



6. Self-Reflective RAG
Self-Reflective RAG란?
•
대규모 언어 모델(LLM)이 자체적으로 검색, 생성, 비판하는 능력을 학습하여 응답의 사실성과 품질을 향상시키는 시스템
•
모델이 자체적으로 생성한 출력물을 활용하여 응답의 맥락적 일관성과 정확성을 높이는 방식으로 작동
•
반복적 응답 개선, 일관성 강화, 이전 출력물을 기반으로 한 정확성 향상에 중점을 두고 있다.
•
해당 아키텍처에서는 분기에 따라 2번의 순환이 일어날 수 있다.
반복적인 응답 개선
•
응답을 구체화하는 과정은 모델이 답을 한 번만 생성하고 거기서 멈추지 않는다는 것을 의미
•
대신 시간이 지남에 따라 해답을 개선할 수 있다.
•
이를 위해서는 이전 결과를 되돌아보고 대화를 통해 배운 내용을 바탕으로 조정하면 된다.
예를 들어, 모델이 정확하지 않거나 더 명확할 수 있는 답을 제시한 경우, 모델은 그 답을 가져와 다음 응답 라운드에서 구체화할 수 있다.
•
이러한 반복적인 프로세스를 통해 정보가 정확할 뿐만 아니라 이해하기도 쉬워진다.
이전 출력의 기초 응답
•
모델이 이미 제공한 정보를 기반으로 새로운 답을 찾는다.
•
이렇게 하면 모델이 무작위 소스에서 정보를 가져오는 것이 아니라 대화에서 이미 설정한 정보를 사용하므로 응답의 정확도가 높아진다.
예를 들어, 모델이 이전에 역사적 사건에 대한 특정 사실을 언급한 경우 관련 질문을 받았을 때 해당 사실을 다시 사용할 수 있다.
•
이렇게 하면 더 일관되고 신뢰할 수 있는 대화가 가능해진다.
목표
자체 성능 개선
•
Self RAG는 자체 출력을 사용하고, 응답을 수정하고, 정보를 바탕으로 하고, 대화에 적응함으로써 상호 작용의 질을 향상시킨다.
•
이를 통해 더 정확하고 일관되며 상황에 맞는 응답이 제공되므로 대화가 더욱 자연스럽고 매력적으로 느껴진다.
•
언어 모델이 자신의 이전 응답을 학습하고 대화의 흐름에 적응하여 더 나은 답변을 제공할 수 있도록 도와주는 역할
검색 전략 조정
•
대화는 시간이 지남에 따라 방향이 바뀌거나 진화할 수 있다.
•
Self RAG를 사용하면 모델이 대화 컨텍스트에 따라 검색 전략을 조정할 수 있다.
•
즉, 사용자가 질문을 더 많이 하거나 주제를 바꾸면 모델이 정보를 검색하고 사용하는 방법을 조정할 수 있다.
예를 들어, 사용자가 한 주제에 대해 이야기하기 시작한 후 관련 주제로 넘어가면 모델은 이러한 변화를 인식하고 새 주제와 더 관련이 있는 정보를 검색할 수 있으므로 대화가 원활하고 참여도가 높아진다.
주요 동작
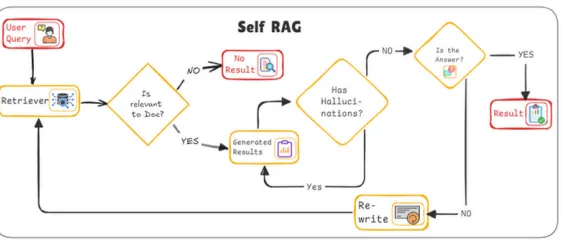
•
Self-Reflective RAG는 이름 그대로 스스로 회고를 한다.
•
주요 회고 과정은 총 3개로 나눌 수 있다.
•
아래 3가지 회고를 진행하며 자체적으로 일관성과 정확성을 높이는 방식이다.
Retriever - Is Relevant to Doc? (문서와 관련이 있는가?)
•
검색된 정보가 사용자 쿼리와 관련성이 있는지 확인하는 단계
•
검색된 문서가 사용자 쿼리와 관련성이 있다고 판단되면 다음 단계로 진행하며, 그렇지 않으면 “No Result”로 분기하여 관련 자료가 없음을 표시한다.
•
관련성이 없는 문서를 거르므로, 쓸데없는 정보로부터 응답의 품질을 유지할 수 있다.
•
이 때, 입력과 검색 판단 (Retrieve on Demand) 과정을 거치게 된다.
◦
입력(prompt)을 처리할 때, LLM은 먼저 "Retrieve" 토큰을 생성하여 추가적인 외부 검색이 필요한지 결정한다.
특정 사실적 정보를 기반으로 한 질문의 경우 검색을 수행해야 하지만, 개인 경험과 관련된 질문에는 검색이 필요하지 않다.
▪
: 검색 필요성을 나타내는 확률 분포
▪
: 검색 여부를 결정하기 위한 학습된 가중치
▪
: 현재 입력 토큰에 대한 은닉 상태
Generated Results - Has Hallucinations? (환각이 있는가?)
•
모델이 생성한 응답에 신뢰할 수 없는 정보(즉, "환각")가 포함되어 있는지 확인하는 단계
•
검색된 문서를 참고하여 모델이 임시 응답을 생성하고, 이 응답이 사용자 쿼리와 일치하는지 확인하는 과정을 거친다.
•
여기서 생성된 결과에 잘못된 정보나 왜곡된 내용이 포함되어 있다면 "Yes"로 분기하여 Re-write 단계로 가서 응답을 수정한다.
•
환각이 없다면 다음 단계로 진행한다.
•
여기선 검색된 문서의 평가 과정에서 Critique Tokens를 사용하게 된다.
