•
ChatGPT를 사용해 과제나 리포트 작성을 할 때, 원하는 방향으로 답변이 나오도록 여러가지 입력을 준 경험이 한 번씩 있다면, "프롬프트(Prompt)를 잘 줘야 ChatGPT가 대답을 잘해줘"라는 말을 들은 경험도 있을 것이다.
•
즉, 프롬프트(Prompt)란 ChatGPT 모델이 사용자가 원하는 답변을 내뱉기 위해 주는 적절한 입력값이다.
•
이러한 프롬프트(Prompt)를 사용해서 모델의 추론/학습에 관여하는 프롬프트 엔지니어링(Prompt Engineering), 프롬프트 튜닝(Prompt Tuning) 등이 활발히 연구되고 있다.
프롬프트 생성 방법
•
프롬프트 생성방법에 따라 크게 Manual-Search Prompt 또는 Auto-Search Prompt로 나눌 수 있다.
Manual-Search Prompt
•
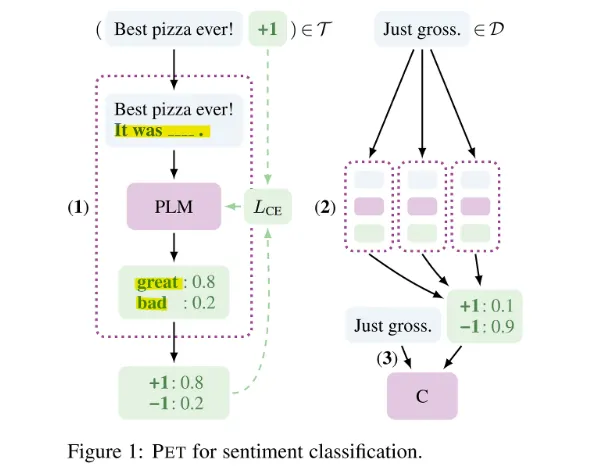
초기에는 주로 메뉴얼한 방식으로 각 테스크마다 적절한 프롬프트를 찾아주었는데, 대표적인 예로는 PET(Schick and Schutze., EACL'20)에서 사용한 Verbalizer를 들 수 있다.
•
감성분석(Sentiment Classification) 테스크를 BERT, RoBERTa와 같은 Masked Language Model(MLM) 기반의 사전학습 모델에서 수행한다고 할 때, 기존에는 "Best pizza ever!"만을 가지고 긍정적인 감정임을 학습해야 했다.
•
그러나, 해당 논문에서는 기존 입력과 함께 "It was [MASK]"라는 탬플릿을 모델에게 주어 [MASK]에 등장해야 하는 단어가 긍정 단어인 great로 예측될 확률을 높이며 학습하게 하였다.
Auto-Search Prompt
•
Manual-Search Prompt의 경우 직관적이고, 모델 학습에 효과적이지만 적절한 프롬프트를 찾기까지에 시간이 많이들고, 프롬프트를 생성할 사람에 따라 편차가 크다는 문제점이 있다.
•
이에 자동적으로 프롬프트를 찾는 방법인 Auto-Search Prompt가 연구되기 시작했다.
•
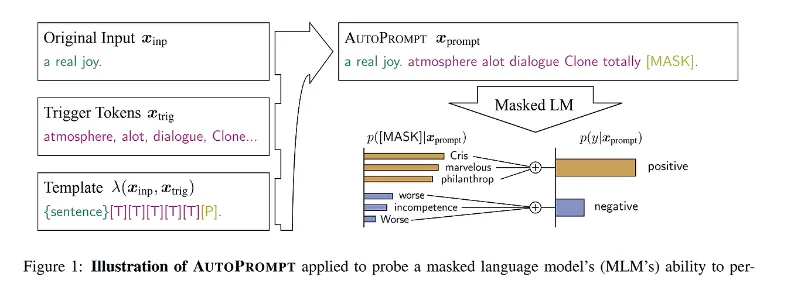
대표적인 논문으로 AutoPrompt(Shin et al., EMNLP'20)가 있다.
•
감정 분석 테스크를 MLM 기반의 모델에서 수행한다고 할 때, PET 논문에서는 직접 사람이 테스크마다 프롬프트를 정의했지만, AutoPrompt에서는 정답 레이블의 확률이 가장 높아지는 토큰을 찾아 이를 프롬프트로 정의한다.
•
기존에는 하나의 정답지만 학습했다면 지금은 여러 개의 정답지를 학습시키는 것이다.
프롬프트의 형태에 따른 학습 방법
Hard Prompt vs. Soft Prompt
•
프롬프트는 크게 Hard Prompt와 Soft Prompt로 나눌 수 있다.
•
Hard Prompt
◦
자연어 형태의 이산적인(Discrete) 값을 가진다.
◦
언어모델은 이산적인 값이 아닌 연속적인 값으로 학습되기 때문에 Hard Prompt는 최적화되지 않은 단점이 있다.
•
Soft Prompt
◦
Soft Prompt는 실수(혹은 실수 값으로 구성된 벡터)로 이루어진 연속적인(Continuous) 값을 가진다.
◦
input 앞에 튜닝이 가능한 임베딩 조각(tunable piece of embedding)이 붙게 된다.
◦
이 임베딩 조각은 실수(Real Number)로 이루어진 연속적인(Continuous) 값으로 학습되고, 기존의 Hear Prompt 학습에 비해 더 효과적인 학습이 가능하다.
