



•
대규모 언어 모델(LLM)을 기반으로 애플리케이션을 구축하기 위한 오픈 소스 프레임워크
•
LLM은 대량의 데이터로 사전 훈련된 대규모 딥 러닝 모델로서, 질문에 답하거나 텍스트 기반 프롬프트에서 이미지를 생성하는 등 사용자 쿼리에 대한 응답을 생성할 수 있다.
•
LangChain은 모델이 생성하는 정보의 맞춤화, 정확성 및 관련성을 개선하기 위한 도구와 추상화 기능을 제공한다.
◦
예를 들어 개발자는 LangChain 구성 요소를 사용하여 새 프롬프트 체인을 구축하거나 기존 템플릿을 맞춤화할 수 있다.
◦
또한 LangChain에는 LLM이 재훈련 없이 새 데이터 세트에 액세스할 수 있도록 하는 구성 요소도 포함되어 있다.
•
인공지능(AI)이 산업과 일상생활을 빠르게 변화시키고 있는 세상에서 기술 발전의 선두에 선다는 것은 그 어느 때보다 중요하다.
•
수많은 혁신 중에서 Langchain은 우리가 AI와 상호 작용하고 활용하는 방식에 혁명을 일으킬 준비가 되어 있는 획기적인 프레임워크로 부상하고 있다.
•
기술과 지능이 독창적으로 결합된 Langchain은 AI 환경의 등대 역할을 한다.
◦
이는 언어 모델을 활용하는 방법에 대한 새로운 패러다임이다.
◦
현재 표준을 훨씬 뛰어넘는 기능을 확장한다.
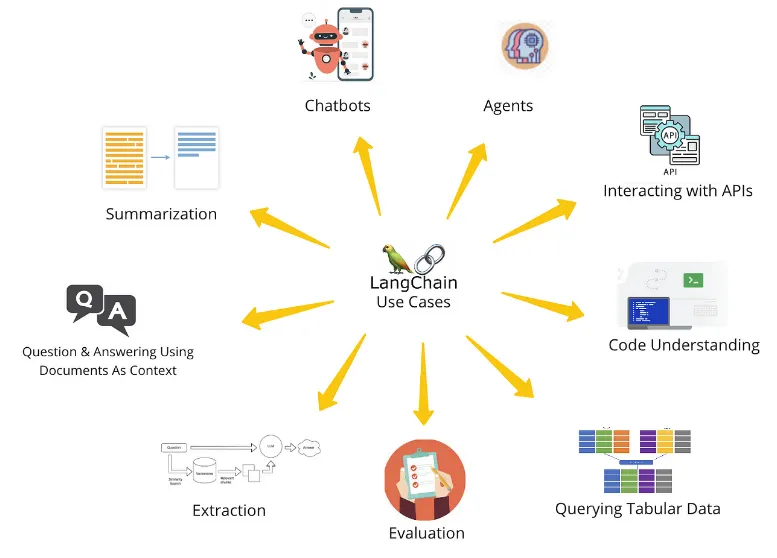
•
언어모델 학습시 사용된 데이터 외에 새로운 사용자 데이터를 인식할 수 있게 함
•
여러가지 LLM 언어모델을 선택적으로 사용할 수 있게 함
•
능동적으로 다른 기능과 연동하여 추가적인 결과를 낼 수 있게 함
•
여러 기능 모듈을 체인으로 연결하여 출력을 다른 툴의 입력으로 사용하는 방식으로 기능 확장이 자유로움
•
라이브러리 wrap이 잘되어 있어서 구현이 상대적으로 편함(파이썬, 자바스크립트)
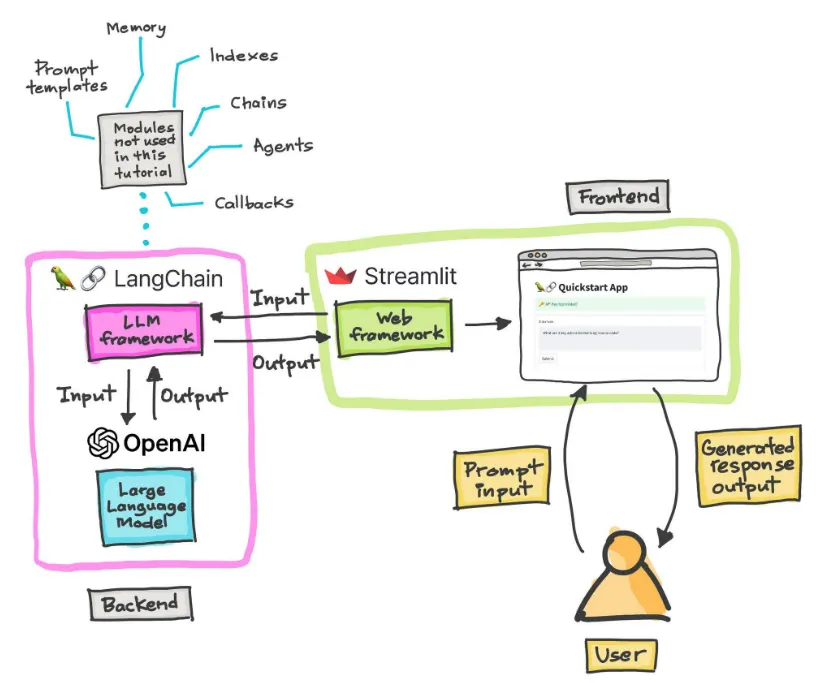
1. Backend (백엔드)
•
LangChain
◦
설명: LangChain은 대형 언어 모델과 상호작용할 수 있는 다양한 도구와 모듈을 제공하는 프레임워크이다.
