.gif&blockId=11b00c82-b138-8050-a58b-dcbceda2ef8f)



개요
•
정보(데이터)는 다양한 형태로 제공된다.
•
텍스트 문서, 리치 미디어, 오디오와 같이 비정형 정보도 있고 애플리케이션 로그, 테이블, 그래프와 같이 정형화된 정보도 있다.
•
인공 지능과 기계 학습(AI/ML)의 혁신을 통해 일종의 ML 모델인 임베딩 모델을 만들 수 있었다.
•
임베딩은 모든 유형의 데이터를 자산의 의미와 컨텍스트를 캡처하는 벡터로 인코딩한다.
•
이를 통해 인접 데이터 포인트를 검색하여 유사한 자산을 찾을 수 있다.
•
벡터 검색 방법을 사용하면 스마트폰으로 사진을 찍고 비슷한 이미지를 검색하는 등 고유한 경험을 할 수 있다.
벡터 데이터베이스
•
벡터를 고차원 포인트로 저장하고 검색하는 기능을 제공
•
N차원 공간에서 가장 가까운 이웃을 효율적이고 빠르게 조회할 수 있는 추가적인 기능을 추가
•
일반적으로 k-NN(k-Nearest Neighbor) 인덱스로 구동되며 계층적 탐색 가능한 소규모 세계(HNSW) 및 반전된 파일 인덱스(IVF) 알고리즘과 같은 알고리즘으로 구축된다.
•
벡터 데이터베이스는 데이터 관리, 내결함성, 인증 및 액세스 제어, 쿼리 엔진과 같은 추가 기능을 제공한다.
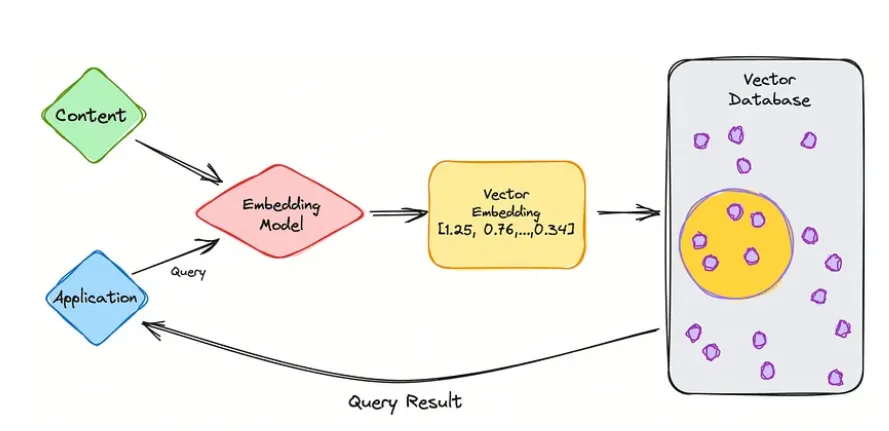
Database 종류
Vector Embedding
•
벡터 임베딩은 텍스트, 이미지, 영상, 오디오 등 다양한 유형의 데이터를 컴퓨터가 이해하고 처리할 수 있도록 수치 형태로 변환하는 방법
•
이 변환 과정은 사람이 직접 정의하는 것이 아니라, 데이터를 AI 모델에 입력하여 모델 스스로가 해당 데이터를 의미 있는 벡터로 변환한다.
•
그리고 벡터 임베딩을 통해 데이터는 고차원 공간에서 저차원의 벡터로 변환된다.
•
이 과정에서 차원은 축소되면서도, 데이터의 중요한 정보와 패턴은 보존된다.
•
이를 통해 컴퓨터는 데이터를 효과적으로 분석하여, 벡터 간의 유사성 또는 패턴을 파악이 가능해진다.