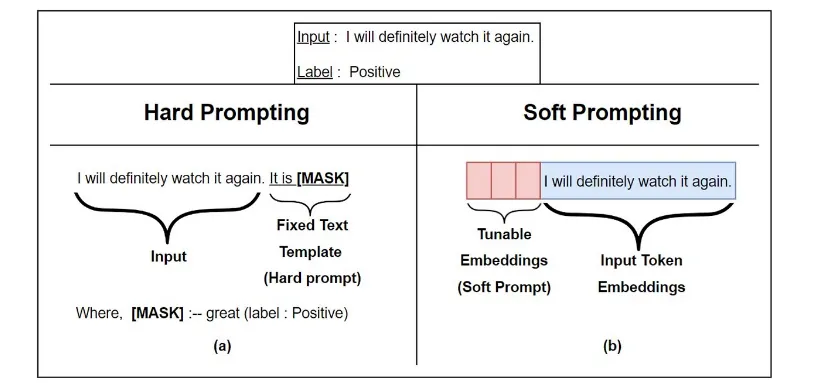
◦
왼쪽에 있는 그림은 Hard Prompting을 나타낸다.
▪
설명
•
Hard Prompting에서는 고정된 텍스트 템플릿을 사용하여 입력 문장에 추가적인 정보를 제공하는 방식이다.
•
예시에서는 "It is [MASK]"라는 템플릿을 사용하여 입력 문장에 빈칸을 만들고, 모델이 해당 빈칸에 들어갈 적절한 단어(레이블에 해당하는 단어)를 예측하도록 한다.
▪
구체적인 예시
•
Input: "I will definitely watch it again."
•
Prompting: "It is [MASK]"
•
여기서 [MASK]는 모델이 추측해야 할 부분이며, 이 예제에서는 긍정적인 감정(예: "great")으로 채워질 것이다.
•
모델이 예측한 값이 [MASK]에 들어갈 단어가 되며, 그 단어를 통해 문장의 감정을 예측한다.
◦
오른쪽의 그림은 Soft Prompting을 나타낸다.
▪
설명
•
Soft Prompting은 고정된 텍스트 템플릿 대신, 학습 가능한 임베딩을 입력에 추가하는 방식이다.
•
모델이 학습 과정에서 이 추가적인 임베딩을 조정하면서 더 나은 성능을 낼 수 있도록 한다.
•
입력 문장은 그대로 두되, 앞에 학습 가능한 임베딩 벡터가 붙는다.
▪
구체적인 예시
•
Input: "I will definitely watch it again."
•
Prompting: 입력 문장 앞에 학습 가능한 임베딩 벡터가 추가된다.
•
이 벡터는 모델이 학습 과정에서 최적화할 수 있으며, 고정된 템플릿을 사용하는 대신 더 유연한 방식으로 모델을 훈련시킨다.
Sfot Prompt + Frozen Pre-trained Model
•
대표적인 연구로는 Prompt Tuning과 Prefix Tuning이 있다.
•
두 논문 모두 Soft Prompt를 이용해 기존의 파인튜닝 대비 효과적인 학습이 가능하다는 점을 주요 포인트로 하고 있다.
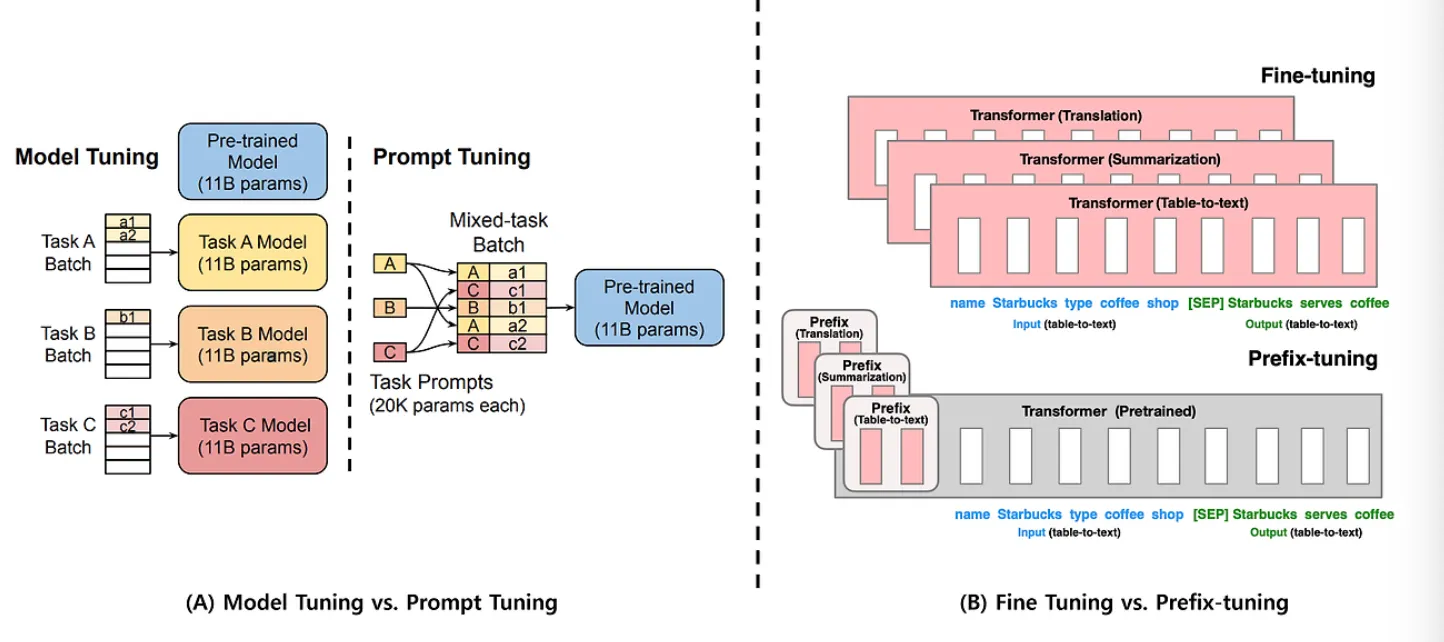
◦
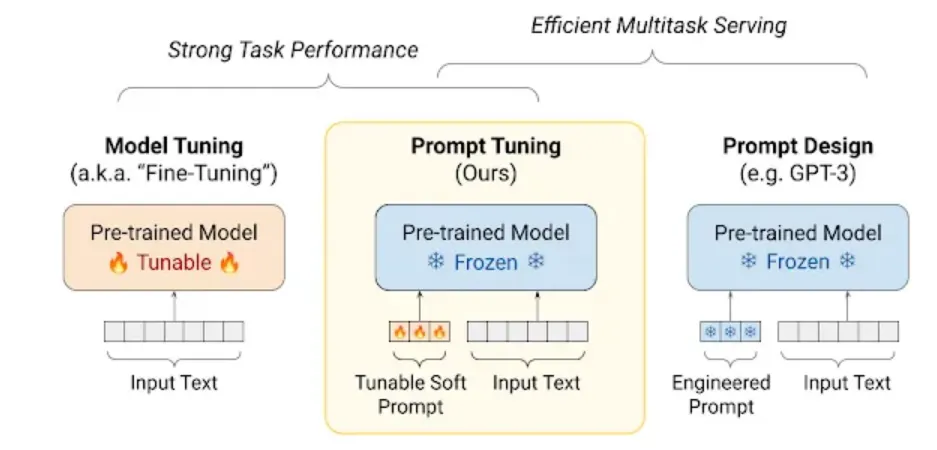
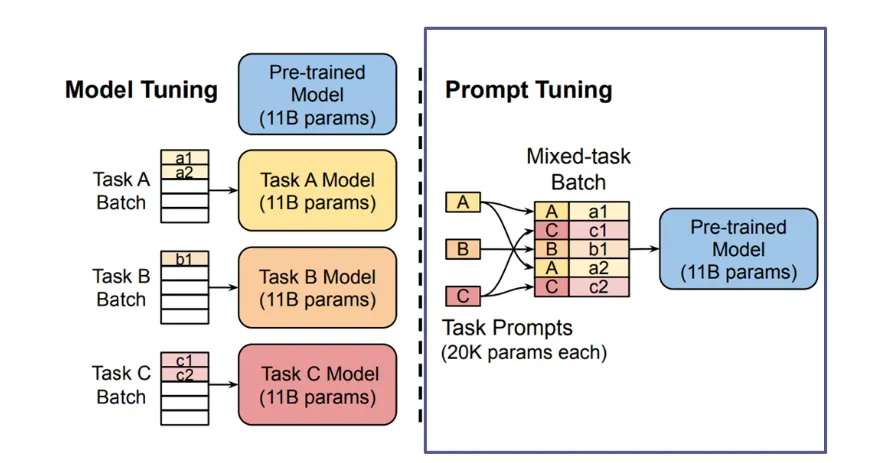
Prompt Tuning(그림 A)
▪
사전학습모델(Pre-trained Model)을 이용하여 A, B, C 테스크를 수행한다고 할 때, 기존의 Model Tuning 방법과 제안 방법인 Prompt Tuning을 비교해서 보여주고 있다.
