



RAG
•
LLM의 할루시네이션을 최소화하는 가장 좋은 방법
•
Retrieveal Augmented Generation
•
LLM의 외부지식을 잘 알맞게 맞춰서 LLM에게 Feeding하는 기술
RAG를 사용하는 이유
•
LLM은 결국 AI 학습 모델이기 때문에 학습되지 않은 거 모른다. 그래서 LLM이 모든 것을 알 수는 없다.
•
이 때 LLM이 모르는 것을 LM에게 동적으로 잘 전달해 주는 기술이 바로 RAG이다.
•
사용자가 말한 의도를 잘 파악해서 그때 필요한 LLM이 모르는 자료들을 그게 문서가 되었건 외부의 웹이 되었건 데이터베이스가 되었건 어떤 다른 서버의 API를 통해서 가지고 오는 게 되었건 LM의 외부의 지식을 가장 잘 다이내믹하게 구성해서 유저 의도에 맞춰서 LLM에게 Feeding하는 기술로 만들어 진게 RAG이다.
예제 : LLM이 2024년 1월까지 학습된 경우
2024년 10월에 개정된 법령을 요약해서 알려줘.에 대한 답변을 할 수 없다.
이 때 RAG로 개정된 법령에 대해서 학습을 시켜줘야만 LLM이 이를 알 수 있다.
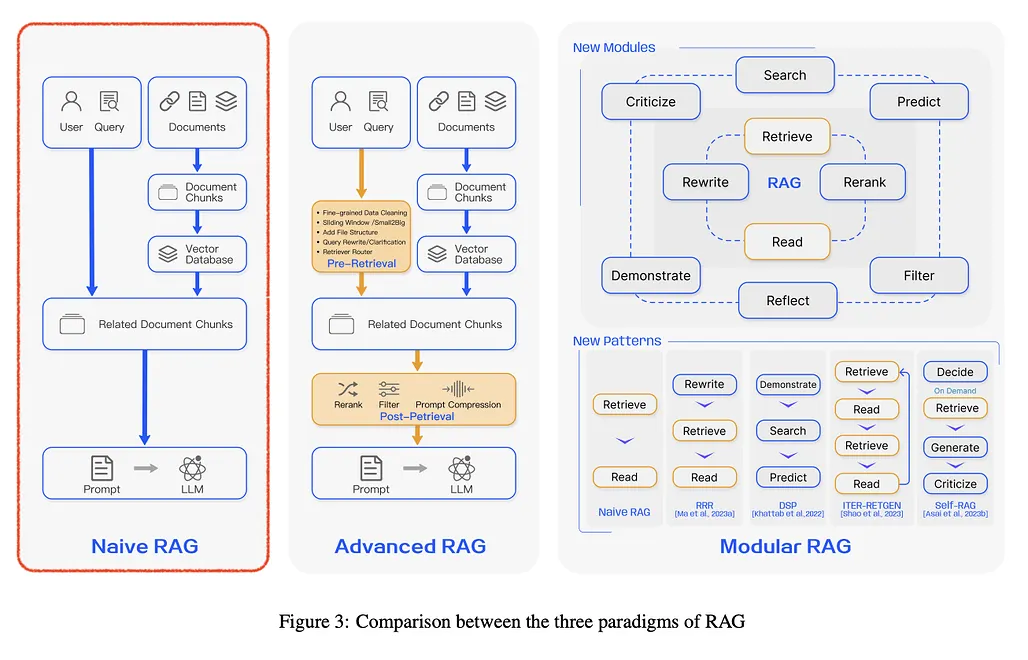
Naive RAG (단순 튜토리얼)
•
RAG의 컨셉을 그냥 그대로 구현한 것
•
현재(2024.11 기준) 기업들이 가장 많이 사용하고 있는 RAG.
•
생각보다 성능이 잘 안나온다며 해당 RAG에 대해 문의하는 경우가 많다.
동작 과정
Indexing - 청킹
1.
RAW Data 추출
2.
다양한 파일 형식을 표준화된 Plain Text로 변환
3.
청킹(Chunking)
•
LLM은 한 번에 처리할 수 있는 텍스트의 최대 길이에 제한이 있기 때문에 청크로 나누게 된다.
•
올거나이즈사에서 가장 좋다고 느껴진 청킹 사이즈는 페이지 단위이다.
4.
