



•
정보 필터링 기술의 일종으로 특정 사용자가 관심을 가질만한 정보(영화, 음악, 책, 뉴스, 이미지, 웹 페이지 등)를 추천하는 것
Cold Start
•
추천 시스템이 새로운 또는 어떤 유저들에 대한 충분한 정보가 수집된 상태가 아니라서 해당 유저들에게 적절한 제품을 추천해주지 못하는 문제
Cold Start가 발생하는 원인
1.
New Community : 여기서 새로운 커뮤니티란, 새로운 서비스가 오픈된 것을 말한다.
2.
New item신제품이 출시된 경우에는 추천 시스템의 종류에 따라 Cold Start가 발생할 수 있다.
3.
New User새로운 유저가 가입했을 때, 신규 유저에 대한 히스토리가 없기 때문에 Cold Start가 발생한다.
Cold Start 해결 방법
•
하이브리드 추천 시스템을 이용하면 어느정도 해결할 수 있다.
•
유저별 히스토리 데이터에 따라 추천 시스템의 종류를 선택적으로 적용한다면 Cold Start에 어느정도 대응을 할 수 있다.
1.
New Community인 겨우, Knowledge-Based Filtering
2.
New item인 경우, Content-Based Filtering
3.
New User인 경우, Knowledge-Based Filtering 또는 비개인화 추천
추천 시스템의 필요성
•
특정 방송사에서 콘텐츠를 생성하는 과거와는 달리 위의 이미지와 같이 유튜브, 왓차, 넷플릭스 등 많은 곳을 통해서 컨텐츠가 생성되고 볼 수 있는 사회에 살고 있다.
•
이러한 사회에서 본인이 정확하게 원하는 컨텐츠를 찾는 것은 점점 힘들어지고 시간이 많이 걸린다고 할 수 있다.
•
이러한 이유로 인하여 유튜브, 넷플릭스, 쿠팡 등 많은 회사에서는 추천 시스템이라는 인공지능 기반 기술을 이용하여 사람들에게 개인화된 컨텐츠를 노출해주고 있다.
•
특히 기존에는 할 수 없던, 고객 개개인에게 맞춤형 서비스를 추천 시스템을 통해 제공함으로써 기업에게는 더 많은 수익 창출을 제공하고, 고객에는 더 높은 만족도를 제공하고 있다.
파레토 법칙 vs 롱테일 법칙
•
파레토 법칙
◦
80 대 20의 법칙
◦
오랫동안 대중적인 마케팅 기법으로 인식되어 왔다.
◦
그러나 인터넷의 발전으로 리테일 부문에서 온라인 시장의 규모가 급성장했다.
•
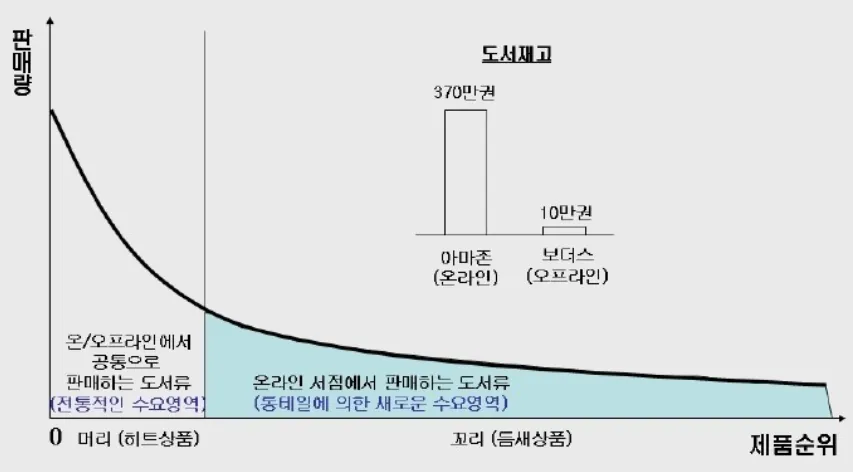
롱테일 법칙
◦
주목받지 못하는 다수가 핵심적인 소수보다 더 큰 가치를 창출하는 현상
◦
주력상품 외에도 다양한 고객의 니즈에 부응하기 위해 판매하는 상품들이 늘어나게 되고 C그룹에 속하는 상품들은 계속해서 증가한다.
