.gif&blockId=11b00c82-b138-8050-a58b-dcbceda2ef8f)

Precision/Recall@K
•
주로 정보 검색과 추천 시스템에서 사용되는 Precision/Recall을 이용한 평가지표
◦
다만 추천 시스템은 하나의 아이템만 추천하지 않으며 정답도 여러개가 될 수 있다.
◦
따라서 등장한 것이 바로 K이다. K는 추천 아이템 수를 의미한다.
◦
높은 Precision을 원할 경우 작은 K를, 높은 Recall을 원할 경우 큰 K를 선택할 수 있다.

K: 모델이 상위 K개의 결과를 반환할 때, 평가의 기준
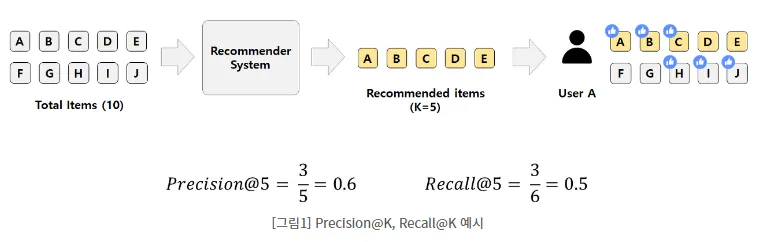
Precision/Precision@K (정밀도)
Precision
•
내가 추천한 아이템 K개 중에 실제 사용자가 관심있는(긍정) 아이템의 비율
•
모델이 얼마나 정확하게 긍정 사례를 예측했는지를 나타낸다.
Precision@K
•
상위 K개의 예측 결과 중 실제로 관련 있는 항목의 비율
•
는 모델이 상위 K개의 결과 중에서 얼마나 많은 관련 항목을 정확히 예측했는지를 나타낸다.
◦
상위 K개 결과의 정확도를 직접적으로 측정하므로, 사용자가 실제로 보는 결과의 품질을 평가할 때 유용
Recall/Recall@K (재현율)
Recall
•
사용자가 관심있는 모든 아이템 중에서 내가 추천한 아이템 K개가 얼마나 포함되는지 비율
•
는 모델이 실제 긍정 사례를 얼마나 많이 찾아냈는지를 나타낸다.
Recall@K
•
전체 관련 항목 중 상위 K개의 예측 결과에 포함된 항목의 비율
•
는 모델이 전체 관련 항목 중 얼마나 많은 항목을 상위 K개에 포함시켰는지를 평가
◦
모델의 포괄성을 측정할 때 유용
◦
사용자가 관심 있는 대부분의 항목이 상위 K개 결과에 포함되어 있음을 의미
한계
•
앞서 설명한 Precision/Recall@K는 모두 순서를 신경쓰지 않는다.
◦
Precision@K는 상위 K개의 결과 중 얼마나 정확하게 관련 있는 항목을 예측했는지를 측정하지만, 관련 항목의 전체 수를 고려하지 않는다.
◦
Recall@K는 전체 관련 항목 중 상위 K개의 결과에 얼마나 많이 포함되었는지를 측정하지만, 상위 K개 내의 정확도는 반영하지 않는다.
•
단독으로 사용할 경우 모델의 전체적인 성능을 충분히 평가하기 어렵다는 한계가 있다.
F-Score@K (or F1-score@K)
•
Precision@K와 Recall@K의 조화 평균
•
F1@K를 사용하는 이유
◦
Precision@K와 Recall@K는 상호 보완적인 관계이다.
→ Precision을 높이면 Recall이 낮아질 수 있고, 반대로 Recall을 높이면 Precision이 낮아질 수 있다.
◦
F1@K는 모델의 균형 잡힌 성능을 평가하는 데 유용하다.
Mean Average Precision@K
•
정보 검색 및 추천 시스템에서 모델의 정확성을 평가하는 데 사용되는 지표
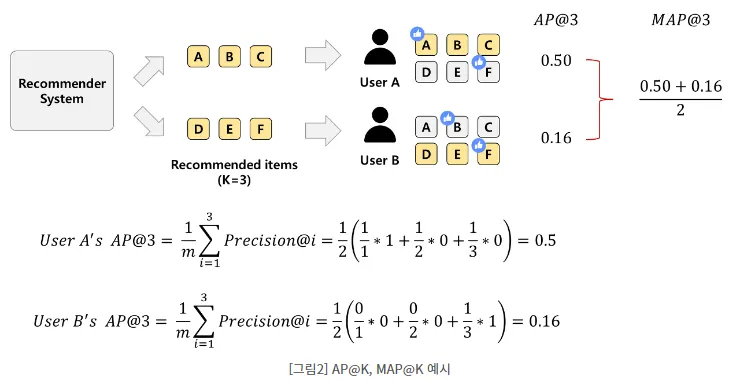
•
추천 시스템에서는 사용자가 관심을 더 많이 가질만한 아이템을 상위에 추천해주는 것이 매우 중요하다.