▪
Model Tuning (모델 튜닝)
•
설명
◦
모델 튜닝은 각 작업(Task)에 대해 모델을 따로 미세 조정하는 방법이다.
◦
예를 들어, Task A, Task B, Task C와 같은 서로 다른 작업마다 해당 작업에 맞게 각각 모델을 튜닝한다.
•
특징
◦
사전 학습된 모델(Pre-trained Model, 11B 파라미터)을 기반으로 각 작업에 맞게 전체 모델을 미세 조정한다.
◦
각 작업마다 새로운 모델을 생성해야 하기 때문에 모델 크기가 크며, 작업이 많아질수록 모델 저장 공간과 시간이 많이 필요하다.
▪
Prompt Tuning (프롬프트 튜닝)
•
설명
◦
프롬프트 튜닝은 동일한 사전 학습된 모델을 사용하되, 작업마다 작은 프롬프트 벡터를 학습시키는 방식이다.
◦
즉, 사전 학습된 큰 모델을 그대로 두고, 프롬프트만 조정하여 여러 작업을 해결한다.
•
특징
◦
사전 학습된 모델(11B 파라미터)은 고정되어 있으며, 작업마다 프롬프트(20K 파라미터)를 조정한다.
◦
작업별로 프롬프트만 학습하므로 훨씬 적은 파라미터를 다룬다.
◦
이는 메모리 효율이 높으며, 여러 작업을 동시에 처리할 수 있는 장점이 있다.
◦
Prefix Tuning(그림 B)
▪
다양한 테스크를 수행한다고 할 때 기존 Fine-tuning 방법은 각 테스크마다 모델 전체 파라미터를 업데이트 해야한다는 문제점을 이야기하고 있다.
▪
Fine-tuning (파인 튜닝)
•
설명
◦
Fine-tuning은 사전 학습된 모델의 모든 파라미터를 작업에 맞춰 조정하는 방법이다.
◦
예를 들어, 번역, 요약, 테이블-텍스트 변환 같은 다양한 작업을 수행하기 위해 모델의 파라미터를 조정한다.
•
특징
◦
각 작업마다 전체 모델을 조정하므로 파라미터 수가 크다.
◦
모델을 특정 작업에 맞게 완전히 맞춤화할 수 있지만, 작업이 달라질 때마다 모델 전체를 미세 조정해야 하기 때문에 연산 비용이 크다.
◦
각 작업에 대해 개별적으로 모델을 저장해야 하므로 메모리 소모가 많다.
▪
Prefix-tuning (프리픽스 튜닝)
•
설명
◦
Prefix-tuning은 사전 학습된 모델의 파라미터를 변경하지 않고, 입력 앞에 학습 가능한 프리픽스(prefix)를 추가하여 모델을 조정하는 방법이다.
◦
이 프리픽스는 입력과 함께 모델로 전달되며, 이를 통해 특정 작업에 맞게 출력을 조정한다.
•
특징
◦
모델의 나머지 부분은 고정되어 있으며, 프리픽스(작업에 맞춘 벡터)만 학습된다.
