사전 Setup (Colab)
OpenAI Key 등록
•
import os
os.environ['OPENAI_API_KEY'] = ''
Python
복사
# 구글 드라이브 연결(데이터 로드를 위해서)
try:
from google.colab import drive
drive.mount('/content/data')
DATA_PATH = "/content/data/MyDrive/Colab Notebooks/ai_study/3. Large Language Models/data/"
except:
DATA_PATH = "./data/"
Python
복사
Install
!pip install -U langchain langchain-community langchain-experimental langchain-core langchain-openai langsmith pypdf faiss-cpu
Python
복사
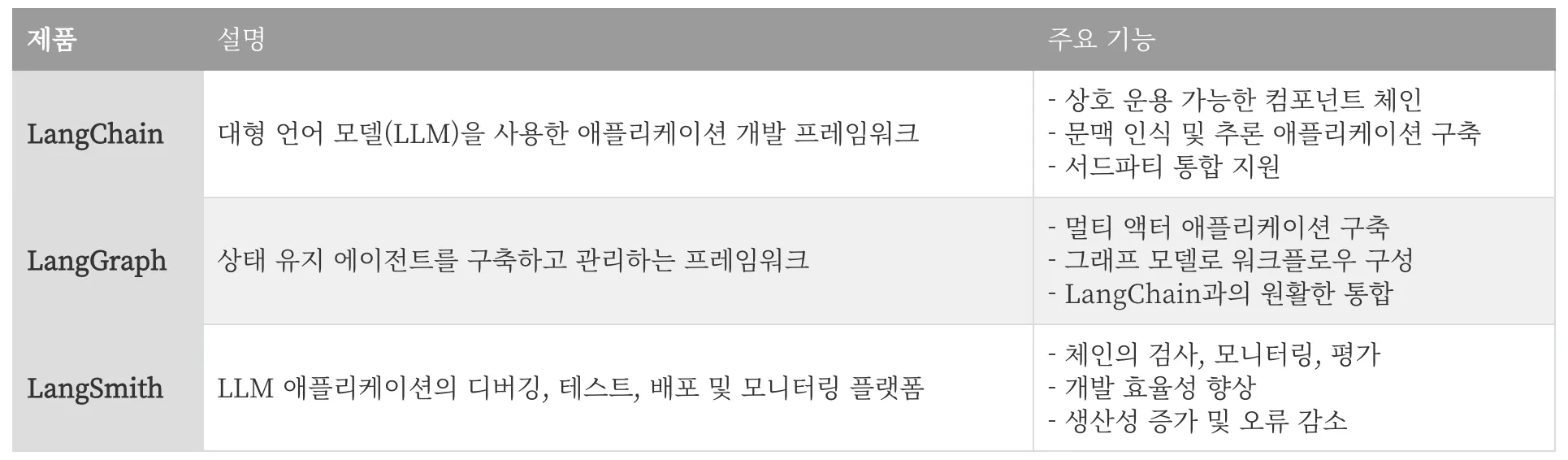
•
Langchain에서 만든 온라인 기반의 LLM 애플리케이션 모니터링, 테스트 지원, 배포 지원 도구
•
Agent에서 분기가 어떻게 이루어지고, Agent가 어떤 구조로 판단을 하는지를 상세하게 모니터링할 수 있다.
•
이 개념 가이드는 LangSmith에 추적 로그를 기록할 때 이해해야 할 중요한 주제를 다룬다.