Vector Store
•
청킹을 하였다면 다음 잘라진 청크는 다시 Vector로 바꾼다.
•
Vector화 된 청크는 Vector DB에 키-값 쌍으로 저장된다.

이 과정에서 생긴 Vector DB는 이후 Retreival 단계에서 Efficient하고 Scalable search capabilities(효율적이고 확장 가능) 기능을 제공한다.
Retrieval
•
이후 사용자 쿼리는 외부 지식 소스인 Vector DB로부터 관련 문맥을 검색하는데 활용이 된다.
•
유저가 질문을 한다면 사용자 쿼리는 인코딩 모델에 의해 처리되어 의미적으로 관련된 임베딩을 생성하게 된다.
•
그다음 벡터화된 쿼리는 Vector DB에서 유사성 검색을 수행하여 가장 비슷한 데이터를 찾게 된다.
Generation (prompt → LLM → Output)
•
사용자의 쿼리와 검색된 추가 정보는 프롬프트에 입력되고 LLM을 거쳐 답변을 생성하게 된다.
문제점
Indexing
•
정보 추출의 불안정성
◦
PDF와 같은 비정형 파일 내 이미지와 표에 있는 유용한 정보를 효과적으로 처리하지 못한다.
•
청킹 방법
◦
청킹 과정에서 파일 유형의 특성을 고려하지 않고 "one-size-fits-all" 을 사용하는 것이 다반사
◦
이는 각 청크에 일관성과 불필요한 의미 정보가 포함될 가능성이 크며, 기존 텍스트의 문단 구분과 중요한 세부 사항을 놓치게 된다.
•
비최적화 인덱싱 구조
◦
인덱싱 구조가 최적화되지 않아 비효율적인 검색 기능을 초래하게 되며, 이는 검색 속도를 현저하게 느리게 만들고 검색 결과의 정확성을 떨어지게 만든다.
•
임베딩 모델의 의미 표현 능력
◦
임베딩 모델이 텍스트의 의미를 제대로 파악하지 못해, 검색된 정보의 관련성이 낮아진다.
◦
이는 중요한 정보를 놓칠 수 있게 된다.
Retrieval
•
제한된 검색 알고리즘
◦
키워드, 의미, 벡터 검색을 결합하지 않은 등 다양한 검색이나 알고리즘의 통합이 제한적이며, 이는 검색 결과의 다양성과 정확성을 저하시킨다.
•
쿼리 및 임베딩 모델의 한계
◦
쿼리가 부족하거나 임베딩 모델의 의미 표현 성능이 낮아 유용한 정보를 검색하지 못한다.
•
답변 정보 중복
Generation
•
잘못된 응답 생성
•
잘못된 정보 제공
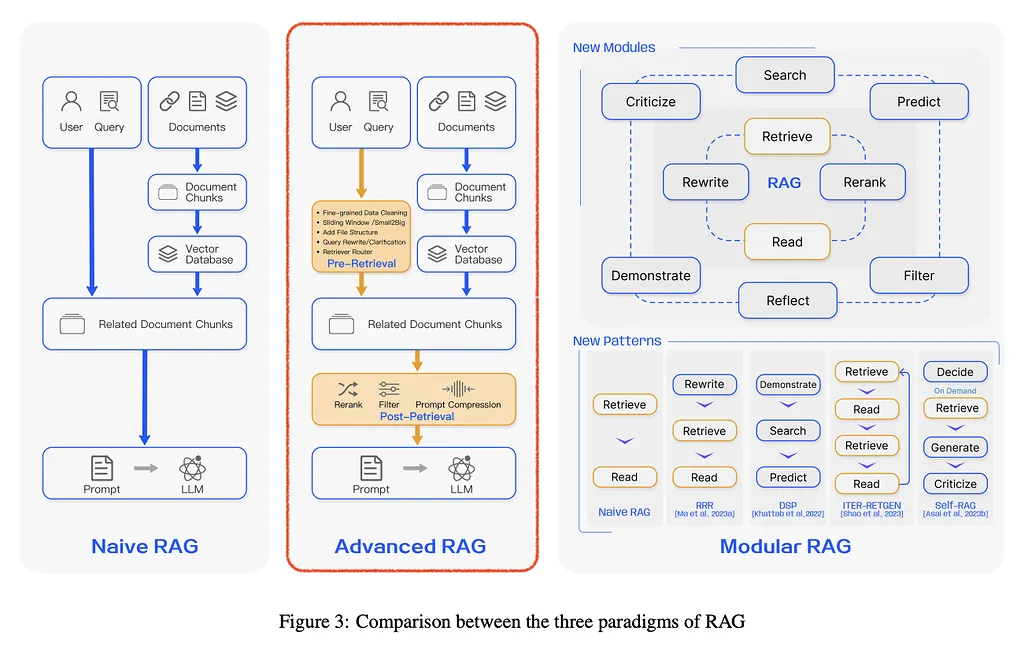
Advanced RAG
•
대체로 할루시네이션은 Retriever 문제이다.