◦
구성 요소:
▪
Prompt templates: 입력 프롬프트를 구조화하거나 특정 작업에 맞게 템플릿화하여 모델에 전달.
▪
LLM framework: 대형 언어 모델(LLM)과의 상호작용을 관리하는 프레임워크.
▪
Modules not used in this tutorial: 그림에서 언급된 다른 모듈(예: 메모리, 인덱스, 체인, 에이전트 등)은 이 튜토리얼에서는 사용되지 않지만, 다양한 기능을 추가적으로 지원할 수 있음.
◦
OpenAI API와의 통합:
▪
OpenAI: 이 프레임워크는 OpenAI의 대형 언어 모델(예: GPT 시리즈)과 통합된다. OpenAI API를 통해 입력을 받아 출력을 생성한다.
▪
Input/Output: LangChain은 사용자 입력을 받아 OpenAI 모델로 전달하고, 모델에서 생성된 응답을 다시 받아서 처리한다.
2. Frontend (프론트엔드)
•
Streamlit
◦
설명: Streamlit은 간단한 웹 애플리케이션을 만들기 위한 프레임워크로, 이 예시에서는 LangChain과 통합하여 사용자 인터페이스(UI)를 제공한다.
◦
구성 요소:
▪
Web framework: Streamlit은 웹 프레임워크로서 LangChain에서 생성된 응답을 웹 애플리케이션 형태로 사용자에게 보여준다.
▪
Quickstart App: 애플리케이션 화면에서 사용자가 입력할 수 있는 텍스트 상자와 모델의 응답을 확인할 수 있는 인터페이스가 제공된다.
3. User Interaction (사용자와의 상호작용)
•
사용자 입력 (Prompt Input): 사용자는 Streamlit 애플리케이션을 통해 프롬프트(질문 또는 요청)를 입력한다.
•
LangChain과의 상호작용: 프롬프트는 LangChain의 LLM 프레임워크로 전달되어 OpenAI 모델에 입력된다.
•
생성된 응답 (Generated response output): 모델이 생성한 응답은 다시 LangChain을 통해 Streamlit에 전달되고, 사용자는 웹 인터페이스에서 이 결과를 확인할 수 있다.
