


•
랭체인 표현 언어
•
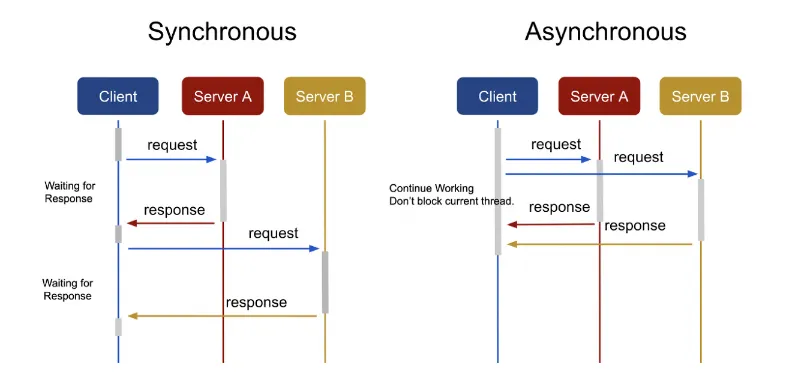
동기(Synchronous) 방식
•
작업이 실행될 때, 해당 작업이 완료될 때까지 기다린다.
→ 즉, 해당 작업이 끝나기 전까지는 다른 작업을 수행하지 않는다.
•
이 작업이 완료된 후에는 결과가 반환된다.
◦
요청과 결과가 한 자리에 동시에 나타나는 것으로 사용자가 서버로 요청을 보냈을 경우 요청에 대한 응답을 리턴받기 전까지 다른 것을 하지 못하고 기다려야 한다.
◦
특정 프로그램을 구동시키는 데 시간이 5분 소요된다고 하면, 이 프로그램이 구동되는 5분 동안 컴퓨터는 다른 프로그램을 동작시키지 못하고, 구동되기를 기다려야 한다.
•
동기 장단점
◦
장점 : 설계가 간단하고, 직관적이다.
◦
단점 : 요청에 대한 결과가 반환되기 전까지 대기해야 한다.
비동기(Asynchronous) 방식
•
작업이 실행되고 완료되는 동안 다른 작업을 수행할 수 있다.
→ 즉, 해당 작업이 완료되지 않았더라도 다른 작업을 수행할 수 있다.
•
결과는 작업이 완료될 때 반환된다.
◦
요청한 곳에 결과가 나타나지 않으며, 사용자가 서버로 요청을 보냈을 경우 요청에 대한 응답을 기다리지 않고, 다른 것을 수행할 수 있으며 서버로 다른 요청을 보낼 수도 있다.
◦
특정 프로그램을 구동시키는 데 시간이 5분 소요되어도 그 시간 동안 다른 프로그램을 수행할 수 있다.
•
비동기 장단점
◦
장점 : 요청에 대한 결과가 반환되기 전에 다른 작업을 수행할 수 있어서 자원을 효율적으로 사용할 수 있다.
◦
단점 : 동기 방식보다 설계가 복잡하고, 논증적이다.
ChatOpenAI
•
옵션
◦
temperature: 사용할 샘플링 온도는 0과 2 사이에서 선택, 0.8과 같은 높은 값은 출력을 더 무작위하게 만들고, 0.2와 같은 낮은 값은 출력을 더 집중되고 결정론적으로 만든다.
◦
max_tokens: 채팅 완성에서 생성할 토큰의 최대 개수
◦
model_name: 적용 가능한 기본 모델 리스트 - gpt-3.5-turbo - gpt-4-turbo - gpt-4o
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="gpt-4o-mini"
)
Python
복사
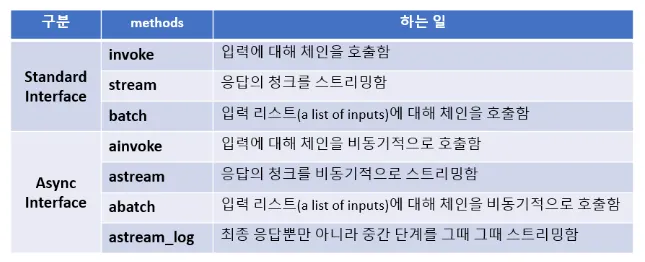
표준 인터페이스
•
stream: 응답의 청크를 스트리밍
•
invoke: 입력에 대해 체인을 호출
•
batch: 입력 목록에 대해 체인을 호출
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 주어진 토픽에 대한 농담을 요청하는 프롬프트 템플릿을 생성
prompt = PromptTemplate.from_template("{topic} 에 대하여 3문장으로 설명해줘.")
