



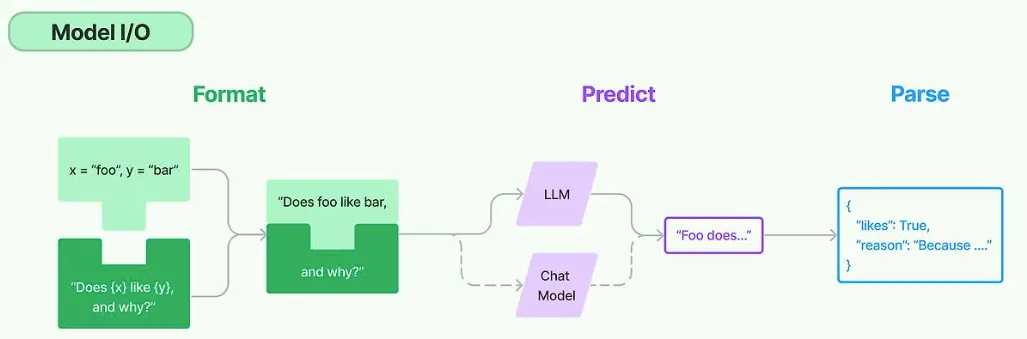
Model
•
랭체인 문서에 따르면 LLM과 Chat Model 클래스는 각각 다른 형태의 입력과 출력을 다루는 언어 모델을 나타낸다.
•
이 두 모델은 각기 다른 특성과 용도를 가지고 있어, 사용자의 요구사항에 맞게 선택하여 사용할 수 있다.
•
일반적으로 LLM은 주로 단일 요청에 대한 복잡한 출력을 생성하는 데 적합한 반면, Chat Model은 사용자와의 상호작용을 통한 연속적인 대화 관리에 더 적합하다.
Large Language Models (LLMs)
•
기능
◦
LLM 클래스는 텍스트 문자열을 입력으로 받아 처리한 후, 텍스트 문자열을 반환
◦
이 모델은 광범위한 언어 이해 및 텍스트 생성 작업에 사용된다.
◦
예를 들어, 문서 요약, 콘텐츠 생성, 질문에 대한 답변 생성 등 복잡한 자연어 처리 작업을 수행할 수 있다.
•
예시
◦
사용자가 특정 주제에 대한 설명을 요청할 때, LLM은 주어진 텍스트 입력을 바탕으로 상세한 설명을 생성하여 반환할 수 있다.
LLM 인터페이스 특징
•
표준화된 인터페이스
◦
랭체인의 LLM 클래스는 사용자가 문자열을 입력으로 제공하면, 그에 대한 응답으로 문자열을 반환하는 표준화된 방식을 제공한다.
◦
이는 다양한 LLM 제공 업체 간의 호환성을 보장하며, 사용자는 복잡한 API 변환 작업 없이 여러 LLM을 쉽게 탐색하고 사용할 수 있다.
•
다양한 LLM 제공 업체 지원
◦
랭체인은 OpenAI의 GPT 시리즈, Cohere의 LLM, Hugging Face의 Transformer 모델 등 다양한 LLM 제공 업체와의 통합을 지원한다.
◦
이를 통해 사용자는 자신의 요구 사항에 가장 적합한 모델을 선택하여 사용할 수 있다.
•
코드
Chat Model
•
기능
◦
Chat Model 클래스는 메시지의 리스트를 입력으로 받고, 하나의 메시지를 반환한다.
◦
이 모델은 대화형 상황에 최적화되어 있으며, 사용자와의 연속적인 대화를 처리하는 데 사용됨
◦
Chat Model은 대화의 맥락을 유지하면서 적절한 응답을 생성하는 데 중점을 둔다.
•
예시
◦
사용자가 챗봇과 대화하는 상황에서, 사용자의 질문과 이전 대화 내용을 고려하여 적절한 답변을 생성
Chat Model 인터페이스 특징
•
대화형 입력과 출력
◦
Chat Model은 대화의 연속성을 고려하여 입력된 메시지 리스트를 기반으로 적절한 응답 메시지를 생성한다.
◦
챗봇, 가상 비서, 고객 지원 시스템 등 대화 기반 서비스에 어울린다.
•
다양한 모델 제공 업체와의 통합
◦
랭체인은 OpenAI, Cohere, Hugging Face 등 다양한 모델 제공 업체와의 통합을 지원합니다.
