

모두의 연구소
모두의 연구소 로고
뭘 하는 곳인가
•
기업이 원하는 실무형 고급 인재를 양성하는 커뮤니티 기반의 성장형 연구 및 교육 플랫폼
•
인공지능(AI), 데이터 과학(Computer Science), 프로그래밍 등 다양한 분야에서 연구와 학습을 할 수 있도록 협업하는 커뮤니티.
•
정해진 교육기관이 아니라, 누구나 연구원으로 참여해 자유롭게 배우고 연구할 수 있는 환경을 제공한다
•
누구나 자유롭게 연구하고 학습할 수 있는 환경을 조성하여, 부트캠프, 국비지원 교육, 기업 맞춤형 교육 등을 통해 실무 중심의 학습 경험을 제공한다.
핵심가치
문화
•
모두의연구소는 "Share Value, Grow Together"를 미션으로 삼아, 지식과 경험을 공유하며 함께 성장하는 문화를 지향한다.

홈페이지에 나와있는 가치관: ‘함께 지식을 공유하고 성장하는 연구 문화를 전파하는 것’
•
이를 위해 내부와 외부의 문화가 동일하도록 노력하며, 열정, 상생, 꾸준함을 강조한다.
•
또한, 성과보다는 진정성을 우선시하며, 투명한 소통과 신뢰를 바탕으로 한 커뮤니티를 구축하고자 한다.
핵심가치
•
상생
•
신뢰
•
열정
•
자기주도
•
정보 공유
•
문화 전파
서비스
•
아이펠(AIFFEL)
◦
모두의연구소의 AI 교육 플랫폼
•
커뮤니티
◦
지도 교수와 상대평가가 없는, 누구에게나 열린 연구 플랫폼
◦
동료 학습과 열린 연구로 함께 지식과 경험을 나누며 성장하는 선순환 생태계를 형성
•
오름캠프
◦
2023년 10월에 처음 런칭된 커뮤니티 기반의 성장형 교육 & 전문성 있는 교육을 만들고자 하는 SW 교육 플랫폼
•
오름클래스
◦
AI/Digital 기술을 활용해 현업(직무)의 고충점을 해결하는 온라인 강의 플랫폼입니다.
•
오름Biz
◦
오름Biz는 기업을 대상으로 운영하고 있는 기업 맞춤형 AI/DX 서비스 플랫폼 입니다.
컨퍼런스
참가자 등록
•
참가자 등록은 모두콘 공식 홈페이지에서 진행하였다.
•
양식은 구글 폼으로 작성하였으며 워크샵과 네트워킹 같은 참여형 프로그램에선 별도로 신청하여 이후 추첨되었다. (필자는 뽑히지 않아 이후 현장에서 선착순 신청으로 참여하였다.)

•
그럼 이후에 이메일로 QR코드가 날라온다.

행사
•
모두콘(MODUCON)은 이번에 처음 참여했는데 생각보다 너무 깔끔하게 운영되어서 정말 깜짝 놀랐다.
•
스태프 분들이 많았는데 다들 친절하시고 활발하셔서 부스를 돌아다니며 쉽게 안내받고 체험할 수 있었다.

카드 체험 부스

Time table 및 참여했던 세션
•
사진은 못 찍었지만 점심으로 크라이스 치즈버거랑 물을 제공받았다. 개인적으로 좋아하는 버거 회사인데 정말 맛있게 먹었다.
브랜드 각인
•
이번 컨퍼런스를 통해 확실한 건 모두의 연구소가 어떤 곳인지, 어떤 서비스를 하고 있는지 확실하게 알 수 있었고 관심도가 커졌다는 것이다.
•
기본적으로 받은 선물들은 우선 지원사 중에 카카오가 있어서 그런지 카카오 선물이 많았고 (굉장히 귀여운) 사진에는 없지만 달력도 같이 받았다.
•
추첨을 통해 친필 싸인 저서, 티셔츠 마그넷 클립, 스티커 등을 경품으로 받을 수 있었다. (저서는 아쉽게도 당첨되지 못했다.)