# 프롬프트와 모델을 연결하여 대화 체인을 생성
chain = prompt | model | StrOutputParser()
Python
복사
stream
•
이 함수는 chain.stream 메서드를 사용하여 주어진 토픽에 대한 데이터 스트림을 생성하고, 이 스트림을 반복하여 각 데이터의 내용(content)을 즉시 출력한다.
•
end="" 인자는 출력 후 줄바꿈을 하지 않도록 설정하며, flush=True 인자는 출력 버퍼를 즉시 비우도록 한다.
# chain.stream 메서드를 사용하여 '멀티모달' 토픽에 대한 스트림을 생성하고 반복함
for token in chain.stream({"topic": "멀티모달"}):
# 스트림에서 받은 데이터의 내용을 출력
# 줄바꿈 없이 이어서 출력하고, 버퍼를 즉시 비운다.
print(token, end="", flush=True)
멀티모달은 다양한 유형의 데이터를 통합하여 처리하는 접근 방식을 의미합니다. 예를 들어, 텍스트, 이미지, 오디오 등 서로 다른 형태... 성능과 이해력을 얻을 수 있습니다.
Python
복사
invoke
•
chain 객체의 invoke 메서드는 주제를 인자로 받아 해당 주제에 대한 처리를 수행한다.
# chain 객체의 invoke 메서드를 호출하고, 'ChatGPT'라는 주제로 딕셔너리를 전달함
chain.invoke({"topic": "ChatGPT"})
ChatGPT는 OpenAI에서 개발한...다양한 주제에 대해 정보를 제공하고, 창의적인 글쓰기, 문제 해결 등 여러 용도로 활용될 수 있습니다.
Python
복사
batch
•
함수 chain.batch는 여러 개의 딕셔너리를 포함하는 리스트를 인자로 받아, 각 딕셔너리에 있는 topic 키의 값을 사용하여 일괄 처리를 수행한다.
# 주어진 토픽 리스트를 batch 처리하는 함수 호출
chain.batch([{"topic": "ChatGPT"}, {"topic": "Instagram"}])
['ChatGPT는 OpenAI에서 개발한 대화형 인공지능 모델로, 자연어 처리 기술을 기반으로 합니다. 사용자의 질문이나 요청에...따라갈 수 있습니다. 또한, 인스타그램은 스토리, IGTV, 리엘스와 같은 기능을 통해 다양한 형식의 콘텐츠를 제공하여 사용자 경험을 풍부하게 합니다.']
Python
복사
◦
max_concurrency 매개변수를 사용하여 동시 요청 수를 설정할 수 있다.
◦
config 딕셔너리는 max_concurrency 키를 통해 동시에 처리할 수 있는 최대 작업 수를 설정한다.
◦
여기서는 최대 3개의 작업을 동시에 처리하도록 설정되어 있다.
비동기 인터페이스
•
astream: 비동기적으로 응답의 청크를 스트리밍
•
ainvoke: 비동기적으로 입력에 대해 체인을 호출
•
abatch: 비동기적으로 입력 목록에 대해 체인을 호출
•
astream_log: 최종 응답뿐만 아니라 발생하는 중간 단계를 스트리밍
async stream: 비동기 스트림
•
함수 chain.astream은 비동기 스트림을 생성하며, 주어진 토픽에 대한 메시지를 비동기적으로 처리한다.
•
비동기 for 루프(async for)를 사용하여 스트림에서 메시지를 순차적으로 받아오고, print 함수를 통해 메시지의 내용(s.content)을 즉시 출력한다.
