

RAG
LLM의 문제점
•
현재 업데이트된 LLM 모델의 대부분은 최신 정보가 들어있지 않다.
•
그래서 그 이후에 일어난 사건이나 지식에 대해서는 알지 못한다.
→ 이건 아래 설명하는 3가지의 치명적인 단점이 될 수 있다.

openai사의 gpt 모델 학습 데이터셋 일자 정보
모델 환각 현상(Model Hallucination Problem)
•
LLM이 생성하는 텍스트는 확률에 기반해 생성된다.
•
충분한 사실 검증 없다면, LLM은 일관성이 없지만 사실인 것 같은 내용을 생성하기도 한다.
•
가장 대두되고 있는 문제이기도 하다.
적시성 문제(Timeliness problem)
•
LLM의 parameter size가 커질수록, 훈련 비용은 증가하고 소요 시간은 길어지게 된다.
•
결과적으로, 시간적으로 최신의 데이터(time sensitive data)가 훈련에 포함되지 않을 수 있는데, 이로 인해 모델이 최신 정보에 대한 질문에 답변에 하지 못하는 경우가 발생하기도 한다.
데이터 보안 문제(Data security problem)
•
일반적인 LLM은 기업 내부 혹은 사용자의 개인 데이터에 접근 권한이 없다.
•
LLM을 사용하면서 데이터 보안을 확실하게 하려면 데이터를 로컬에 저장하고 모든 데이터 연산을 로컬에서 수행하는 것에 좋은데 이를 지키다 보니 클라우드 LLM은 정보를 요약하는 목적으로만 사용되게 된다.
RAG란?
•
위에서 설명한 LLM의 문제점들을 개선하기 위해 나온 기술
•
LLM의 문제점인 학습된 지식에만 의존하는 것이 아니라 새로운 지식을 추가(증강)하여 LLM이 올바른 답변을 할 수 있게 도와준다.
•
가장 큰 장점은 이미 강력한 LLM의 기능을 특정 도메인이나 조직의 내부 지식 기반으로 확장하므로 모델을 다시 교육할 필요가 없다.
•
이는 LLM 결과를 개선하여 다양한 상황에서 관련성, 정확성 및 유용성을 유지하기 위한 비용 효율적인 접근 방식이다.
•
R(Retrieval)
◦
검색 - "어디선가 가져오는 것, 집어오는 것"
◦
어딘가에 가서 요청된 무언인가를 집어오는 것
•
A(Augmented)
◦
증강 - “내용을 더 자세하게 설명하는 것”
◦
LLM이 더 이해하기 쉽도록 LLM이 참고할만한 내용을 추가시키는 것
•
G(Generation)
◦
생성 - “내용을 바탕으로 답변을 만들어 주는 것”
◦
위 두 과정을 거치고 나온 정보를 기반으로 LLM이 답변을 생성한다.
RAG 프레임워크 플로우
•
RAG는 아래 플로우처럼 LLM에 증강된 컨텍스트(추가 내용)를 제공함으로써 LLM이 좀 더 기존보다 향상된 응답을 할 수 있도록 도와줄 수 있다.
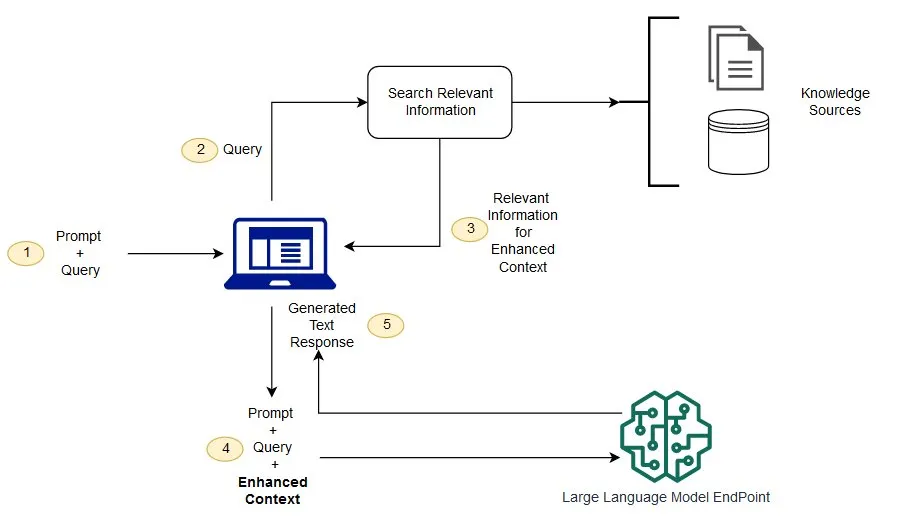
1단계: Prompt + Query 입력
•
사용자는 LLM(Large Language Model)에 요청을 보내기 위해 Prompt와 Query를 생성하여 입력한다.