◦
검색된 각 문서에 대해 모델은 해당 문서의 관련성과 생성된 답변의 지원 여부를 평가한다.
◦
"ISREL", "ISSUP" 등의 Critique Tokens를 생성하여 문서가 입력 질문에 적합한지(관련성), 그리고 답변이 문서로 뒷받침되는지(지지성)를 나타낸다.
▪
: 관련성과 지지성 점수의 가중치
▪
: 관련성과 지지성에 대한 확률 점수
Is the Answer? (정답인가?) + Re-write
•
생성된 응답이 사용자 쿼리에 정확하게 부합하는지 확인하는 마지막 단계
•
응답이 사용자 요청에 부합하면 "Yes"로 분기하여 최종 결과로 사용자에게 전달하고, 부합하지 않으면 다시 검색기로 돌아가 추가 정보를 찾는 과정을 반복한다.
•
각 세그먼트(문장 단위) 생성 후, Critique Tokens를 기반으로 모델 자체적으로 결과를 검토한다.
◦
: 생성된 결과의 최종 점수
◦
: 생성된 결과의 확률
◦
: Critique Tokens의 점수
•
필요에 따라 생성된 결과를 반복적으로 개선할 수 있다. → Re-write 사용
Re-write (재작성)
•
환각이 포함된 응답을 수정하여 더 정확하고 신뢰할 수 있는 응답을 작성하는 단계
•
초기 응답의 정확성을 높이며, 반복적인 수정으로 최종 결과의 일관성과 신뢰성을 강화할 수 있다.
7. 적응형(Adaptive) RAG
Adaptive RAG란?
•
언어 모델에서 외부 소스로부터 추가 정보를 찾을 시기를 결정하여 응답을 생성하는 방식을 개선하기 위해 사용하는 방법
•
신뢰도 점수와 정직성 프로브를 사용하여 효율적이면서 응답의 질을 높히도록 한다.
•
항상 외부 정보를 찾는 대신 필요하다고 생각될 때만 검색하도록 선택할 수 있다.
•
적응형으로 동작한다.
•
Self RAG와의 가장 큰 차이점은 내부 인덱스와의 비교가 있느냐 없느냐이다.
동적 의사 결정
•
외부 지식을 검색할 시기를 동적으로 결정할 수 있다.
•
항상 외부 정보를 찾는 대신 필요하다고 생각될 때만 검색하도록 선택할 수 있다.
•
언어 모델에 공통 주제에 대한 질문이 주어지면 내부 지식에 의존할 수 있다.
•
그러나 질문이 매우 구체적이거나 최근 이벤트에 관한 것이라면 더 나은 답변을 제공하기 위해 추가 정보를 찾아보기로 결정할 수 있다.
내부 지식과 외부 지식의 균형
•
모델은 내부 지식(이미 알고 있는 정보) 과 외부 지식 (다른 출처에서 검색한 정보)의 균형을 유지한다.
•
이 균형이 중요한 이유는 모형이 스스로 이해한 내용을 활용하는 동시에 외부에서 가져온 최신 정보나 상세한 정보를 바탕으로 대응 능력을 높일 수 있기 때문이다.
목표
불필요한 검색 줄이기
•
신뢰도 점수와 정직성 프로브를 사용하여 불필요한 검색을 줄여준다.
→ 필요하지 않을 때 외부 정보를 찾지 않아도 되므로 토큰을 아끼니까 시간과 비용(리소스)이 절감된다.
예를 들어, 모델에 “프랑스의 수도는 어디입니까?” 와 같은 간단한 질문을 하는 경우 검색하지 않아도 자신있게 “파리”라고 대답할 수 있다.
•
이러한 효율성은 신속한 응답을 제공하는 데 매우 중요하다.
효율성 및 응답 정확도 향상
•
전반적으로 Adaptive RAG는 모델의 효율성과 응답의 정확도를 모두 개선한다.
•
모델은 언제 추가 정보를 찾아야 하고 언제 자체 지식을 활용해야 하는지를 알면 해답을 더 빠르고 안정적으로 제공할 수 있다.
•
이는 챗봇이나 가상 어시스턴트와 같이 사용자가 빠르고 정확한 답변을 기대하는 실시간 애플리케이션에서 특히 중요하다.
•
단순한 질문에는 불필요한 검색 과정을 생략함으로써 계산 비용을 절약하고, 복잡한 질문에는 다단계 검색과 추론을 수행하여 높은 정확성을 달성한다.
주요 동작
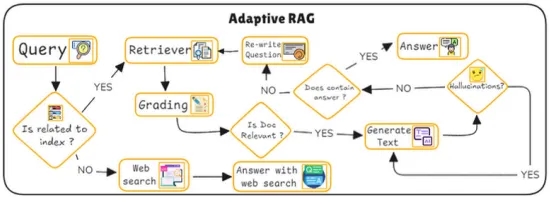
Is related to index? (인덱스와 관련이 있는가?)
•
질문이 이미 시스템의 내부 인덱스나 지식 베이스에 있는 정보와 관련이 있는지 확인
•
시스템은 내부 데이터베이스에서 빠르게 답변할 수 있는 질문인지 판별한다.
•
만약 관련이 있다고 판단되면 다음 단계로 진행하고, 관련이 없다면 외부 웹 검색을 통해 정보를 검색한다.
→ 관련이 없는 경우 불필요한 내부 검색을 피하고, 필요한 경우에만 외부 검색을 시도하여 효율성을 높인다.
질문이 사서가 자주 다루는 주제에 관한 것이라면 바로 도서관의 자료를 사용하지만, 그렇지 않다면 외부 출처나 다른 도서관에 연락해 추가 자료를 요청하는 것과 같다.
질문 복잡도 분류 (Query Complexity Classification)
•
Adaptive RAG는 질문의 복잡도를 사전 훈련된 분류기(Classifier)를 통해 A, B, C의 세 가지 복잡도 수준으로 분류한다.