데이터 유형별 임베딩 과정
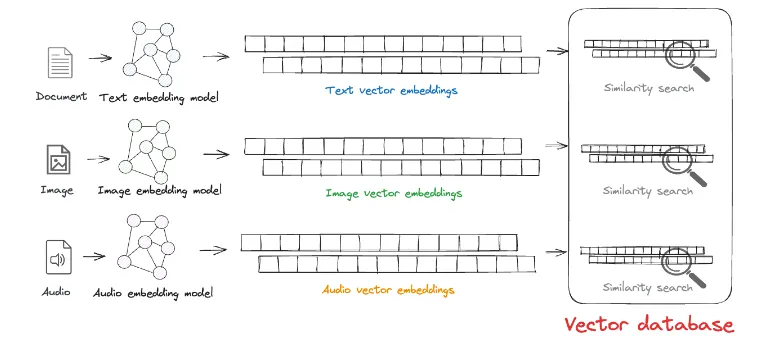
1.
텍스트 데이터 (Document):
•
텍스트 임베딩 모델을 사용하여 텍스트 데이터를 벡터 형태로 변환한다.
•
이 과정에서 텍스트는 단어 또는 문장 간의 의미를 수치로 표현한 텍스트 벡터 임베딩으로 변환된다.
2.
이미지 데이터 (Image):
•
이미지 임베딩 모델을 사용하여 이미지 데이터를 벡터로 변환한다.
•
이 벡터는 이미지의 특징을 수치로 표현하여, 이미지 간 유사도를 측정하거나 분류하는 데 사용된다.
3.
오디오 데이터 (Audio):
•
오디오 임베딩 모델을 사용하여 오디오 데이터를 벡터로 변환한다.
•
이 벡터는 오디오의 특징 (예: 음색, 주파수 패턴 등)을 나타내며, 이를 통해 오디오 파일 간의 유사도를 비교할 수 있다.
•
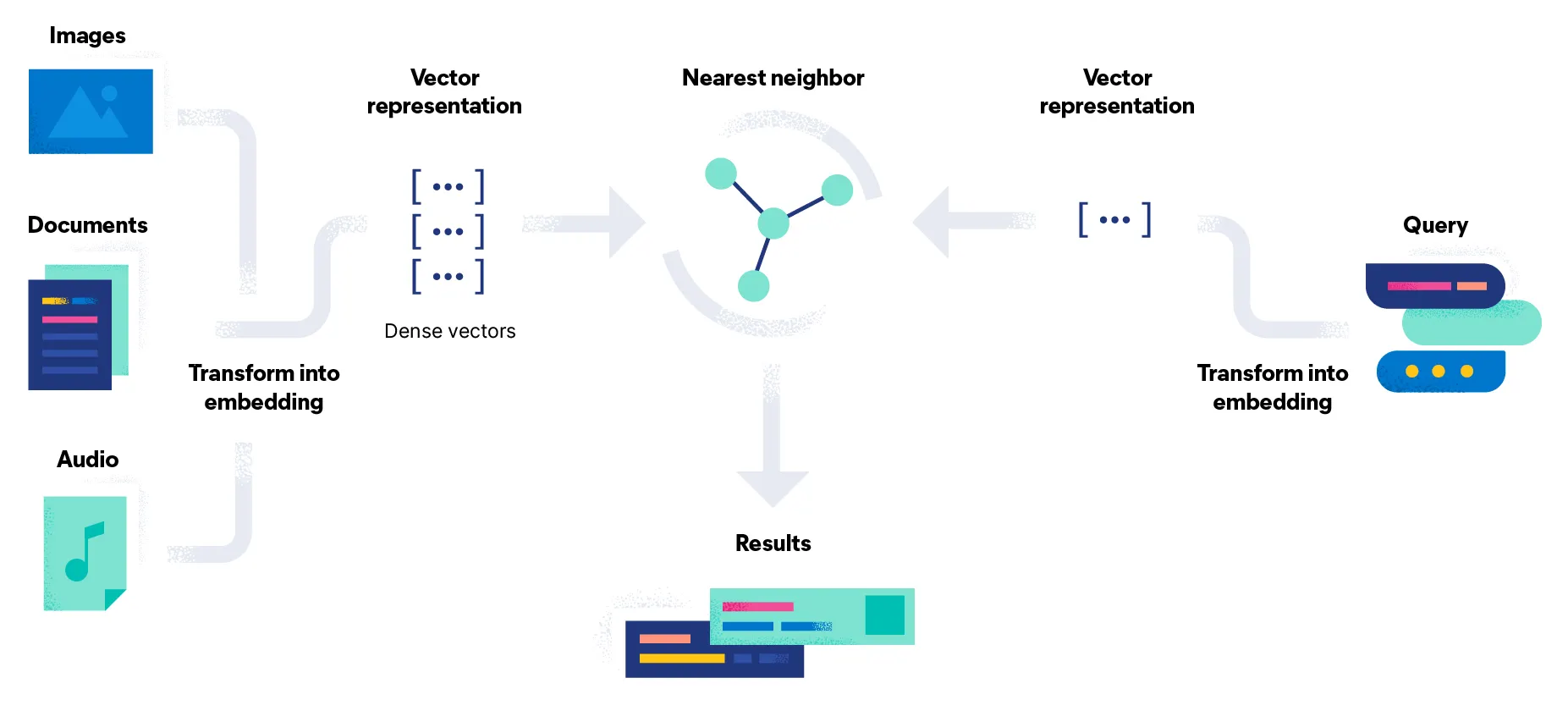
관계형 데이터베이스는 쿼리와 정확히 일치하는 행을 찾아 반환한다.
•
반면, 벡터 데이터베이스에서는 유사도 메트릭(Similarity Metrics)을 적용하여 가장 유사한 벡터를 찾는다.
•
벡터 데이터베이스의 일반적인 파이프라인은 다음과 같다.
elastic

1.
색인(Indexing)
•
PQ, LSH, HNSW와 같은 알고리즘을 사용하여 벡터를 색인한다.
•
이 단계에서는 더 빠른 검색을 가능하게 하는 데이터 구조에 벡터를 매핑한다.
2.
쿼리(Querying)
•