◦
전통적으로 소홀히 취급되어 왔던 파레토 분포상에서 긴 꼬리에 해당하는 틈새 상품도 기업의 매출에 매우 큰 영향력을 발휘할 수 있게 되었다.
•
추천 시스템을 통해서 긴 꼬리에 해당하는 다품종 소량 생산품들을 필요한 소비자들에게 적절하게 추천을 할 수 있게 되었다.

'사소한 다수와 중요한 소수가 문제의 원인으로 우리 주변에서 일어나는 많은 현상의 80%는 20%의 중요한 원인 때문에 발생한다는 것'
•
상위 20% 고객이 전체 수익의 80%를 올려 준다.
•
20%의 우수한 사원이 회사 전체 매출의 80%를 이끈다.
•
회사 핵심 제품 20%가 전체 매출의 80%를 담당한다. 등

‘80%의 사소한 다수가 20%의 핵심 소수보다 더 뛰어난 성과를 창출한다는 것’
•
개별 매출액은 작지만 이들을 모두 합하면 히트상품 못지 않은 매출을 올릴 수 있는 틈새상품의 영역을 말하는 것
•
기존에는 파레토법칙과 같은 수백만개씩 팔리는 상품을 개발하려는 사고방식이었다면 앞으로는 기존 패러다임에서 사소한 것으로 간주되었던 나머지 80%가 점점 부각될 것이다라는 것이 핵심이다.
추천 시스템 분류
시나리오에 따른 분류
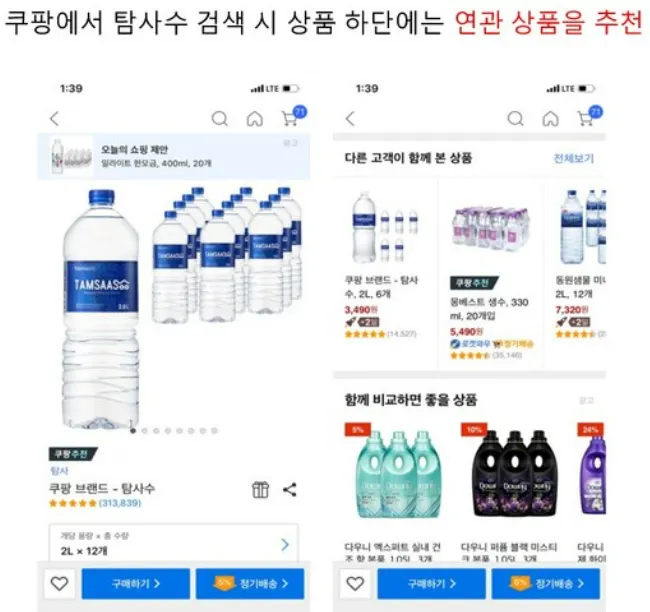
연관된 아이템 추천
•
현재 소비되고 있는 아이템과 연관된 아이템을 추천
개인화 아이템 추천
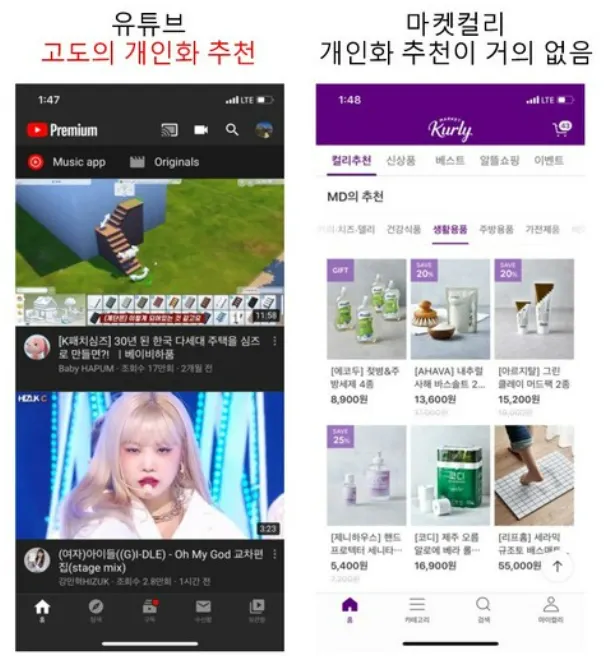
•