◦
이를 통해 개발자는 여러 소스의 Chat Models를 조합하여 활용할 수 있습니다.
•
다양한 작동 모드 지원
◦
랭체인은 동기(sync), 비동기(async), 배치(batching), 스트리밍(streaming) 모드에서 모델을 사용할 수 있는 기능을 제공합니다.
◦
다양한 애플리케이션 요구사항과 트래픽 패턴에 따라 유연한 대응이 가능합니다.
•
코드
# 프롬프트 생성
chat_prompt = ChatPromptTemplate.from_messages([
("system", "이 시스템은 여행 전문가입니다."),
("user", "{user_input}"),
])
chat_prompt
ChatPromptTemplate(input_variables=['user_input'], input_types={}, partial_variables={}, messages=[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=[], input_types={}, partial_variables={}, template='이 시스템은 여행 전문가입니다.'), additional_kwargs={}), HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['user_input'], input_types={}, partial_variables={}, template='{user_input}'), additional_kwargs={})])
Python
복사
LLM 파라미터 설정
•
LLM 모델의 기본 속성값을 조정하는 방법
•
모델의 속성에 해당하는 모델 파라미터는 LLM의 출력을 조정하고 최적화하는데 사용되며, 모델이 생성하는 텍스트의 스타일, 길이, 정확도 등에 영향을 주게 된다.
•
사용하는 모델이나 플랫폼에 따라 세부 내용은 차이가 있다.
일반적으로 적용되는 주요 파라미터
•
Temperature
◦
생성된 텍스트의 다양성을 조정
◦
값이 작으면 예측 가능하고 일관된 출력을 생성하는 반면, 값이 크면 다양하고 예측하기 어려운 출력을 생성
•
Max Tokens (최대 토큰 수)
◦
생성할 최대 토큰 수를 지정
◦
생성할 텍스트의 길이를 제한
•
Top P (Top Probability)
◦
생성 과정에서 특정 확률 분포 내에서 상위 P% 토큰만을 고려하는 방식
◦
이는 출력의 다양성을 조정하는 데 도움이 된다.
•
Frequency Penalty (빈도 패널티)
◦
값이 클수록 이미 등장한 단어나 구절이 다시 등장할 확률을 감소
◦
이를 통해 반복을 줄이고 텍스트의 다양성을 증가시킬 수 있다. (0~1)
•
Presence Penalty (존재 패널티)
◦
텍스트 내에서 단어의 존재 유무에 따라 그 단어의 선택 확률을 조정
◦
값이 클수록 아직 텍스트에 등장하지 않은 새로운 단어의 사용이 장려된다. (0~1)
•
Stop Sequences (정지 시퀀스)
◦
특정 단어나 구절이 등장할 경우 생성을 멈추도록 설정
◦
이는 출력을 특정 포인트에서 종료하고자 할 때 사용
모델 생성할 때, 적용
from langchain_openai import ChatOpenAI
# 모델 파라미터 설정
params = {
"temperature": 0.7, # 생성된 텍스트의 다양성 조정
"max_tokens": 100, # 생성할 최대 토큰 수
"frequency_penalty": 0.5, # 이미 등장한 단어의 재등장 확률
"presence_penalty": 0.5, # 새로운 단어의 도입을 장려
"stop": ["\n"] # 정지 시퀀스 설정
}
# 모델 인스턴스를 생성할 때 설정
model = ChatOpenAI(model="gpt-4o-mini", **params)
# 모델 호출
question = "태양계에서 가장 큰 행성은 무엇인가요?"
response = model.invoke(input=question)
> print(response.content)
태양계에서 가장 큰 행성은 목성(Jupiter)입니다. 목성은 지름이 약 142,984킬로미터로, 태양계의 다른 모든 행성을 합친 것보다도 훨씬 큽니다. 또한, 목성은 가스 거인으로 분류되며, 두꺼운 대기와 많은 위성을 가지고 있습니다.
Python
복사
모델 호출할 때, 적용
# 모델 파라미터 설정
params = {
"temperature": 0.7, # 생성된 텍스트의 다양성 조정
"max_tokens": 10, # 생성할 최대 토큰 수
}
# 모델 인스턴스를 호출할 때 전달
response = model.invoke(input=question, **params)
# 문자열 출력
> print(response.content)
태양계에서 가장 큰 행성은 목
Python
복사
bind 메소드
•
bind 메소드를 사용하여 모델 인스턴스에 파라미터를 추가로 제공할 수 있다.