유사도 메트릭(코사인 유사도, 유클리디안 거리, 내적 등)을 적용하여 가장 가까운 벡터를 찾는다.
코사인 유사도(Cosine Similarity)
•
두 벡터 간의 각도를 측정하여 유사성을 판단
•
두 벡터가 얼마나 같은 방향으로 향하고 있는지를 나타낸다.
•
값은 -1 ~ 1 사이에 있으며, 값이 1에 가까울수록 두 벡터는 유사하고, -1에 가까울수록 반대 방향에 있는 것을 나타낸다.
유클리디안 거리(Euclidean Distance)
•
두 벡터 간의 직선 거리를 측정
•
값은 항상 0 이상이며, 두 벡터 간의 거리가 짧을수록 유사성이 높다고 판단
내적(Dot Product)
•
두 벡터 간의 곱셈 연산을 통해 유사성을 측정
•
두 벡터가 얼마나 유사한 방향을 가지고 있는지를 나타낸다.
•
두 벡터가 유사한 방향을 가지면 양수이고, 반대 방향을 가지면 음수이며, 두 벡터가 직교하면 0
3.
후처리(Post Processing)
•
데이터셋에서 최종 최근접 이웃을 검색하고 이를 후처리하여 최종 결과를 반환
•
일부 벡터 데이터베이스는 벡터 검색을 하기 전에 필터를 적용할 수 있다.
•
필터링 과정
1.
사전 필터링
•
벡터를 검색하기 전에 메타데이터 필터링이 수행
•
이 방식은 검색량을 줄이는 데 도움이 될 수 있다.
•
그러나 메타데이터 필터링 기준에 부합하지 않지만 실제 연관이 있는 결과를 놓칠 수 있으며, 광범위한 메타데이터 필터링으로 인해 추가 오버헤드가 발생하여 쿼리 수행이 느려질 수 있다.
2.
사후 필터링
•
벡터를 검색한 후에 메타데이터 필터링이 수행된다.