•
럭키드로우도 진행했었는데 여기선 뭐 항상 뽑기만 하면 꽝이 걸리는 나는 그러려니 했고, 1등상은 에어팟 맥스였다. (위 추첨도 전부 다 꼴등상)

필자가 받은 선물 내역
세션
•
각 세션마다 연사자분들에게 너무 많은 것을 배울 수 있었는데, 발표 내용 뿐만 아니라 칼 같은 발표 시간과 정보 주입력, 효과적인 PPT 구성 같이 발표 면에서도 배울 수 있었다.
◦
이 발표에 대해 중요하게 생각했던 이유는 타 컨퍼런스의 경우, 시간을 오버하거나 발표 구성이 잘 짜여지지 않는 경우가 있었다.
◦
내가 들었던 세션에서는 연사자분들이 그때그때 시간을 체크해가며 유동적으로 템포를 조절하거나 주요 내용에 대해서 위주로 설명하는 등의 테크닉을 사용하여 각자 시간을 맞추려고 노력하시는 게 보이셨다.
•
NVIDIA 세션의 경우, 네트워킹이 이어져서 덕분에 아쉬웠던 짧은 QnA 시간을 커버할 수 있었다.
◦
정말 멘토님에게 폭풍 질문 쇄도를 하며 많은 걸 알아가는 시간이였다.
AI Agent 팀과 LLM 오케스트레이션의 비밀
•
AI Agent 팀
◦
LLM들끼리 협업하는 구조를 갖춘다.
Prompt Engineering
•
Reasoning Module
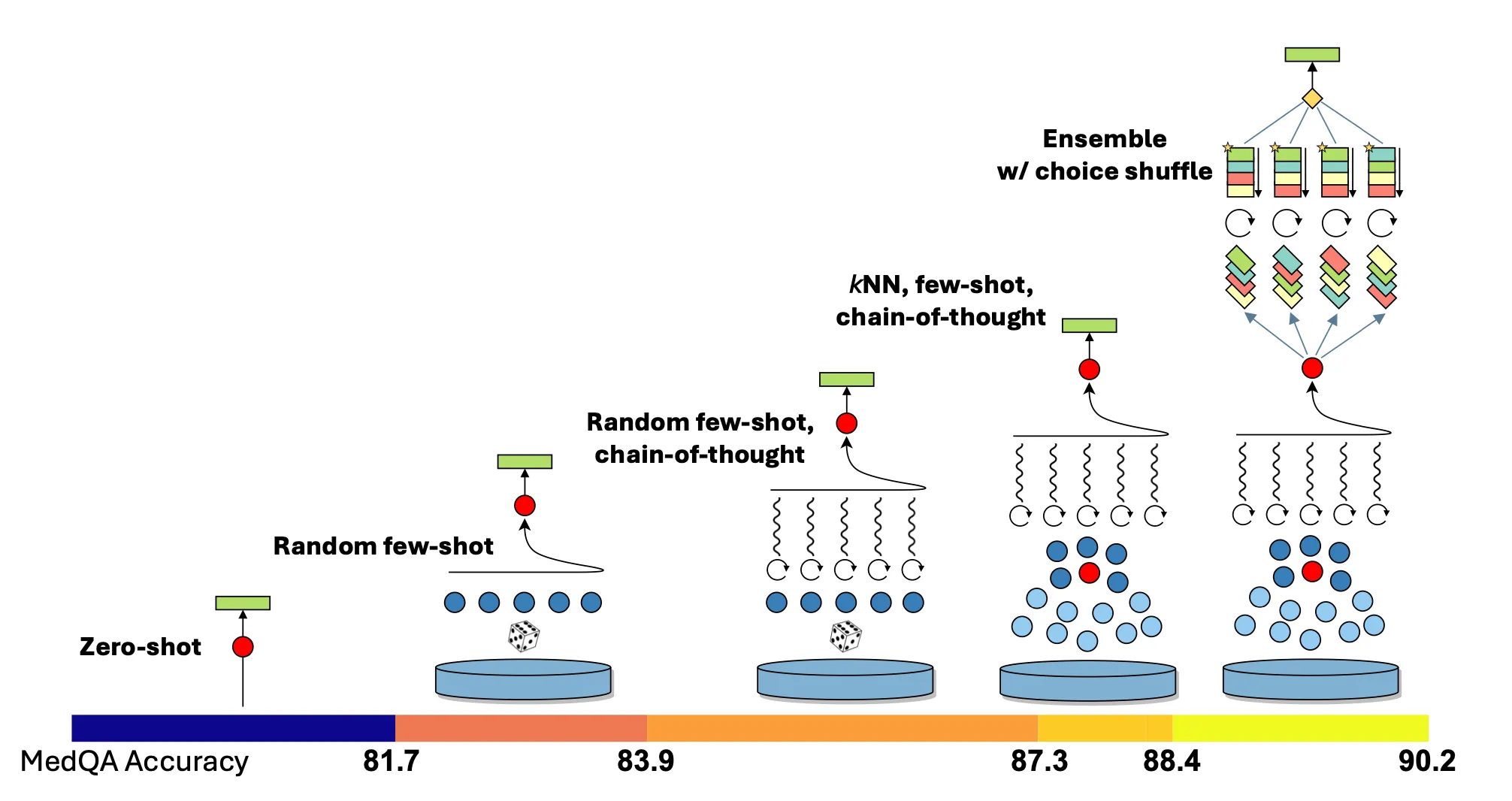
성능 향상 스냅샷
◦
사람도 프로젝트를 진행할 때, 어떤 방법론으로 협업할 건지를 정하는 것처럼, LLM간의 협업도 어떤 방식으로 협업을 할지 의사 결정이 필요하다.
