


Data Connection(or Index)
•
애플리케이션별 데이터와의 인터페이스
•
많은 LLM 애플리케이션에는 모델 훈련 세트의 일부가 아닌 사용자별 데이터가 필요
•
LangChain은 데이터를 로드, 변환, 저장 및 쿼리할 수 있는 빌딩 블록을 제공
◦
Document loaders: 다양한 소스에서 문서 불러오기
◦
Document transformers: 문서분할, Q&A형식으로 문서 변환, 중복 문서 작세 등 다양한 작업 수행
◦
Text Splitters: 문서가 너무 길어서 LLM에 한 번에 입력이 어려운 경우 사용
◦
Text embedding models: 비정형 텍스트를 float 숫자 목록으로 변환
◦
Vector stores: embedding된 데이터 저장 및 검색
◦
Retrievers: 문자열을 받아서 document 목록을 반환
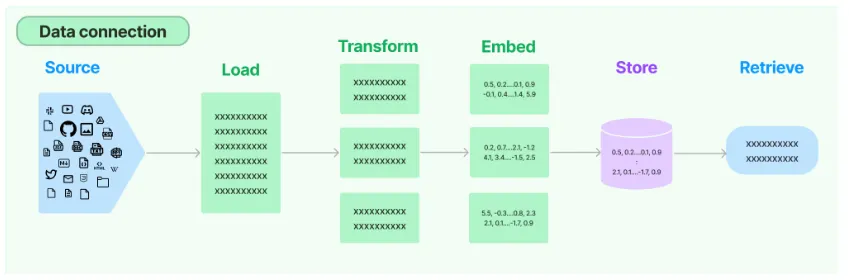
LangChain에서 데이터를 처리하는 전체적인 흐름을 설명하는 도식
1. Source (데이터 소스)
•
설명
◦
데이터 소스는 다양한 형식의 원본 데이터를 의미
◦
여기에는 텍스트 문서, 이미지, 비디오, 오디오, 소셜 미디어 게시물 등 다양한 데이터 형식이 포함된다.
•
예시: PDF 파일, 웹사이트, 트위터 글, 데이터베이스 등.
•
역할: 이 단계는 데이터를 수집하는 역할을 합니다.
2. Load (데이터 로드)
•
설명
◦
데이터를 LangChain으로 불러오는 단계
◦
다양한 소스에서 데이터를 불러오기 위한 Document Loaders가 사용된다.
Document loaders: 여러 소스에서 문서를 불러오는 모듈
예를 들어 웹에서 데이터를 크롤링하거나 PDF 파일을 불러올 때 사용
•
역할: 이 단계는 소스에서 데이터를 가져와 시스템에 로드하는 역할을 한다.
3. Transform (데이터 변환)
•
설명
◦
데이터를 필요한 형태로 변환하는 단계
◦
Document Transformers 및 Text Splitters를 사용하여 문서를 분할하거나, 중복된 내용을 처리하고, 필요에 맞게 데이터를 조정합니다.
Document transformers: 문서를 분할하고, 중복된 데이터를 처리하는 등 다양한 변환 작업을 수행
Text Splitters: 문서가 너무 길어 모델이 한 번에 처리하기 어려울 경우, 문서를 적절한 크기로 분할하는 역할
•
역할: 데이터를 효율적으로 처리할 수 있도록 구조화하고 최적화한다.
4. Embed (임베딩)
•
설명
◦
텍스트를 임베딩(Embedding) 벡터로 변환하는 단계
◦
비정형 텍스트를 수치화하여 벡터 형태로 표현하고, 이를 통해 의미적 유사성을 계산할 수 있다.
Text embedding models: 비정형 텍스트 데이터를 고차원 벡터로 변환하여 임베딩함.
예를 들어, 텍스트 데이터를 숫자의 리스트로 변환하여 컴퓨터가 이해할 수 있는 형태로 만든다.
•
역할: 텍스트 데이터를 숫자로 변환하여 나중에 검색할 수 있도록 준비한다.
5. Store (저장)
•
설명
◦
변환된 임베딩 데이터를 벡터 저장소(Vector Store)에 저장하는 단계
◦
벡터 저장소는 임베딩된 데이터를 효율적으로 저장하고 검색할 수 있는 기능을 제공
Vector stores: 임베딩된 데이터를 저장하고 나중에 빠르게 검색할 수 있는 데이터베이스 역할
•
역할: 임베딩된 데이터를 저장하여 나중에 검색 요청에 사용할 수 있도록 준비한다.
6. Retrieve (검색)
•
설명
◦
검색기(Retriever)가 사용자의 질의에 맞는 데이터를 벡터 저장소에서 검색
◦
검색된 결과는 원본 텍스트나 문서 형식으로 변환
Retrievers: 사용자가 입력한 문자열(질문 또는 키워드)을 받아서 관련된 문서 목록을 반환
•
역할: 벡터 저장소에서 의미적으로 관련된 데이터를 검색하여 사용자에게 전달