•
end=""는 출력 후 줄바꿈을 하지 않도록 설정하며, flush=True는 출력 버퍼를 강제로 비워 즉시 출력되도록 한다.
# 비동기 스트림을 사용하여 'YouTube' 토픽의 메시지를 처리
async for token in chain.astream({"topic": "YouTube"}):
# 메시지 내용을 출력, 줄바꿈 없이 바로 출력하고 버퍼를 비운다.
print(token, end="", flush=True)
YouTube는 사용자들이 비디오를 업로드, 공유 및 시청할 수 있는 온라인 플랫폼입니다. 다양한 콘텐츠가 제공되며, 개인 제작자부터 대규모 미디어 기업까지 다양한 사용자가 참여하고 있습니다. YouTube는 교육, 오락, 정보 제공 등 다양한 용도로 활용되며, 전 세계적으로 큰 인기를 끌고 있습니다.
Python
복사
async invoke: 비동기 호출
•
chain 객체의 ainvoke 메서드는 비동기적으로 주어진 인자를 사용하여 작업을 수행한다.
•
여기서는 topic이라는 키와 NVDA(엔비디아의 티커) 라는 값을 가진 딕셔너리를 인자로 전달하고 있다.
•
이 메서드는 특정 토픽에 대한 처리를 비동기적으로 요청하는 데 사용될 수 있다.
# 비동기 체인 객체의 'ainvoke' 메서드를 호출하여 'NVDA' 토픽을 처리
my_process = chain.ainvoke({"topic": "NVDA"})
# 비동기로 처리되는 프로세스가 완료될 때까지 대기
> await my_process
NVIDIA Corporation (NVDA)는 그래픽 처리 장치(GPU)와 인공지능(AI) 기술을 전문으로 하는 미국의 대기업입니다. 이 회사는 게임, 데이터 센터, 자율주행차 등 다양한 분야에서 사용되는 고성능 컴퓨팅 솔루션을 제공합니다. 최근에는 AI와 머신러닝 분야에서의 혁신적인 기술 개발로 주목받고 있으며, 시장에서 중요한 역할을 하고 있습니다.
Python
복사
async batch: 비동기 배치
•
함수 abatch는 비동기적으로 일련의 작업을 일괄 처리한다.
•
이 예시에서는 chain 객체의 abatch 메서드를 사용하여 topic 에 대한 작업을 비동기적으로 처리하고 있다.
•
await 키워드는 해당 비동기 작업이 완료될 때까지 기다리는 데 사용된다.
# 주어진 토픽에 대해 비동기적으로 일괄 처리를 수행
my_abatch_process = chain.abatch(
[{"topic": "YouTube"}, {"topic": "Instagram"}, {"topic": "Facebook"}]
)
# 비동기로 처리되는 일괄 처리 프로세스가 완료될 때까지 대기
> await my_abatch_process
['YouTube는 사용자들이 비디오를 업로드, 공유 및 시청할 수 있는 온라인 플랫폼입니다. 2005년에 설립된 이 사이트는 전 세계적으로 다양한 콘텐츠를 제공하며, 개인 제작자부터 기업, 교육 기관까지 다양한 사용자들이 활동하고 있습니다. 또한, YouTube는 광고 수익 모델을 통해 콘텐츠 제작자들에게 수익을 창출할 수 있는 기회를 제공합니다.',
'인스타그램은 사용자들이 사진과 동영상을 공유하고, 다른 사용자들과 소통할 수 있는 소셜 미디어 플랫폼입니다. 이 플랫폼은 필터와 편집 도구를 제공하여 사용자가 자신의 콘텐츠를 더욱 매력적으로 꾸밀 수 있도록 돕습니다. 또한, 해시태그와 스토리 기능을 통해 사용자들은 다양한 주제와 관심사를 탐색하고 팔로워와의 상호작용을 강화할 수 있습니다.',
'Facebook은 2004년 마크 저커버그에 의해 설립된 소셜 미디어 플랫폼으로, 사용자들이 친구 및 가족과 소통하고 콘텐츠를 공유할 수 있는 공간을 제공합니다. 이 플랫폼은 사진, 동영상, 글 등을 게시하고, 댓글 및 좋아요를 통해 상호 작용할 수 있는 기능을 갖추고 있습니다. 또한, 다양한 광고 및 비즈니스 도구를 통해 기업들이 고객과 연결될 수 있도록 지원하는 역할도 합니다.']