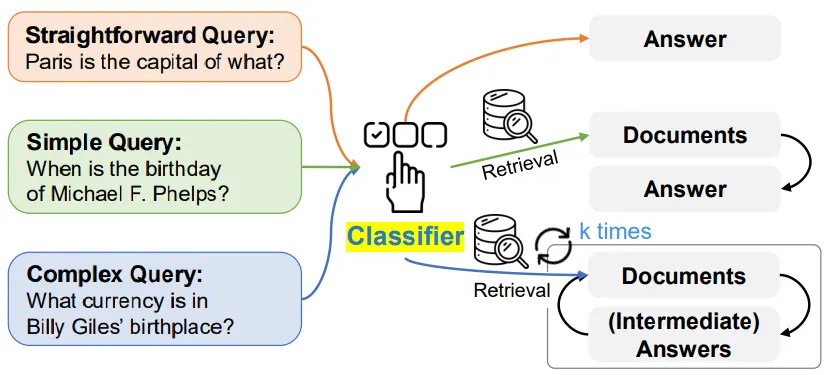
질문 q가 주어졌을 때, Adaptive RAG는 분류기를 사용하여 복잡도를 예측 한다.
•
: 분류기의 출력값, 복잡도 수준() 중 하나를 반환.
•
분류기는 데이터셋에서 자동으로 학습된 가중치를 사용하여 정확도를 극대화한다.
•
A 레벨 (단순 질문 - Non-Retrieval)
◦
LLM이 자체적으로 처리 가능한 간단한 질문.
◦
외부 검색 없이 자체 지식만으로 답변을 생성.
"한국의 수도는?"
•
B 레벨 (중간 복잡도 - Single-Step Retrieval)
◦
단일 검색 후 처리해야 하는 질문.
▪
:
▪
: 지식 베이스
◦
특정 정보를 포함하는 문서를 검색하여 답변에 반영.
"어제 서울의 날씨는 어땠어?"
•
C 레벨 (복잡한 질문 - Multi-Step Retrieval)
◦
다단계 검색 및 논리적 추론이 필요한 복잡한 질문.
"한국 경제 성장률의 변화를 설명하고, 주요 요인을 분석해줘."
8. REFEED Retrieval Feedback
리피드(REFEED)란?
•
검색 피드백의 약자
•
언어 모델(예: 챗봇 또는 가상 어시스턴트)에서 생성된 답변을 개선하는 데 사용되는 방법
•
미세 조정(Fine-tuning)이라는 복잡한 프로세스가 필요하지 않는다.
•
모델을 추가적으로 학습(fine-tuning)하지 않고, 검색된 문서를 활용해 응답을 반복적으로 개선한다.
•
자동 검색 피드백을 제공하는 플러그 앤 플레이 방식의 파이프라인
목표
답변 신뢰성 향상
•
LLM의 제한적인 지식 문제 해결
◦
실시간으로 검색된 외부 정보를 활용하여 이 문제를 해결하고, 더 신뢰할 수 있는 답변을 생성하는 것을 목표로 한다.
•
검색 피드백 및 순위 지정 방법을 사용하여 모델이 제공하는 답변의 신뢰도를 향상시킨다.
•
사용자는 자신이 받는 정보가 정확하고 외부 데이터를 통해 잘 뒷받침된다는 확신을 가질 수 있다.
비용 효율적인 학습 지원
•
REFEED는 추가적인 모델 미세조정(fine-tuning) 없이 모델의 성능을 향상시킨다.
•
기존의 인간 피드백이나 강화 학습 기반 접근법은 비용이 많이 들고 비실용적인 경우가 많다.
•
REFEED는 이러한 리소스 집약적인 과정 없이, 검색 피드백을 통해 LLM의 출력을 효율적으로 개선한다.
AI와의 상호작용 증대 - CoT
•
검색 전/후 결과 결합, 순위 시스템, 복수 답변 생성 등의 피드백을 AI와 상호작용하는 과정을 통해 성능을 향상시킨다.
•
LLM은 시퀀스 기반으로 빈칸 채우듯이 문장을 생성하는 특징이 있다보니, 이러한 특징을 살려서 중간 과정을 단계별로 풀이했을 때, 그 성능이 좋아진 것이 아니었을까라고 추측함.
주요 동작
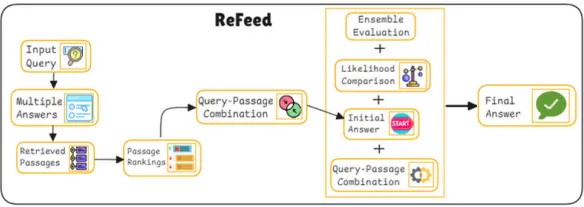
Multiple Answers (다중 응답)
•
초기 단계에서 여러 개의 응답을 생성해 다양한 관점에서 질문에 답한다.
•
사용자의 질문 에 대해 LLM은 초기 답변 를 생성한다.

이때, LLM은 자체 지식에 기반하여 가장 가능성이 높은 답변을 생성하거나, 다양한 답변을 생성하도록 샘플링을 적용할 수 있다.
◦
: 질문 에 기반한 초기 답변 의 확률
◦
: 답변의 i번째 토큰이 이전 토큰 및 질문 q에 따라 선택될 확률
◦
LLM의 autoregressive 특성을 반영하며, 초기 답변이 질문을 기반으로 순차적으로 생성되는 과정
autoregressive: 자기 회귀 모델
•
모델이 이전 출력을 미래 예측의 입력으로 사용한다는 것
•
데이터 포인트가 시간 경과에 따라 정기적으로 수집되는 시계열 분석의 기본 개념
•
모델은 질문에 대한 여러 응답을 생성하며, 이는 나중에 비교하여 가장 신뢰할 수 있는 응답을 선택하는 데 사용된다.