◦
사전 학습된 모델을 그대로 유지하면서도 작업마다 다른 프리픽스를 사용하여 다양한 작업을 처리할 수 있다.
◦
메모리 사용량과 연산 비용이 절감된다.
•
두 논문에서는 학습 가능한 Soft Prompt를 이용하여 테스크마다 개별로 모델 전체 파라미터를 업데이트 할 필요없이 프롬프트만 업데이트하여 효율적인 학습을 가능하게 했다.
•
모델에 들어가는 입력 데이터(input data)를 사람이 읽을 수 있는 설명(human readable instructions)으로 잘 작성된 텍스트와 연결하여 수정하게 되는데, 이때 만들어지는 텍스트를 프롬프트(prompt)라고 한다.
•
프롬프트는 task-specific하게 훈련되지 않아도 사전학습 언어모델(PLM, Pre-trained Language Model)이 새로운 테스크(e.g. 질의응답, 기계번역 등)에 대해서 잘 수행되도록 한다.
•
즉, 단지 자연어로 모델이 어떤 일을 수행해야 할지 알려주는 것만으로도 별도의 추가훈련 없이 새로운 테스크를 좋은 성능으로 수행할 수 있다.

Prompt-based learning 목적 : 프롬프트의 도움을 받아 사전학습된 지식을 최대한 활용하자
Prompt-based Learning Method
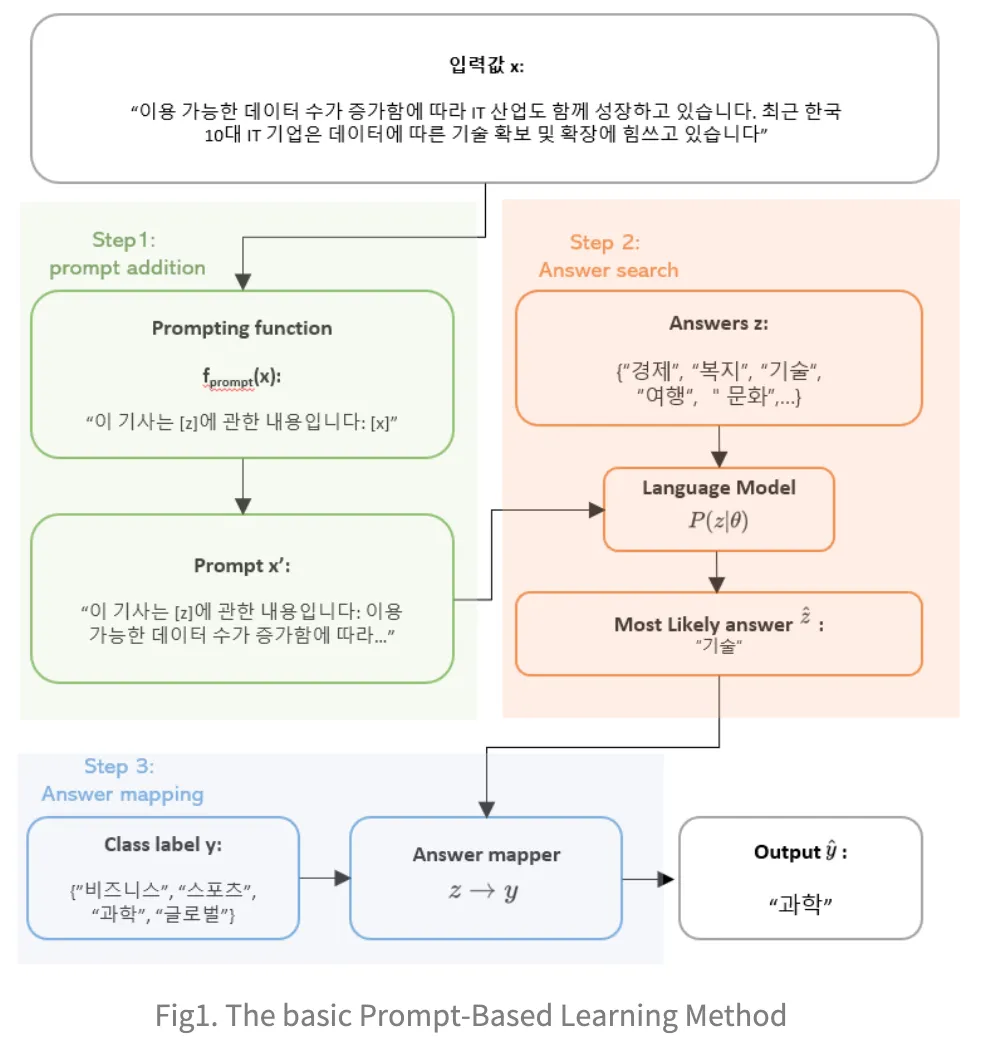
Step 1: Prompt Addition (프롬프트 추가)
•
설명
◦
먼저 기존의 입력값(x)가 prompt function을 통과하게 되면, 사전에 정의해둔 패턴 형식인 prompt x'로 바뀌게 된다.
▪
이때 사전에 정의해둔 형태를 prompt template이라고 하게 된다.
◦
해당 template은 언어모델이 특정 테스크를 풀 수 있도록 기존의 입력값 형태를 바꿔주는 것
▪
예로 언어모델이 MLM(Masked Language Model) 기반이라면 입력값이 적절한 변형과 <MASK> 토큰을 넣어주게 된다.
•
입력 값
◦
예시로 "이용 가능한 데이터 수가 증가함에 따라 IT 산업도 함께 성장하고 있습니다. 최근 한국 10대 IT 기업은 데이터에 따른 기술 확보 및 확장에 힘쓰고 있습니다."라는 문장이 주어짐.
