


Deep FM
•
Factorization Machine(FM)과 Deep Neural Network(DNN)을 결합하여, low-order feature interaction과 high-order feature interaction을 동시에 학습하는 CTR 예측 모델.
•
FM을 통한 2차 상호작용 모델링과 DNN을 통한 고차 상호작용 학습이 통합되어 하나의 모델 안에서 End-to-End로 학습되는 구조를 가진다.
•
이는 Wide & Deep 모델과 달리 embedding 레이어를 공유함으로써 파라미터 효율성과 학습 효율성을 동시에 얻는다.
•
Factorization Machine (FM)
◦
low-order interaction뿐만 아니라 high-order interaction도 이론상으로 모델링이 가능하다.
◦
하지만 후자까지 고려할 경우 모델의 complexity가 너무 커져 사실상 사용하기 어렵다.
•
Factorization Machine supported Neural Network (FNN)
◦
NN 기반으로 high-order interaction은 모델링이 가능하다.
◦
하지만 low-order를 제대로 포착하기 어렵고 pre-train FM을 사용하기 때문에 이것의 성능이 모델 전체의 성능을 좌우하게 되는 단점이 있다.
CTR (Click-Through Rate)
•
CTR 예측은 사용자가 특정 아이템(광고나 추천 아이템)을 클릭할 확률을 추정하는 문제이며, 이 때 feature 간 상호작용을 잘 포착하는 것이 핵심이다.
•
Low-order interaction(예: "앱 카테고리"와 "시간대"의 상호작용)뿐만 아니라 고차 상호작용(예: "유저의 성별", "나이", "선호하는 앱 카테고리" 사이의 복잡한 관계)도 학습해야 한다.
•
DeepFM은 이러한 다양한 계층의 상호작용을 단일 모델 안에서 처리한다는 점이 특징이다.
◦
이러한 CTR을 최대화하려면, 다양한 user-item 특성들의 상호작용을 포착해야 하며, DeepFM은 이를 효율적으로 처리한다.
Click - Through Rate Prediction for recommendation
•
CTR Prediction은 User가 추천 아이템을 클릭할 확률을 추정하는 것으로 유저에게 추천될 아이템의 순위를 매길 수 있다. 또한 온라인 광고 같은 시나리오에서도 수입을 증가시킬 수 있다.
•
CTR Prediction은 User click 행동에 존재하는 implicit feature interactions를 학습하는 것이 중요하다.
•
일반적으로 User click 행동의 interactions는 매우 복잡하고 low-order, high-order interaction이 중요한 역할을 한다.
식사시간에 배달앱 다운로드 하는 경우 많음 ->"app category"와 "time-stamp"의 interaction (order-2)
10대 남자들은 Shooting games & RPG games 좋아함 ->"app category", "gender", "age"의 interaction (order-3)
◦
예시와 같이 쉽게 어떠한 feature interactions는 이해할 수 있지만, 대부분의 feature interactions는 데이터 속에 숨겨져 있어서 알기 어렵다.
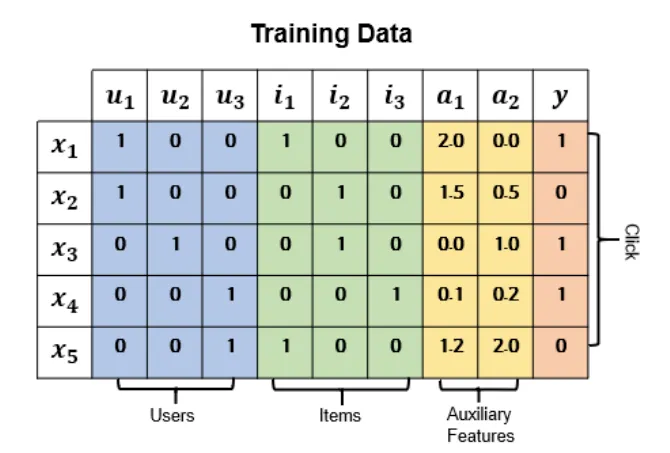
Training Dataset
•
y(target)
◦
Binary (1: user가 아이템을 클릭, 0: 클릭하지 않음)
•
x(features)
◦
Categorical fields (예: gender): one-hot encoding 후 embedding
◦
Numerical fields (예: age): value 혹은 discretization 후 embedding
◦
모든 입력 feature들은 Embedding Layer를 거쳐 같은 차원 k로 사상된 dense 벡터로 변환된다다.
