


OpenAI o1 System Card
•
이번에 o1 모델이 나오면서 기존처럼 System Card도 같이 첨부되어 있었는데, 핵심 사항 및 주요 지표를 정리하자면 다음과 같다.
핵심 사항
•
o1 모델은 대규모 강화 학습(Reinforcement Learning)을 통해 체계적 사고(chain-of-thought)를 훈련함으로써 개발되었다.
⇒ 이는 모델이 단순히 질문에 답변하는 것을 넘어 복잡한 문제 해결 및 정책 준수도를 강화하는 데 중점을 둔다.
모델 학습 데이터
•
모델 학습 데이터로는 아래 나와있는 총 3가지의 데이터를 사용하였다.
◦
공개 데이터: 웹 데이터 및 오픈소스 데이터셋, 과학 논문과 같은 자료를 포함하여 일반적 지식과 기술적 주제 모두를 다룰 수 있는 학습 기반을 제공한다.

원문 공개 데이터 내용
◦
비공개 데이터: 데이터 파트너십을 통해 고부가가치 데이터를 확보, 특히 산업별 전문성을 강화하는 데 사용되었다.

원문 비공개 데이터 내용
◦
맞춤형 데이터셋: OpenAI 자체 개발 자료로, 위험한 콘텐츠를 걸러내는 안전 필터링과 정제 과정을 거쳤다.

원문 맞춤형 데이터셋 내용
특히 맞춤형 데이터에서는 데이터 필터링 및 정제 과정을 통해 개인정보와 해로운 콘텐츠를 제거하여 데이터 품질을 유지하는 데 중점을 두었다.
기존 모델 대비 주요 개선점
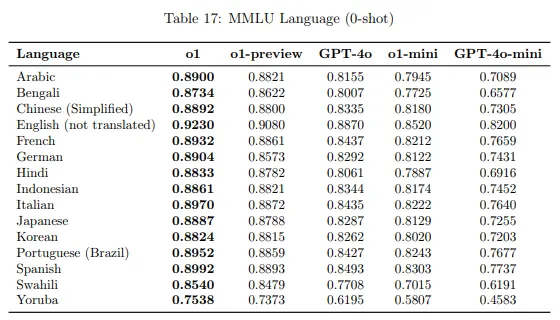
각 언어별 0-shot 성능 차이 표
•
기존 모델 대비 주요 개선점으로는 다음과 같이 3가지가 있다.
◦
추론 능력: o1 모델은 체계적인 사고 체인을 사용하여 사용자 요청에 대한 응답 전 심층적인 사고 과정을 제공한다. 이를 통해 GPT-4o 대비 더 높은 안전성과 정책 준수도를 보였다.
◦
안전성: o1 모델은 위험한 요청을 거부하는 능력에서 탁월한 성능을 보였으며, 특별히 챌린지 테스트에서 높은 점수를 기록했다.
◦
정확성: 단순 QA(SimpleQA) 및 인물 QA(PersonQA) 테스트에서 o1 모델은 GPT-4o 대비 높은 정확성과 낮은 환각률을 달성했다.
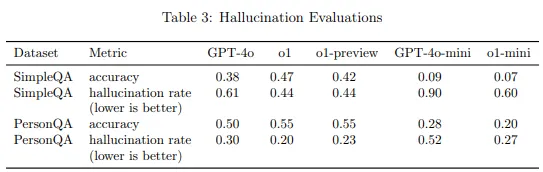
Hallucination Evaluations
•
이번에 o1모델은 주의 깊게 봐야하는 부분은 안전성에 관련된 부분인데, 실제로 읽어보니 안정성에 대한 내용과 지표가 두드러지게 많았다.
•
아무래도 최근에 대두된 AI 챗봇이 청소년의 자살을 부추긴 사건이나 미래 AI의 파급력을 고려해서 안전성을 중요시하게 여긴 거 같다.
Pairwise Safety Comparison
•
여기서 Red Teaming 평가 중에 Mitigation 되기 이전의 o1이 GPT-4o보다 덜 안전하다고 인식된 대화를 분석한 결과가 있는데 이부분도 흥미롭다.

