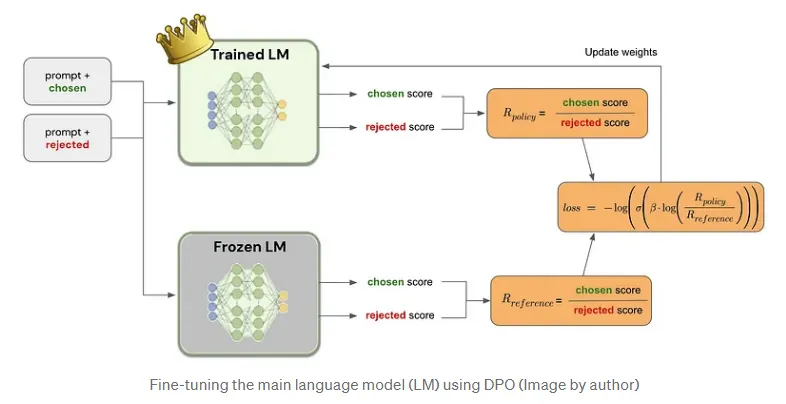
1. Prompt와 선택된 응답 및 거절된 응답 (Prompt + Chosen/Rejected)
◦
설명: 입력으로는 프롬프트와 이에 대한 두 가지 응답이 주어진다.
▪
Chosen: 인간 피드백이나 특정 기준에 따라 더 나은 응답으로 선택된 응답.
▪
Rejected: 덜 적절하거나 거절된 응답.
이 두 응답을 모델이 비교하여, 선택된 응답이 더 적절함을 학습하도록 한다.
2. Trained LM (훈련된 언어 모델)
◦
설명: 훈련된 언어 모델이 프롬프트와 응답을 입력받아, 각 응답에 대한 score를 계산한다.
▪
Chosen Score: 선택된 응답에 대한 점수.
▪
Rejected Score: 거절된 응답에 대한 점수.
◦
핵심 역할: 이 모델은 응답에 대한 점수를 계산하고, 선택된 응답과 거절된 응답의 점수를 비교한다. 이를 바탕으로 R_policy 값을 계산하는데, 이 값은 선택된 응답과 거절된 응답 간의 점수 차이로 정의된다.
◦
공식:
3. Frozen LM (고정된 언어 모델)
◦
설명: 고정된 언어 모델은 학습 과정에서 업데이트되지 않는다. 이 모델은 참조 모델(reference model)로 사용되어, 훈련된 모델이 얼마나 더 나은지 비교하는 기준 역할을 한다.
▪
고정된 모델 역시 선택된 응답과 거절된 응답에 대해 점수를 계산하고, R_reference 값을 생성한다.
◦
공식:
4. Loss Function (손실 함수)
◦
설명: 최종적으로 손실 함수는 훈련된 모델과 참조 모델 간의 점수 차이를 기반으로 계산된다.
▪
R_policy와 R_reference 간의 차이를 바탕으로, 선택된 응답이 거절된 응답보다 더 높은 점수를 받을 수 있도록 모델을 조정한다.
▪
이 손실 함수는 모델이 선택된 응답을 더 높게 평가하고, 거절된 응답은 낮게 평가하도록 학습시킨다.
◦
공식:
5. Update Weights (가중치 업데이트)
◦
설명
▪
계산된 손실을 바탕으로 언어 모델의 가중치가 업데이트된다.
▪
이 과정은 반복되어 모델이 더 나은 응답을 선택하고, 거절된 응답을 피할 수 있도록 학습한다.