◦
이 embedding 과정을 통해 Sparse한 high-dimensional input을 low-dimensional dense vector로 나타낼 수 있으며, 이는 FM과 DNN 모두에 효율적으로 활용된다.
Model Structure
•
Factorization Machines(FM)과 Deep Neural Network(DNN)의 구조를 결합한 새로운 NN 모델이다.

•
Wide & Deep 모델과 다르게 같은 input, embedding layer를 공유하기 때문에 효율적으로 학습할 수 있다.
•
Benchmark data와 commercial data에 평가한 결과 다른 CTR Prediction 모델보다 일관적으로 향상된 결과를 보였다.
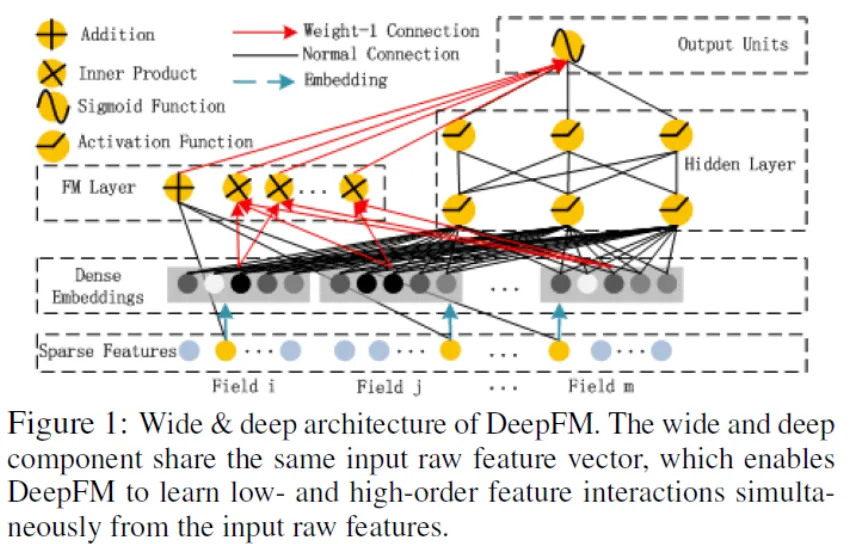
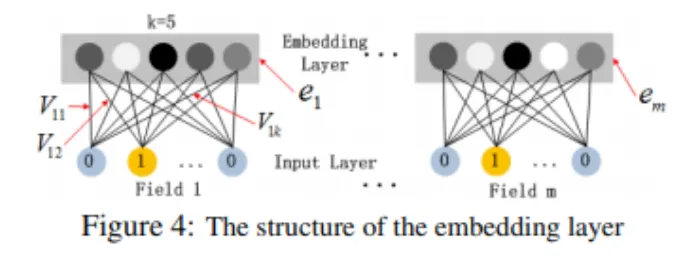
Shared Embedding Layer
•
각 field에 대해 k차원 embedding 벡터를 학습한다.
•
예: Gender(남/여), Age(정수), Region(카테고리) 등 모든 feature들을 k차원 벡터로 임베딩.
•
임베딩 벡터: , 여기서 는 특정 field 혹은 feature index를 의미한다.
Dense Embeddings
FM Component와 Deep Componet가 같은 Embedding 벡터를 공유한다. 이러한 구조는 두 가지 정점을 가진다.
1.
Field vector의 크기가 다를 수 있지만 Embedding Layer로 인해 같은 크기(k=5)를 가진다.
Genger의 경우 크기가 2인 vector이지만 국적이나 나이의 경우 Gender보다 더 큰 벡터를 가지게 된다. 하지만 결과적으로 k-dimension으로 Embedding된다.
2.
pre-trained할 필요가 없고 End-to-End로 학습을 할 수 있다.
FM Component
•
FM의 핵심은 2차 상호작용을 내적(inner product)으로 모델링하는 것이다.