•
프롬프트 함수
◦
입력 문장 x에 특정 프롬프트를 추가하는 단계
◦
이 프롬프트는 모델이 답을 찾기 쉽게 힌트를 제공하는 역할을 한다.
◦
예시 프롬프트: "이 기사는 [z]에 관한 내용입니다: [x]"
◦
여기서 [z]는 모델이 예측해야 할 답변 자리이고, [x]는 주어진 입력 문장이 그대로 들어간다.
•
출력값 : 생성된 프롬프트
◦
최종적으로 생성된 문장은 다음과 같다:
▪
"이 기사는 [z]에 관한 내용입니다: 이용 가능한 데이터 수가 증가함에 따라..."
Step 2: Answer Search (답변 검색)
•
prompt function을 통과한 값 x'은 언어모델을 통해 prediction되며 결과는 언어모델의 vocab에 존재하는 단어인 z로 나오게 된다.
•
Answers
◦
모델은 여러 가지 가능한 답변 후보(예: "경제", "복지", "기술", "여행", "문화" 등) 중에서 가장 적절한 답을 선택하게 된다.
•
Language Model (언어 모델)
◦
사전 학습된 언어 모델이 입력된 프롬프트에 맞는 답을 확률적으로 계산한다. 모델은 주어진 문맥을 바탕으로 가장 적절한 답을 찾는다.
◦
이 모델은 확률 에 따라 답변 후보 중에서 가장 적합한 답변을 예측한다.
•
Most Likely Answer (최적 답변)
◦
모델이 가장 높은 확률로 예측한 답변은 "기술"이다.
◦
여기서 "기술"이라는 답은 주어진 입력 문장의 주제와 관련된 정보로 판단된다.
Step 3: Answer Mapping (답변 매핑)
•
해당 값 z를 테스크의 레이블링 값으로 변환해주는 과정을 거쳐 최종 아웃풋인 y를 얻게 된다.
•
Class Label y
◦
답변 후보가 주제별로 분류되며, 예를 들어 "비즈니스", "스포츠", "과학", "글로벌"과 같은 분류 레이블이 있다.
•
Answer Mapper (답변 매퍼)
◦
모델이 예측한 답변 "기술"을 특정 카테고리로 매핑한다.
◦
예를 들어 "기술"이라는 답변이 "과학"이라는 클래스로 매핑된다.
•
최종 출력
◦
모델이 최종적으로 출력한 값은 "과학"이다. 이는 입력 문장이 "과학"과 관련된 내용이라고 판단한 결과이다.
Prompt Based Learning의 필요성
1.
기존의 접근 방식: Pre-train과 Fine-tune
a.
Pre-train (사전 학습)
•
언어 모델을 대량의 텍스트 데이터로 미리 학습시키는 단계
•
예: GPT-3, BERT 등이 있다.
b.
Fine-tune (파인튜닝)
•
사전 학습된 모델을 특정 작업(예: 감정 분석, 번역 등)에 맞추기 위해 추가로 학습시키는 단계
문제점:
•
레이블링된 데이터 필요: 파인튜닝을 위해서는 정답이 표시된(레이블링된) 데이터가 필요
•
비용과 시간: 데이터를 직접 수집하고 라벨링하는 데 많은 시간과 비용이 든다.
•
데이터의 한계: 무료로 사용할 수 있는 레이블링된 데이터는 한정적이다.
2.
Prompt-Based Learning의 등장
•
Prompt-Based Learning은 모델을 추가로 학습(fine-tuning)시키지 않고, 입력 문장을 적절히 설계(prompt)를 통해 원하는 작업을 수행하도록 하는 방법
•
장점
◦
파인튜닝의 한계 극복: 추가 학습 없이도 모델을 다양한 작업에 활용할 수 있다.
◦
비용 절감: 레이블링된 데이터가 필요 없거나 매우 적기 때문에 비용과 시간을 절약할 수 있다.
◦
유연성: 다양한 작업에 쉽게 적용할 수 있다.
3.
Zero-shot과 Few-shot Learning
•
Zero-shot Learning (제로샷 학습)
◦
모델이 새로운 작업을 수행할 때, 전혀 추가 학습 데이터 없이도 결과를 도출하는 방법
•
Few-shot Learning (퓨샷 학습)
◦
모델이 새로운 작업을 수행할 때, 아주 적은 양의 학습 데이터(예: 몇 개의 예시)만으로도 좋은 성능을 내는 방법
•
장점
◦
추가 데이터 불필요: 많은 레이블링된 데이터가 필요 없거나 전혀 필요하지 않다.
◦
다양한 작업 수행 가능: 하나의 모델로 여러 가지 작업을 수행할 수 있다.