•
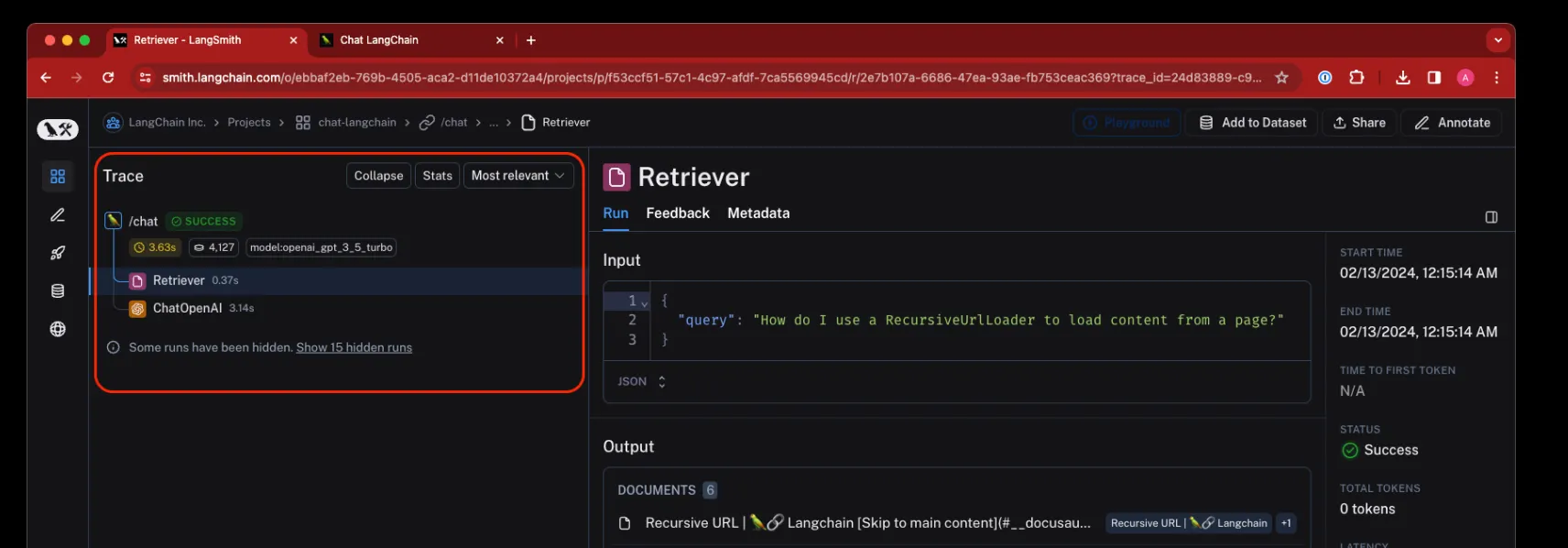
Trace : 애플리케이션이 입력에서 출력으로 가는 일련의 단계를 의미
•
Run : 각각의 개별 단계
•
Project : 단순히 여러 개의 Trace 모음
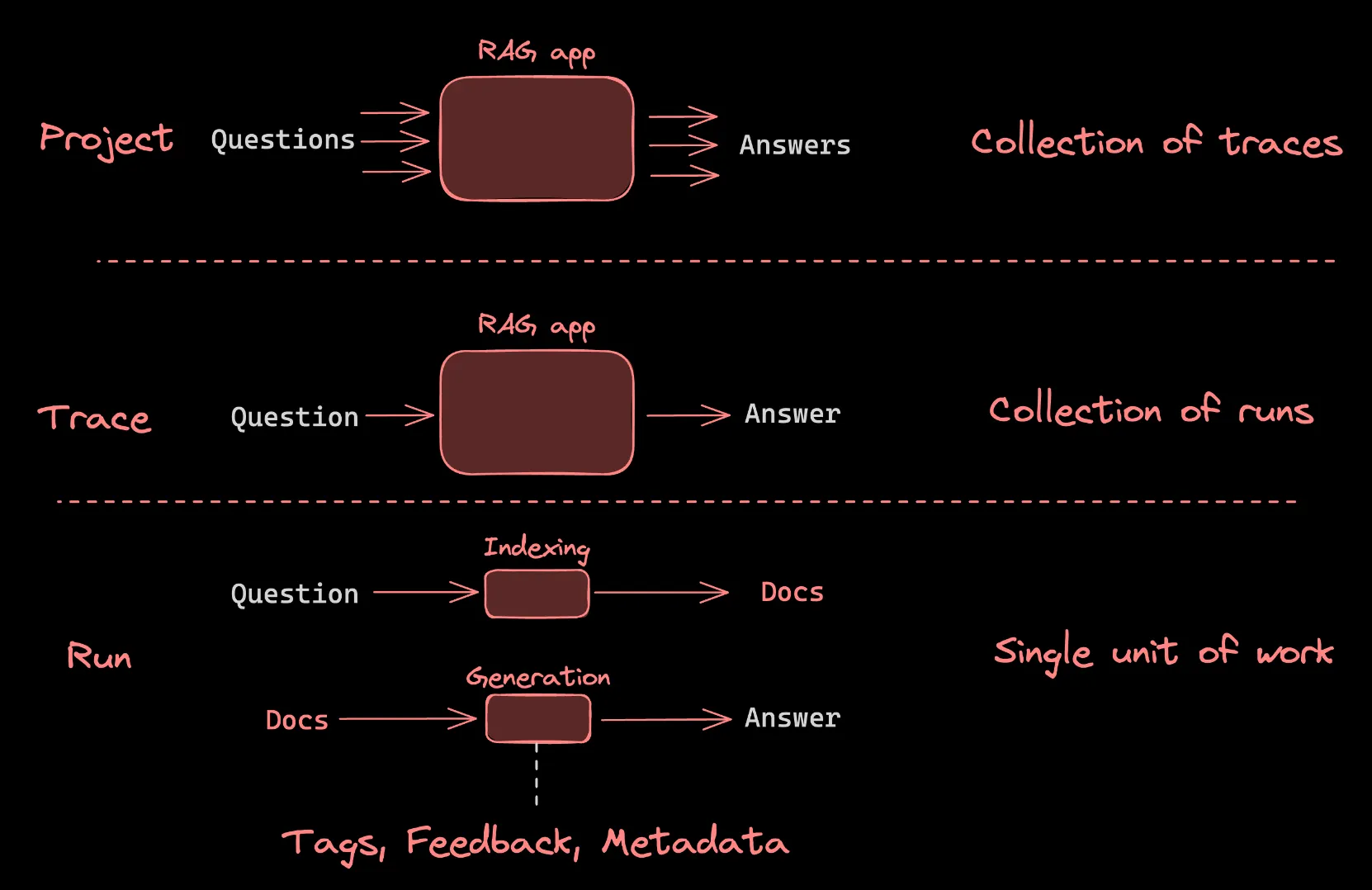
문서에서 문서를 검색하고 답변을 생성하는 간단한 RAG(검색-생성) 앱의 컨텍스트에서의 개념
Run
•
LLM 애플리케이션 내에서 단일 작업 또는 운영 단위를 나타내는 범위
•
이는 LLM 또는 체인에 대한 단일 호출, 프롬프트 형식 지정 호출, 실행 가능한 람다 호출 등 무엇이든 될 수 있다.
Trace
•
단일 작업과 관련된 여러 Run의 모음
•
예를 들어, 사용자 요청이 체인을 트리거하고, 그 체인이 LLM에 대한 호출을 하고, 이후 출력 파서를 호출하는 등의 작업을 한다면, 이러한 모든 Run은 동일한 Trace의 일부가 된다.
•
Run은 고유한 Trace ID에 의해 Trace에 묶인다.
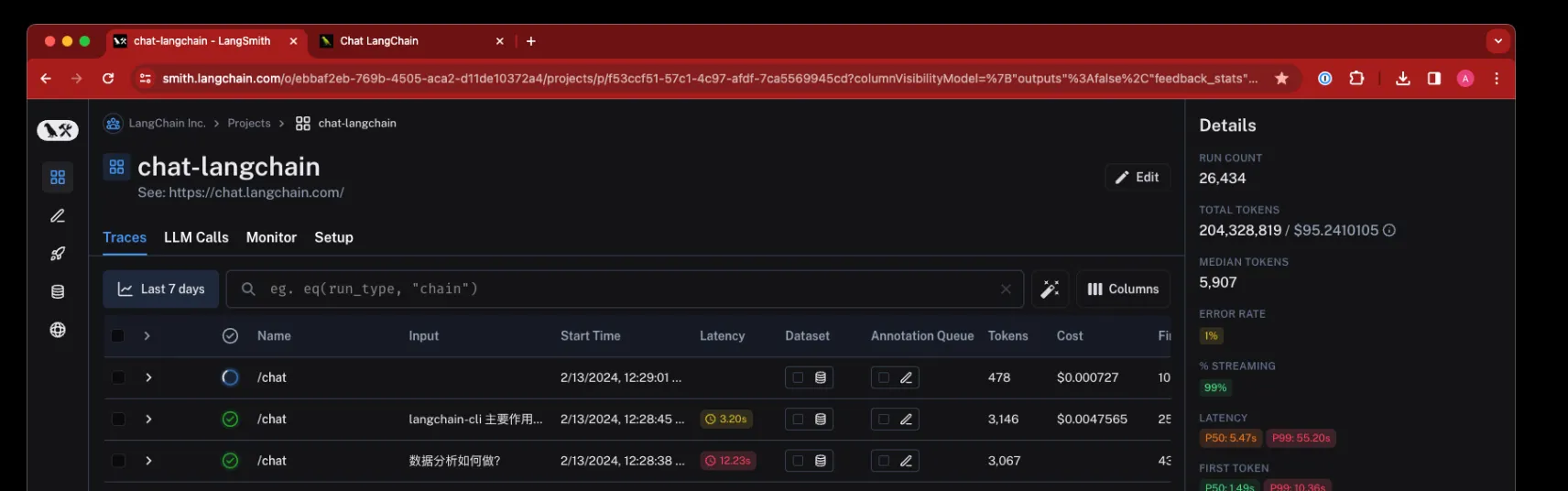
Projects
•
여러 Trace의 모음
•
프로젝트는 단일 애플리케이션이나 서비스와 관련된 모든 Trace를 담는 컨테이너로 생각할 수 있다.