•
이를 위해 성능 평가에 순서 개념을 도입한 것이 Mean Average Precision@K이다.
•
이 지표는 여러 사용자에 대한 평균적인 정밀도를 측정하며, 특히 추천 목록의 상위 K개 항목에서의 성능을 평가하는 데 중점을 둔다.
◦
N: 전체 사용자 수
◦
: 각 사용자 에 대한 Average Precision@K
▪
: 추천 리스트에서 번째 위치까지의 정밀도(Precision)이며,
▪
는 번째 항목이 관련성 있는지 여부를 나타내는 이진 변수
(관련성이 있으면 1, 없으면 0).
▪
는 사용자 가 실제로 선호하는 관련 항목의 집합
이 수식은 각 위치 에서의 정밀도를 가중 평균하여 사용자의 평균 정밀도를 계산하고, 이를 모든 사용자에 대해 평균화함으로써 MAP@K를 도출한다.
•
각 사용자에 대한 평균 정밀도를 계산한 후, 이를 전체 사용자에 대해 평균화하여 모델의 전반적인 성능을 파악한다.
•
이는 단순히 추천된 항목 중 관련성이 높은 항목의 비율을 넘어서, 관련 항목이 얼마나 높은 순위에 위치하는지를 고려함으로써 보다 정교한 평가를 가능하게 한다.
사용자가 실제로 선호하는 아이템이 추천 리스트의 상위에 많이 위치할수록 MAP@K 값은 높아지며, 이는 사용자 만족도와 직접적으로 연관될 수 있다.
활용
•
MAP@K는 추천 시스템에서 사용자의 선호도를 정확하게 반영하고, 관련성이 높은 항목을 추천 리스트 상위에 배치하는 것이 중요한 경우에 특히 유용하다.
전자상거래 플랫폼에서 사용자가 구매할 가능성이 높은 상품을 상위에 추천하고자 할 때 활용할 수 있다.
뉴스 기사 추천이나 동영상 추천과 같이 사용자가 실제로 관심을 가질 가능성이 높은 콘텐츠를 효과적으로 제공하고자 할 때 활용할 수 있다.
•
이 지표는 단순한 정확도 측정보다 사용자의 만족도를 더 잘 반영하며, 관련 항목의 순위에 민감하게 반응하기 때문에 추천 알고리즘의 세부적인 성능 향상에 기여할 수 있다.
•
따라서, 추천 리스트의 상위 K개 항목의 품질을 중시하고, 사용자 경험을 최적화하고자 할 때 MAP@K를 사용하는 것이 적합하다.