안전 등급 비교 표
•
주요 문제로는:
◦
기본적으로 o1은 응답에 훨씬 더 자세한 내용을 입력하기 때문에, 이는 위험한 조언을 요청하는 프롬프트에서 더 안전하지 않은 것으로 평가되었다.
◦
GPT-4o는 위험한 조언을 요청하는 프롬프트에 대해 일반적인 조언으로 응답한 반면, o1은 더 깊이 관여하는 것으로 나타났다.
•
그래서 OpenAI측은 PII(개인 식별 정보)를 제거하고 CBRN(화학, 생물학, 방사선, 핵 관련) 위험 데이터를 필터링하거나 거부 정책을 강화하고 강화 학습(RLHF)을 통해 모델이 부적절한 요청을 정확히 식별하고 응답을 제한하도록 조정했다.
•
또한 Moderation API와 결합된 시스템 레벨의 안전 분류기를 활용하여 모니터링을 하고 사전 감지 및 차단 기능까지 도입하여 보완시켰다.
주요 지표
Disallowed content evaluation
•
우선 아까 말했던 안전성과 같은 부분에서 거부 평가(Disallowed Content Evaluations)에서 4가지 지표가 있었는데 그 중에서 Challenging Refusal(고난도 요청)에서 4o랑 비교했을 때 0.21%p 더 높았다.
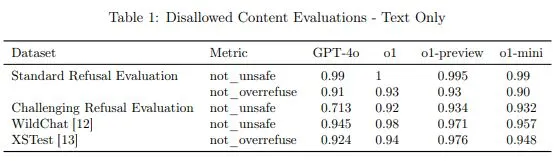
Disallowed Content Evaluations - Text Only
•
not_overrefuse Metric에서 Text Only에서 조금 더 나은 성능을 보이고 Multimodal 검증에서는 0.96이라는 높은 수치를 보였지만, 아까 말했던 Pairwise Safety Comparison부분과의 타협점을 찾고 있기 때문인지 not_unsafe Metric에서는 0.03%p정도 조금 낮은 수치를 보였다.
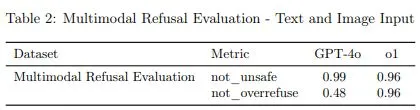
Multimodal Refusal Evaluation - Text and Image Input
Benchmark
•
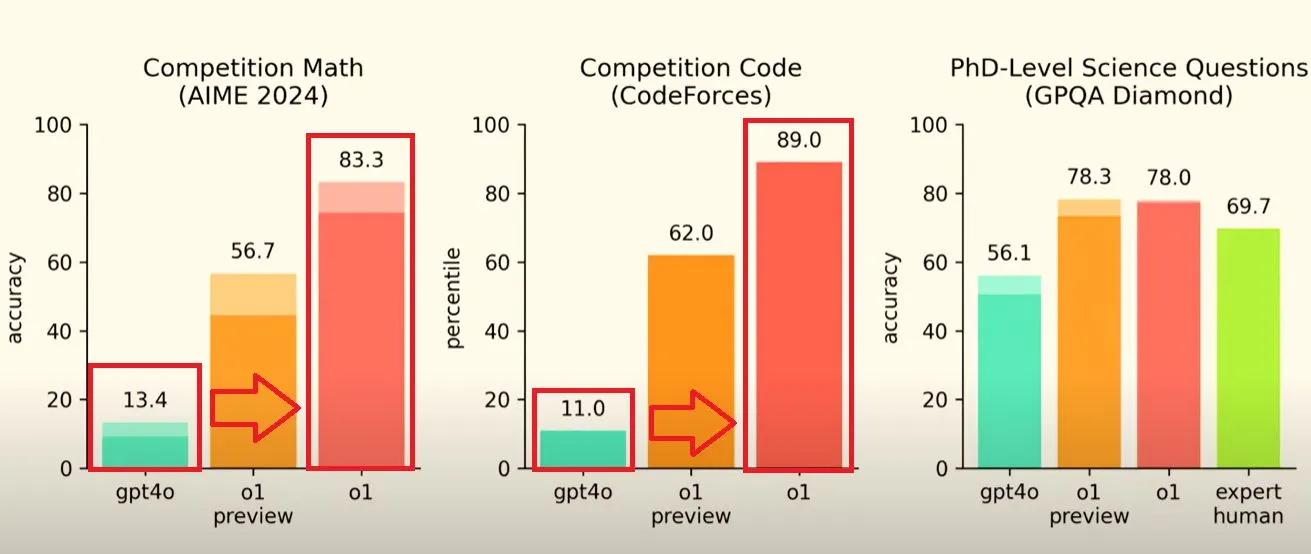
오늘 한국 시각으로 새벽에 진행한 Day 1 Live에서 샘 올트먼 형님이 이것저것 설명해 주시며 초반에 4o, o1 preview, o1의 벤치마크를 보여줬었다.
◦
수학, 코딩 능력에서는 사실 여기서 그렇게 성능이 좋다던 o1 preview도 50~60이였던게 충격적이였는데, 그에 비해 o1은 4o와 비교하였을 때 압도적인 성능 차이가 있다는 것이 보여진다.
▪
개인적으론 이 분야에서도 사람은 추월했다고 보인다.
◦
정말 어느 정도 도메인 지식을 가진 사람이 아이디어만 내면 인공지능이 대체하는 건 얼마 안 남은 이야기인 거 같다.
◦
또 의미심장한 것은 과학 부문에서 사람(expert human)과의 비교에서 인간보다 더 똑똑하다는 걸 입증한 부분이라고 보인다.