•
Retriever에서 틀린 정보를 준다면 LLM의 고조증조할아버지가 와도 잘못된 정보를 반환함
•
근본적으로 Retriever가 잘못된 정보를 넘겨주면LLM이 답을 맞출 수 없다.
•
할루시네이션을 최소화하려면 프롬프트 엔지니어링이 적절히 나와야 함
동작 과정
Pre-Retrieval (Optimization)
•
사용 이유
◦
회사마다 문서의 스타일이 되게 다르고 문서의 제목을 붙이는 스타일조차 회사가 되게 다르다.
◦
어디는 되게 특이한 DRM 시스템을 써서 뭔가 내가 저장을 하면 그 뒤에 고유한 아이디 같은 게 붙고 의미를 알 수 없는 숫자가 이렇게 막 들어가 있으면 이 벡터들을 잘 못 찾는다.
◦
그래서 해당 회사(프로젝트)의 문서 스타일에 맞게 Optimize하는 것이 중요하다.
•
색인 구조와 사용자 쿼리를 개선하는 목적의 용도
특히 RAG에 들어가는 프롬프트 들은 할루시네이션을 최소화해야 되기 때문에 “컨텍스트에 주어진 대로 컨텍스트에 기반해서만 답해”, “너의 지식에 기반해서 답하면 안 돼”라고 명시하는 것이 중요하다.
•
예를 들어 B2B 프로덕트에서 혹시라도 틀린 정보를 그럴 듯하게 직원에게 알려줘서 직원이 그 틀린 정보를 가지고 고객에게 안내해서 가입할 경우 소송이 되고 이런 문제는 의료나 법률 같은 경우로 가면 훨씬 더 크리티컬한 문제가 된다.
•
종류
◦
데이터 인덱싱 최적화(Optimizing Data Indexing)
◦
임베딩(Embedding)
◦
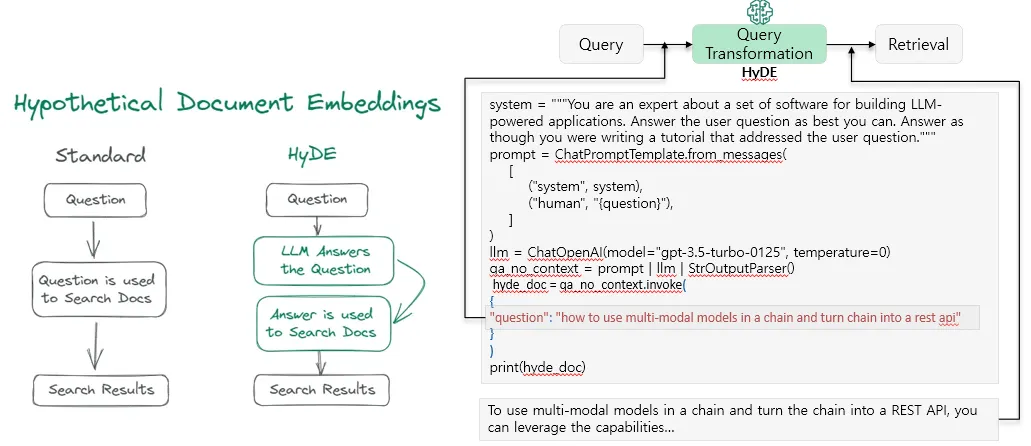
HyDE(Hypothetical Document Embedding)
▪
사용자 query를 Vector DB와 같은 지식 검색소 검색 전, LLM에 주입하여 가상의 답변을 얻고,query 대신 가상 답변으로 검색하여 Context를 얻는 기술
▪
가상 답변은 query 대비, 풍부한 정보를 담고 있어 지식 검색 시, 더 많은 정보를 담은 context를 얻을 수 있다.