NDCG@K
•
Normalized Discounted Cumulative Gain@K
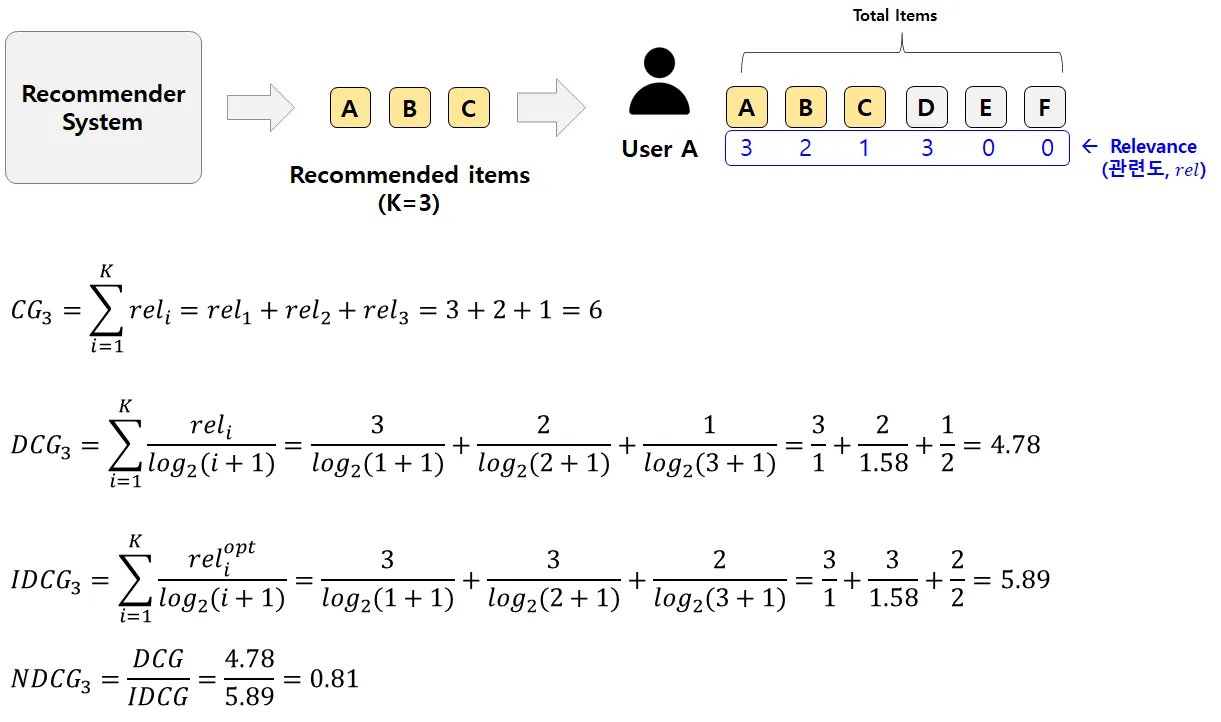
•
정보 검색 및 추천 시스템에서 추천 품질을 평가하는 데 널리 사용되는 지표
•
추천 리스트 내에서 관련 항목의 순위와 그 관련성의 정도를 동시에 고려하여 평가
◦
IDCG@K(Ideal DCG@K): 해당 사용자에 대한 이상적인 추천 리스트에서의 DCG@K 값
◦
DCG@K(Discounted Cumulative Gain@K): 추천 리스트의 상위 K개 항목까지의 누적 이득을 계산
▪
: 추천 리스트의 번째 항목의 관련성 점수
관련성 점수는 일반적으로 사용자의 선호도를 반영하여 부여되며, 0부터 시작하여 높은 값일수록 더 관련성이 높음을 의미
▪
DCG@K는 관련성 점수를 내림차순으로 정렬한 이상적인 추천 리스트에서의 DCG@K를 의미
→ 실제 추천 리스트의 DCG@K를 이상적인 DCG@K로 정규화하여 0과 1 사이의 값을 가지도록 한다.
NDCG@K는 이렇게 정규화된 값을 통해 추천 시스템의 성능을 상대적으로 평가할 수 있으며, 1에 가까울수록 이상적인 추천 리스트에 가깝다는 것을 의미한다.
•
특히, NDCG는 상위에 위치한 관련 항목에 더 높은 가중치를 부여하여 사용자의 실제 만족도와 밀접하게 연관된 평가를 제공한다.
→ 추천 시스템이 단순히 관련 항목을 많이 포함하는 것을 넘어, 관련 항목을 얼마나 높은 위치에 배치하는지를 효과적으로 반영
사용자가 실제로 선호하는 항목이 추천 리스트의 상위에 위치할수록 NDCG@K 값은 증가하며, 이는 추천 시스템의 품질이 높음을 의미
활용
•
NDCG@K는 추천 리스트에서 관련 항목의 순위가 중요한 경우에 적합한 평가 지표
검색 엔진에서 사용자에게 가장 관련성이 높은 결과를 최상위에 배치하는 것이 중요할 때 NDCG@K를 활용할 수 있다.
뉴스 추천 시스템이나 동영상 추천 서비스에서도 사용자가 가장 먼저 접할 항목의 관련성을 높이는 것이 중요할 때 NDCG@K를 활용할 수 있다.
•
이 지표는 단순히 관련 항목의 수를 세는 것보다 더 정교하게 추천 품질을 평가할 수 있으며, 특히 상위 K개 항목의 품질을 중시하는 응용 분야에서 효과적이다.
•
따라서, 추천 시스템의 순위 성능을 세밀하게 분석하고, 사용자의 만족도를 극대화하고자 할 때 NDCG@K를 사용하는 것이 적합하다.