•
다양한 답변을 미리 생성해 놓음으로써, 최종적으로 가장 신뢰할 수 있는 답변을 선택하는 데 도움을 준다.
한 주제에 대해 여러 자료를 참고하여 다양한 관점을 이해하려는 것과 유사하다.
Retrieved Passages (검색된 구절들)
•
검색된 구절을 질문에 대한 관련성에 따라 순위를 매긴다.
•
검색된 구절들의 적합성을 평가하고, 관련성이 높은 순으로 정렬하여 최적의 답변을 만드는 데 필요한 자료의 우선순위를 설정한다.
•
순위를 매김으로써 가장 관련성이 높은 정보를 우선적으로 활용할 수 있다.
여러 자료 중 가장 유용한 것부터 검토하여 시간을 절약하고 효율성을 높이는 것과 같다.
Query-Passage Combination (질문-구절 결합) + Initial Answer (초기 응답)
•
초기 응답과 검색된 구절을 결합하여 응답의 정확성을 높이는 과정
•
초기 응답을 생성한 후, 이를 검색된 구절과 결합하여 응답의 근거를 강화하거나 수정한다. 이를 통해 더욱 완성도 높은 답변을 만들 수 있다.
•
검색된 자료를 반영해 초기 응답을 개선함으로써 답변의 신뢰성을 높일 수 있다.
논문을 작성할 때, 본인의 주장에 대한 근거 자료를 인용하여 논리적 일관성을 강화하는 것과 유사하다.
•
검색된 문서 를 기반으로 초기 답변 를 정제하여 최종 답변 를 생성한다.
◦
: 질문 q에 대한 최종 답변 a의 확률
◦
: 문서 , 질문 , 초기 답변 를 기반으로 최종 답변 를 생성할 확률
◦
: 문서 가 선택될 확률
◦
: 초기 답변 가 질문 에 따라 생성될 확률
+ Ensemble Evaluation (앙상블 평가) & Likelihood Comparison (가능성 비교)
•
여러 응답을 평가하여 가장 신뢰할 수 있는 응답을 선택하는 과정
•
생성된 초기 답변 와 검색 피드백을 통해 정제된 답변 를 비교하여 최종적으로 가장 신뢰할 수 있는 답변을 선택한다.
◦
: 검색 피드백을 반영한 최종 답변의 로그 우도(≒가능도)
◦
: 초기 답변의 로그 우도(≒가능도)
▪
각 답변의 가능도를 평가하고, 가장 높은 가능도를 가진 답변을 반환한다.
◦
이면 정제된 답변이 최종 선택된다.
•
여러 응답의 신뢰성을 평가하고, 다양한 응답을 통합하여 최적의 응답을 선택하는 데 사용된다.
•
다양한 관점에서 생성된 응답을 종합적으로 고려하여, 더욱 신뢰성 높은 답변을 제공할 수 있다.
여러 사람의 의견을 듣고 이를 종합하여 최적의 결론을 도출하는 과정과 유사하다.
•
모델은 각 응답의 가능성(정확도) 점수를 계산하고, 가장 가능성이 높은 응답을 선택 → 신뢰성↑
여러 자료의 신뢰성을 비교하여 가장 타당한 것을 선택하는 것과 같다.
9. REALM - Pre-Training
REALM이란?
•
인간의 언어를 이해하고 생성하는 컴퓨터 프로그램인 언어 모델이 질문에 답하는 방식을 개선하기 위해 설계된 시스템
•
대규모 데이터베이스(예: Wikipedia)에서 관련 문서를 검색해 모델의 예측 정확성을 향상시키는 모델
•
미지도 사전 학습과 지도 학습 미세 조정을 통해 학습되며, 검색과 예측을 결합하여 오픈 도메인 질문 응답에서 강력한 성능을 보인다.
•
오픈 도메인 질문 응답(Open-domain Question Answering)에서 효과적이다.
목표
외부 지식 활용
•
REALM은 모델이 자체적으로 지식을 생성하는 것 외에도, 외부의 대규모 지식 데이터베이스를 참고하여 더욱 신뢰성 높은 응답을 제공한다.
•
이를 통해 오픈 도메인 질문에서도 다양한 답변을 할 수 있다.
효율적 검색 시스템
•
Maximum Inner Product Search (MIPS) 방식을 사용하여 수백만 개의 문서 중에서도 빠르게 관련 문서를 찾을 수 있다.
•
이로 인해, 질문에 대한 답변을 생성할 때 필요한 정보를 효과적으로 추출할 수 있다.
미세 조정(Fine-tuning)으로 응답 품질 개선
•
지도 학습을 통한 미세 조정(Fine-tuning) 단계에서 모델은 더욱 세밀한 응답을 생성할 수 있게 된다.
•
이를 통해 다양한 유형의 질문에 대해 더 높은 품질의 답변을 제공할 수 있다.
오픈 도메인 질문 응답 성능 향상
•
REALM은 외부 지식을 자유롭게 활용함으로써 기존 모델보다 오픈 도메인 질문에 대해 더 나은 성능을 발휘한다.
•
이를 통해 다양한 주제에 대한 정확한 답변이 가능하다.
주요 동작
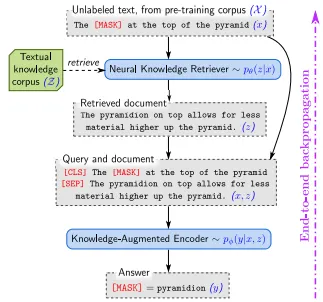
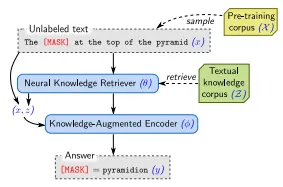
지식 검색 (Knowledge Retrieval)
•
주어진 입력 에 대해, REALM은 지식 코퍼스 에서 잠재적으로 유용한 문서 를 검색한다.