소비중인 아이템이 없더라도, 개인의 관심사를 찾아 소비할 만한 아이템을 추천
피드백 종류에 따른 분류
Explicit feedback(명시적 피드백) 추천
•
명백한, 외재적인 피드백
•
별점, 좋아요/싫어요 등
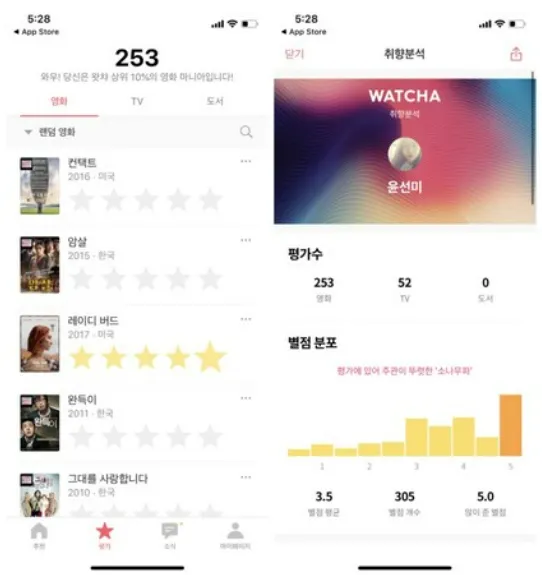
Implicit feedback(암시적 피드백) 추천
•
은영중인, 내재적인 피드백
•
뉴스 클릭 수, 검색 기록, 페이지 유지 시간 등
추천 알고리즘
•
추천 시스템은 보통 개인의 취향에 맞춰 상품이나 콘텐츠를 추천해주는 알고리즘을 생각할 수 있지만, 사용자 개인에 대한 정보가 없는 경우에는 인기도 기반 추천/조회수 기반 추천/평점 기반 추천 등을 이용할 수 있다.
인기도 기반 추천
•
말 그대로 가장 인기있는 아이템을 추천하는 것을 의미한다.
•
하지만 "인기"는 추상적인 개념이라 이를 평가할 수 있는 지료로 좋아요/싫어요 수, 리뷰 수, 평균 평점 등을 사용할 수 있다.

조회 수 기반 추천 (Most Popular)
•
사용자는 뉴스를 볼 때 핫한 이슈이면서도 최근 소식을 보기를 원한다.
•
따라서, 조회수와 날짜를 조합한 점수를 만들면 사용자에게 최근에 작성된 따끈따끈하고 핫한 뉴스를 추천할 수 있다.
•
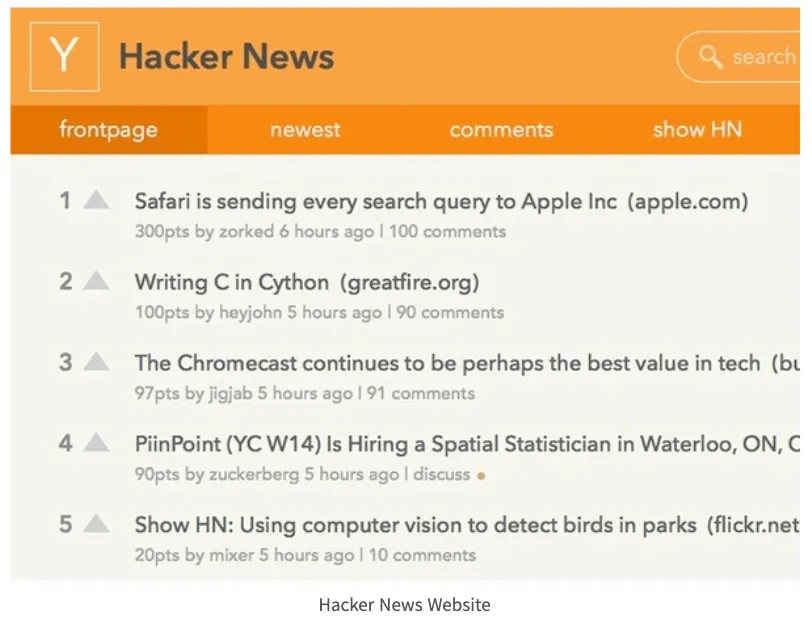
아래는 IT 뉴스 서비스 웹사이트인 'Hacker News'와 소셜 뉴스 웹사이트인 'Reddit'에서 사용하는 뉴스 추천 알고리즘이다.