•
여러 개의 프로젝트를 가질 수 있으며, 각 프로젝트는 여러 Trace를 포함할 수 있다.
Langsmith 설정
•
LANGCHAIN_TRACING_V2: "true"로 설정하면 추적을 시작
•
•
LANGCHAIN_API_KEY: 이전 단계에서 발급받은 키를 입력
•
LANGCHAIN_PROJECT: 프로젝트명을 기입하면 해당 프로젝트 그룹으로 모든 실행(Run) 이 추적됨
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_PROJECT"] = "AGENT TUTORIAL"
os.environ["LANGCHAIN_API_KEY"] = ""
Python
복사
•
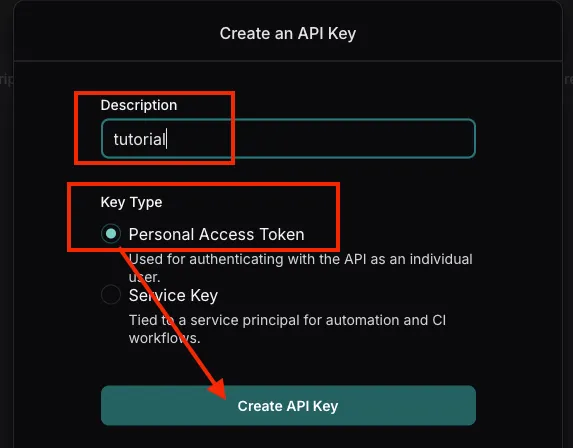
위 링크에서 회원가입/로그인을 한 후 진행
•
API 설명 및 Key Type 지정
•
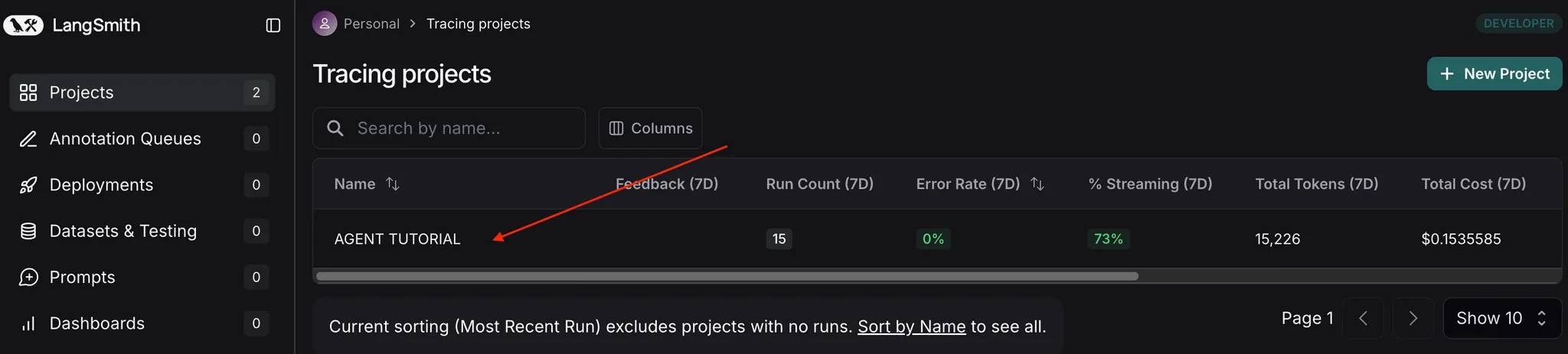
Projects 접속

•
Project 선택
•
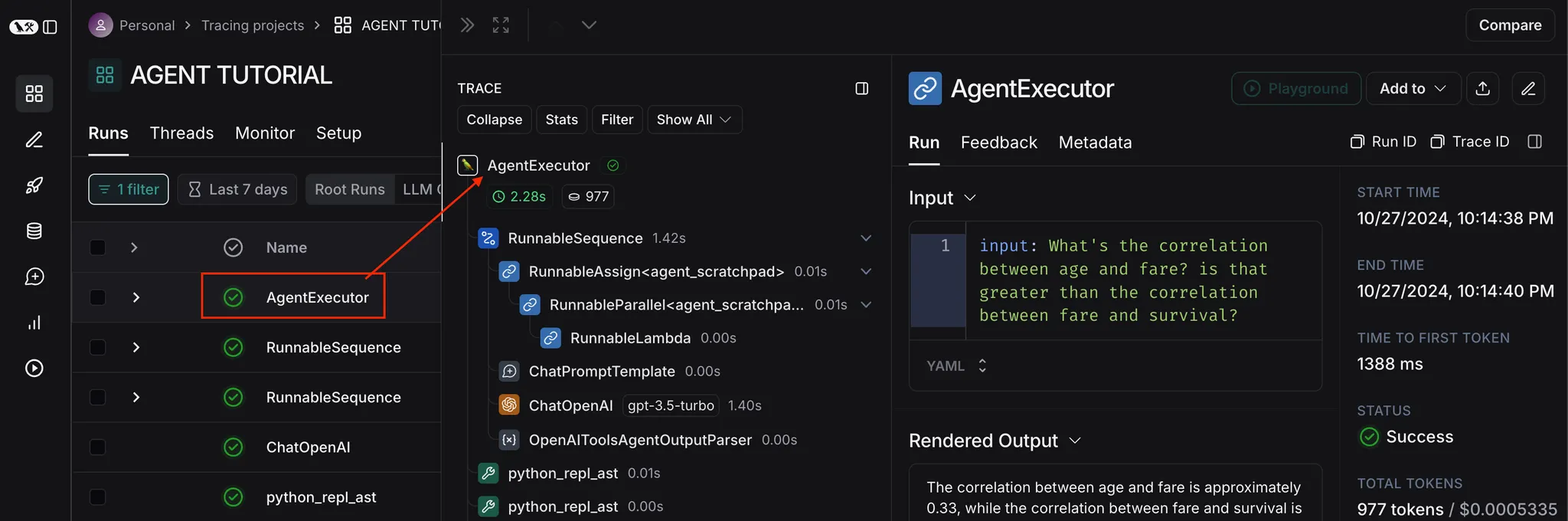
실행된 목록 선택
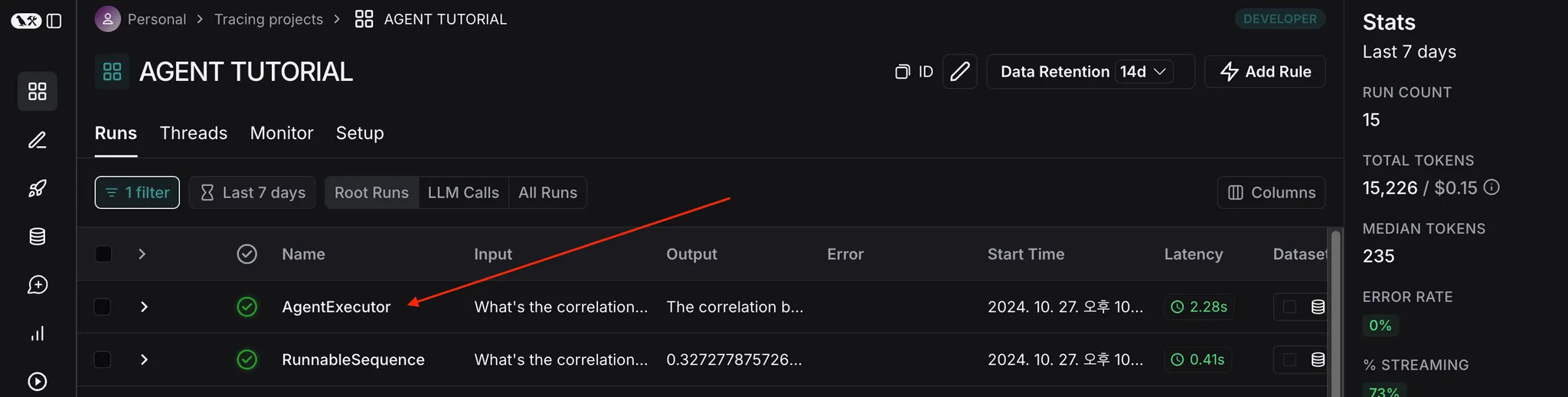
