.gif&blockId=11b00c82-b138-8050-a58b-dcbceda2ef8f)



MapReduce
•
2004년에 구글에서 MapReduce: Simplified Data Processing on Large Clusters 논문 발표하였다.
•
이 논문은 Large Cluster 에서 Data Processing 을 하기 위한 알고리즘(MapReduce)를 소개하고 있다.
•
이 모델은 방대한 데이터를 작은 조각으로 나누어 여러 대의 컴퓨터(클러스터)에서 병렬로 처리함으로써 처리 속도를 높이고 자원을 효율적으로 활용한다.
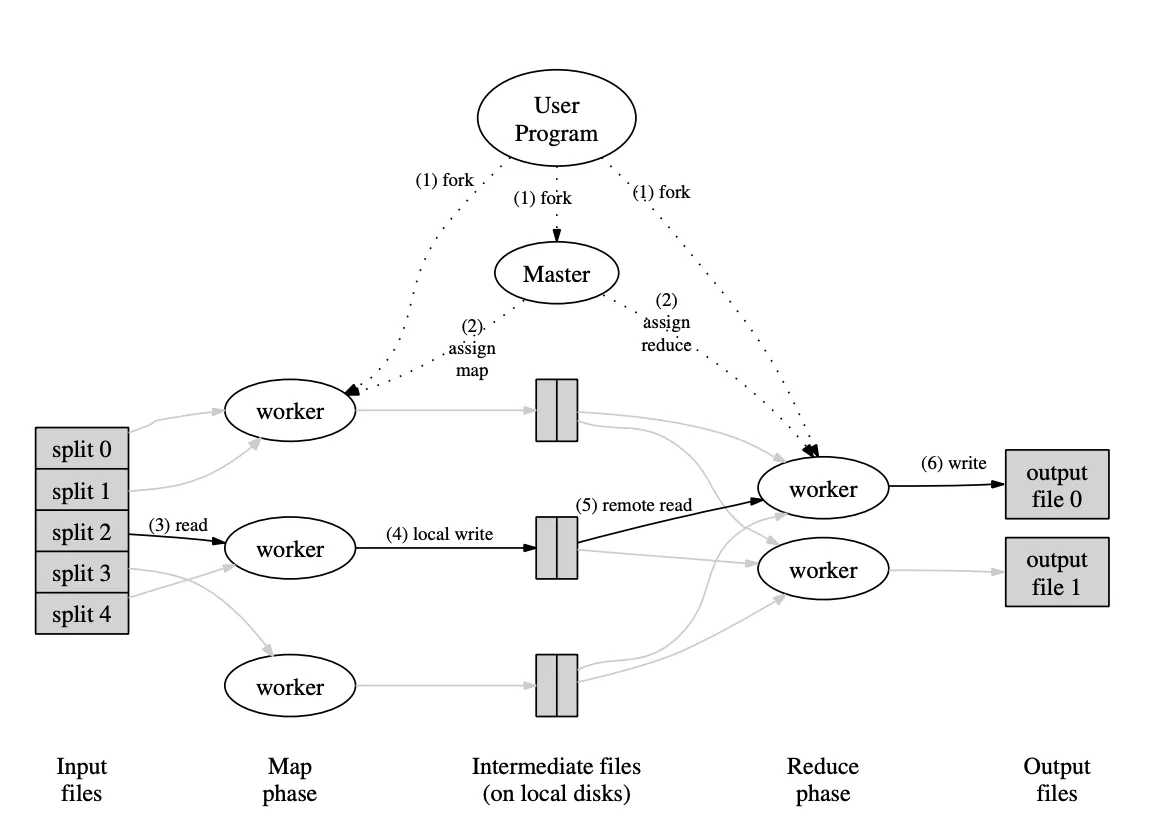
동작 원리
•
MapReduce는 크게 Map 단계, Shuffle and Sort 단계, 그리고 Reduce 단계로 구성된다.
Map 단계
1.
데이터 분할
•
입력 데이터 세트를 여러 개의 작은 조각(Input Split)으로 분할한다.
•
이를 통해 대용량 데이터를 병렬로 처리할 수 있는 기반을 마련한다.
2.
맵 함수 적용
•
각 데이터 조각에 맵 함수(Map Function)를 적용한다.
•
맵 함수는 입력 데이터를 키-값(Key-Value) 쌍의 중간 결과로 변환한다.
텍스트 파일에서 단어 빈도를 계산할 경우, 각 단어를 키로 하고 값은 1로 하는 키-값 쌍을 생성한다.
•
맵 함수는 데이터 필터링, 변환, 가공 등의 작업을 수행한다.
3.
중간 결과 출력: 맵 함수의 출력은 로컬 디스크에 일시적으로 저장된다. 이 중간 결과들은 이후 단계에서 사용된다.