•
검색 과정은 다음과 같은 확률 분포로 모델링된다.
◦
: 입력 와 문서 간의 유사성을 나타내는 내적(inner product) 점수
◦
과 : 각각 입력과 문서를 고차원 벡터로 매핑하는 함수
이는 BERT 스타일 Transformer로 구현된다.
•
이 검색 단계에서 내 모든 문서의 유사도를 계산해야 하므로 대규모 데이터셋에서 효율적인 검색이 핵심 과제이다.
•
이를 위해 MIPS(Maximum Inner Product Search) 알고리즘을 사용해 검색 시간을 최적화한다.
지식 증강 인코딩 (Knowledge-Augmented Encoding)
•
검색된 문서 z와 원래 입력 x를 결합하여 하나의 시퀀스로 만들고, 이를 Transformer에 입력한다.
◦
: BERT 구조의 특별 토큰.
◦
Transformer의 출력을 활용하여 (e.g., 질문에 대한 답변)를 생성한다.
•
마스킹 언어 모델(Masked Language Model, MLM)의 경우, 각 마스크된 토큰 의 확률을 다음과 같이 모델링한다.
◦
: 마스크된 토큰 에 해당하는 Transformer 출력 벡터
◦
: 모델이 학습한 예측 벡터.
생성(Generation)
•
REALM은 를 생성하기 위해 검색된 문서 에 기반한 분포를 사용하고, 에 대해 마진(Marginalization)을 수행한다.
◦
: 입력 에 대한 최종 출력 의 확률
◦
: 특정 문서 를 기반으로 출력 를 생성할 확률
◦
: 문서 가 검색될 확률
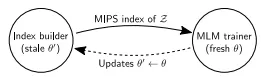
훈련(Training)
•
REALM은 위의 의 로그 우도를 최대화하는 방식으로 훈련된다.
•
이 과정에서 를 계산해야 하며, 이는 에 대한 확률적 Gradient Update로 나타난다.
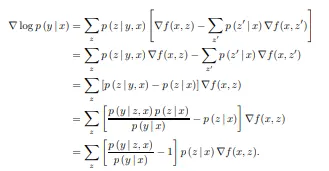
◦
각 문서 에 대해 확률적 기여도를 고려하여 모델 파라미터를 업데이트
구조
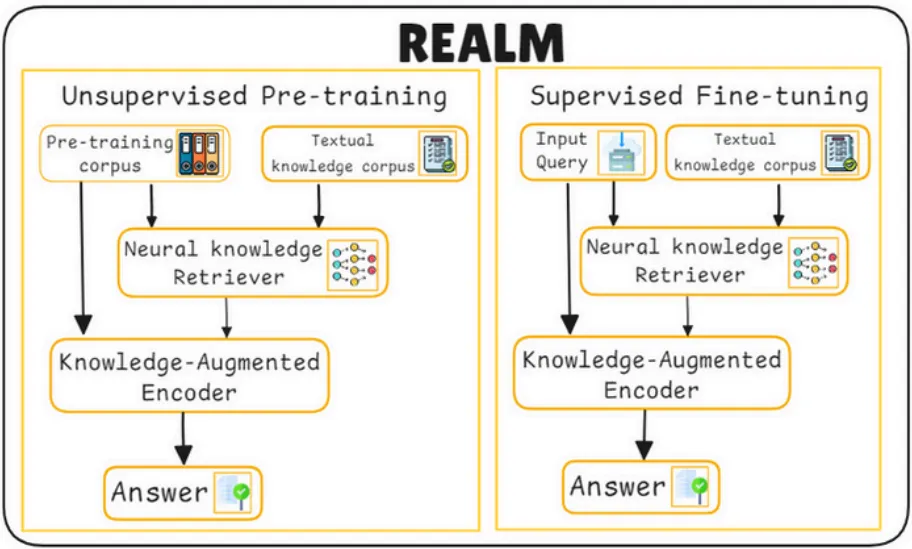
Unsupervised Pre-training (미지도 사전 학습)
•
Pre-training corpus (사전 학습 데이터)
◦
모델이 미리 학습하는 데 사용하는 대규모 텍스트 데이터
◦
다양한 텍스트 데이터를 사용해 언어의 기본적인 패턴과 의미 구조를 학습한다.
◦
이를 통해 언어 모델이 텍스트 이해 능력을 갖추도록 한다.
특정 주제에 대한 전문 지식을 얻기 전에, 먼저 일반적인 읽기와 글쓰기를 배우는 과정과 같다.
•
Textual knowledge corpus (텍스트 지식 데이터베이스)
◦
모델이 답변을 위해 참고할 수 있는 외부 지식의 출처
◦
예를 들어 Wikipedia와 같은 대규모의 텍스트 데이터베이스에서 정보를 가져와, 모델이 이를 바탕으로 질문에 답할 수 있도록 한다.
도서관의 자료처럼 필요한 정보를 언제든지 참고할 수 있는 지식의 창고와 같다.
•
Neural knowledge Retriever (신경 지식 검색기)
◦
질문과 관련된 문서를 검색하여 모델에 제공하는 역할
◦
이 검색기는 입력된 질문과 가장 관련이 높은 문서를 찾아내고, 이를 다음 단계로 넘겨 모델이 참고할 수 있도록 한다. 검색 과정은 Maximum Inner Product Search (MIPS) 방식을 사용해 효율적으로 이뤄진다.
사용자가 질문을 하면 도서관 사서가 관련 책을 찾아서 가져오는 것과 유사하다.
•
Knowledge-Augmented Encoder (지식 확장 인코더)
◦
검색된 문서의 정보를 바탕으로 최종 응답을 생성하는 인코더
◦
모델은 검색된 문서의 내용을 이해하고 이를 바탕으로 사용자 질문에 대한 답변을 형성한다.