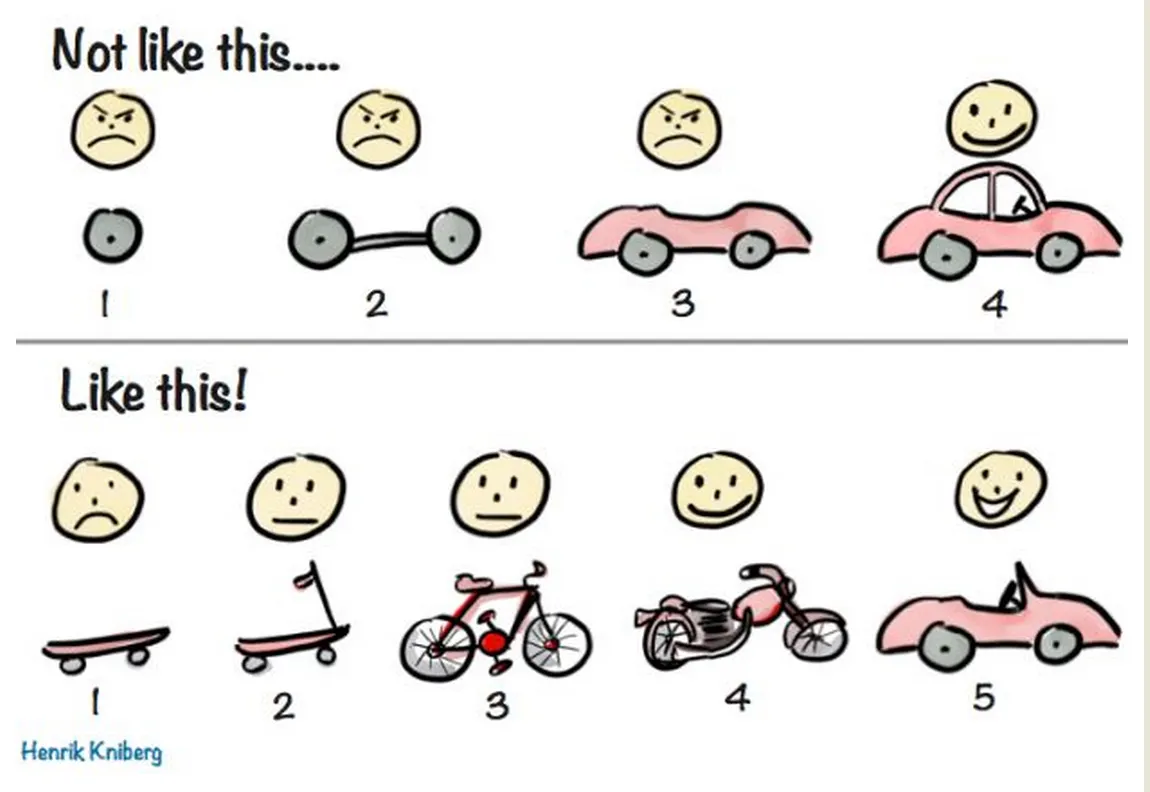
◦
예시로, 에자일 방법론, 폭포수(Waterfall) 모델 등이 있다.