•
이 방식은 연관된 모든 결과를 추출하는 데 도움이 되지만, 검색이 완료된 후 관련 없는 결과를 필터링해야 하므로 추가 오버헤드가 발생하고 쿼리 프로세스가 느려질 수 있다.
•
벡터 인덱스 생성에서 사용하는 알고리즘
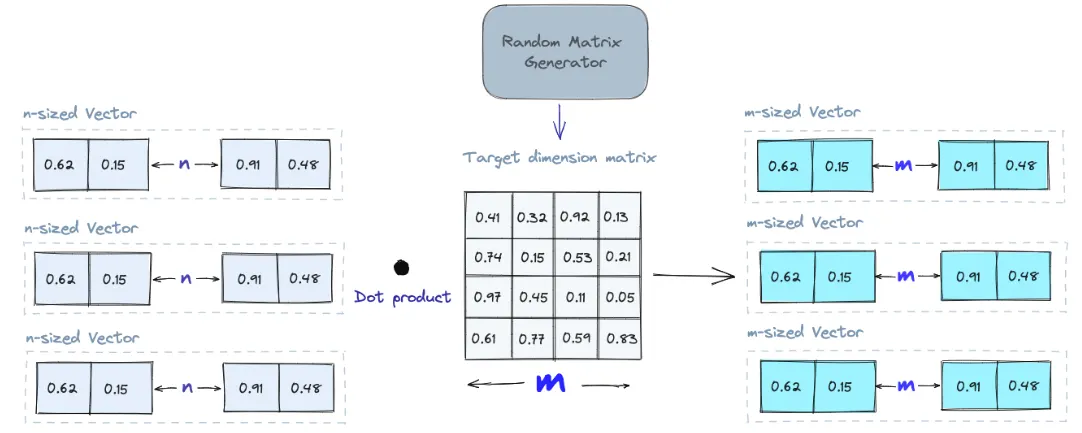
Random Projection
•
무작위 투영의 기본 아이디어는 무작위 투영 행렬을 사용하여 고차원 벡터를 저차원 공간에 투영하는 것
1.
난수 행렬을 만든다.
2.
행렬의 크기는 우리가 원하는 목표 저차원 값이 될 것이다.
3.
그런 다음 입력 벡터와 행렬의 내적을 계산하여 원래 벡터보다 차원이 적지만 유사성을 유지하는 투영 행렬을 생성한다.
Product Quantization
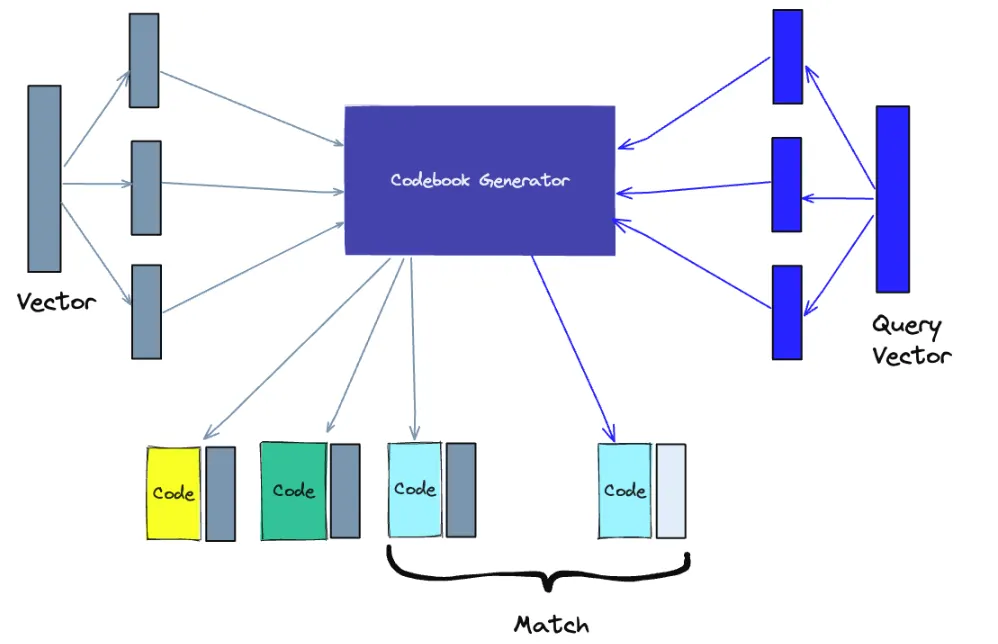
•
벡터 임베딩과 같은 고차원 벡터에 대한 손실 압축 기술인 제품 양자화(PQ)
•
원본 벡터를 가져와서 더 작은 청크로 나누고 각 청크에 대한 대표 "코드"를 생성하여 각 청크의 표현을 단순화한 다음 유사성 작업에 중요한 정보를 잃지 않고 모든 청크를 다시 결합하는 것