•
OpenAI가 발표한 GPT-3는 어마어마한 규모와 더불어 뛰어난 성능을 자랑함
•
in-context learning과 prompting이라는 새로운 패러다임을 제시
Traditional | Fine-tuning
•
파인튜닝 : 원하는 태스크에 특화된 지도학습 데이터셋을 학습시킴으로써 사전학습된 모델(Large Pretrained Language Model)의 가중치(weight)을 업데이트하는 방법
가중치를 업데이트한다는 것 = 원하는 태스크에 맞는 언어적 특징을 학습한다는 것을 의미
◦
태스크 예시: 감정분석, 기계번역, 요약, 질의응답 등
•
지도학습이기 때문에 정답이 라벨링이 된 굉장히 많은 수의 데이터들이 사용됨
•
굉장히 좋은 성능을 보여주지만, 여러 가지 한계가 존재
◦
매 태스크마다 새로운 큰 규모의 데이터셋이 필요
◦
일반화가 잘 되지 않는(poor generalization) 문제가 발생할 수 있음
▪
언어에 대한 일반적인 지식을 학습한 pretrained model의 파라미터를 원하는 태스크에 맞춰 조정하는 과정에서 일반화 성능이 감소할 수 있음
In-context Learning
•
인컨텍스트 러닝 : 언어모델의 인풋 앞에 자연어 태스크에 대한 설명과 몇 가지 예시를 더해 모델에 넣으면, 언어모델이 태스크에 맞는 아웃풋을 생성하는 새로운 학습방법
•
자연어 이해 및 생성에 있어서 언어모델의 예측을 도울 수 있도록 인풋 컨텍스트에 특별한 템플릿을 사용하는 것을 의미
•
가중치(weight)의 업데이트가 일어나지 않음
•
대량의 데이터셋이 필요하지 않음
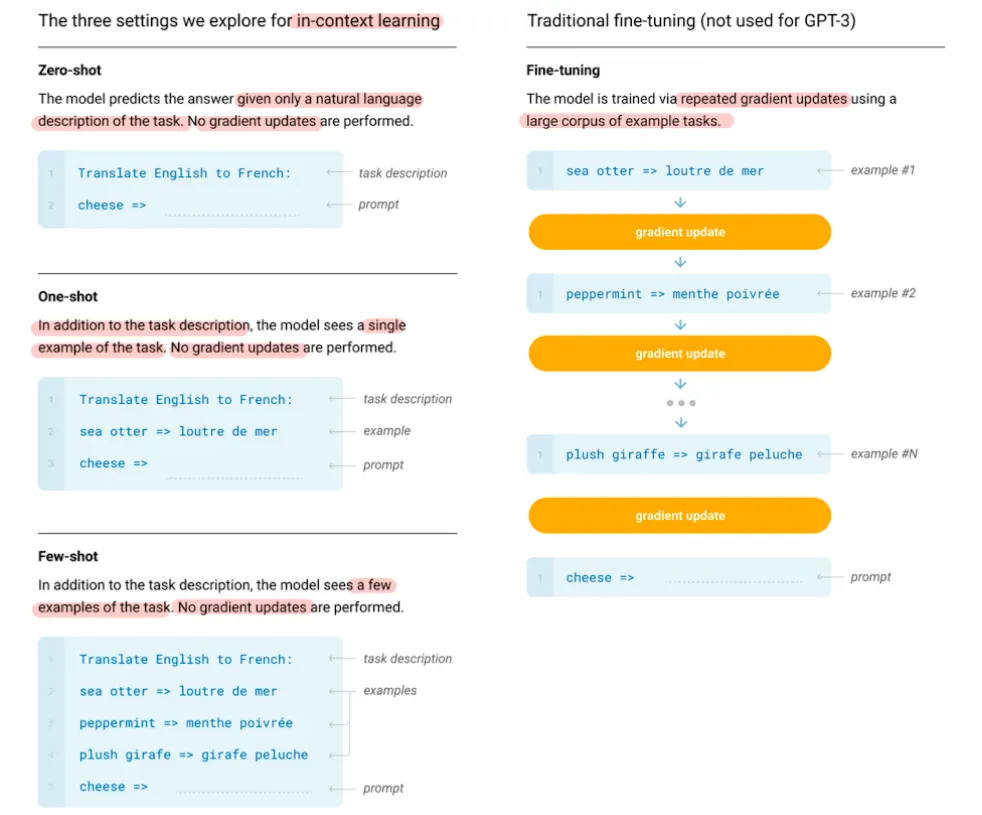
Few-shot(2개 이상)
•
언어모델이 추론(inference)을 할 때, 태스크에 대한 몇 개의 demonstration(예시)이 주어짐
•
장점
◦
태스크에 특화된 데이터의 필요성을 감소시킴
◦
파인튜닝의 문제점으로 꼽히는 (narrow distribution의 학습으로 인한) 일반화 성능 감소의 가능성을 낮춰줌
◦
사전학습된 모델에 내재되어 있는 태스크들 사이의 넓은 분포를 학습하고(=일반화 성능을 놓치지 않으며), 새로운 태스크에 빠르게 적응
•
단점
◦
SOTA(state-of-the-art) 파인튜닝에 비해 성능이 다소 떨어짐
◦
여전히 태스크 특화 데이터가 일부 필요
One-shot(1개)
•
Few-shot과 유사하지만 오직 하나의 demonstration(예시)만 허용
•
사람이 자연어 테스크를 수행하는 방식과 유사
◦
예) 우리는 "이 영화 완전 노잼"이라는 문장을 bad로 분류하라는 하나의 예시만 보더라도, 다른 여러 영화 리뷰에 대해서 "good" 혹은 "bad"로 분류할 수 있음
Zero-shot(0개)
•