•
Self-Discover
◦
사전에 다양한 추론 구조(Reasoning Structure)를 정의하고 이 중 적절한 추론 방식을 LLM이 선택하여 추론을 진행한다.
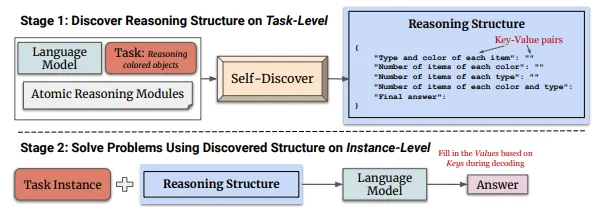
SELF-DISCOVER: Large Language Models Self-Compose Reasoning Structures -[Submitted on 6 Feb 2024]
Flow Engineering
•
여기서 Flow는 여러 에이전트가 환경과 서로 협력하고 상호 작용하여 작업을 완료하는 반복적 프로세스이다.
•
Flow Engineering은 작업을 더 작은 단계로 나누고 LLM이 답변을 스스로 정제하도록 촉구하여 신속한 엔지니어링을 향상 시켜 정확도를 높이고 더 나은 성과를 내는 과정이다.
•
MoE (Mixture of Experts): 병렬 구조
◦
여러 전문가 모델(Experts) 중에서 일부만 선택적으로 활성화하여 학습과 추론을 수행하는 방식
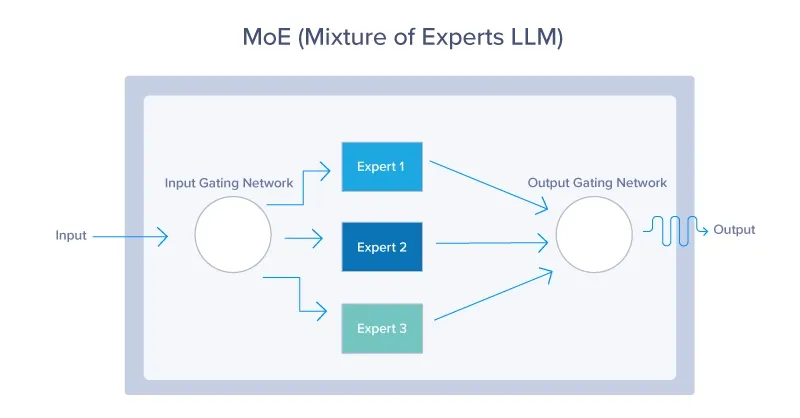
•
MoA (Mixture of Agents): 직렬 구조