•
Hacker News의 점수화 알고리즘
◦
pageviews:해당 뉴스의 조회수, 1을 빼는 이유는 기사 작성자의 조회수를 제거하기 위함
◦
age:뉴스 업로드 날짜로부터 현재까지 지난 기간(Hours)를 의미
◦
gravity:age가 커질수록 분모를 얼마나 더 크게 증가시킬 것인지 설정하는 상수
Hacker News에서는 gravity 값을 1.8로 설정
◦
조회수가 높을수록 점수가 높아지지만, 시간이 지남에 따라 오래된 뉴스는 조회수가 높더라도 낮은 점수를 갖게 된다. 그리고 중렬 상수가 클수록 시간의 흐름에 더 많은 영향을 받게 된다.
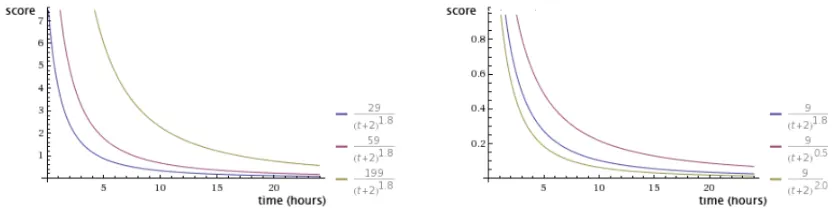
조회수와 중력 상수 값에 따른 변화
평점 기반 추천 (Highly Rated)
•
평점은 점수를 세분화하여 다양한 아이템 간의 비교를 용이하게 한다는 점에서 좋은 지표지만, 평가받은 빈도를 고려하지 못 한다는 단점이 있다.
•
각각 5번과 500번의 평가를 받은 두 아이템의 평점이 같은 5점일 때, 우리는 두 개의 5점을 다르게 받아들일 것이다.
•
충분히 많으 수의 평가를 받은 아이템에 더 신뢰가 갈 것이다.
•
이처럼 평점뿐만 아니라 신뢰성을 함께 고려하는 것이 중요하다.
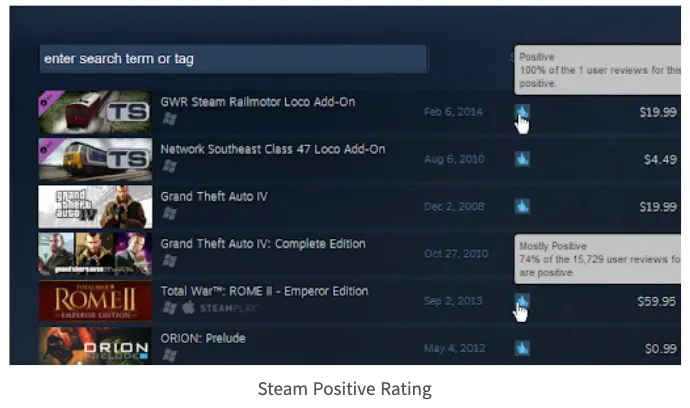
게임 플랫폼 'Steam'의 게임 랭킹 알고리즘
게임의 순위를 매길 때 평균 긍정률(avg rating)을 사용한다.
•
리뷰 수가 충분히 많은 경우에는 두번째 텀이 0으로 수렴하게 되면서 평균 긍정률을 거의 그대로 점수에 반영한다. (로그함수에 마이너스를 취함으로써 리뷰 수가 높아지면 0에 수렴한다.)
•
하지만 리뷰 수가 적은 경우에는 두번째 텀이 점수를 보정하는 역할을 한다.
◦
평점이 0.5보다 낮은 경우, 두번째 텀이 음수가 되면서 점수를 높게 만들고,
◦
반대로 평점이 높은 경우 두번째 텀이 양수가 되면서 낮게 보정해준다.
•
0.5는 Steam에서 사용하는 점수가 0 또는 1이라 이 둘의 가운데 값인 0.5를 사용한 것이다.