•
로그 확인
◦
1개의 실행을 한 뒤 retrieve 된 문서의 검색 결과 뿐만 아니라, GPT 의 입출력 내용에 대해서 자세하게 기록한다.
◦
따라서, 문서의 검색된 내용을 확인 후 검색 알고리즘을 변경해야할지 혹은 프롬프트를 변경해야할지 판단하는데 도움이 된다.
◦
뿐만 아니라, 상단에는 1개의 실행(Run) 이 걸린 시간(약 30초)와 사용된 토큰(5,104) 등이 표기가 되고, 토큰에 마우스 호버를 하게 되면 청구 금액까지 표기해 준다.

•
사용자의 요청을 받은 후 어떤 기능을 어떤 순서로 실행할지 결정하는 역할
•
Agent의 주요 특징들
◦
목표(정책) 기반 행동: 주어진 목표를 달성하기 위해 행동합니다.
◦
자율성: 목표가 주어지면 자동으로 작동합니다.
◦
감지: 주변 환경에서 정보를 수집합니다.
•
Tools : Agent가 할 수 있는 일(도구, 기술, 함수들)에 해당.
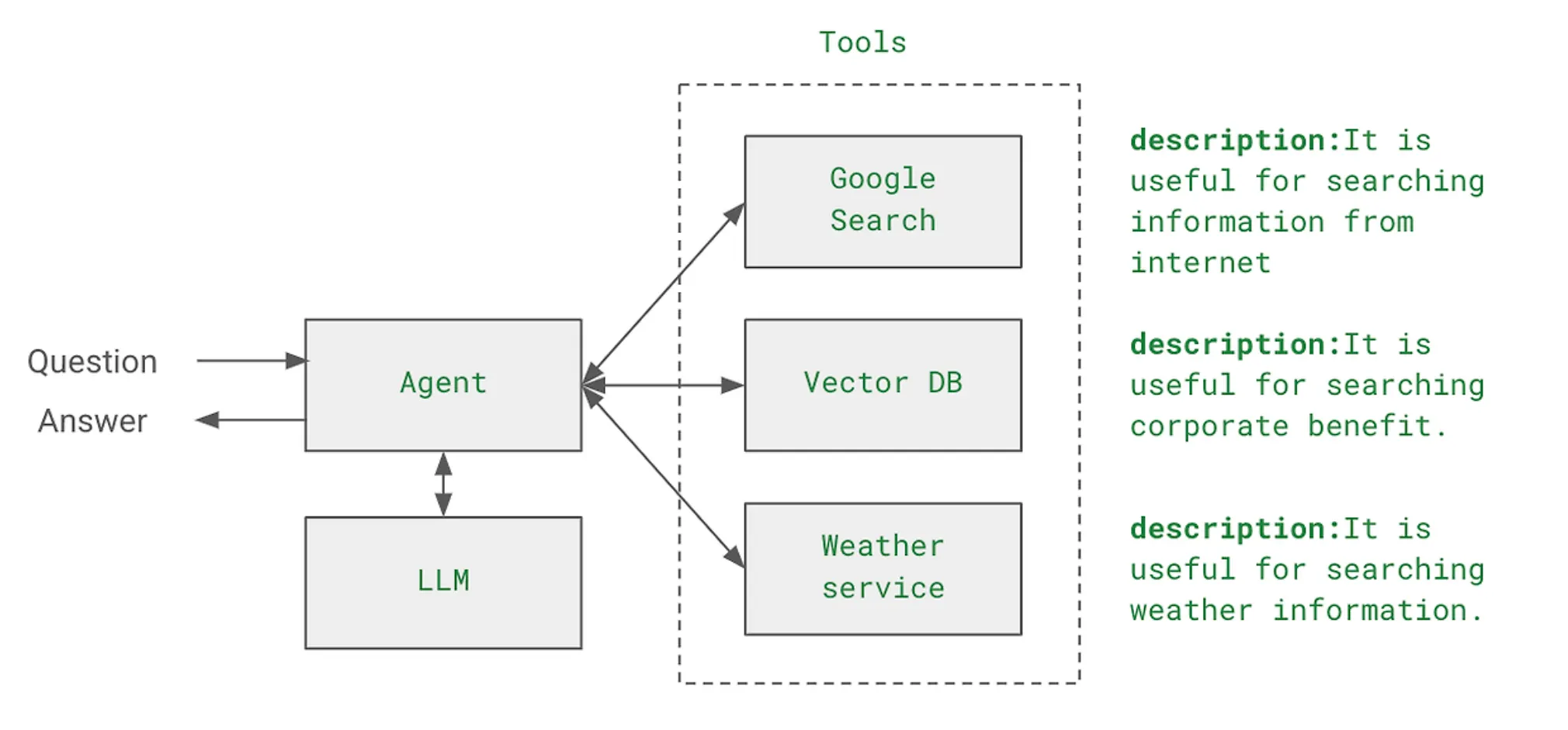
주요 특징
•
자율성 : 에이전트는 사전에 정의된 규칙이나 명시적인 프로그래밍 없이도 스스로 결정을 내리고 행동할 수 있다.