demonstration(예시)이 없고, 태스크를 설명하는 자연어 설명(instruction)만 주어짐
•
굉장히 편리하지만 가장 어려우며, 1S과 마찬가지로 사람이 하는 방식과 굉장히 유사
◦
예) 우리는 "I am a boy"라는 문장을 한국어로 번역하라 라는 instruction만 보고서도 "나는 소년이다"라는 문장을 만들어냄
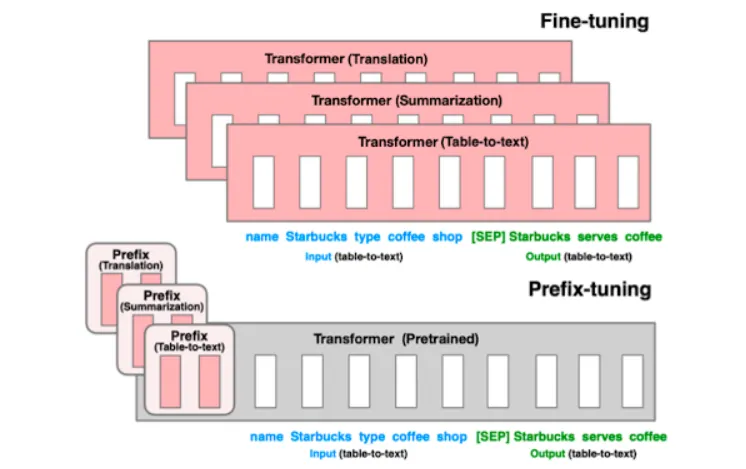
Prefix-Tuning
•
Prefix Tuning은 이전의 연구에서 더 나아가, 인풋의 앞에 prefix, 즉 일련의 연속적인 태스크 특화 벡터(a sequence of continuous task-specific vectors)를 붙이는 방식
•
prefix 뒤에 이어지는 토큰들은 앞에 나온 prefix를 일련의 가상의 토큰인 것처럼 attend
•
prefix는 prompt와는 다르게 실제 토큰(=자연어 단어)과 대응되지 않는 free parameter
•
prefix tuning의 가장 큰 장점은 NLG(자연어 생성) 태스크에서 LM(언어모델)의 파라미터 변경 없이도 모델이 적절한 컨텍스트를 취하도록 할 수 있다는 점
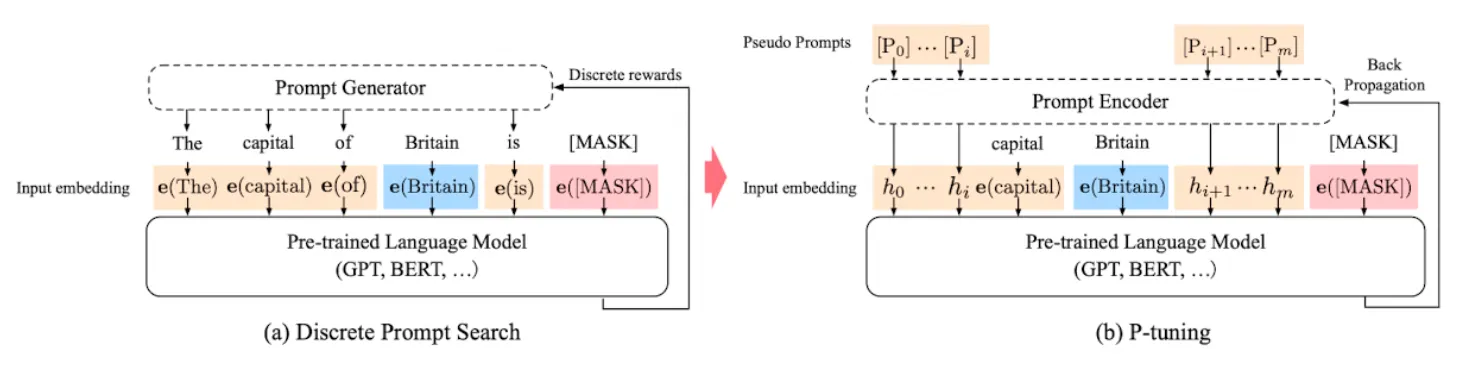
P-Tuning
•
파란색으로 표시된 Britain이 context, 빨간색으로 표시된 [MASK]가 target, 나머지 노란색 부분이 prompt token
•
P-tuning에서는 pseudo prompt와 prompt encoder가 미분가능한 방법으로 최적화
•
이러한 연속적인 토큰에 "수도(capital)"와 같은 태스크와 관련된 앵커 토큰(task-related anchor token)을 추가하면 성능이 더욱 향상
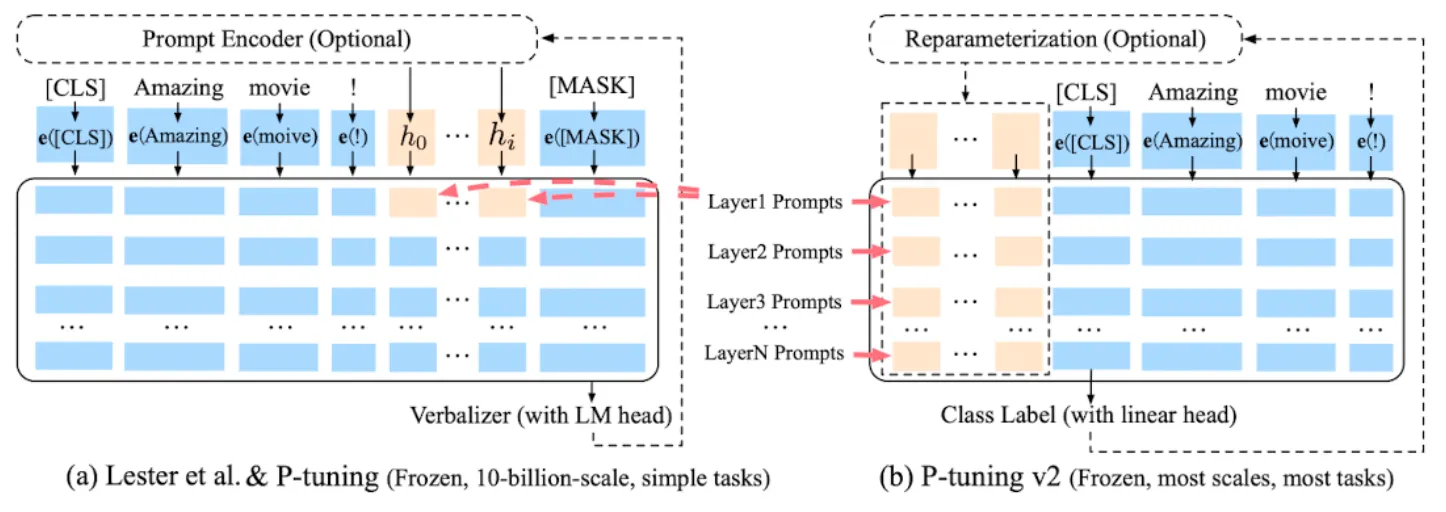
P-tuning v2
•
Prefix tuning은 원래 NLG를 위해 제안되었으나, 이 논문의 저자들은 이 구조가 NLU에도 효과적이라는 사실을 발견
•
P-tuning에서 연속적인 프롬프트는 트랜스포머의 첫 번째 레이어에 인풋 임베딩에 삽입
•
P-tuning v2에서는 prefix tuning처럼 multi-layer prompt(deep prompt tuning), 즉 여러 레이어에 프롬프트를 붙이는 방법을 사용
•
각기 다른 레이어에 위치한 프롬프트는 인풋 시퀀스에 prefix 토큰으로 더해지고, 다른 interlayer들과는 독립적
•
이를 통해 더 많은 수의 태스크 특화 파라미터를 튜닝, 더 깊은 레이어에 더해진 프롬프트를 통해 결과 예측에 더 직접적이고 주요한 영향
Model Tuning
•
기존 모델 튜닝 방식은 각각의 task에 맞게 pre-trained 된 모델들을 모두 fine-tuning하는 방식이었음.