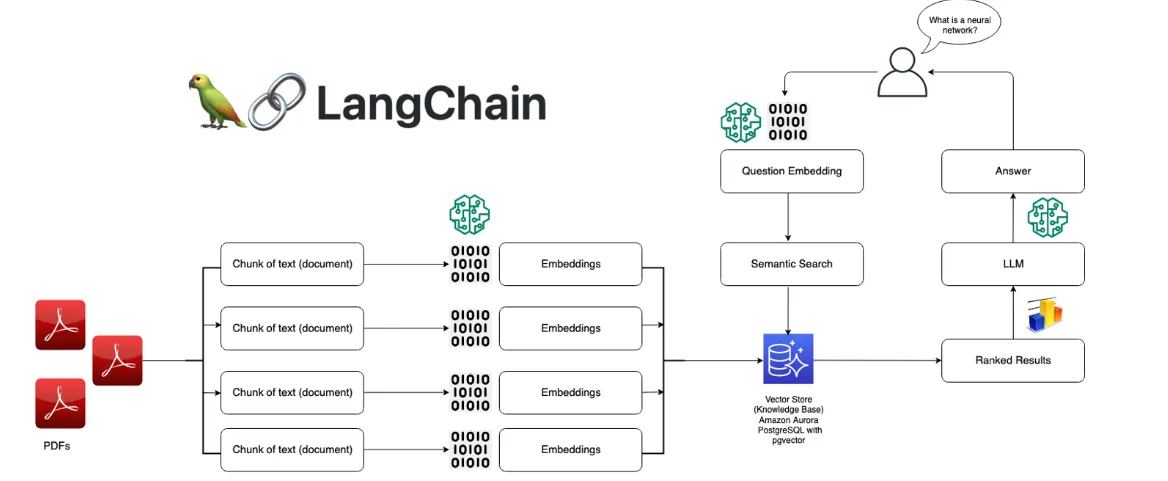
PDF 문서에서 정보를 검색하고, 이를 대형 언어 모델(LLM)을 통해 처리하여 질문에 답변하는 과정
•
전체적으로 PDF 파일에서 텍스트를 추출하고, 해당 텍스트를 임베딩(벡터)로 변환한 후, 질문과 관련된 내용을 검색하는 시맨틱 검색(Semantic Search)을 통해 대답을 제공하는 과정
1. PDF 문서 처리
•
PDFs (입력): 여러 PDF 파일들이 입력으로 제공된다.
•
Chunk of text (문서 텍스트 분할): PDF 문서가 길기 때문에, 각 문서는 여러 부분으로 나뉘어 텍스트 청크(chunk) 단위로 처리된다. 이 과정은 대규모 문서를 효율적으로 처리하기 위한 전처리 단계이다.
2. 임베딩 생성 (Embedding Generation)
•
Embedding: 각 텍스트 청크는 언어 모델에 의해 임베딩(Embedding)으로 변환된다. 임베딩은 고차원 벡터 표현으로, 문서의 의미를 벡터 공간에서 나타낸다.
◦
임베딩 벡터는 이후의 시맨틱 검색에서 중요한 역할을 한다. 각 청크가 고유한 벡터로 표현되어 나중에 의미적 유사성을 기준으로 검색될 수 있다.
3. 벡터 저장소 (Vector Store)
•
Vector Store (벡터 저장소): 생성된 임베딩 벡터는 벡터 저장소에 저장된다. 이는 데이터베이스처럼 작동하며, 각 텍스트 청크에 해당하는 임베딩 벡터가 저장되고 나중에 검색된다.
◦
예시로는 Amazon Aurora나 PostgreSQL을 사용하여 벡터 저장소를 구성할 수 있으며, 여기에 pgvector 확장을 통해 임베딩 벡터를 저장 및 검색할 수 있다.
4. 질문 임베딩 생성 (Question Embedding)
•
Question Embedding: 사용자가 질문을 입력하면, 이 질문도 임베딩 벡터로 변환된다.
◦
예시: 사용자가 "What is a neural network?"라는 질문을 입력하면, 이 질문도 벡터로 변환되어 문서 임베딩과 비교할 수 있게 된다.
5. 시맨틱 검색 (Semantic Search)
•
Semantic Search: 질문 임베딩과 문서 임베딩 간의 의미적 유사성을 기반으로 검색이 이루어진다.
◦
벡터 저장소에서 질문과 가장 유사한 임베딩 벡터(즉, 텍스트 청크)를 찾아내는 과정이다. 이는 전통적인 키워드 기반 검색과 달리, 의미적 유사성을 고려한 검색 방식이다.
◦
검색된 결과는 관련성에 따라 Ranked Results (순위화된 결과)로 제공된다.
6. 대형 언어 모델(LLM)과 답변 생성
•
LLM (대형 언어 모델): 시맨틱 검색에서 나온 관련 텍스트 청크는 LLM으로 전달되어, 질문에 대한 최종적인 답변이 생성된다.
◦
예를 들어, 검색된 텍스트 청크를 바탕으로 "What is a neural network?"라는 질문에 대한 답변을 생성한다.
•
Answer (답변): LLM이 생성한 답변이 사용자에게 제공된다.