◦
이 인코더는 단순히 문서를 읽는 것이 아니라, 질문에 맞게 정보를 요약하고 조합하여 최적의 답변을 만든다.
책에서 읽은 정보를 기반으로 독자가 질문에 맞게 응답하는 것과 비슷하다.
Supervised Fine-tuning (지도 학습 미세 조정)
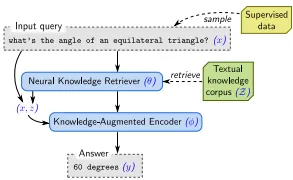
•
Input Query (입력 쿼리)
◦
사용자가 질문을 입력하는 단계, Fine-tuning 단계의 시작점
◦
Fine-tuning 단계에서는 사용자가 주는 다양한 질문에 대해 훈련된 데이터를 활용해 응답의 품질을 더욱 높인다.
훈련을 통해 더욱 숙련된 답변을 생성할 수 있도록 하는 과정이다.
•
Textual knowledge corpus (텍스트 지식 데이터베이스)
◦
Pre-training 단계에서 사용된 것과 동일한 외부 지식 데이터베이스
◦
Fine-tuning 단계에서도 질문에 대한 답변을 위해 텍스트 지식 데이터베이스를 활용한다.
훈련된 지식을 사용하여 새로운 질문에 답하는 과정에서 기존 자료를 참고하는 것과 유사하다.
•
Neural knowledge Retriever (신경 지식 검색기)
◦
Fine-tuning 단계에서도 관련 문서를 검색하여 답변을 위한 정보를 제공한다.
◦
Pre-training 단계와 동일하게, 입력된 질문에 맞는 문서를 찾아주며, 이 과정에서 모델이 더욱 정확하게 정보를 검색할 수 있도록 학습한다.
경험을 쌓은 사서가 질문에 더 적합한 자료를 빠르게 찾는 능력을 키워가는 과정과 같다.
•
Knowledge-Augmented Encoder (지식 확장 인코더)
◦
검색된 정보를 바탕으로 최종 응답을 생성하는 단계
◦
지도 학습을 통해 더욱 정밀하게 응답을 생성하는 법을 학습한다.
◦
이전 단계에서 찾아온 문서와 질문을 결합해 보다 세밀하고 신뢰성 있는 응답을 생성한다.
학습과 훈련을 통해 더욱 정확한 지식을 바탕으로 답변하는 것과 같다.
10. RAPTOR (장문의 문서에 적합)
RAP-TOR(Tree-Organized Retrieval)란?
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
트리 구조 검색을 위한 재귀적 추상 처리
•
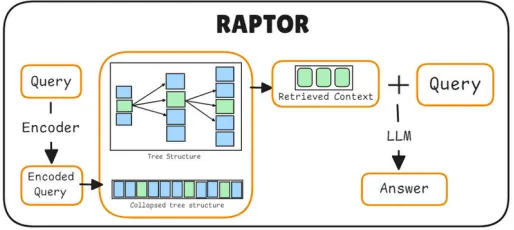
트리 구조를 활용하여 정보를 계층적으로 조직하고 검색하는 시스템
•
복잡한 질문 응답에서 뛰어난 성능을 발휘한다.
•
텍스트를 재귀적으로 클러스터링하고 요약하여 계층적인 트리를 구성함으로써 다양한 수준의 추상화에서 정보를 검색할 수 있다.
•
이를 통해 광범위한 주제와 구체적인 세부 사항을 동시에 처리할 수 있다.
계층적 트리 구조
•
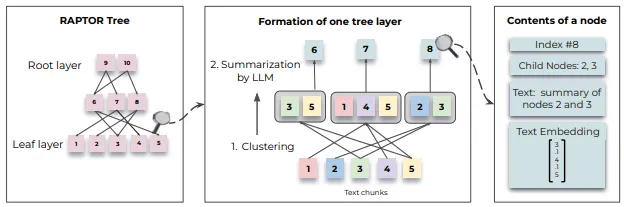
RAPTOR는 계층적 트리를 생성한다.
•
이 트리를 메인 아이디어가 맨 위에 있고 관련 아이디어가 그 아래에 뻗어 있는 가계도와 같다고 생각하자.
•
이 트리는 텍스트를 클러스터링하고 요약 혹은 정보 추출(Retrieve)하여 만들어졌다.
클러스터링: 유사한 정보를 함께 그룹화하는 것을 의미하며, 요약이란 많은 정보를 취합하여 더 짧고 관리하기 쉬운 조각으로 압축하는 것
추상화 수준
•
트리를 사용하면 더욱 다양한 추상화 수준에서 검색할 수 있다.
•
광범위한 주제
◦
주제에 대한 일반적인 정보를 원하면 트리의 위쪽 가지를 살펴보자.
예를 들어 주 주제가 '동물'인 경우 '포유류', '새', '파충류'와 같은 광범위한 범주를 찾을 수 있다.
•
특정 세부 정보
◦
더 자세한 정보가 필요하면 나무를 더 깊이 파고들 수 있다.
예를 들어 '포유류' 아래에 '개', '고양이', '코끼리'와 같은 특정 동물이 있을 수 있다.
목표
복잡한 질문 답변 작업
•
해당 주제에서 RAPTOR는 기존 RAG보다 더 좋은 성능을 발휘한다.
•
이름에서 보이는 것처럼 RAP-TOR(Tree-Organized Retrieval)는 트리 구조를 사용하여 정보를 정리하는 시스템이다.
•
그래서 사용자는 광범위한 주제와 특정 세부 사항을 모두 탐색할 수 있으므로 복잡한 질문에 대한 답을 더 쉽게 찾을 수 있다.
트리 탐색
•
RAPTOR는 트리 구조를 통해 정보를 계층적으로 조직함으로써 검색의 효율성을 높이고, 복잡한 질문에도 정확하게 대응할 수 있다.