Shuffle and Sort 단계
1.
데이터 재분배(Shuffle)
•
맵 단계에서 생성된 중간 결과를 키를 기준으로 재분배한다.
•
동일한 키를 가진 데이터들이 동일한 리듀스 노드로 전송되도록 한다.
2.
정렬(Sort)
•
각 리듀스 노드에서 수신한 데이터들을 키를 기준으로 정렬한다.
•
이를 통해 리듀스 함수가 데이터를 효율적으로 처리할 수 있게 된다.
Reduce 단계
1.
리듀스 함수 적용
•
정렬된 키-값 쌍에 대해 리듀스 함수(Reduce Function)를 적용한다.
•
리듀스 함수는 동일한 키를 가진 값들을 집계하거나 요약하는 역할을 한다.
단어 빈도 계산의 경우 동일한 단어의 빈도를 합산한다.
2.
최종 결과 출력
•
리듀스 함수의 출력은 최종 결과물로서 분산 파일 시스템(HDFS 등)에 저장되거나 사용자에게 제공된다.
예제 - 단어 갯수 세기
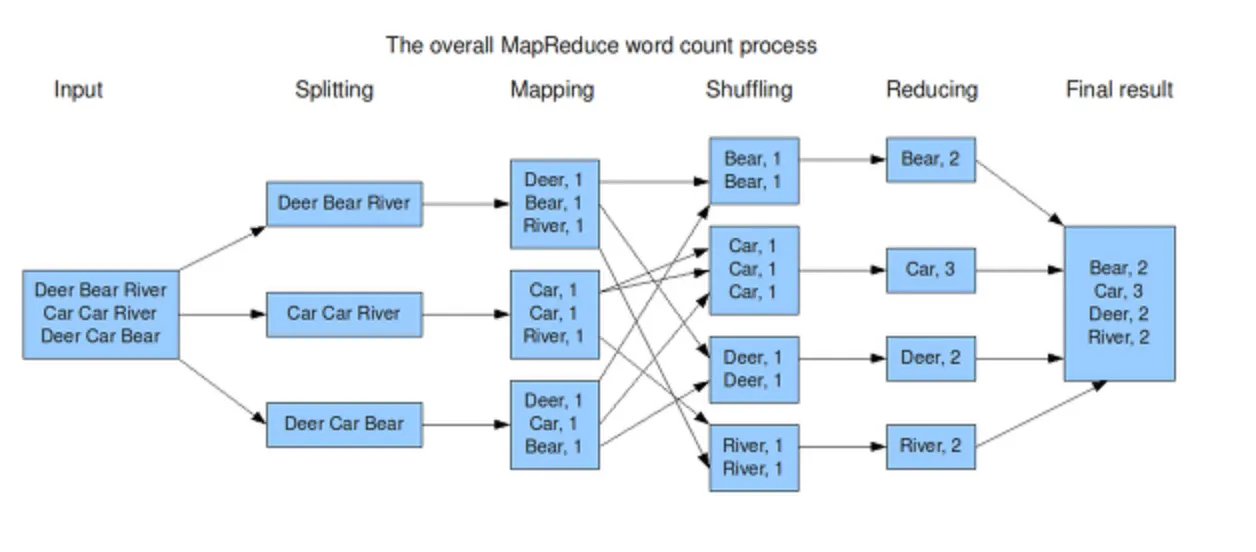
Splitting (분할)
•
입력 데이터를 각 프로세스로 나눠 병렬로 처리할 수 있도록 분할한다.
◦
첫 번째 프로세스: Deer Bear River
◦
두 번째 프로세스: Car Car River
◦
세 번째 프로세스: Deer Car Bear
Mapping (매핑)
•
각 분할된 데이터를 단어 단위로 쪼개고, 각 단어에 대해 키-값 쌍 (단어, 1)을 생성한다.
◦
첫 번째 프로세스: Deer → (Deer, 1), Bear → (Bear, 1), River → (River, 1)
◦
두 번째 프로세스: Car → (Car, 1), Car → (Car, 1), River → (River, 1)
◦
세 번째 프로세스: Deer → (Deer, 1), Car → (Car, 1), Bear → (Bear, 1)
Shuffling (셔플링)
•
동일한 키(단어)를 가진 데이터들을 그룹화하여 정렬하고 결합한다.
◦
Bear: (Bear, 1), (Bear, 1)
◦
Car: (Car, 1), (Car, 1), (Car, 1)
◦
Deer: (Deer, 1), (Deer, 1)
◦
River: (River, 1), (River, 1)
Reducing (합산)
•
같은 키(단어)를 가진 값들을 합산하여 최종 결과를 계산한다.
◦
Bear: 1 + 1 = 2
◦
Car: 1 + 1 + 1 = 3
◦
Deer: 1 + 1 = 2
◦
River: 1 + 1 = 2