•
목표 지향성 : 특정 목표나 작업을 달성하기 위해 설계되어 있다.
•
환경 인식 : 주변 환경이나 상황을 인식하고 이에 따라 적응할 수 있다.
•
도구 사용 : 다양한 도구나 API를 활용하여 작업을 수행할 수 있다.
•
연속성 : 주어진 목표를 달성하기 위하여 1회 수행이 아닌 반복 수행을 통해 목표 달성을 추구한다.
LangChain 에이전트 구성요소
•
Tools : 에이전트가 사용할 수 있는 기능들의 집합
from langchain.tools import tool
@tool
def add(a:int, b:int) -> int:
return a + b
@tool
def minus(a:int, b:int) -> int:
return a - b
Python
복사
•
Toolkits : 관련된 도구들의 그룹
toolkit = [
add, minus
]
Python
복사
•
Agent : 의사 결정을 담당하는 핵심 컴포넌트
agent = create_openai_tools_agen(
llm, toolkit, prompt
)
Python
복사
•
AgentExecutor : 에이전트의 실행을 관리하는 컴포넌트
agent_executor = AgentExecutor(
agent=agent, tools=toolkit,
verbos=True
)
result = agent_executor.invoke({
"input":"what is 1 + 1"
})
Python
복사
활용 사례 (근데 이건 LLM이 하는거 아닌가?)
•
정보 검색 및 분석: 웹 검색, 데이터베이스 쿼리 등을 수행
•
작업 자동화: 복잡한 워크플로우를 자동으로 처리
•
고객 서비스: 질문에 답변하고 문제 해결
•
의사 결정 지원: 데이터를 분석하고 권장 사항을 제공
•
창의적 작업: 글쓰기, 코드 생성 등의 창의적 작업을 수행
장단점
•
장점
◦
복잡한 작업의 자동화
◦
유연성과 적응성 (이건 ㅇㅈ)
◦
다양한 도구와의 통합 가능성
•
단점
◦
제어와 예측 가능성의 어려움
◦
계산 비용과 리소스 요구사항
Agent의 작업 처리 순서도
•
Agent의 작업 수행 과정
1.
Input: 사용자가 Agent에게 작업을 할당한다.
2.
Thought: Agent가 작업을 완수하기 위해 무엇을 할지 생각한다.
3.
Action/Action Input: 사용할 도구를 결정하고, 도구의 입력(함수의 입력값)을 결정한다.
4.
Observation: 도구의 출력 결과를 관찰한다.
5.
관찰 결과 작업을 완료(Finish)했다는 판단에 도달할 때까지 2~4번 과정을 반복한다.
•
Agent Executor : LangChain에서 해당 과정을 처리하는 객체
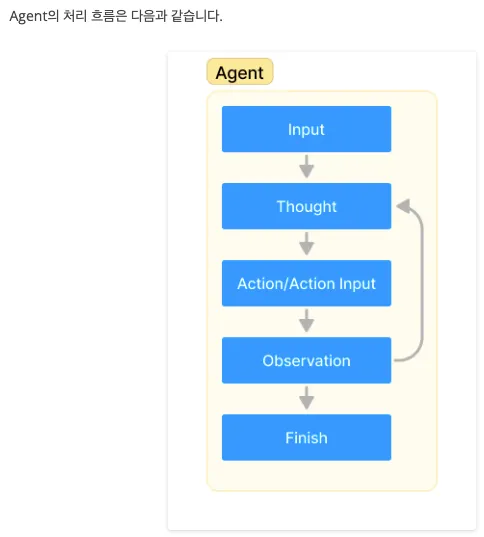
Agent 사용법
•
에이전트, 체인 또는 LLM이 외부 세계와 상호작용하기 위한 인터페이스
•
LangChain 에서 기본 제공하는 도구를 사용하여 쉽게 도구를 활용할 수 있으며, 사용자 정의 도구(Custom Tool) 를 쉽게 구축하는 것도 가능하다.
•
이 도구는 Python 코드를 REPL(Read-Eval-Print Loop) 환경에서 실행하기 위한 두 가지 주요 클래스를 제공한다.
from langchain_core.tools import Tool
from langchain_experimental.utilities import PythonREPL
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda
Python
복사
Tool 생성 & 사용법
•
tool 생성
python_tool = PythonREPL()
python_tool.run("print(1+1)")
Python
복사
•
tool 사용하는 함수 정의
# 파이썬 코드를 실행하고 중간 과정을 출력하고 도구 실행 결과를 반환하는 함수
def print_and_execute(code, debug=True):
if debug:
print("CODE:")
print(code)
return python_tool.run(code)
Python
복사
•
prompt 정의
# 파이썬 코드를 작성하도록 요청하는 프롬프트
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are Raymond Hetting, an expert python programmer, well versed in meta-programming and elegant, concise and short but well documented code. You follow the PEP8 style guide. "
"Return only the code, no intro, no explanation, no chatty, no markdown, no code block, no nothing. Just the code.",
),
("human", "{input}"),
]
)
Python
복사
•
LLM & chain 정의 후 실행
# LLM 모델 생성
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 프롬프트와 LLM 모델을 사용하여 체인 생성
chain = prompt | llm | StrOutputParser() | RunnableLambda(print_and_execute)
Python
복사
# 결과 출력
print(chain.invoke("로또 번호 생성기를 출력하는 코드를 작성하세요."))