◦
여러 에이전트(Agents)들이 순차적으로(직렬로) 협업하는 방식
◦
각 에이전트는 특정 태스크를 해결하는 데 특화된 역할을 수행한다.
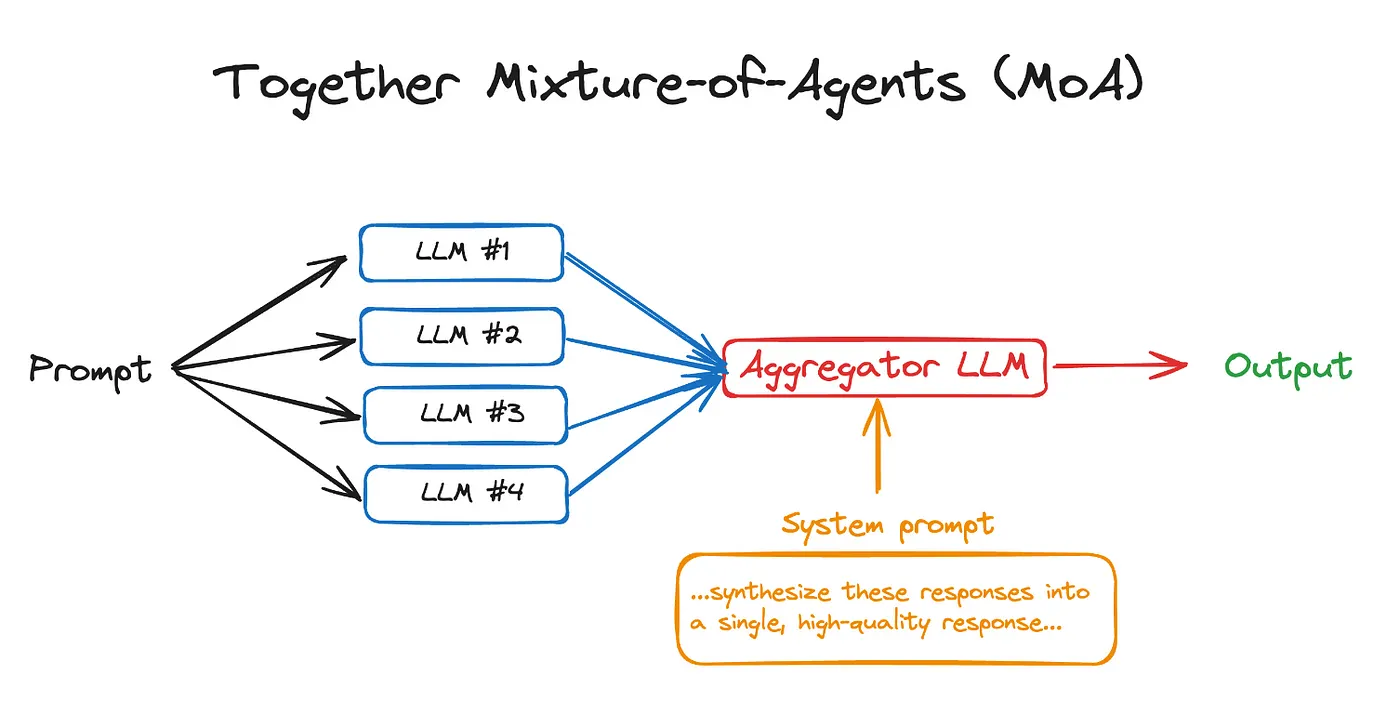
플로와이즈

•
LLM Ochestration Framework
◦
프레임워크를 사용하지 않을 경우 기본적으로 노드가 30개 정도 되는데 이걸 50번 정도 직접 수정을 해야한다.
•
플로와이즈는 RAG부터 MultiAgent, MoA(Mixture of Agent)까지 기업을 위한 LLM 올인원 솔루션, 현재 기업의 로컬 환경에서 오픈소스 LLM 모델을 통해 Group-Reflection을 구현할 수 있는 독보적인 수단이다.
Group-Reflection: 팀이나 그룹이 함께 모여 특정 작업, 프로젝트, 경험 등에 대해 돌아보며 공동으로 성찰하는 과정
•
구현 예시 (RAG)
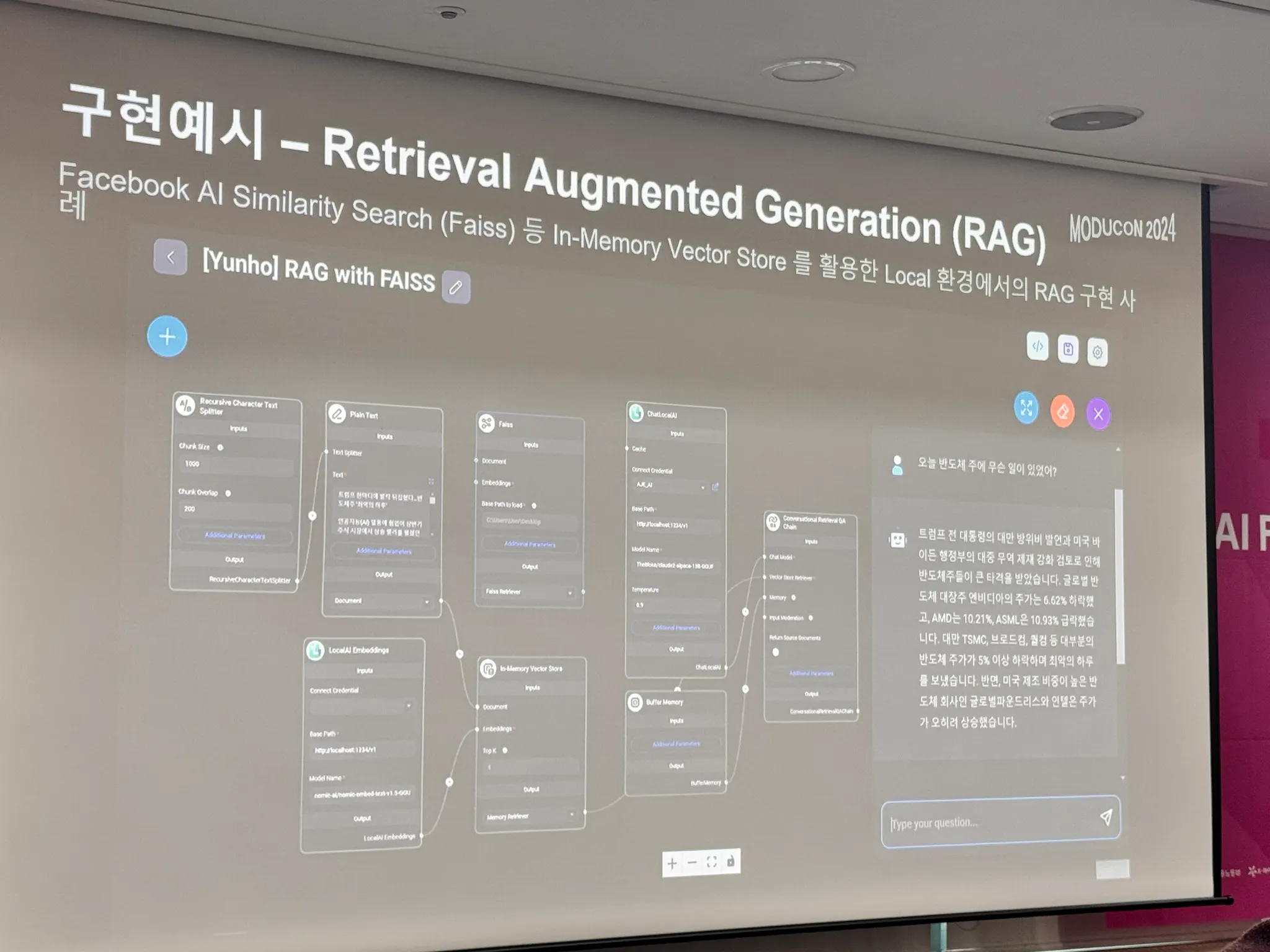
•
랭체인(LangChain) 등의 코드 구현을 통해 협업의 과정을 인위적으로 하드코딩하여 추가할 수 있으나, 이는 어디까지나 사람이 협업을 인위적으로 구성한 것 뿐이다.