•
bind 메서드를 사용하는 방식의 장점은 특정 모델 설정을 기본값으로 사용하고자 할 때 유용하며, 특수한 상황에서 일부 파라미터를 다르게 적용하고 싶을 때 사용
•
기본적으로 일관된 파라미터 설정을 유지하면서 상황에 맞춰 유연한 대응이 가능하다.
•
이를 통해 코드의 가독성과 재사용성을 높일 수 있다.
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "이 시스템은 천문학 질문에 답변할 수 있습니다."),
("user", "{user_input}"),
])
messages = prompt.format_messages(user_input="태양계에서 가장 큰 행성은 무엇인가요?")
> messages
[SystemMessage(content='이 시스템은 천문학 질문에 답변할 수 있습니다.', additional_kwargs={}, response_metadata={}),
HumanMessage(content='태양계에서 가장 큰 행성은 무엇인가요?', additional_kwargs={}, response_metadata={})]
Python
복사
model = ChatOpenAI(model="gpt-4o-mini", max_tokens=100)
before_answer = model.invoke(messages)
# binding 이전 출력
> print(before_answer.content)
태양계에서 가장 큰 행성은 목성(Jupiter)입니다. 목성은 지구의 약 1,300배에 달하는 부피를 가지고 있으며, 주로 수소와 헬륨으로 이루어져 있습니다. 또 강력한 자기장과 다수의 위성을 가지고 있는 특징이 있습니다.
Python
복사
•
Binding
# 모델 호출 시 추가적인 인수를 전달하기 위해 bind 메서드 사용 (응답의 최대 길이를 10 토큰으로 제한)
chain = prompt | model.bind(max_tokens=10)
after_answer = chain.invoke({"user_input": "태양계에서 가장 큰 행성은 무엇인가요?"})
# binding 이후 출력
> print(after_answer.content)
태양계에서 가장 큰 행성은 목
> after_answer.pretty_print()
================================== Ai Message ==================================
태양계에서 가장 큰 행성은 목
Python
복사
•
특정 호출에 대한 토큰 사용량을 추적하는 방법에 대해 설명
•
이 기능은 현재 OpenAI API 에만 구현되어 있다.
•
먼저 단일 Chat 모델 호출에 대한 토큰 사용량을 추적하는 매우 간단한 예를 살펴보자.
from langchain.callbacks import get_openai_callback
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-4o-mini")
with get_openai_callback() as cb:
result = llm.invoke("대한민국의 수도는 어디야?")
print(cb)
Tokens Used: 23
Prompt Tokens: 15
Completion Tokens: 8
Successful Requests: 1
Total Cost (USD): $7.049999999999999e-06
Python
복사
◦
분할해서 보기
with get_openai_callback() as cb:
result = llm.invoke("대한민국의 수도는 어디야?")
print(f"총 사용된 토큰수: \t\t{cb.total_tokens}")
print(f"프롬프트에 사용된 토큰수: \t{cb.prompt_tokens}")
print(f"답변에 사용된 토큰수: \t{cb.completion_tokens}")
print(f"호출에 청구된 금액(USD): \t${cb.total_cost}")
총 사용된 토큰수: 23
프롬프트에 사용된 토큰수: 15
답변에 사용된 토큰수: 8
호출에 청구된 금액(USD): $7.049999999999999e-06
Python
복사
캐싱(Cache)
•
LangChain은 LLM을 위한 선택적 캐싱 레이어를 제공한다.
•
유용한 두 가지 이유
◦
동일한 완료를 여러 번 요청하는 경우 LLM 공급자에 대한 API 호출 횟수를 줄여 비용을 절감 할 수 있다.