CODE:
import random
def generate_lotto_numbers():
"""Generate a set of 6 unique lotto numbers from 1 to 45."""
return sorted(random.sample(range(1, 46), 6))
if __name__ == "__main__":
print(generate_lotto_numbers())
Python
복사
•
Langsmith 로그 확인
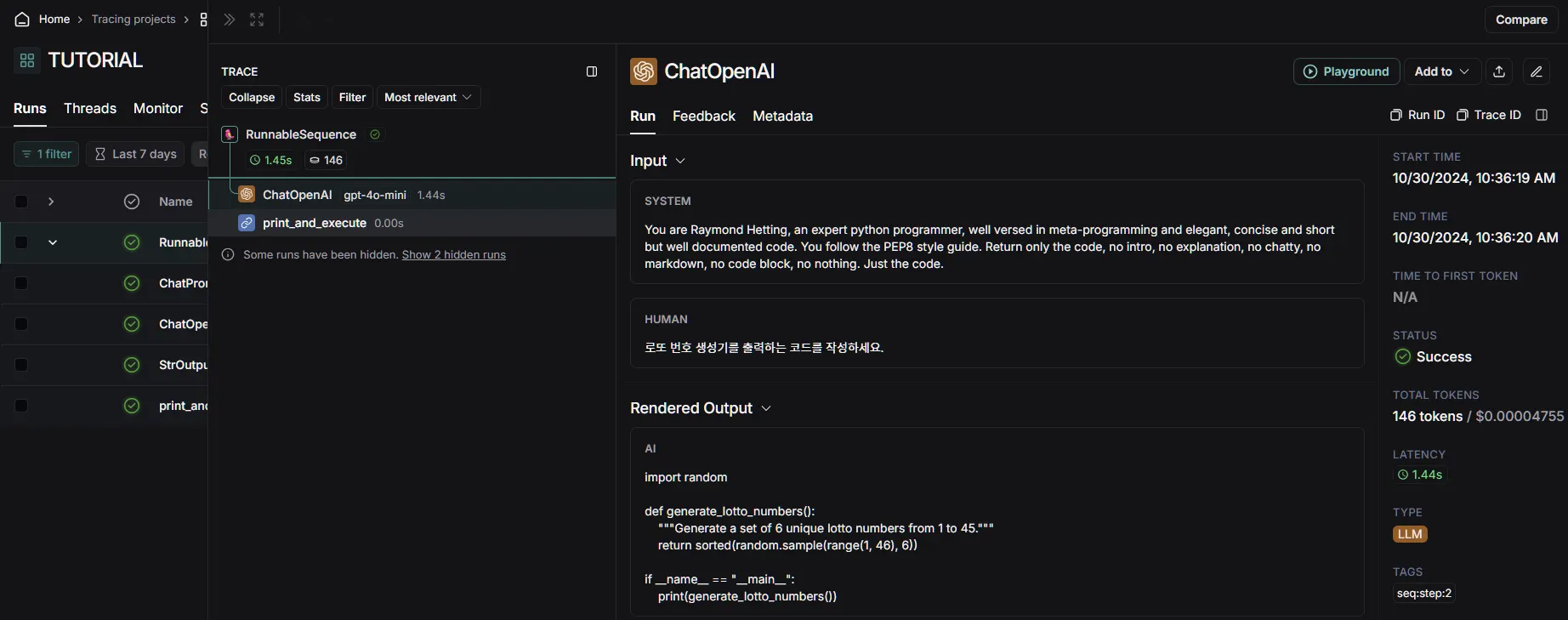
•
Tavily 검색 API를 활용하여 검색 기능을 구현하는 도구
LLMs의 한계점
•
대규모 언어 모델(Large Language Models, LLMs)은 자연어 처리 분야에서 혁명적인 발전을 이루었지만, 여전히 중요한 한계점을 가지고 있다. 그 중 하나는 최신 정보 처리의 어려움이다.
•
대부분의 LLM은 특정 시점까지의 데이터로 학습되어 있어, 그 이후의 정보나 실시간 변화하는 상황에 대해 정확한 답변을 제공하기 어렵습니다.
Tavily 주요 특징
•
AI 최적화: LLM과의 원활한 통합을 위해 설계되었습니다.
•
최신 정보: 실시간으로 업데이트되는 정보를 제공합니다.
•
다양한 검색 모드: 일반 검색, 뉴스 검색, 이미지 검색 등 다양한 모드를 제공합니다.
•
콘텐츠 필터링: 신뢰할 수 있는 소스의 정보만을 제공합니다.
•
무료 사용량: 월 1,000회의 무료 API 호출을 제공합니다.
# TAVILY API KEY를 기입
os.environ["TAVILY_API_KEY"] = ""
Python
복사
TavilySearchResults
•
Tavily 검색 API를 쿼리하고 JSON 형식의 결과를 반환
•
포괄적이고 정확하며 신뢰할 수 있는 결과에 최적화된 검색 엔진
•
현재 이벤트에 대한 질문에 답변할 때 유용
•
주요 매개변수
◦
max_results (int): 반환할 최대 검색 결과 수 (기본값: 5)
◦
search_depth (str): 검색 깊이 ("basic" 또는 "advanced")
◦
include_domains (List[str]): 검색 결과에 포함할 도메인 목록
◦
exclude_domains (List[str]): 검색 결과에서 제외할 도메인 목록
◦
include_answer (bool): 원본 쿼리에 대한 짧은 답변 포함 여부
◦
include_raw_content (bool): 각 사이트의 정제된 HTML 콘텐츠 포함 여부
◦
include_images (bool): 쿼리 관련 이미지 목록 포함 여부
from langchain_community.tools.tavily_search import TavilySearchResults
# 도구 생성
tool = TavilySearchResults(
max_results=6,
include_answer=True,
include_raw_content=True,
# include_images=True,
# search_depth="advanced", # or "basic"
include_domains=["github.io", "wikidocs.net"],
# exclude_domains = []
)
# 도구 실행
result = tool.invoke({"query": "LangChain Tools 에 대해서 알려주세요"})
> result
[{'url': 'https://wikidocs.net/253106',
'content': '도구(Tools) 02. 도구 바인딩(Binding Tools) 03. 에이전트(Agent) 04. Claude, Gemini, Ollama ... LangChain 에 대해서 알려주세요.\\n'},
{'url': 'https://wikidocs.net/262582',
'content': "LangChain 에서 기본 제공하는 도구를 사용하여 쉽게 도구를 활용할 수 있으며, 사용자 정의 도구(Custom Tool) 를 쉽게 구축하는 것도 가능합니다. LangChain 한국어 튜토리얼\\n바로가기 👀\\n[LangChain] 에이전트(Agent)와 도구(tools)를 활용한 지능형 검색 시스템 구축 가이드\\n2024년 02월 09일\\n41 분 소요\\n이 글에서는 LangChain 의 Agent 프레임워크를 활용하여 복잡한 검색과 📍 전체 템플릿 코드\\n다음의 추적 링크에서 자세한 단계별 수행 결과를 확인할 수 있습니다\\nLangSmith 추적\\n마무리입니다!\\n 문서 기반 QA 시스템 설계 방법 - 심화편\\n2024년 02월 06일\\n22 분 소요\\nLangChain의 RAG 시스템을 통...