◦
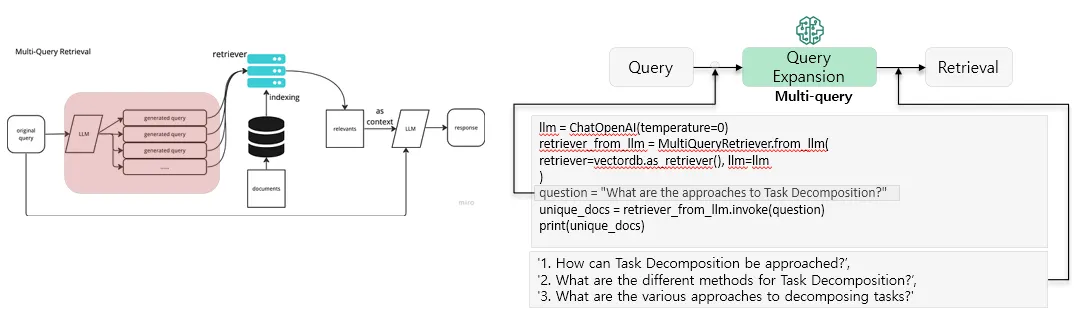
Multi-query
▪
LLM을 사용하여 주어진 사용자 입력 쿼리에 대해 다양한 관점에서 여러 쿼리로 생성하여 검색함으로써 기존 단일 검색의 한계를 극복하고 더 풍부한 결과를 얻을 수 있는 기술
◦
Text-to-SQL
▪
LLM을 사용하여 주어진 입력 쿼리를 SQL로 변환함으로써 Vector DB 외에도 RDBMS를 검색 가능하게 만드는 기술

Post-Retrieval
•
데이터베이스에서 검색된 중요한 문맥을 질의와 결합하여 LLM에 입력하는 과정
•
관련된 정보(청크)들을 Vector Database 내에서 검색한 후, 쿼리와 함께 LLM에 입력된다.
•
하지만 문제는 검색된 청크들이 간혹 중복이 되거나 의미 없는 정보를 담는 경우 발생하게 되는데, 이는 LLM이 주어진 컨텍스트를 처리하는 방식에 영향을 미칠 수 있다.
•
또한 LLM의 컨텍스트 윈도우(context window) 크기를 초과할 수도 있고 비효율적이다.
•
그래서 “어떻게 Retriever가 틀린 거를 그 자리에서 고칠 수 있냐”에서 고안된 게 바로 Post-Retrieval이다.
•
Re-ranking
◦
검색된 정보를 재순위하여 가장 관련성 높은 답변을 우선시하는 것.
◦
이에 검색된 청크를 재정렬하고 Top-K 가장 관련성 높은 청크를 식별하여 LLM에 사용할 컨텍스트로 제공한다.
◦
기존에는 후보를 예를 들면 5개를 뽑아서 그 컨텍스에 5개를 준다고 할 때,
◦
Re-ranking에선 10개 20개를 뽑은 다음에 이제 틀렸던 것들에 대한 거를 뭔가 사용자가 피드백을 줬다거나 하면 거기에 다시 또 Vector 유사도를 비교해서 랭킹을 다시 올리는 방식이다.
◦
처음엔 틀렸더라도 두 번째부터는 이게 바로 반영되게 하는 게 포스트 리트리벌에 들어가는 가장 중요한 테크닉이다.
RAG and LLM Finetuning
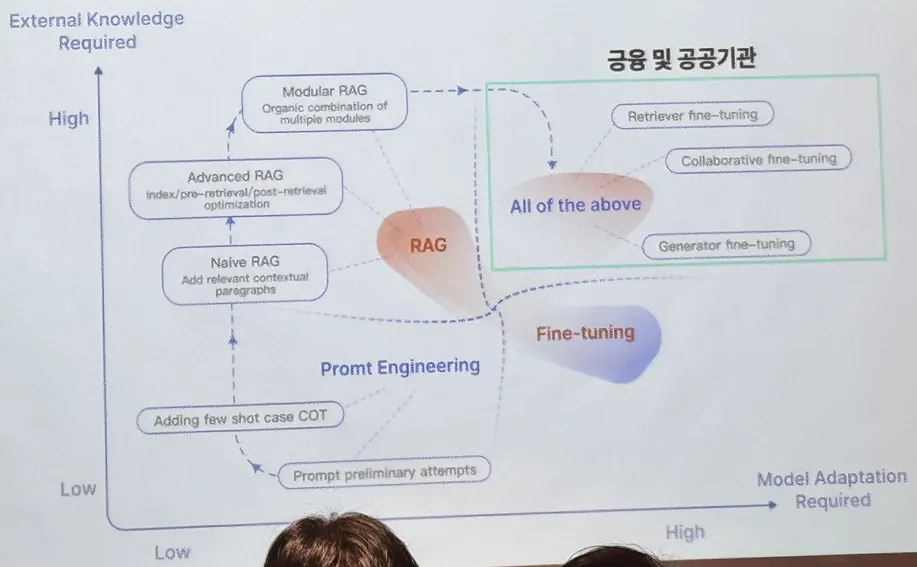
•
모든 도메인에서 RAG가 필요하지는 않음
•
조건에 맞춰서 사용해야함
RAG, Fine Tuning이 필요한 경우
1.
