



FAISS
•
Facebook에서 개발 및 배포한 밀집 벡터의 유사도 측정과 클러스터링에 효율적인 라이브러리
•
보통 벡터 유사도(vector similarity)를 구할 때는 numpy나 scikit-learn에서 제공해주는 cosine similarity 등을 많이 사용하는데, GPU를 지원하며, C++로 개발된 덕분에 Faiss를 사용하면 훨씬 빠르고 강력하게 유사도를 측정할 수 있다.
되짚기 - Similarity search란 무엇인가
•
특정한 차원을 가진 벡터들의 집합이 있을때, 데이터 구조들을 램 위에 올려두고 새로운 벡터가 들어 왔을때 거리가 가장 적은 벡터를 계산하는 것
◦
은 유클라디안 거리를 나타낸다.
FAISS 에서 data structure는 index라 한하며 객체들을와 더하기 위한 더하기 메서드를 가진다.
argmin을 구하는 것은 index에 대해서 search 연산을 하는것을 말한다.
FAISS의 기능 및 특징
•
nearest neighbor와 k-th nearest neighbor를 얻을 수 있다.
•
한번에 한 벡터가 아닌 여러 벡터를 검색할수 있다(batch processing). 여러 인덱스 타입들에서 여러 벡터를 차례로 검색하는것 보다 더 빠르다.
•
정확도와 속도 간에 트레이드 오프가 존재한다. 예를들어 10% 부정확한 결과를 얻는다고 할때, 10배 더 빠르거나, 10배 더 적은 메모리를 사용할 수 있다.
•
유클라디안 거리를 최소화 하는 검색이 아닌 maximum inner product가 최대로 되는 방식으로 계산한다. (다른 거리들을 구하는데는 제한 사항들이 있으니 공식 문서 참고)
•
query point에서 주어진 radius에 포함되는 모든 element들을 반환한다.
•
인덱스는 디스크에 저장 된다.
인덱스 및 식별자에 대한 이해
•
Faiss가 벡터의 식별자를 처리하는 방법
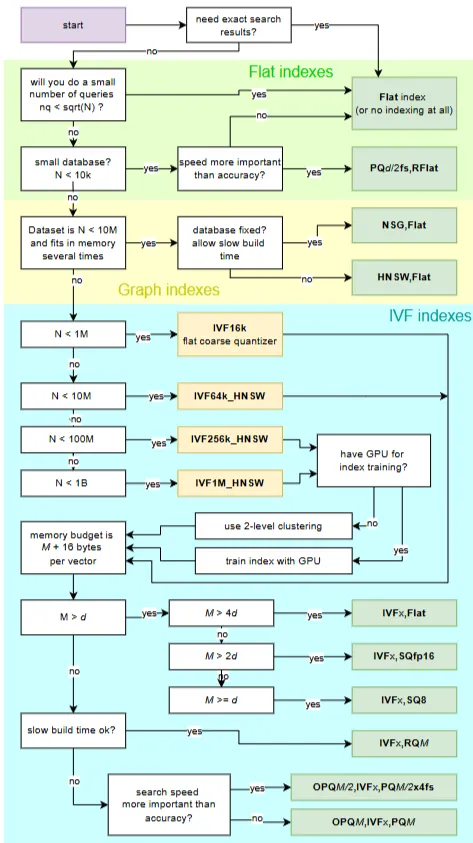
의사 결정 트리를 사용해 파이스 인덱스를 선택하는 과정 - CPU에서 유클리드 k-최근접 이웃 검색의 일반적인 경우를 위한 것
•
식별자 유형
◦
순차 ID
▪
벡터가 색인에 추가되는 순서에 따라 할당되는 간단한 숫자
▪
콘서트에 입장하기 위해 사람들이 줄지어 서 있는 것처럼 생각해보자
▪
첫 번째 사람은 숫자 1을, 두 번째 사람은 숫자 2를 받는 식
•
이렇게 하면 주문을 쉽게 추적할 수 있다.
◦
임의의 63비트 정수 ID
▪
사용자는 고유한 숫자 (최대 63비트 길이) 를 생성하여 각 벡터를 식별할 수도 있다.
▪
이는 콘서트 라인에 있는 각 사람에게 숫자가 아닌 특별한 이름표를 부여하는 것과 같다.
▪
이러한 ID는 63비트 한도 내에 해당하는 숫자라면 원하는 숫자로 지정할 수 있다.
•
FAISS 인덱스에 벡터를 추가하는 방법
◦
Add
▪
해당 메서드는 특정 ID 없이 벡터를 추가하기만 하면 된다.
▪
순차 ID 시스템을 사용
◦
ID로 추가
▪
이 방법을 사용하면 고유한 ID와 함께 벡터를 추가할 수 있다.
▪
이는 자체 네이밍 시스템을 사용하여 어떤 벡터가 어떤 벡터인지 추적하려는 경우에 유용
•
벡터 제거 및 업데이트
◦
Faiss를 사용하면 벡터를 추가한 후에도 벡터를 관리할 수 있다.
◦
ID 제거
▪
벡터를 삭제하려는 경우 해당 ID를 사용하여 삭제할 수 있다.
▪
이는 게스트 목록에서 누군가를 지우는 것과 같다.
◦
벡터 업데이트
▪
벡터를 변경해야 하는 경우 벡터의 ID를 사용하여 업데이트할 수 있다.
▪
이는 네임태그의 정보를 변경하는 것과 비슷하다.
사용 과정
1.
임베딩된 벡터 준비
2.
인덱스 생성
3.
검색