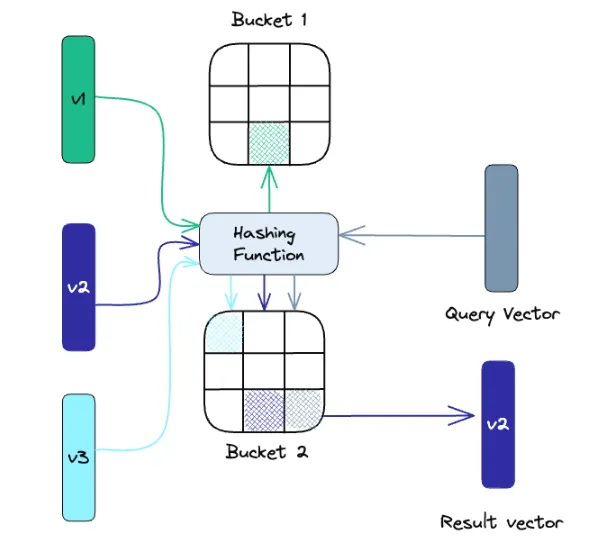
Loclity-sensitive hashing
•
LSH(Locality-Sensitive Hashing)는 근사 최근접 이웃 검색 컨텍스트에서 인덱싱하는 기술
•
속도에 최적화되어 있으면서도 대략적이고 포괄적이지 않은 결과를 제공한다.
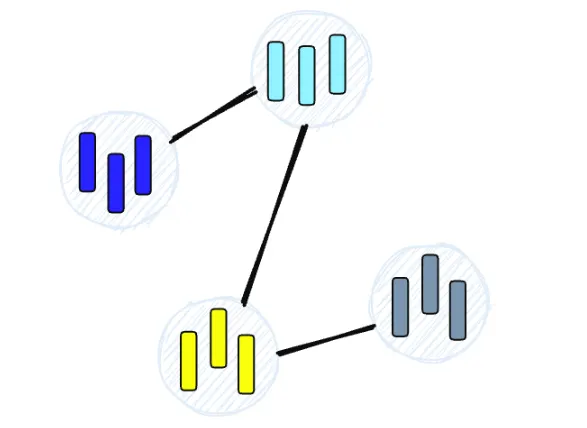
Hierarchical Navigable Small World (HSNW)
•
HSNW는 트리의 각 노드가 벡터 세트를 나타내는 계층적 트리와 같은 구조를 생성
•
노드 사이의 모서리는 벡터 간의 유사성을 나타낸다.
메타데이터를 통한 필터링
Post-filtering
•
벡터 검색 후에 메타데이터 필터링이 수행된다.
•
이렇게 하면 모든 관련 결과를 고려하는 데 도움이 될 수 있지만 검색이 완료된 후 관련 없는 결과를 필터링해야 하므로 추가 오버헤드가 발생하고 쿼리 프로세스 속도가 느려질 수도 있다.