◦
언제 협업을 끝낼 지, 누구와 협업할지를 LLM 스스로 선택할 수 있어야 진정한 Group-Reflection이다.
◦
사람과 LLM이 함께 작업하면, LLM끼리만 작업을 했을 때보다 성과가 더 안 좋아지기도 한다.
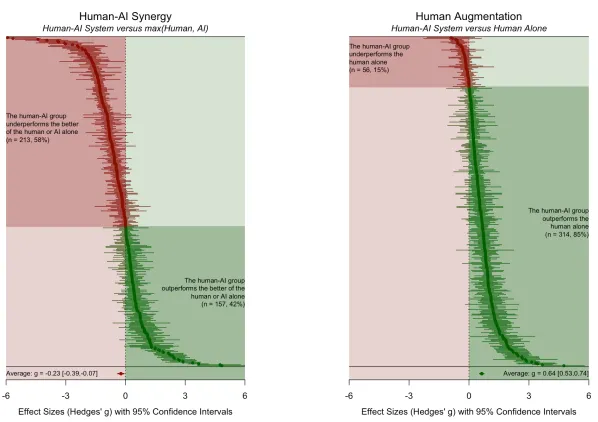
When combinations of humans and AI are useful last revised 29 Oct 2024
◦
플로와이즈는 무한 루프를 막기 위해 최대횟수를 제한하고 스스로 의사결정을 할 수 있도록 지원한다.
이 부분에서 필자는 개인적으로 토큰 사용량 측면에서나 Supervisor로서의 역할을 어떻게 성능과 비용을 고려하여 개선할 것인지에 대한 문제를 제시한다.
•
플로와이즈의 목적
◦
기존 문제 분석
▪
사람이 생성한 텍스트 데이터를 학습한 LLM은 편향(Bias)성을 지닌다.
▪
LLM의 정보를 통해 의사결정을 하는 사람도 편향(Bias)이 존재하기 때문에 다양한 측면을 고려할 수 있는 리서치 역량과 더불어 도입에 필요한 실무 역량이 필수적이다.