> len(result) # 리스트 형태로 넘어오기 때문에 결과 개수를 반환할 수 있습니다.
6
Python
복사
•
해당 데코레이터는 함수를 도구로 변환하는 기능을 제공
•
다양한 옵션을 통해 도구의 동작을 커스터마이즈할 수 있다.
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
Python
복사
# Let's inspect some of the attributes associated with the tool.
print(multiply.name)
print(multiply.description)
print(multiply.args)
multiply
Multiply two numbers.
{'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}
Python
복사
Tool
•
실험을 위한 도구(tool) 를 정의
◦
get_word_length : 단어의 길이를 반환하는 함수
◦
add_function : 두 숫자를 더하는 함수
◦
naver_news_crawl : 네이버 뉴스 기사를 크롤링하여 본문 내용을 반환하는 함수
import re
import requests
from bs4 import BeautifulSoup
from langchain.agents import tool
# 도구를 정의합니다.
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
@tool
def add_function(a: float, b: float) -> float:
"""Adds two numbers together."""
return a + b
@tool
def naver_news_crawl(news_url: str) -> str:
"""Crawls a 네이버 (naver.com) news article and returns the body content."""
# HTTP GET 요청 보내기
response = requests.get(news_url)
# 요청이 성공했는지 확인
if response.status_code == 200:
# BeautifulSoup을 사용하여 HTML 파싱
soup = BeautifulSoup(response.text, "html.parser")
# 원하는 정보 추출
title = soup.find("h2", id="title_area").get_text()
content = soup.find("div", id="contents").get_text()
cleaned_title = re.sub(r"\n{2,}", "\n", title)
cleaned_content = re.sub(r"\n{2,}", "\n", content)
else:
print(f"HTTP 요청 실패. 응답 코드: {response.status_code}")
return f"{cleaned_title}\n{cleaned_content}"
tools = [get_word_length, add_function, naver_news_crawl]
Python
복사
bind_tools()
•
llm 모델에 bind_tools() 를 사용하여 도구를 바인딩
from langchain_openai import ChatOpenAI
# 모델 생성
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 도구 바인딩
llm_with_tools = llm.bind_tools(tools)
# 실행 결과
llm_with_tools.invoke("What is the length of the word 'teddynote'?").tool_calls
Python
복사
Chain
from langchain_core.output_parsers.openai_tools import JsonOutputToolsParser
# 도구 바인딩 + 도구 파서
chain = llm_with_tools | JsonOutputToolsParser(tools=tools)
# 실행 결과
tool_call_results = chain.invoke("What is the length of the word 'teddynote'?")
Python
복사
•
type: 도구의 이름
•
args: 도구에 전달되는 인자
print(tool_call_results, end="\n\n==========\n\n")
# 첫 번째 도구 호출 결과
single_result = tool_call_results[0]
# 도구 이름
print(single_result["type"])
# 도구 인자
print(single_result["args"])
tool_call_results[0]["type"], tools[0].name
Python
복사
def execute_tool_calls(tool_call_results):
"""
도구 호출 결과를 실행하는 함수
:param tool_call_results: 도구 호출 결과 리스트
:param tools: 사용 가능한 도구 리스트
"""
# 도구 호출 결과 리스트를 순회합니다.
for tool_call_result in tool_call_results:
# 도구의 이름과 인자를 추출합니다.
tool_name = tool_call_result["type"]
tool_args = tool_call_result["args"]
# 도구 이름과 일치하는 도구를 찾아 실행합니다.
# next() 함수를 사용하여 일치하는 첫 번째 도구를 찾습니다.
matching_tool = next((tool for tool in tools if tool.name == tool_name), None)
if matching_tool:
# 일치하는 도구를 찾았다면 해당 도구를 실행합니다.
result = matching_tool.invoke(tool_args)
# 실행 결과를 출력합니다.
print(f"[실행도구] {tool_name}\n[실행결과] {result}")
else:
# 일치하는 도구를 찾지 못했다면 경고 메시지를 출력합니다.
print(f"경고: {tool_name}에 해당하는 도구를 찾을 수 없습니다.")
Python
복사
bind_tools + Parser + Execution
•
llm_with_tools : 도구를 바인딩한 모델
•
JsonOutputToolsParser : 도구 호출 결과를 파싱하는 파서
•
execute_tool_calls : 도구 호출 결과를 실행하는 함수
from langchain_core.output_parsers.openai_tools import JsonOutputToolsParser
# bind_tools + Parser + Execution
chain = llm_with_tools | JsonOutputToolsParser(tools=tools) | execute_tool_calls
# 실행 결과
chain.invoke("What is the length of the word 'teddynote'?")
# 실행 결과
chain.invoke("114.5 + 121.2")
print(114.5 + 121.2)
# 실행 결과
chain.invoke(
"뉴스 기사 내용을 크롤링해줘: https://n.news.naver.com/mnews/hotissue/article/092/0002347672?type=series&cid=2000065"
)
Python
복사
•
도구 호출을 사용하면 모델이 하나 이상의 도구(tool) 가 호출되어야 하는 시기를 감지하고 해당 도구에 전달해야 하는 입력 으로 전달할 수 있다.
•
API 호출에서 도구를 설명하고 모델이 이러한 도구를 호출하기 위한 인수가 포함된 JSON과 같은 구조화된 객체를 출력하도록 지능적으로 선택할 수 있다.