•
이로 인해 광범위한 질문에 대해서도 세부 사항을 빠르게 찾을 수 있다.
•
트리 구조는 필요한 경우 전체 구조를 탐색하지 않고도 특정 레벨에서 관련 정보를 신속하게 검색할 수 있도록 한다.
•
압축된 트리 구조를 활용해 빠른 검색이 가능하다.
•
사용자가 원하는 정보의 깊이에 따라 적절한 레벨에서 검색을 수행함으로써, 세부 정보와 전반적인 개요를 모두 다룰 수 있다.
•
트리 구조를 통해 광범위한 주제에서 세부 사항까지 빠르게 접근할 수 있어, 복잡한 질문에 대한 응답 성능이 향상된다.
주요 동작
Clustering
•
100 개의 토큰을 기준으로 문장이 끊어지지 않도록 청킹을 하게 된다.
•
청킹된 문장들은 embedding을 거쳐 dense embedding로 변환되게 된다.
Dense Embedding: 고차원 데이터를 보다 저차원의 공간으로 압축하여, 정보를 최대한 유지하면서도 컴퓨터가 처리하기 쉽게 표현하는 기법
예시로 Word2Vec, BERT와 같은 Transformer 모델 임베딩 등이 있다.
◦
여기서 임베딩된 문장들은 각각의 고유한 의미를 담고 있게 된다.
•
이후 차원축소를 진행하는데 RAPTOR 논문에서는 UMAP를 제안하였다.
◦
긴 문서를 임베딩 시키게 되면, 대부분 몇 천개의 차원으로 이루어져 있다.
◦
그렇기 때문에 이 모든 것을 클러스터링 알고리즘에 태우는 것이 사실상 불가능하다.
→ 여기서 어느정도 의미 있는 차원만 남겨 소수의 임베딩만 남도록 차원 축소하자. = UMAP
UMAP(Uniform Manifold Approximation and Projection): 고차원의 데이터를 저차원으로 축소하여 시각화하거나, 패턴을 파악하는 데 유용한 비지도 학습 차원 축소 기법
자세히 알고 싶다면 하단 링크를 참고하자.
 Understanding UMAP
Understanding UMAP
Understanding UMAP•
GMM을 통해 클러스터링을 수행하게 된다.
GMM(Gaussian Mixture Model): 데이터의 분포가 여러 개의 가우시안 분포의 조합으로 이루어져 있다고 가정하고 이를 통해 데이터의 밀도 분포를 추정하는 확률 모델
◦
GMM에서 주어진 데이터 포인트 x의 가능도는 다음과 같이 정의된다.
▪
, : 각각 번째 가우시안 분포의 평균과 공분산 행렬
◦
이러한 성질을 가진 GMM은 청크를 유사한 주제의 클러스터로 구성하는데 도움을 주며, 각 텍스트 세그먼트가 여러 클러스터에 속할 수 있도록 Soft Clustering방식을 채택한다.
•
전체 가능도는 가중 합으로 계산된다.
◦
: 각 클러스터에 대한 가중치
•
전체 텍스트를 대상으로 클러스터링을 한번 진행한 후, 몇 개의 클러스터가 적절한지 글로벌 단위로 측정하고 각 클러스터 내에서 한번 더 진행하게 된다.
•
이후 BIC을 통해 최적의 클러스터 수를 결정할 수 있게 된다.
◦
수동적으로 n번씩 최적의 클러스터 개수를 지정하지 않고 최적의 클러스트 수를 자동으로 결정할 수 있게 한다.
BIC(Bayesian Information Criterion): 통계 모델을 평가하고 비교할 때 사용하는 기준
모델이 데이터를 얼마나 잘 설명하는지뿐만 아니라, 모델의 복잡도(즉, 파라미터의 수)도 고려해서 최적의 모델을 선택하도록 돕는다.
BIC 수식
Retrieving
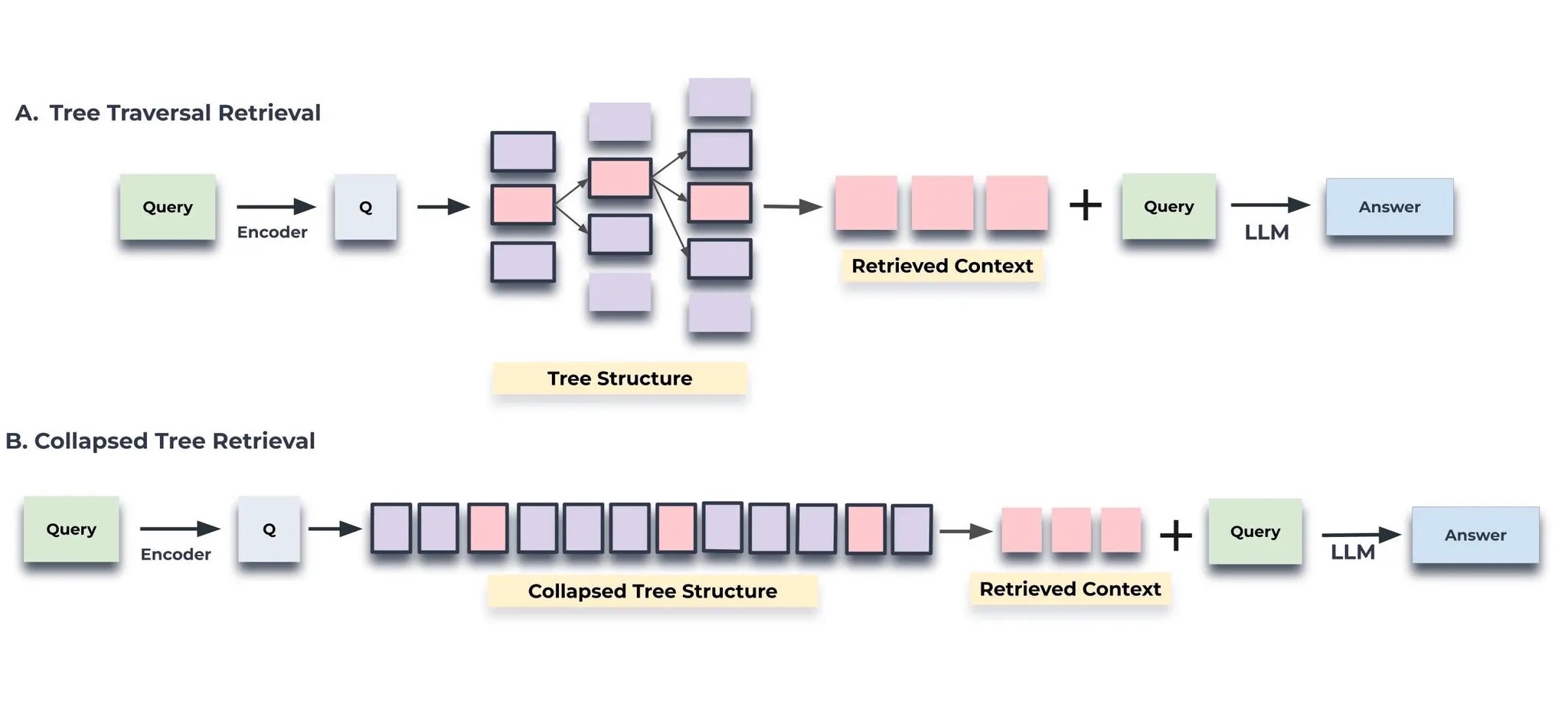
a.