◦
LLM 제공업체에 대한 API 호출 횟수를 줄여 애플리케이션의 속도를 높일 수 있다.
from langchain_openai import ChatOpenAI
# 모델을 생성합니다.
llm = ChatOpenAI(model="gpt-4o-mini")
Python
복사
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template("{country} 에 대해서 200자 내외로 요약해줘")
> prompt
PromptTemplate(input_variables=['country'], input_types={}, partial_variables={}, template='{country} 에 대해서 200자 내외로 요약해줘')
Python
복사
캐싱 전
with get_openai_callback() as cb:
%time response = chain.invoke({"country": "한국"})
print(response.content)
print("*"*10)
print(f"총 사용된 토큰수: \t\t{cb.total_tokens}")
print(f"프롬프트에 사용된 토큰수: \t{cb.prompt_tokens}")
print(f"답변에 사용된 토큰수: \t{cb.completion_tokens}")
print(f"호출에 청구된 금액(USD): \t${cb.total_cost}")
CPU times: user 31.6 ms, sys: 2.74 ms, total: 34.3 ms
Wall time: 1.14 s
한국은 동아시아에 위치한 국가로, 한반도의 남쪽에 위치해 있습니다. 수도는 서울이며, 경제, 문화, 기술 분야에서 빠른 발전을 이루어왔습니다. 한류, K-pop, 전통 음식 등으로 세계적으로 알려져 있으며, 교육 수준이 높고 IT 산업이 발달해 있습니다. 또한, 역사적으로 풍부한 문화유산과 자연경관이 어우러져 있어 관광지로도 매력적입니다.
**********
총 사용된 토큰수: 121
프롬프트에 사용된 토큰수: 20
답변에 사용된 토큰수: 101
호출에 청구된 금액(USD): $6.36e-05
Python
복사
InMemoryCache
from langchain.globals import set_llm_cache
from langchain.cache import InMemoryCache
# 인메모리 캐시를 사용합니다.
set_llm_cache(InMemoryCache())
Python
복사
•
메모리에 저장
with get_openai_callback() as cb:
%time response = chain.invoke({"country": "한국"})
print(response.content)
print("*"*10)
print(f"총 사용된 토큰수: \t\t{cb.total_tokens}")
print(f"프롬프트에 사용된 토큰수: \t{cb.prompt_tokens}")
print(f"답변에 사용된 토큰수: \t{cb.completion_tokens}")
print(f"호출에 청구된 금액(USD): \t${cb.total_cost}")
CPU times: user 18.2 ms, sys: 2.9 ms, total: 21.1 ms
Wall time: 1.76 s
한국은 동아시아에 위치한 한반도의 국가로, 남한과 북한으로 나뉘어 있다. 서울은 수도로, 경제와 문화의 중심지이다. 한국은 고유의 전통과 현대 문화가 조화를 이루며, K-팝, 영화, 음식 등이 세계적으로 인기를 끌고 있다. 한편, 역사는 고대 왕국부터 현대 민주국가에 이르기까지 풍부하며, 한국전쟁 이후 남북 간의 분단 상황이 지속되고 있다.
**********
총 사용된 토큰수: 132
프롬프트에 사용된 토큰수: 20
답변에 사용된 토큰수: 112
호출에 청구된 금액(USD): $7.02e-05
Python
복사
◦
속도가 빨라진 걸 확인할 수 있다.
SQLite Cache
from langchain.cache import SQLiteCache
from langchain.globals import set_llm_cache
set_llm_cache(SQLiteCache(database_path="my_llm_cache.db"))
Python
복사
•
요청 데이터가 저장됨
with get_openai_callback() as cb:
%time response = chain.invoke({"country": "한국"})
print(response.content)
print("*"*10)
print(f"총 사용된 토큰수: \t\t{cb.total_tokens}")
print(f"프롬프트에 사용된 토큰수: \t{cb.prompt_tokens}")
print(f"답변에 사용된 토큰수: \t{cb.completion_tokens}")
print(f"호출에 청구된 금액(USD): \t${cb.total_cost}")
CPU times: user 33.8 ms, sys: 2.08 ms, total: 35.9 ms
Wall time: 1.75 s
한국은 동아시아에 위치한 한반도의 국가로, 남한과 북한으로 나뉩니다. 남한은 민주주의와 시장경제를 채택하며, IT, 영화, 음악 등에서 세계적인 영향력을 미치고 있습니다. 북한은 사회주의 체제를 유지하며, 군사 중심의 경제를 운영합니다. 한국의 전통문화와 현대문화가 조화를 이루고 있으며, 한식, K-pop, 한류 등이 세계적으로 알려져 있습니다. 역사적으로는 고려, 조선 등 강력한 왕조를 거쳤고, 20세기에는 일제강점기와 한국 전쟁을 경험했습니다.