•
도구 API의 목표는 일반 텍스트 완성이나 채팅 API를 사용하여 수행할 수 있는 것보다 더 안정적으로 유효하고 유용한 도구 호출(tool call) 을 반환하는 것
Tool 생성
from langchain.tools import tool
from typing import List, Dict, Annotated
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_experimental.utilities import PythonREPL
# 도구 생성
@tool
def search_news(query: str) -> List[Dict[str, str]]:
"""Search News by input keyword"""
news_tool = TavilySearchResults(
max_results=6,
include_answer=True,
include_raw_content=True,
# include_images=True,
# search_depth="advanced", # or "basic"
include_domains=["google.com", "naver.com"],
# exclude_domains = []
)
return news_tool.invoke({"query": query})
# 도구 생성
@tool
def python_repl_tool(
code: Annotated[str, "The python code to execute to generate your chart."],
):
"""Use this to execute python code. If you want to see the output of a value,
you should print it out with `print(...)`. This is visible to the user."""
result = ""
try:
result = PythonREPL().run(code)
except BaseException as e:
print(f"Failed to execute. Error: {repr(e)}")
finally:
return result
print(f"도구 이름: {search_news.name}")
print(f"도구 설명: {search_news.description}")
print(f"도구 이름: {python_repl_tool.name}")
print(f"도구 설명: {python_repl_tool.description}")
도구 이름: search_news
도구 설명: Search News by input keyword
도구 이름: python_repl_tool
도구 설명: Use this to execute python code. If you want to see the output of a value,
you should print it out with `print(...)`. This is visible to the user.
# tools 정의
tools = [search_news, python_repl_tool]
Python
복사
Prompt 생성
•
chat_history : 이전 대화 내용을 저장하는 변수 (멀티턴을 지원하지 않는다면, 생략 가능)
•
agent_scratchpad : 에이전트가 임시로 저장하는 변수
•
input : 사용자의 입력
from langchain_core.prompts import ChatPromptTemplate
# 프롬프트 생성
# 프롬프트는 에이전트에게 모델이 수행할 작업을 설명하는 텍스트를 제공합니다. (도구의 이름과 역할을 입력)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. "
"Make sure to use the `search_news` tool for searching keyword related news.",
),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)
Python
복사
Agent 생성
from langchain_openai import ChatOpenAI
from langchain.agents import create_tool_calling_agent
# LLM 정의
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Agent 생성
agent = create_tool_calling_agent(llm, tools, prompt)
Python
복사
AgentExecutor
•
도구를 사용하는 에이전트를 실행하는 클래스
•
주요 메서드
◦
invoke: 에이전트 실행
◦
stream: 최종 출력에 도달하는 데 필요한 단계를 스트리밍
•
주요 속성
◦
agent: 실행 루프의 각 단계에서 계획을 생성하고 행동을 결정하는 에이전트
◦
tools: 에이전트가 사용할 수 있는 유효한 도구 목록
◦
return_intermediate_steps: 최종 출력과 함께 에이전트의 중간 단계 경로를 반환할지 여부
◦
max_iterations: 실행 루프를 종료하기 전 최대 단계 수
◦
max_execution_time: 실행 루프에 소요될 수 있는 최대 시간
◦
early_stopping_method: 에이전트가 AgentFinish를 반환하지 않을 때 사용할 조기 종료 방법. ("force" or "generate")
◦
force: 시간 또는 반복 제한에 도달하여 중지되었다는 문자열을 반환
◦
generate: 에이전트의 LLM 체인을 마지막으로 한 번 호출하여 이전 단계에 따라 최종 답변을 생성
◦
handle_parsing_errors: 에이전트의 출력 파서에서 발생한 오류 처리 방법. (True, False, 또는 오류 처리 함수)
◦
trim_intermediate_steps: 중간 단계를 트리밍하는 방법. (-1 trim 하지 않음, 또는 트리밍 함수)
from langchain.agents import AgentExecutor
# AgentExecutor 생성
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
max_iterations=10,
max_execution_time=10,
handle_parsing_errors=True,
)
# AgentExecutor 실행
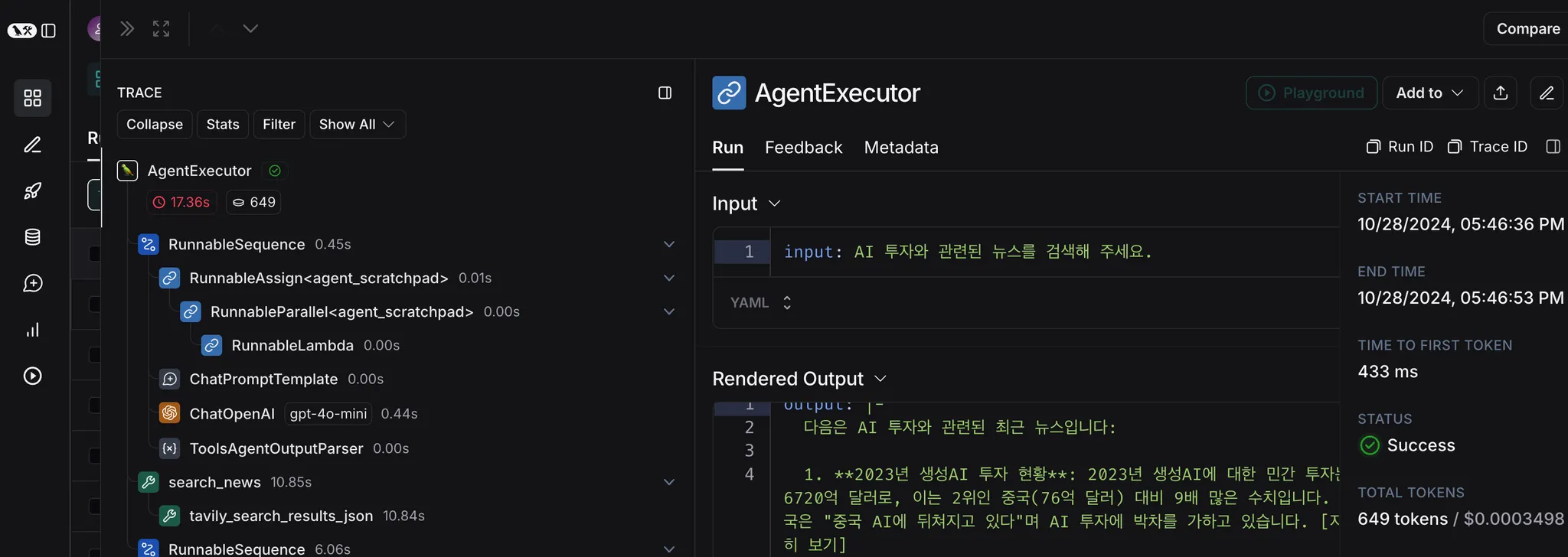
result = agent_executor.invoke({"input": "AI 투자와 관련된 뉴스를 검색해 주세요."})
print("Agent 실행 결과:")
print(result["output"])
Python
복사