트리 탐색 접근 방식(Tree Traversal)
•
쿼리 임베딩과의 코사인 유사도에 따라 가장 관련성이 높은 상위 k개의 루트 노드를 선택한다.
코사인 유사도: 내적공간의 두 벡터간 각도의 코사인값을 이용하여 측정된 벡터간의 유사한 정도
•
선택된 노드의 하위 노드는 다음 계층에서 고려되고 쿼리 벡터와의 코사인 유사도에 따라 이 풀에서 다시 상위 노드가 선택된다.
•
이 과정은 리프 노드에 도달할 때까지 반복된다.
•
마지막으로, 선택된 모든 노드의 텍스트가 연결되어 검색된 컨텍스트를 형성한다.
알고리즘 단계
1.
RAPTOR 트리의 루트 레이어에서 시작, 쿼리 임베딩과 이 초기 계층에 존재하는 모든 노드의 임베딩 간의 코사인 유사도를 계산
2.
가장 높은 코사인 유사도 점수를 기준으로 최상위 노드를 선택하여 집합 을 형성
3.
집합에 있는 요소의 하위 노드로 진행. 쿼리 벡터와 이러한 하위 노드의 벡터 임베딩 사이의 코사인 유사도를 계산
4.
쿼리에 대한 코사인 유사도 점수가 가장 높은 상위 자식 노드를 선택하여 집합을 형성
5.
레이어에 대해 이 프로세스를 재귀적으로 계속하여 집합을 생성
6.
세트를 연결하여 쿼리와 관련된 컨텍스트를 조합
•
해당 방법에서 근본이 되는 트리 탐색 방식은 무조건 최상위 루트 노드에서 시작해 단계적으로 최하단 노드까지 내려가며 필요한 정보를 찾는 방법이다.
•
여기서 상위 레벨에서는 질문의 전반적인 주제나 추상적인 내용을 포함하는 노드를 선택하고, 구체적인 내용들을 담고 있는 하위 노드로 내려가면서 핵심과 관련된 세부 내용에 접근할 수 있게 된다.
→ 즉, 해당 방식은 추상적인 것과 구체적인 것에 대한 답변을 얻을 수 있다.
•
그러나 만약 상위 레벨 노드가 요약이 잘되지 않았거나 혹은 질문이 너무 구체적인 경우 상위 레벨의 특정 노드가 선택되지 않을 가능성이 커진다.
•
그래서 이 과정 속에서 정보 손실이 있을 수 있다.
b.
축소 트리 접근 방식(Collapsed Tree Retrieval)
•
트리의 계층을 완전히 무시하고 모든 노드를 평면화(flattened)하여 한 번에 비교하는 방식
•
트리의 모든 노드를 동시에 고려함으로써 관련 정보를 검색하는 더 간단한 방법을 제공한다.
•
여기에서 중요한 점은 상위 노드 혹은 하위 노드의 개념이 아예 없고, 모든 노드가 동일한 레벨에 있는 것처럼 간주한다.
•
이에 각 노드와 질문 간의 유사도를 계산하여 상위 노드들을 차례대로 선택한다.
•
그럼 똑같이 질문에 대해 병합 방식으로 처리할 때는 트리의 모든 노드를 한 번에 비교해 핵심과 직접적으로 연관된 내용들을 담고 있는 노드를 우선적으로 선택하게 된다.
•
이 방법은 레이어별로 이동하는 대신 다층 트리를 단일 레이어로 평평하게 만들어 모든 노드를 동일한 수준으로 가져와 비교한다.
알고리즘 단계
1.
먼저 전체 RAPTOR 트리를 단일 레이어로 축소한다. 이 새로운 노드 집합은 원래 트리의 모든 계층의 노드를 포함하는 것으로 표시된다.
2.
다음으로, 쿼리 임베딩과 축소된 집합에 존재하는 모든 노드의 임베딩 사이의 코사인 유사도를 계산한다.
3.
마지막으로 쿼리와 코사인 유사도 점수가 가장 높은 최상위 노드를 선택한다.
이 때 미리 정의된 최대 토큰 수에 도달할 때까지 결과 집합에 노드를 계속 추가하여 모델의 입력 제한을 초과하지 않도록 주의하자.