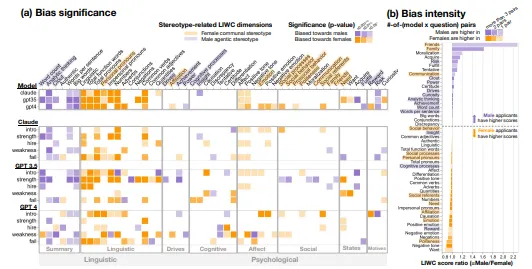
Gender Bias in LLM-generated Interview Responses last revised 28 Nov 2024
◦
목적
▪
위와 같은 문제를 해결하기 위해 사람을 대체하도록 LLM 올인원으로 대체하자.
모두의 연구소 NVIDIA 기술랩 세션
NVIDIA
•
NVIDIA는 GPU만 만드는 회사이다?
◦
NVIDIA는 기존 반도체 시장 뿐 아니라 Application Frameworks와 상호 연결되어 있는 NVIDIA AI, Omniverse같은 Platform, Acceleration Libraries, System Software 등 다양한 분야로 확장하고 있다.

•
다양한 기술 스택과 교육
◦
NVIDIA는 다양한 툴, 에코시스템을 통해 GPU를 효과적으로 사용하여 문제를 해결한다.

◦
이런 기술들은 NVIDIA사에서 다양한 교육 자료로 제공해주고 있다.
데이터 과학이란?
•
데이터 과학은 수학, 통계, 인공 지능, 컴퓨터 공학 분야의 방법과 기법을 결합하여 대량의 데이터를 분석하는 융합적 접근 방식이다.
wikimedia commons
•
단순 정량적 분석이 아닌 도구, 방법, 기술을 사용하는 지식을 결합하여 데이터에서 의미를 창출한다.
•
데이터로부터 알 수 있는 것들:
◦
무슨 일이 일어났는지?
◦
이 일이 왜 일어났는지?
◦
앞으로 무슨 일이 더 일어날지?
◦
이 결과를 가지고 무슨 일을 더 할 수 있을지?
손쉽게 달성하는 데이터 과학 가속화 - RAPIDS
•
CPU 기반 라이브러리들을 GPU 기반으로 변경하여 사용할 수 있게 해주는 라이브러리
•
CUDA 기반으로 작성되어 있다.
•
Machie Learning Life Cycle
◦
Machine Learning 환경은 선형이 아니다.
▪
일반적으로 우리는 ML(DL)을 선형적으로 생각한다.
▪
크게 데이터 및 모델 탐색, 모델 학습 및 적용, 모델 배포 및 서비스로 바라볼 수 있다.
▪
하지만, 배포된 모델로 부터 continual하게 learning한다면, 점점 더 나은 서비스를 만들 수 있다.
◦
이 때 많은 경우 우리는 데이터 엔지니어링을 한다.
▪
데이터를 탐색하고, 어떤 모델을 선정할지(Data Science)
▪
선택한 모델을 활용하여 실제 DB로 부터 데이터를 학습하는 과정(Data Engineering)
▪
배포된 모델로부터 사용자에게 결과를 돌려주거나 테스트 하는 과정(Data Engineering)
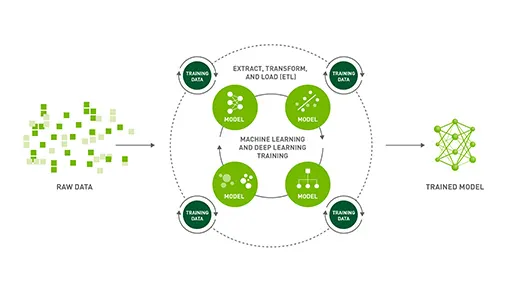
•
아파치 애로우(Apache Arrow) 인메모리 데이터 구조 기반으로 구현된 RAPIDS는 판다스(pandas), 사이킷런(scikit-learn)과 거의 동일한 파이썬 인터페이스를 제공한다.
◦
코드를 전혀 변경하지 않고도 기존 라이브러리(Pandas 등)의 속도를 높이고 성능을 크게 향상시킨다.
•
Query Optimization
◦
RAPIDS Accelerator를 사용하여 Query Optimization을 할 수 있다.