•
Steam Rating Formula
•
Movie Rating Formula
Content-Based Filtering: CBF
•
추천하고자 하는 분야의 도메인 지식을 활용해 추천하는 방식
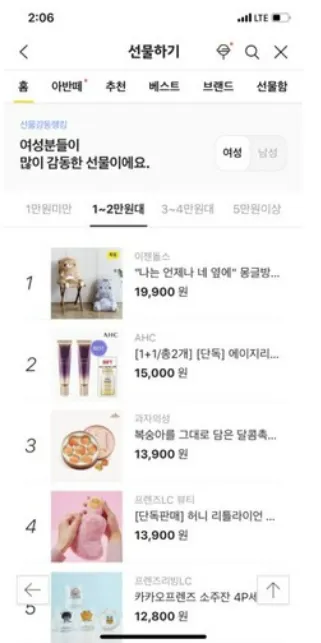
카카오톡 선물하기
•
사용자가 과거에 좋아했던 아이템들의 특징을 분석하여, 유사한 특징을 가진 새로운 아이템을 추천한다.
성별/연령별로 많이 팔리는 상품들을 모아 추천에 활용
•
추천 과정
1.
특징 추출
•
각 아이템의 고유한 속성을 벡터 형태로 표현한다.
영화라면 벡터 = [액션: 1, 코미디: 0, 드라마: 1] 처럼 다룰 수 있다.
2.
사용자 프로필 생성
•
사용자가 평가하거나 좋아한 아이템의 벡터들을 평균 또는 가중 평균하여 사용자 프로필을 만든다.
•
사용자 프로필 벡터는 사용자가 선호하는 특성을 나타낸다.
3.
유사도 계산
•
추천할 아이템과 사용자 프로필 간의 유사도를 계산한다.
•
일반적으로 코사인 유사도(Cosine Similarity)를 사용한다.
4.
추천 제공
•
유사도가 높은 아이템을 사용자에게 추천한다.
•
장점
◦
개인화 - 사용자의 고유한 선호를 기반으로 하기 때문에 맞춤화된 추천이 가능하다.
◦
새로운 사용자 문제 해결 - 사용자가 선호도를 제공하면 즉시 추천이 가능하다.
•
단점
◦
새로운 아이템 문제 - 사용자가 기존에 평가한 적 없는 새로운 아이템은 추천하기 어렵다.
◦
편향 - 사용자가 선호했던 카테고리에만 국한되어 다양성이 부족할 수 있다.
Knowledge-Based Filtering: KBF
•
사용자가 과거에 선호했던 아이템(예: 영화, 책, 음악 등)의 특성을 기반으로 새로 추천할 아이템을 선택하는 방식
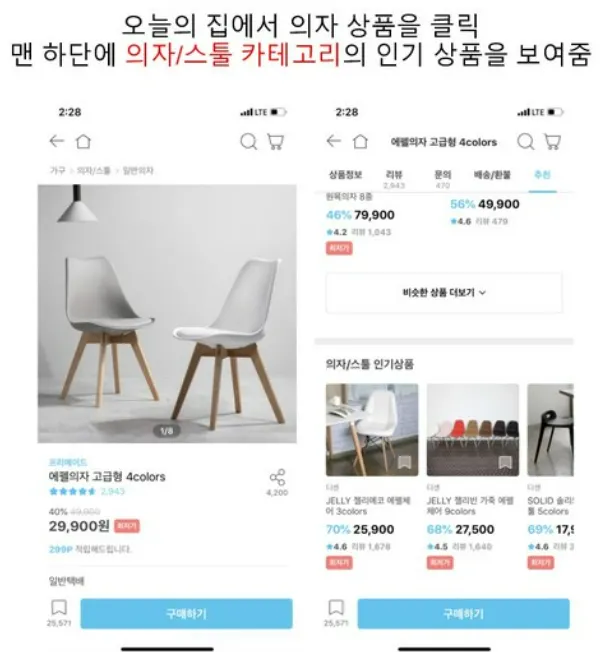
사용자의 명시적인 요구사항과 도메인 지식을 활용하여 적합한 아이템을 추천하는 방식
•
사용자 선호도뿐 아니라 전문가의 지식이나 아이템의 특성과 사용자의 요구사항 간의 관계를 정의하여 추천한다.
상품 페이지 하단에 같은 카테고리에 있는 인기 상품 추천
•
추천 시스템이 도메인 지식과 규칙(예: "A라는 속성을 가진 상품은 B 속성도 함께 있어야 한다")을 이용해 추천을 제공한다.
•
추천 과정
1.