Prompt: 요청의 기본 컨텍스트(명령어 또는 지시사항).
Query: 더 구체적인 질문이나 검색해야 할 항목.
Prompt: "위키피디아 문서 요약 제공."
Query: "2024년 미국 대통령 선거 관련 정보."
2단계: Query로 정보 검색
•
입력된 Query를 바탕으로 시스템은 관련된 지식 소스(Knowledge Sources)에서 정보를 검색한다.
Knowledge Sources: 데이터베이스, 문서 저장소, API 등.
(온라인 백과사전, 내부 데이터베이스.)
검색 목표: Query와 연관성이 높은 데이터를 찾는 것.
결과: "2024년 미국 대선 주요 후보와 일정."
3단계: 컨텍스트 강화 정보 반환
•
검색된 관련 정보가 Enhanced Context를 형성하는 데 사용된다.
•
반환된 정보는 원래 Prompt와 Query의 이해도를 높이는 추가적인 배경지식으로 활용됨.
검색 결과: "주요 후보는 X와 Y, 대선 날짜는 2024년 11월 5일."
•
이 정보는 이후 단계에서 모델이 답변을 생성할 때 컨텍스트로 포함된다.
4단계: 강화된 컨텍스트를 포함한 요청 생성
•
Prompt + Query + Enhanced Context가 결합되어 최종 요청이 생성된다.
•
강화된 요청은 모델이 더 정확하고 구체적인 응답을 생성할 수 있도록 도움을 준다.
최종 요청: "2024년 미국 대통령 선거에 대한 요약 정보를 제공하되, 후보와 주요 일정을 포함하도록 해라."
5단계: 텍스트 응답 생성
•
강화된 요청을 LLM에 전달하여 텍스트 기반 응답을 생성한다.
•
모델은 입력된 모든 정보를 바탕으로 자연어로 답변을 생성한다.
응답: "2024년 미국 대통령 선거는 11월 5일에 열릴 예정이며, 주요 후보로는 헤리스와 트럼프가 있습니다."
RAG 주요 특징
정보 검색 통합성
•
외부의 대규모 지식 베이스(예: 위키피디아, 도메인 특화 데이터베이스)에서 실시간으로 관련 정보를 검색하여 텍스트 생성 과정에 통합한다.
•
이 통합 과정은 모델이 단순히 내부적으로 학습한 지식에 의존하는 것이 아니라, 최신의 외부 정보를 활용할 수 있게 한다.
높은 정확성
•
신뢰할 수 있는 외부 데이터 소스를 기반으로 답변을 생성함으로써, 정보의 정확성과 신뢰성을 크게 향상시킨다.
•
생성 모델만 사용할 경우 발생할 수 있는 정보 왜곡이나 오류를 최소화할 수 있다.
유연한 적용성
•
질문 응답(Q&A), 문서 요약, 대화형 AI, 콘텐츠 생성 등 다양한 자연어 처리(NLP) 작업에 적용할 수 있다.
•
이러한 유연성 덕분에 여러 비즈니스와 연구 분야에서 폭넓게 활용될 수 있다.
최신 정보 반영 용이성
•
지식 베이스를 주기적으로 업데이트함으로써, RAG는 모델 자체를 재학습하지 않고도 최신 정보를 쉽게 반영할 수 있다.
•
이는 빠르게 변화하는 정보 환경에서 특히 중요한 특징이다.
효율성
•
필요한 정보만을 검색하여 사용하기 때문에, 대규모 생성 모델을 사용하는 것보다 계산 자원을 절약할 수 있다.
•
검색 단계와 생성 단계를 효율적으로 결합하여 실시간 응답이 가능하다.