•
리드를 하면서 필터링까지 같이 해버림.

데이터 처리 진화 과정
•
HPC 환경에서 더 좋은 것 같다.
◦
RAM에서 손해보는 연산을 할 수 밖에 없음
◦
자체적으로 분석해서 같이할 수 있는 건 같이 해버린다.
◦
gpu 카파빌리티 성능이 좋으면 당연히 좋아진다.
•
메시브한 데이터에서 효과가 좋다.
•
메모리를 management하는 라이브러리가 따로 있다.
•
colab, kaggle 환경에서도 지원하고 있음
병렬화와 추론 최적화
•
NVIDIA NLP Forge LAB
◦
NLP 추론쪽으로 도움
◦
Megatron, 병렬화
◦
LLM 기반 오픈소스 서비스 개발
▪
Code Assistant
▪
Image Embedding 기반 Image Search
•
GPU 병렬화 기술 개론
◦
Data Parallelism
▪
배치별로 데이터를 쪼개서 각각의 노드로 보낸다.
◦
Tensor Parallelism
▪
모델안에 들어있는 파라미터를 쪼개서 각각의 GPU로 보낸다.
▪
Column-wise
▪
Row-wise
◦
Pipeline Parallelism
▪
Layer단위로 쪼개서 각각의 GPU로 보낸다.
•
플롭스를 계산 - 각각의 GPU가 얼마나 부동소수점 연산을 할 수 있냐.
•
향후 활동
•
NLP 추적, Pararel
Foundation Model
•
엄청난 양의 데이터로 학습된 대규모 딥러닝 모델
•
비지도 학습(unsupervised learning)을 통해 훈련된 AI 신경망
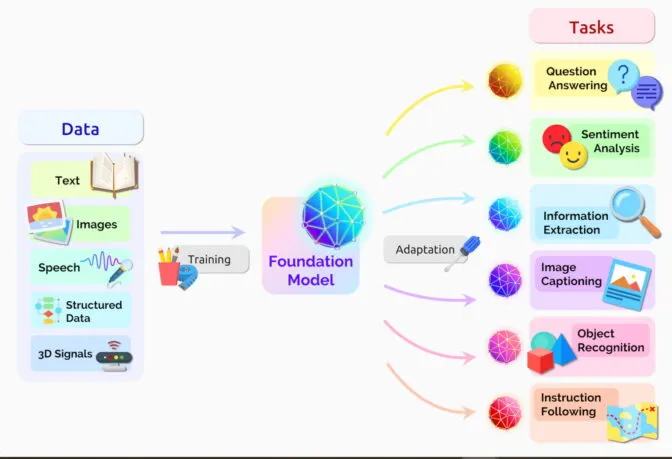
2021년 논문에서 연구자들은 파운데이션 모델이 다양한 용도로 사용되고 있다고 보고하였다.
•
연구자들과 일반인들이 머신러닝을 사용하는 방식을 획기적으로 바꾼 기술
→ 다양한 작업을 한 번에 처리할 수 있는 만능형 ML 모델
•
주로 label이 없는 데이터를 사용해 폭넓고 일반화된 지식을 학습한다.
•
이 모델은 청므부터 특정 작업을 위해 만들어진 것이 아니라, 여러 작업에서 활용될 수 있도록 기본 지식을 담고 있다.
•
이를 통해 언어 이해, 텍스트 및 이미지 생성, 음성 인식 같은 작업을 효율적이고 효과적으로 처리할 수 있다.
Stable Diffusion, ChatGPT-4o, Sora
•
특징
1.
다목적 활용 가능성
•
자연어 처리, 이미지 생성, 음성 인식 등 여러 분야에서 활용 가능
2.
간단한 데이터로 Fine-tuning
•
사전 학습된 모델이기 때문에 소량의 데이터로도 특정 작업에 맞게 빠르게 맞춤화가 가능
3.
강력한 초기 성능
•
대규모, 고품질 데이터를 바탕으로 학습해 초기 성능이 뛰어남
NVIDIA Foundation Model Lab
•
선정 이유
◦
Foundation Model Application Task는 실무에서 성능이 안정적이고, 산업적 활용도와 수요가 높을 것으로 판단
•
연구 초점
◦
Foundation Model 활용 및 최적화: GPU 비용은 줄이고 학습 시간이 적은 응용 연구에 집중