요구사항 정의
•
사용자가 특정한 요구를 명시적으로 입력하거나, 기존의 구매/선호 데이터를 바탕으로 요구사항을 추론한다.
여행 추천에서는 "해변 근처 호텔"과 같은 조건이 요구사항이 된다.
2.
규칙 및 제약 적용
•
도메인 지식을 바탕으로 사용자 요구사항에 맞는 필터링을 적용한다.
"이용 가능한 방이 있는 호텔 중 가격이 $100 이하" 같은 규칙.
3.
아이템 추천
•
요구사항과 규칙을 만족하는 아이템들만 추천 리스트에 포함한다.
•
장점
◦
설명 가능성 - 추천 결과에 대한 이유를 명확히 설명할 수 있다.
◦
복잡한 요구사항 처리 - 사용자 요구사항이 복잡한 경우에도 적합하다.
◦
새로운 사용자 문제 해결 - 사용자의 과거 기록이 없어도 요구사항만으로 추천 가능하다.
•
단점
◦
규칙 설계의 복잡성 - 도메인 지식을 모델링하는 데 많은 시간과 노력이 필요하다.
◦
확장성 부족 - 규칙이 너무 세밀하거나 고정적일 경우 추천의 유연성이 떨어진다.
Collaborative Filtering: CF
•
협업 필터링(Collaborative Filtering)은 많은 사용자로부터 수집한 구매 패턴이나 평점을 기반으로 하여 다른 사용자에게 콘텐츠를 추천해 주는 방법
•
사용자들 간의 협업 데이터를 활용하여 추천을 제공하는 방식
•
"같은 아이템을 좋아하는 사람들은 다른 아이템도 비슷하게 좋아할 가능성이 높다"는 가정에 기반하여 추천을 수행한다.
집단 지성의 개념과 매우 유사하다고 볼 수 있다.
Memory-Based Algorithm
•
과거의 데이터(메모리)에 직접 접근하여 유사성을 계산하고, 이를 기반으로 예측이나 결정을 내리는 방법
자주 쓰이는 Similarity(유사도)
코사인 유사도 (Cosine Similarity)
* 평균 제곱 차이 유사도 (Mean Squared Difference Similarity)
피어슨 유사도 (Pearson Similarity)
•
user와 item의 데이터를 직접적으로 연관시키고 추천하기 때문에 설명성이 높고 적용이 용의하다.
•
히지만, 추천 결과를 생성할 때마다 많은 연산이 필요하다.
→ sparse한 data인 경우 성능이 저하되고(cold start 문제) 쉽게 확장할 수 없다.
•
User-Based Collaborative Filtering
◦
비슷한 평가 패턴을 가진 사용자들을 찾아 그들의 평가 정보를 기반으로 새로운 추천을 생성하는 방식

▪
행: 사용자
▪
열: 아이템(영화), 특정 영화의 평점 데이터를 포함
▪
값: 사용자가 각 영화에 대해 평가한 평점
첫 번째 사용자는 Sherlock에 대해 평점 2를 부여.
▪
빈 칸 (NA): 해당 사용자가 평가하지 않은 아이템 (≒ 예측해야 할 대상)

▪
sim(u, v)
•
사용자 간의 유사도
•
유사도 계산을 통해 각 사용자가 다른 사용자와 얼마나 비슷한지를 나타내는 값이 포함
◦
예측된 평점
▪
원본 데이터에서 빈칸(NA)으로 나타난 부분에 대해 예측된 평점이 계산됨.
다섯 번째 사용자가 셜록을 평가하지 않았지만, 유사한 사용자의 평가 데이터를 기반으로 3.51로 예측되었다.
•
: 사용자 u와 유사도가 높은 이웃 사용자들의 집합
•
: 사용자 v가 아이템 j에 부여한 평점
•
: 사용자 v의 전체 평점의 평균
▪
여기서 사용자 와 의 유사도는 다음과 같이 계산된다.
•
: 사용자 u와 v가 모두 평가한 아이템들의 집합
•
: 사용자 u가 아이템 i에 부여한 평점
•
: 사용자 u의 전체 평점의 평균
Model-Based Algorithm
•
수집된 데이터를 학습하여 예측 모델을 구축하고, 이를 통해 새로운 데이터에 대한 예측이나 결정을 내리는 방법
◦
수집된 데이터를 기반으로 통계적 모델이나 머신러닝 모델을 학습하여 사용자와 아이템의 잠재 요인을 추정한다.