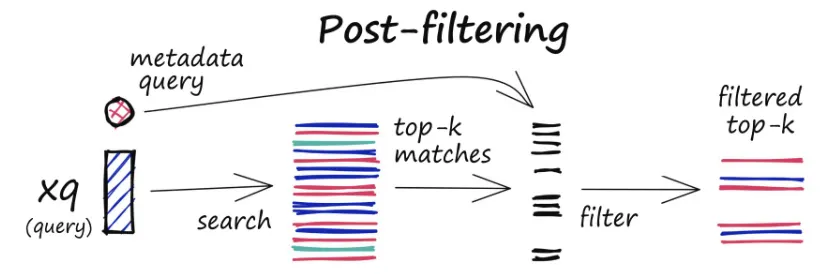
Pre-filtering
•
벡터 검색 전에 메타데이터 필터링이 수행된다.
•
이렇게 하면 검색 공간을 줄이는 데 도움이 되지만 시스템에서 메타데이터 필터 기준과 일치하지 않는 관련 결과를 간과할 수도 있다.
•
또한 광범위한 메타데이터 필터링으로 인해 계산 오버헤드가 추가되어 쿼리 프로세스가 느려질 수 있다.
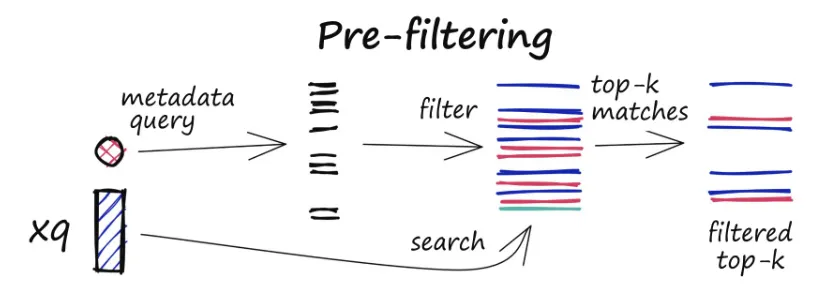
Chroma
•
LLM(대규모 언어 모델) 애플리케이션 개발을 간소화하도록 설계된 오픈 소스 임베딩 데이터베이스
•
이 솔루션의 핵심은 LLM을 위한 지식, 사실, 기술을 쉽게 통합할 수 있도록 하는 데 있다.
•
Chroma DB에 대해 자세히 살펴보면 텍스트 문서를 손쉽게 처리하고, 텍스트를 임베딩으로 변환하고, 유사도 검색을 수행할 수 있는 기능을 확인할 수 있다.
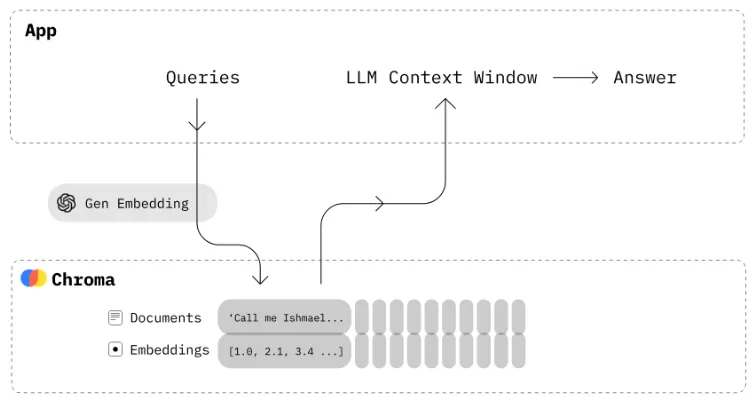
•
오픈소스X
•
간단한 API를 통해 사용자가 관리하는 클라우드 기반 벡터 데이터베이스로, 인프라 설정이 필요하지 않다.
•
Pinecone을 사용하면 인프라 유지 관리, 서비스 모니터링, 알고리즘 문제 해결 등의 번거로운 작업 없이도 AI 솔루션을 시작, 관리, 개선할 수 있다.
•
데이터를 신속하게 처리하고 사용자가 메타데이터 필터와 희소 밀도 인덱스를 지원하여 다양한 검색 요구사항에 걸쳐 정확하고 신속한 결과를 보장한다.