외부 지식(LLM한테 가르치지 않은 지식)이 필요한 경우
•
LLM한테 가르치지 않은 지식이 필요하면 무조건 RAG를 해야한다.
2.
Model Adaptation이 필요한 경우
a.
LLM이 이미 알고 있는 뭔가의 지식이 우리랑 다를 때 회사랑 다를 때 LLM이 잘못된 지식을 알고 있을 때 → 모델 Fine Tuning이 필요
b.
LLM이 뱉어내는 어떤 텍스트의 스타일이 우리 회사와 크게 다를 때
ex) 약관 문서가 LLM이 트레이닝에 쓰여지긴 했지만 LLM 트레이닝에 쓰여진 다른 텍스트 대비 엄청나게 적을 때 우리 회사 스타일대로 보험 약관을 만들어내야 될 경우
→ 모델 Fine Tuning이 필요
프롬프트 엔지니어링만 필요한 경우
•
위에 설명한 두 경우가 아닐 경우
•
특별히 LLM이 가지고 있는 거에서 Adaptation할 필요는 없을 경우
•
우리 회사의 지식을 LLM이 잘 알기만 하면 될 경우 대체로 RAG로 대부분 해결이 된다.
금융이나 공공기관 같은 경우
•
문서 스타일이 우리가 보는 스타일과 다른 경우가 많다.
•
복잡하게 표가 많이 있는 경우도 많이 있고 그다음에 수식이 되게 많이 들어가야 되는 경우도 있고 보험 약관 같이 우리가 일반적으로 모르는 문서들 아니 변리사가 쓴 특허 문서들 이런 걸 다룰 경우
→ RAG랑 LLM Fine Tuning 전부 필요하다.
베스핀 글로벌사의 전략

Generative Answer
단계 | 문서 | 활용방안 | 특징 | RAG |
1단계 | 10개 내외 | 회사의 HR 규정 문서를 업로드하고, 사내 직원의 HR Assistant로 활용 | 문서의 수가 제한적이고, 모두 최신 버전이다. | Naive RAG |
2단계 | 수백~수천 개 | 주요 직군(보험업의 Underwriter, 여신 관리 업무 매니저, 콜센터 상담원 등)이 사용하는 상품 매뉴얼, 규제 문서, 관련 법령 등에 기반해서 AI를 Work Assistant로 활용 | 현업의 사용자가 실제 업무중에 Assistant로 활용한다. 문서는 모두 최종 버전 | Advanced RAG / Agent RAG |
3단계 | 수 만개 이상 | 회사 내에서 생상되는 모든 문서를 연동하여, 넓은 직군의 많은 수의 직원이 Work Assistant로 활용한다. | 문서의 수가 수만 - 수백만 개가 되며, Ver 0.1, Ver 0.2, 최종, 최최종 등 최종 버전이 아닌 문서가 많다. | Agent RAG |
HR : Human Resources - 인적 자원
•
문서가 많지 않을 경우 → Naive RAG만 구현해도 웬만큼의 성과를 볼 수 있다. 80~90%의 정확도
•
문서 폴더가 많고 다양한 폴더 안의 문서들에 비슷한 내용이 엄청 많을 경우 → Advanced RAG 더 가면 Agent RAG까지 고려
•
회사 안의 거의 모든 게 다 들어가 있는 경우 → Agent RAG
최적화 전략
Single Turn VS Multi Turn
•
에이전트 RAG가 필요함
•
여러번의 인터럭션을 걸쳐서 더 정확한 정보를 반환하는 방법
One Way VS Interactive
One Way
•
생성 모델이 외부 데이터 소스를 한 번 조회(retrieve)한 후, 그 정보를 바탕으로 응답을 생성하는 방식
•
정보 검색과 응답 생성이 분리된 단순한 구조
•
주로 사전 처리 단계에서 필요한 정보를 수집
•
장점
◦
구현이 비교적 간단하고, 처리 속도가 빠르다.