◦
학습된 모델을 활용하여 사용자가 상호작용하지 않은 아이템에 대한 평점을 예측하거나, 선호도를 기반으로 아이템을 추천한다.
•
잠재 요인(Latent Factor) 협업 필터링 방법은 현재에도 자주 쓰이는 방법
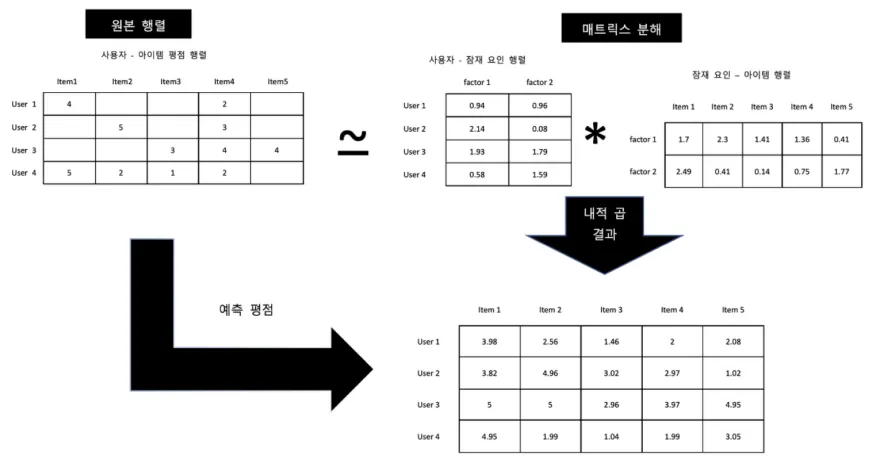
•
user와 item 간의 평점 행렬 속에 숨어 있는 잠재 요인 행렬을 추출하여 내적 곱을 통해 사용자가 평가하지 않은 항목들에 대한 평점까지 예측하여 추천하는 방법
•
행렬 분해(Matrix Factorization)라는 방법을 통해 큰 다차원 행렬을 차원 감소시키는 과정에서 행렬에 포함되어 있는 잠재 요인을 추출할 수 있다.
Memory-Based vs Model-Based
특징 | 메모리 기반 알고리즘 | 모델 기반 알고리즘 |
데이터 활용 방식 | 과거 데이터 직접 활용 | 데이터 학습 후 모델 활용 |
유사도 계산 | 사용자/아이템 간 유사도 | 잠재 요인 기반 유사도 |
실시간 업데이트 | 용이 | 모델 재학습 필요 |
확장성 | 제한적 | 우수 |
예측 정확도 | 중간 | 높음 |
설명력 | 높음 | 낮음 |
•
메모리 기반 알고리즘은 단순하고 직관적이지만, 데이터 희소성 문제와 확장성에 한계가 있다.
•
반면, 모델 기반 알고리즘은 복잡한 패턴을 학습하여 높은 예측 정확도를 제공하지만, 모델 학습에 시간이 소요되고 추천 결과의 해석이 어려울 수 있다.
Hybrid Recommender System
•
컨텐츠 기반 추천시스템과 협업 필터링을 결합한 모델
•
두 가지 알고리즘을 모두 적용하여 아이템마다 가중평균을 구해 랭킹을 구하는 방법
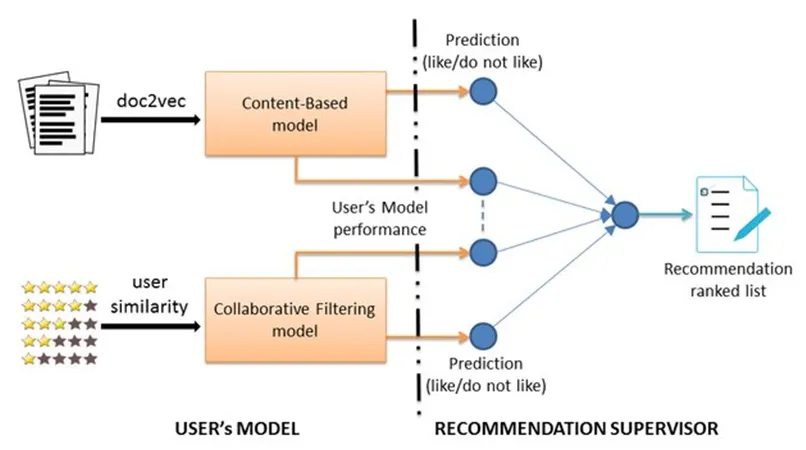
•
한계 개선
◦
콘텐츠 기반 필터링의 한계
▪
사용자의 기존 선호도에만 의존하므로 추천의 다양성이 부족할 수 있다.