Weaviate
•
오픈 소스 벡터 데이터베이스
•
선호하는 ML 모델의 데이터 오브젝트와 벡터 임베딩을 간편하게 저장할 수 있다.
•
이 다용도 도구는 수십억 개의 데이터 개체를 번거로움 없이 관리할 수 있도록 원활하게 확장
•
수백만 개의 항목에 대해 밀리초 이내에 10-NN(10개의 가장 가까운 이웃) 검색을 신속하게 수행한다.
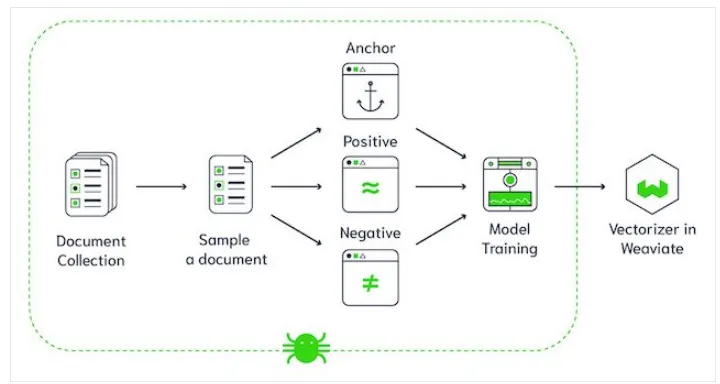
FAISS (Facebook AI Similarity Search)
•
유사점을 신속하게 검색하고 밀집된 벡터의 클러스터링을 위한 오픈 소스 라이브러리
•
주요 개발은 Meta의 Fundamental AI Research 그룹에서 수행
•
여기에는 RAM 용량을 초과할 수 있는 벡터 세트까지 다양한 크기의 벡터 세트 내에서 검색할 수 있는 알고리즘이 포함되어 있다.
•
또한 Faiss는 평가 및 매개변수 조정을 위한 보조 코드를 제공
•
주로 C++로 코딩되었지만 Python/NumPy 통합을 완벽하게 지원
•
주요 알고리즘 중 일부는 GPU 실행에도 사용할 수 있다.
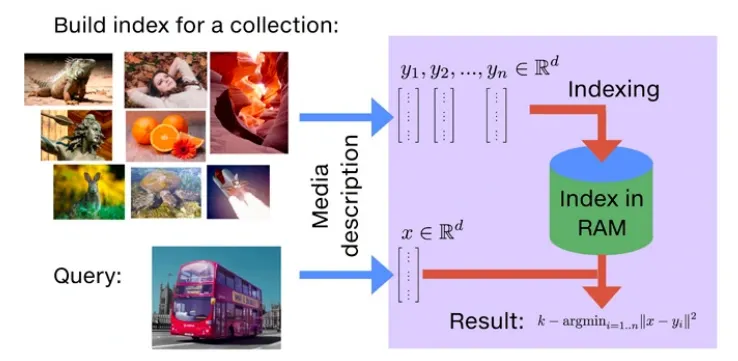
Qdrant
•
가장 최신에 나온 벡터 DB
•
벡터 데이터베이스 역할을 하며, 벡터 유사성 검색을 쉽게 수행할 수 있도록 도와줌.
•
API 서비스를 통해 운영되며, 가장 밀접하게 관련된 고차원 벡터를 쉽게 검색할 수 있다.
•
주요 특징
◦
다목적 API: OpenAPI v3 사양과 다양한 언어에 대한 기성 클라이언트를 제공
◦
속도와 정확성: 빠르고 정확한 검색을 위해 맞춤형 HNSW 알고리즘을 사용
◦
고급 필터링: 관련 벡터 페이로드를 기반으로 결과 필터링을 허용
◦
다양한 데이터 유형: 문자열 일치, 숫자 범위, 지리적 위치 등을 지원
◦
확장성: 수평적 확장 기능을 갖춘 클라우드 네이티브 디자인
◦
효율성: Rust가 내장되어 있어 동적 쿼리 계획을 통해 리소스 사용 최적화
