•
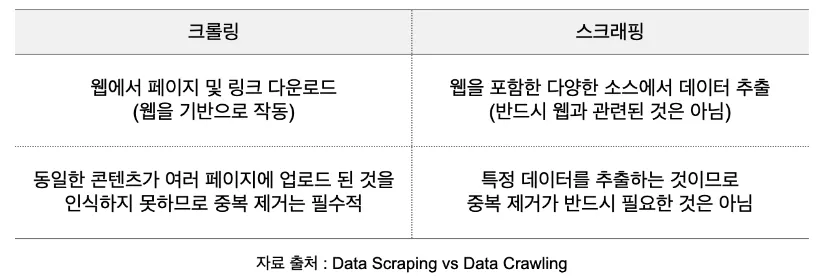
웹 스크래핑(Web Scraping) : 웹 사이트 상에서 원하는 정보를 추출하는 방법
•
웹 크롤링(Web Crawling)
◦
웹 크롤러(web crawler)가 정해진 규칙에 따라 복수 개의 웹페이지를 탐색하는 행위
= 웹 스파이더링
◦
웹페이지 탐색 후 원하는 정보 추출(Web scraping)하여 저장하는 것
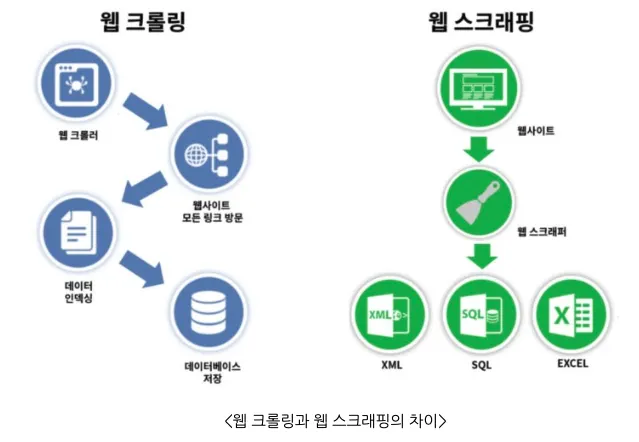
웹 크롤링의 종류 - 정적/동적
정적 웹페이지
•
웹 서버에 미리 저장된 파일이 그대로 전달되는 웹페이지
•
특정 웹페이지의 url 주소만 주소창에 입력하면 웹 브라우저로 해당 html 정보를 마음대로 가져다 쓸 수 있다.
•
url 주소 외에 아무것도 필요 없다
동적 웹페이지
•
url만으로는 들어갈 수 없는 웹페이지
•
실시간으로 내용이 계속 추가되거나 수정이 되면 동적 웹페이지
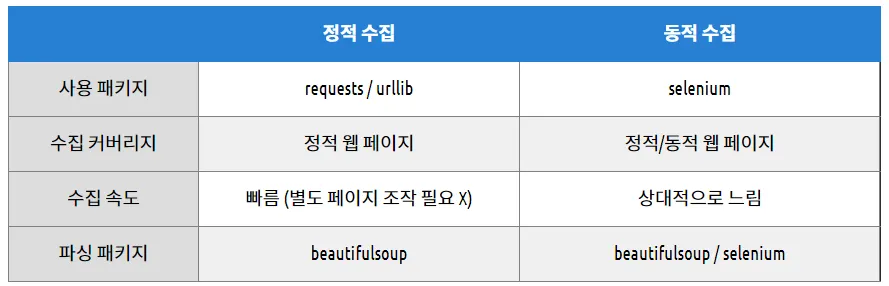
정적 수집
•
멈춰있는 페이지의 html을 requests 혹은 urllib 패키지를 이용해 가져와서 beautifulsoup 패키지로 파싱하여 원하는 정보를 수집
파싱 : 복잡한 html문서를 분류, 정리하여 다루기 쉽게 바꾸는 작업
•
장점
◦
바로 해당 url의 html을 받아와서 수집하기 때문에 수집속도가 빠르다
◦
요청에 대한 파일만 전송하면 되기 때문에 서버간 통신이 거의 없고 속도가 빠름
◦
단순한 문서들로만 이루어져 있어서 어떤 호스팅서버에서도 동작 가능하므로 구축하는데 드는 비용이 적음
•
단점
◦
여기저기 모두 사용할수 있는 범용성은 떨어진다
◦
저장된 정보만 보여주기 때문에 서비스가 한정적
◦
추가, 수정, 삭제 등의 작업을 서버에서 직접 다운받아 편집 후 업로드로 수정해줘야 하기 때문에 관리가 어려움
동적 수집
•
계속 움직이는 페이지를 다루기 위해 selenium 패키지로 chromdriver를 제어
•
driver.find_elements_by 함수를 이용해 html을 곧바로 지목해서 추출
•
driver.page_source 함수를 이용해 전체 html을 받아 올 수 있다.
•
장점
◦
html 전체를 받아와서 beautifulsoup로 파싱하면 페이지에서 하나하나 가져오는 것보다 수집 속도가 빠르다.
◦
다양한 정보를 조합하여 웹 페이지를 제공하기 때문에 서비스가 다양함
◦
추가, 수정, 삭제 등의 작업이 가능하기 때문에 관리가 편함
•
단점
◦
브라우저를 직접 조작하고 브라우저가 실행될때까지 기다려주기도 해야해서 속도가 느리다
◦
웹 페이지를 보여주기 위해서 여러번의 비동기 통신을 처리하기 때문에 상대적으로 속도가 느림
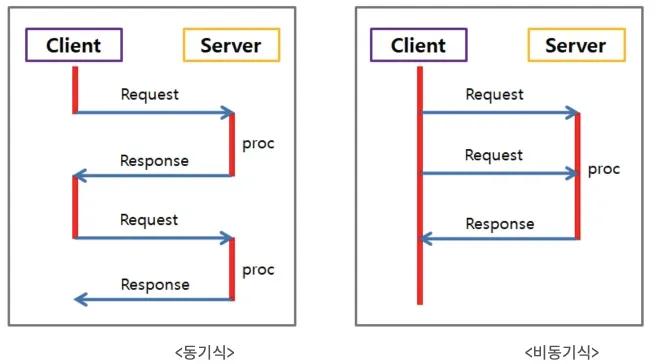
 -동기비동기-블로킹논블로킹-개념-정리
-동기비동기-블로킹논블로킹-개념-정리