Hit Rate@K
•
추천 시스템의 성능을 평가하는 간단하면서도 직관적인 지표 중 하나
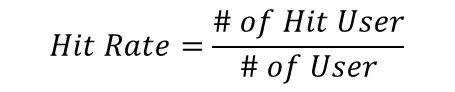
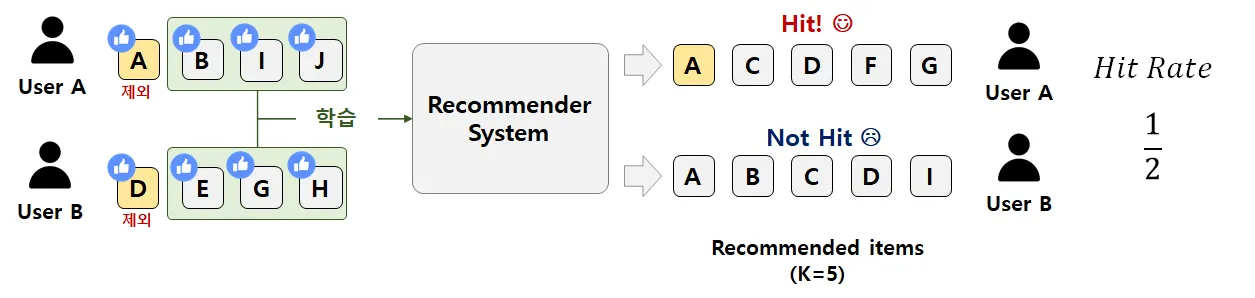
•
추천 리스트의 상위 K개 항목 중 적어도 하나가 사용자가 실제로 선호하는 항목과 일치하는지를 측정한다.
◦
N: 전체 사용자 수
◦
: 사용자 에 대한 추천 리스트의 번째 항목
◦
: 사용자 가 실제로 선호하는 관련 항목의 집합
◦
: 지시 함수, 조건이 참일 경우 1을, 거짓일 경우 0을 반환
◦
각 사용자에 대해 추천 리스트의 상위 K개 항목 중 적어도 하나가 실제 관련 항목 에 포함되는지를 확인하고, 이를 모든 사용자에 대해 평균화하여 Hit Rate@K를 계산한다.
◦
결과적으로, Hit Rate@K는 전체 사용자 중 추천 리스트에서 관련 항목을 "히트"시킨 비율을 나타내며, 0부터 1 사이의 값을 가잔다.
→ 값이 클수록 추천 시스템이 사용자의 관심을 효과적으로 반영하고 있음을 의미
•
이 지표는 추천 리스트가 사용자의 관심사와 얼마나 일치하는지를 이진적으로 평가하며, 단순히 관련 항목의 포함 여부에 초점을 맞춘다.
•
Hit Rate@K는 사용자가 실제로 관심을 가진 항목을 추천 리스트 상위에 포함시키는 것이 얼마나 잘 이루어졌는지를 나타내며, 특히 사용자가 하나 이상의 관심 항목을 가질 때 유용하게 사용된다.
전자상거래 플랫폼에서 사용자가 구매할 가능성이 있는 상품을 상위 K개에 포함시키는 것이 목표일 때, Hit Rate@K는 해당 목표를 얼마나 잘 달성했는지를 평가하는 데 적합하다.
활용
•
Hit Rate@K는 추천 시스템에서 사용자의 관심 항목을 적어도 하나 이상 추천 리스트 상위에 포함시키는 것이 중요한 경우에 적합한 평가 지표입니다.
영화 추천 시스템에서 사용자가 관심을 가질 만한 영화를 상위 K개에 포함시키는 것이 목표일 때, Hit Rate@K는 이를 효과적으로 평가할 수 있다.
뉴스 추천이나 광고 추천 등에서 사용자가 관심을 가질 가능성이 있는 항목을 빠르게 포착하는 것이 중요할 때도 Hit Rate@K는 유용하게 사용된다.
•
이 지표는 간단하면서도 직관적인 평가를 제공하기 때문에, 시스템의 기본적인 성능을 빠르게 파악하고자 할 때 유용하다.
•
따라서, 추천 리스트 내에 사용자의 관심을 충족시키는 항목이 포함되는지를 빠르게 확인하고자 할 때 Hit Rate@K를 사용하는 것이 적합하다.