▪
아이템의 특징을 정확하게 추출하기 어려운 경우가 있다.
◦
협업 필터링의 한계
▪
신규 사용자나 아이템에 대한 정보가 부족한 경우 추천이 어려운 Cold Start 문제가 발생한다.
▪
데이터가 희소한 경우 추천의 정확도가 떨어질 수 있다.
가중치 혼합(Weighted Hybrid)
•
여러 추천 알고리즘의 결과에 가중치를 부여하여 최종 추천을 생성하는 방식
◦
계산식
▪
: 사용자 에 대해 아이템 의 최종 예측 평점
▪
: 알고리즘 의 에 대한 예측 평점
▪
: 알고리즘 에 할당된 가중치 ()
▪
: 결합된 알고리즘의 총 개수
◦
계산 과정
1.
각 알고리즘()의 결과를 독립적으로 계산.
2.
알고리즘 별 가중치()를 설정 (성능에 따라 동적 설정 가능).
3.
가중치 기반 합산을 통해 최종 추천 생성.
•
각 알고리즘의 신뢰도나 성능에 따라 가중치를 설정하며, 이를 통해 다양한 알고리즘의 장점을 조합할 수 있다.
콘텐츠 기반 필터링 결과에 70%, 협업 필터링 결과에 30%의 가중치를 부여하여 결합할 수 있다.
스위칭(Switching)
•
상황이나 사용자 특성에 따라 적절한 추천 알고리즘을 선택하여 적용하는 방식
◦
조건부 함수
▪
: 콘텐츠 기반 필터링(Content-Based Filtering)의 결과
▪
: 협업 필터링(Collaborative Filtering)의 결과
◦
구현 과정
1.
사용자 상태 (예: 신규 사용자, 평가 데이터 부족 등)를 분석.
2.
조건에 따라 알고리즘 선택.
3.
선택된 알고리즘을 실행하여 추천 생성.
신규 사용자에게는 콘텐츠 기반 필터링을, 기존 사용자에게는 협업 필터링을 적용할 수 있다.
캐스케이드(Cascade)
•
한 추천 알고리즘의 결과를 다른 알고리즘의 입력으로 사용하여 단계적으로 추천을 개선하는 방식
◦
단계적 필터링
▪
: 협업 필터링(CF)을 통해 생성된 상위 N개의 후보군
▪
: 콘텐츠 기반 필터링(CBF)을 사용해 후보군을 재정렬한 최종 추천
◦
필터링 과정
1.
첫 번째 알고리즘에서 상위 N개 후보를 선정 ().
2.
두 번째 알고리즘이 후보군을 세밀히 평가.
3.
최종 추천 리스트() 생성.
•
초기 알고리즘이 후보 아이템을 선정하고, 후속 알고리즘이 이를 정교하게 필터링하거나 순위를 매긴다.
협업 필터링으로 후보 아이템을 선정한 후, 콘텐츠 기반 필터링으로 최종 추천을 생성할 수 있다.
피처 보강(Feature Augmentation)
•
한 알고리즘의 출력을 다른 알고리즘의 입력 특징으로 사용하여 추천의 정확도를 높이는 방식
◦
특징 수식
▪
: 협업 필터링으로 생성된 사용자 u의 특징 벡터
▪
: 사용자 u의 평가 기록
▪
: 아이템 i의 콘텐츠 특징 벡터
▪
: 콘텐츠 기반 필터링 함수
◦
생성 과정
▪
협업 필터링으로 사용자 특징 벡터 생성 ().
▪
콘텐츠 기반 필터링이 이를 입력으로 사용해 추천 생성.
•
알고리즘 간의 상호 보완 효과를 극대화할 수 있다.
협업 필터링으로 사용자 프로필을 생성하고, 이를 콘텐츠 기반 필터링의 입력으로 사용할 수 있다.