Python
복사
async astream_log: 비동기 로그
•
최종 응답뿐만 아니라 중간 단계 로그를 그때 그때 스트리밍한다.
•
중간 단계의 세부 로그 데이터를 확인할 수 있다.
async for chunk in chain.astream_log(
"What are some colors of rainbow? Only answer the colors one by one per a line."):
print("---" * 20)
print(chunk)
Python
복사
RunLogPatch({'op': 'replace',
'path': '',
'value': {'final_output': None,
'id': 'bd05038f-5b07-4687-ae42-fcd2e3f7f259',
'logs': {},
'name': 'RunnableSequence',
'streamed_output': [],
'type': 'chain'}})
------------------------------------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/PromptTemplate',
'value': {'end_time': None,
'final_output': None,
'id': 'ef34bfff-3256-43f7-bfaa-67e270a609a6',
'metadata': {},
'name': 'PromptTemplate',
'start_time': '2024-10-29T06:15:02.644+00:00',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['seq:step:1'],
'type': 'prompt'}})
------------------------------------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/PromptTemplate/final_output',
'value': StringPromptValue(text='What are some colors of rainbow? Only answer the colors one by one per a line. 에 대하여 3문장으로 설명해줘.')},
{'op': 'add',
'path': '/logs/PromptTemplate/end_time',
'value': '2024-10-29T06:15:02.646+00:00'})
....
Python
복사
병렬 인터페이스
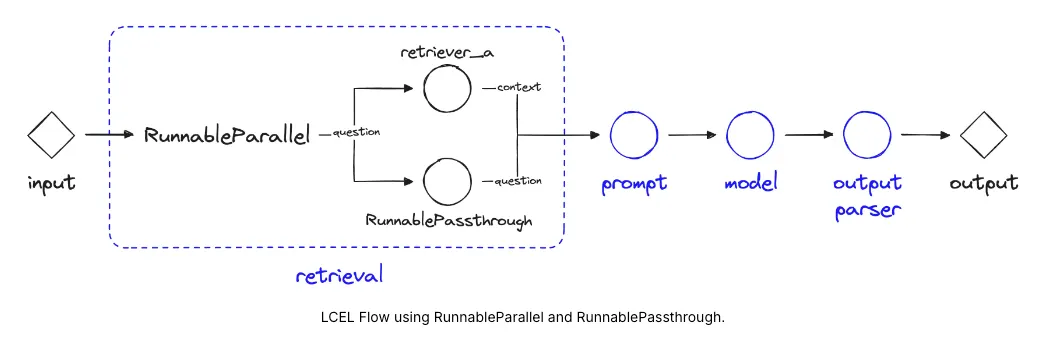
Parallel: 병렬성
•
LangChain Expression Language가 병렬 요청을 지원하는 방법
◦
RunnableParallel을 사용할 때(자주 사전 형태로 작성됨), 각 요소를 병렬로 실행한다.
•
langchain_core.runnables 모듈의 RunnableParallel 클래스를 사용하여 두 가지 작업을 병렬로 실행하는 예시
from langchain_core.runnables import RunnableParallel
# {country}의 수도를 물어보는 체인을 생성
chain1 = (
PromptTemplate.from_template("{country} 의 수도는 어디야?")
| model
| StrOutputParser()
)
# {country}의 면적을 물어보는 체인을 생성
chain2 = (
PromptTemplate.from_template("{country} 의 면적은 얼마야?")
| model
| StrOutputParser()
)
# 위의 2개 체인을 동시에 생성하는 병렬 실행 체인을 생성
combined = RunnableParallel(capital=chain1, area=chain2)
Python
복사
◦
ChatPromptTemplate.from_template 메서드를 사용하여 주어진 country에 대한 수도 와 면적 을 구하는 두 개의 체인(chain1, chain2)을 생성
◦
이 체인들은 각각 model과 파이프(|) 연산자를 통해 연결
◦
마지막으로, RunnableParallel 클래스를 사용하여 이 두 체인을 capital와 area이라는 키로 결합하여 동시에 실행할 수 있는 combined 객체를 생성
# chain1를 실행
> chain1.invoke({"country": "대한민국"})
대한민국의 수도는 서울입니다.