**********
총 사용된 토큰수: 157
프롬프트에 사용된 토큰수: 20
답변에 사용된 토큰수: 137
호출에 청구된 금액(USD): $8.520000000000001e-05
Python
복사
•
저장된 데이터를 사용
with get_openai_callback() as cb:
%time response = chain.invoke({"country": "한국"})
print(response.content)
print("*"*10)
print(f"총 사용된 토큰수: \t\t{cb.total_tokens}")
print(f"프롬프트에 사용된 토큰수: \t{cb.prompt_tokens}")
print(f"답변에 사용된 토큰수: \t{cb.completion_tokens}")
print(f"호출에 청구된 금액(USD): \t${cb.total_cost}")
CPU times: user 102 ms, sys: 36.2 ms, total: 138 ms
Wall time: 138 ms
한국은 동아시아에 위치한 한반도의 국가로, 남한과 북한으로 나뉩니다. 남한은 민주주의와 시장경제를 채택하며, IT, 영화, 음악 등에서 세계적인 영향력을 미치고 있습니다. 북한은 사회주의 체제를 유지하며, 군사 중심의 경제를 운영합니다. 한국의 전통문화와 현대문화가 조화를 이루고 있으며, 한식, K-pop, 한류 등이 세계적으로 알려져 있습니다. 역사적으로는 고려, 조선 등 강력한 왕조를 거쳤고, 20세기에는 일제강점기와 한국 전쟁을 경험했습니다.
**********
총 사용된 토큰수: 157
프롬프트에 사용된 토큰수: 20
답변에 사용된 토큰수: 137
호출에 청구된 금액(USD): $8.520000000000001e-05
Python
복사
모델 직렬화(Serialization)
•
is_lc_serializable 클래스 메서드로 실행하여 LangChain 클래스가 직렬화 가능한지 확인할 수 있다.
from langchain_openai import ChatOpenAI
from langchain.llms.loading import load_llm
# 직렬화가 가능한지 체크
> print(f"ChatOpenAI: {ChatOpenAI.is_lc_serializable()}")
ChatOpenAI: True
Python
복사
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template("{fruit}의 색상이 무엇입니까?")
> prompt
PromptTemplate(input_variables=['fruit'], input_types={}, partial_variables={}, template='{fruit}의 색상이 무엇입니까?')
Python
복사
◦
직렬화
chain = prompt | llm
> chain.is_lc_serializable()
True
response = chain.invoke({"fruit": "사과"})
> response
AIMessage(content='사과의 색상은 다양합...색을 띠고 있습니다. 사과의 색상은 품종에 따라 다르며, 익은 정도에 따라서도 변화할 수 있습니다.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 132, 'prompt_tokens': 16, 'total_tokens': 148, 'completion_tokens_details': {'audio_tokens': None, 'reasoning_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_8bfc6a7dc2', 'finish_reason': 'stop', 'logprobs': None}, id='run-2fa4f212-10d3-442c-bb5b-386edc856f43-0', usage_metadata={'input_tokens': 16, 'output_tokens': 132, 'total_tokens': 148, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 0}})
Python
복사
모델 저장
•
직렬화 가능한 모든 객체는 딕셔너리 또는 json 문자열로 직렬화할 수 있다.
from langchain.load import dumpd
dumped_chain = dumpd(chain)
Python
복사
import pickle
# fuit_chain.pkl 파일로 직렬화된 체인을 저장
with open("fruit_chain.pkl", "wb") as f:
pickle.dump(dumped_chain, f)
Python
복사
모델 불러오기
with open("fruit_chain.pkl", "rb") as f:
loaded_chain = pickle.load(f)
from langchain.load.load import load
> loaded_chain.invoke({"fruit": "사과"}).pretty_print()
================================== Ai Message ==================================
사과의 색상은 다양합니다. 일반적으로 빨간색, 초록색, 노란색 등이 있으며, 일부 사과는 이들 색상이 혼합된 형태로도 나타납니다. 예를 들어, 레드 딜리셔스 사과는 진한 빨간색을 띠고, 그라니 스미스 사과는 선명한 초록색을 가지고 있습니다. 또한, 골든 딜리셔스 사과는 노란색을 띠고 있습니다. 사과의 색상은 품종에 따라 다르며, 익은 정도에 따라서도 변화할 수 있습니다.
Python
복사