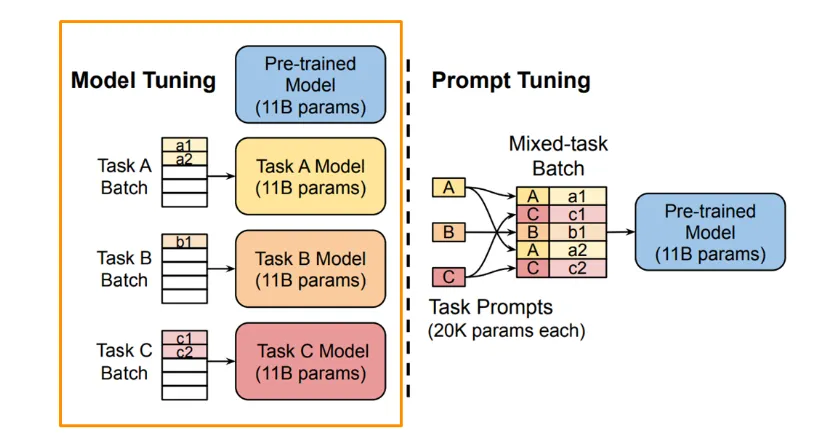
Prompt Tuning
•
input text 의 앞부분에 추가된 additional k 토큰들만 downstream 태스크에서 학습함.
•
각 태스크마다 prompt 들을 저장하여 인퍼런스에서 mixed-task로 사용.
•
GPT3 의 prompt와 달리 기존 트랜스포머 모델 파라미터는 froze 해놓고, prompt 파라미터 update 할 수 있음.
•
프롬프트 엔지니어링의 주요 목표는 사용자의 의도와 원하는 결과를 전달하는 프롬프트를 만들어 모델의 성능, 정확성, 유용성을 극대화하는 것이다.
•
프롬프트 엔지니어링이 필요한 이유는 현재 LLM의 동작 방식의 한계와 인간과 컴퓨터의 상호 작용을 위해 자연어를 사용하고 있기 때문이다.
Prompt Engineering vs Prompt Tuning
•
프롬프트 엔지니어링과 프롬프트 튜닝은 AI 성능과 출력을 최적화하기 위한 보완적 접근 방식으로 두 방식 모두 사용자와 AI 간 상호 작용을 개선하는데 중점을 두고 있다.
•
프롬프트 튜닝과 프롬프트 엔지니어링의 주요 차이점은 프롬프트 튜닝이 더 자동화된다는 것이다.
◦
프롬프트 튜닝을 사용하면 사용자가 프롬프트를 제공하기만 하면 LLM이 나머지 작업을 수행한다.
◦
프롬프트 엔지니어링을 사용하면 사용자가 직접 프롬프트를 설계해야 하므로 더 많은 시간이 소요될 수 있다.
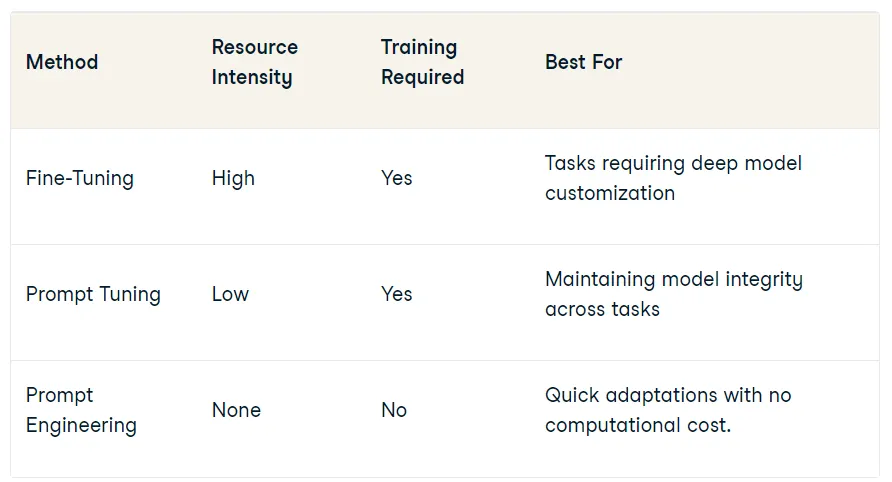
프롬프트 엔지니어링과 프롬프트 튜닝의 장단점
•
프롬프트 엔지니어링
◦
장점: 프롬프트 엔지니어링은 출력을 더 많이 제어할 수 있기 때문에 프롬프트 튜닝보다 좀더 효과적이다.
◦
단점: 프롬프트 엔지니어링은 사람의 입력이 더 많이 필요하기 때문에 프롬프트 튜닝보다 더 많은 시간이 소요된다.
•
프롬프트 튜닝
◦
장점: 프롬프트 튜닝은 더 자동화되어 있기 때문에 프롬프트 엔지니어링보다 빠르고 쉽다.
◦
단점: 프롬프트 튜닝은 출력에 대한 많은 제어를 허용하지 않기 때문에 프롬프트 엔지니어링보다 덜 효과적이다.