Python
복사
◦
chain1.invoke() 함수는 chain1 객체의 invoke 메서드를 호출
◦
이때, country이라는 키에 대한민국라는 값을 가진 딕셔너리를 인자로 전달
# chain2를 실행
> chain2.invoke({"country": "미국"})
미국의 총 면적은 약 9,830,000 평방킬로미터(3,796,000 평방마일)입니다. 이는 미국이 세계에서 세 번째로 큰 나라임을 의미합니다. 면적에는 육지와 수역이 모두 포함됩니다
Python
복사
◦
이번에는 chain2.invoke() 를 호출, country 키에 다른 국가인 미국을 전달
# 병렬 실행 체인을 실행
combined.invoke({"country": "대한민국"})
{'capital': '대한민국의 수도는 서울입니다.',
'area': '대한민국의 면적은 약 100,210 평방킬로미터입니다. 이는 한반도의 남쪽 부분을 포함한 면적입니다.'}
Python
복사
◦
combined 객체의 invoke 메서드는 주어진 country에 대한 처리를 수행
◦
이 예제에서는 대한민국라는 주제를 invoke 메서드에 전달하여 실행
배치에서의 병렬 처리
•
병렬 처리는 다른 실행 가능한 코드와 결합될 수 있다.
•
이 예시에서는 "대한민국"와 "미국"라는 두 개의 토픽을 배치 처리하고 있다.
# 배치 처리를 수행
> chain1.batch([{"country": "대한민국"}, {"country": "미국"}])
['대한민국의 수도는 서울입니다.', '미국의 수도는 워싱턴 D.C.입니다.']
Python
복사
◦
chain1.batch 함수는 여러 개의 딕셔너리를 포함하는 리스트를 인자로 받아, 각 딕셔너리에 있는 "topic" 키에 해당하는 값을 처리한다.
# 배치 처리를 수행
> chain2.batch([{"country": "대한민국"}, {"country": "미국"}])
['대한민국의 면적은 약 100,210 평방킬로미터(㎢)입니다. 이는 한반도의 남쪽 부분에 해당하며, 북한과 함께 한반도를 구성하고 있습니다.',
'미국의 면적은 약 9,830,000 평방킬로미터(3,796,742 평방마일)입니다. 이는 미국이 세계에서 세 번째로 큰 나라임을 나타냅니다.']
Python
복사
◦
chain2.batch 함수는 여러 개의 딕셔너리를 리스트 형태로 받아, 일괄 처리(batch)를 수행
◦
이 예시에서는 대한민국와 미국라는 두 가지 국가에 대한 처리를 요청
# 주어진 데이터를 배치로 처리합니다.
combined.batch([{"country": "대한민국"}, {"country": "미국"}])
Python
복사
◦
combined.batch 함수는 주어진 데이터를 배치로 처리하는 데 사용된다.
◦
이 예시에서는 두 개의 딕셔너리 객체를 포함하는 리스트를 인자로 받아 각각 대한민국와 미국 두 나라에 대한 데이터를 배치 처리한다.
•
RunnableLambda 는 사용자 정의 함수를 실행 할 수 있는 기능을 제공한다.
•
이를 통해 개발자는 자신만의 함수를 정의하고, 해당 함수를 RunnableLambda 를 사용하여 실행할 수 있다.