◦
외부 데이터 소스와의 상호작용이 최소화되어 보안 측면에서 유리할 수 있다.
•
단점
◦
사용자의 추가 질문이나 피드백에 실시간으로 반응하기 어렵다.
◦
데이터가 고정되어 있기 때문에 변화에 유연하지 않다.
Interactive
•
생성 모델이 사용자와의 상호작용을 통해 지속적으로 외부 데이터 소스를 조회하고, 실시간으로 응답을 생성하는 방식
•
대화 중에 사용자의 추가 질문이나 피드백에 따라 동적으로 정보를 검색하고 응답을 조정한다.
•
장점
◦
유연한 응답
◦
정확성과 관련성이 높아진다.
•
단점
◦
구현이 복잡하며, 실시간으로 데이터 조회와 생성이 필요하여 시스템 자원이 많이 소모될 수 있다.
◦
외부 데이터 소스와의 지속적인 상호작용으로 인해 보안 측면에서 많은 고려가 필요할 수 있다.
Zero-shot & One-shot & Few-shot
Zero-shot learning (ZSL)
•
모델이 학습 과정에서 본 적 없는 새로운 클래스를 인식할 수 있도록 하는 학습 방법
•
모델이 클래스 간의 관계나 속성을 통해 일반화하는 능력을 활용한다.
•
예제
◦
새로운 클래스에 대한 설명 정보를 입력으로 제공해야 한다.
◦
이미지 인식에서는 이미지의 특징을 설명하는 텍스트 정보를 사용하여 이전에 본 적이 없던 이미지더라도 해석이 가능하게 된다.
One-shot learning (OSL)
•
각 클래스에 대해 단 하나의 예시만 제공될 때 모델이 그 클래스를 인식할 수 있도록 하는 학습 방법
•
유사도 학습이나 메타 학습 등의 기법을 활용하여 구현된다.
•
예제
◦
고양이를 인식하는 딥러닝 모델에게 "스핑크스"라는 새로운 종류의 고양이를 인식하도록 요청한다면, 모델은 이전에 본 적이 없는 스핑크스 고양이 사진 하나만으로도 인식을 수행할 수 있어야 한다.
◦
이것은 학습 데이터가 매우 제한적인 경우에 유용
Few-shot learning (FSL)
•
극소량의 데이터만을 이용하여 새로운 작업이나 클래스를 빠르게 학습하도록 설계된 알고리즘
•
이 방법은 메타 러닝(meta-learning)이나 학습 전략의 최적화 등을 통해 적은 데이터로도 효과적인 일반화(generalization) 능력을 갖추도록 한다.
•
예제
◦
연구자들이 아주 드문 종류의 식물 사진 몇 장을 확보했다고 할 때, 전통적인 지도학습 모델은 이 식물을 학습하기에 충분한 데이터가 없다는 문제에 직면한다.
◦
하지만 Few-shot learning을 사용하면, 소수의 이미지만으로도 모델은 새로운 식물 종을 인식하고 분류하는 방법을 학습할 수 있다.
◦
이러한 상황에서는 다양한 사전 훈련된 모델과 조합하여 적은 데이터로도 높은 정확도를 달성할 수 있는 전략이 중요하게 작용한다.
Agent RAG
•
사용자와 적절히 인터렉션하면서, 질문과 관련 있는 폴더만을 대상으로 Retriever를 실행한다.
•
Multi Turn이며 Interactive하게 동작한다.
필요한 이유
•
질문을 한 번에 제대로 하는 사람은 별로 없다.
•
대부분의 사용자들은 자기가 물어보고 답을 듣고 그걸 수정하는 형태로 진행해서 원하는 답을 얻는 경우가 많다.
◦
처음에 물어볼 때 자기가 물어볼 게 명확하게 형성이 안 된 경우가 대단히 많기 때문
•
나이브나 어드벤스 라그는 전부 One Way이다. → 한 번에 답이 나오는 형식