•
FM의 예측 부분을 수식으로 표현하면 아래와 같다.
◦
: one-hot으로 표현된 feature value.
(Categorical일 경우 0 또는 1, Continuous면 원래 값)
◦
와 : bias와 1차 항의 가중치
◦
: 두 임베딩 벡터간의 내적(dot product), 2차 상호작용을 표현한다다.
•
FM component는 저차(2차) 상호작용을 효율적으로 포착하며, 많은 feature들이 Sparse할 때도 일반화 능력이 탁월하다.
Deep Component (DNN)
•
Deep Component는 임베딩된 feature 벡터들을 입력으로 받아 고차 상호작용을 비선형적으로 학습한다.
•
예: 임베딩 벡터들을 모두 concatenation한 뒤 fully-connected layer를 통과시키며 ReLU나 PReLU 등의 활성함수를 사용해 복잡한 상호작용을 학습.
•
DNN의 출력: 는 hidden layer를 거쳐 나온 scalar값으로 표현된다.
•
DNN 부분의 일반적인 수식 표기는 다음과 같다.
◦
: 활성함수
◦
: l번째 layer의 파라미터
◦
: l번째 layer의 hidden representation
DeepFM의 장점
1.
Embedding 공유로 효율성 향상: FM과 DNN 모두 동일한 임베딩 레이어를 공유하므로 파라미터 수가 줄고 학습 효율이 증가한다.
2.
Pre-training 불필요: 기존 FNN(Factorization-machine supported Neural Network)는 FM으로 사전학습을 필요로 했으나, DeepFM은 처음부터 End-to-End 학습 가능하다.
3.
성능 개선: 벤치마크 및 상용 데이터에 대한 실험에서 Wide&Deep, FNN 등 기존 모델 대비 일관된 CTR 예측 성능 향상을 보인다.
DeepFM 이후 개선된 모델
xDeepFM(Extreme DeepFM)
•
기존 DeepFM에 CIN(Compressed Interaction Network)를 추가하여 다양한 차수의 상호작용을 압축적으로 표현할 수 있도록 개선한 모델
•
xDeepFM은 CTR 예측에서 SOTA(State-of-the-art)에 가까운 성능을 달성하는데 도움을 준다.
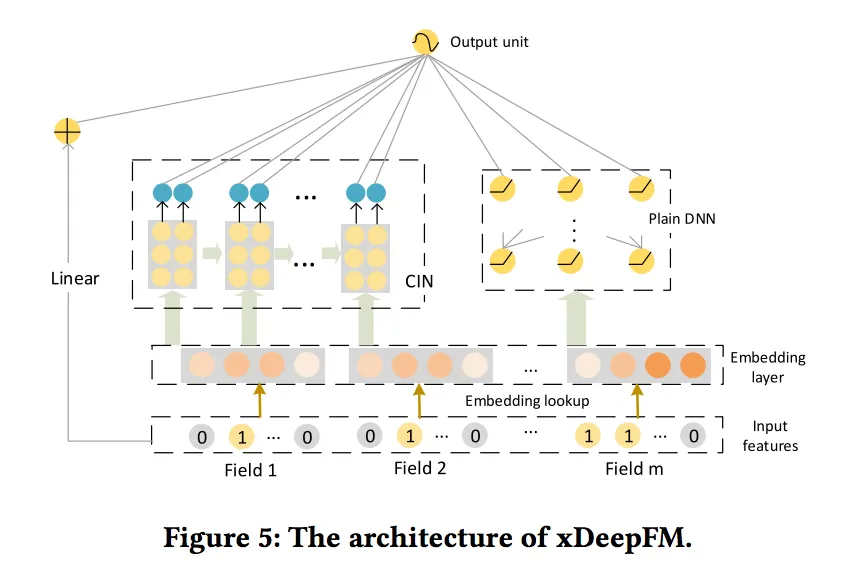
◦
이전의 DeepFM과의 차이점은 CIN부분이다.
▪
FM or Product Layer를 제외하고는 구조는 매우 유사하다.
▪
실제 xDeepFM은 DeepFM(아래 이미지)에서 FM구조가 CIN으로 변경된 것이다.