•
예를 들어, 데이터 전처리, 계산, 또는 외부 API와의 상호 작용과 같은 작업을 수행하는 함수를 정의하고 실행할 수 있다.
from operator import itemgetter
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAI
Python
복사
사용자 함수
def length_function(text):
return len(text)
def _multiple_length_function(text1, text2):
return len(text1) * len(text2)
def multiple_length_function(_dict):
return _multiple_length_function(_dict["text1"], _dict["text2"])
Python
복사
ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("what is {a} + {b}")
> prompt
ChatPromptTemplate(input_variables=['a', 'b'], input_types={}, partial_variables={}, messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['a', 'b'], input_types={}, partial_variables={}, template='what is {a} + {b}'), additional_kwargs={})])
Python
복사
chain
chain = (
{
"a": itemgetter("foo") | RunnableLambda(length_function),
"b": {"text1": itemgetter("foo"), "text2": itemgetter("bar")}
| RunnableLambda(multiple_length_function),
}
| prompt
| model
)
response = chain.invoke({"foo": "bar", "bar": "gah"})
> response
AIMessage(content='3 + 9 equals 12.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 8, 'prompt_tokens': 14, 'total_tokens': 22, 'completion_tokens_details': {'audio_tokens': None, 'reasoning_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_f59a81427f', 'finish_reason': 'stop', 'logprobs': None}, id='run-368fd6a2-d045-485f-923d-f35a8efabcbb-0', usage_metadata={'input_tokens': 14, 'output_tokens': 8, 'total_tokens': 22, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 0}})
> response.content
3 + 9 equals 12.
Python
복사
•
RunnablePassthrough 는 데이터를 전달하는 역할을 한다.
•
해당 클래스는 invoke() 메서드를 통해 입력된 데이터를 그대로 반환한다.
•
이는 데이터를 변경하지 않고 파이프라인의 다음 단계로 전달하는 데 사용될 수 있다.
•
RunnablePassthrough 는 다음과 같은 시나리오에서 유용할 수 있다.
◦
데이터를 변환하거나 수정할 필요가 없는 경우
◦
파이프라인의 특정 단계를 건너뛰어야 하는 경우
◦
디버깅 또는 테스트 목적으로 데이터 흐름을 모니터링해야 하는 경우
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# prompt 와 llm 을 생성
prompt = PromptTemplate.from_template("{num} 의 10배는?")
# chain 을 생성
chain = prompt | model
# chain 을 실행
response = chain.invoke({"num": 5})
> response
AIMessage(content='5의 10배는 50입니다.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 10, 'prompt_tokens': 14, 'total_tokens': 24, 'completion_tokens_details': {'audio_tokens': None, 'reasoning_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_f59a81427f', 'finish_reason': 'stop', 'logprobs': None}, id='run-1f3fecc1-6c16-424a-be5a-6d49c16cfd5d-0', usage_metadata={'input_tokens': 14, 'output_tokens': 10, 'total_tokens': 24, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 0}})
> response.content
5의 10배는 50입니다.
Python
복사
RunnablePassthrough
•
RunnablePassthrough() 가 단독으로 호출되면, 단순히 입력을 받아 그대로 전달한다.
from langchain_core.runnables import RunnablePassthrough
# runnable
> RunnablePassthrough().invoke({"num": 10})
{'num': 10}
Python
복사
runnable_chain = {"num": RunnablePassthrough()} | prompt | model
# dict 값이 RunnablePassthrough() 로 변경되었다.
response = runnable_chain.invoke(10)
> response
AIMessage(content='10의 10배는 100입니다.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 10, 'prompt_tokens': 14, 'total_tokens': 24, 'completion_tokens_details': {'audio_tokens': None, 'reasoning_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_f59a81427f', 'finish_reason': 'stop', 'logprobs': None}, id='run-9c264f26-4fc0-40db-a4b2-07e14d355284-0', usage_metadata={'input_tokens': 14, 'output_tokens': 10, 'total_tokens': 24, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 0}})
> response.content
10의 10배는 100입니다.
Python
복사
RunnablePassthrough.assign()
•
입력 값으로 들어온 값의 key/value 쌍과 새롭게 할당된 key/value 쌍을 합친다.
# 입력 키: num, 할당(assign) 키: new_num
result = (RunnablePassthrough.assign(num=lambda x: x["num"] * 3)).invoke({"num": 1})
result
Python
복사
