.gif&blockId=11b00c82-b138-8050-a58b-dcbceda2ef8f)



앙상블(Ensemble)
•
여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법
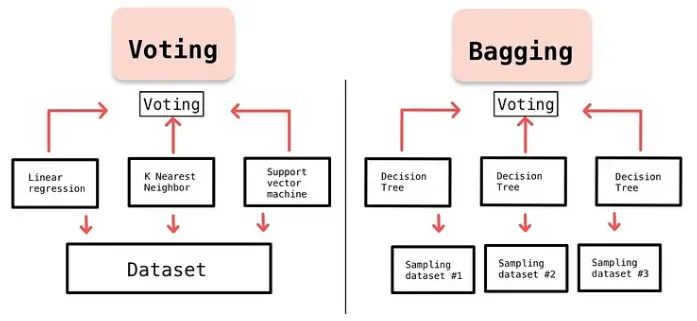
Bagging
1.
데이터로부터 복원추출을 통해 n개의 bootstrap sample 생성
2.
해당 sample에 대해서 모델 학습
3.
1,2 과정을 M번 반복한 후 최종 Bagging 모델을 정의
Random Forest
•
Decision Tree의 주요 단점 : 훈련 데이터에 과대적합되는 경향이 있다는 것이다.
•
랜덤 포레스트는 해당 문제를 회피할 수 있는 방법이다.
•
랜덤하게 일부 샘플들과 일부 피쳐들을 뽑아서 여러개의 트리를 만들어서 앙상블하는 모델
•
주요 파라미터
◦
n_estimators: 생성할 트리의 개수
◦
max_features: 각 트리가 얼마나 무작위가 될지를 결정하며 작을 수록 과대적합을 줄여준다.
(일반적으로 기본값을 추천)
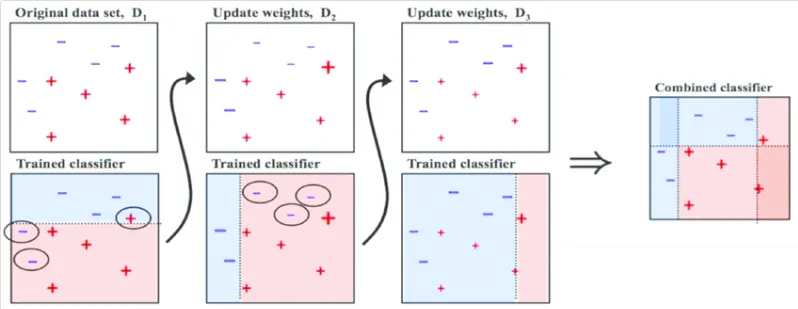
Boosting
1.
weak learner를 생성한 후 Error를 계산
2.
Error에 기여한 Sample마다 다른 가중치를 주고 해당 Error를 감소시키는 새로운 모델 학습
3.
1,2 과정을 M번 반복한 후 최종 Boosting 모델을 정의
Gradient Boost
•
보통 max_depth를 1 ~ 5 이하로 설정하여 약한 트리들을 만들어 학습하는 알고리즘
•
트리 기반 부스팅 앙상블 모델
•
머신러닝 알고리즘 중에서 가장 예측 성능이 높다고 알려졌고 인기있는 알고리즘
•
주요 파라미터
◦
max_depth: 1 ~ 5 이하로 설정
◦
n_estimators: 생성할 트리의 개수
◦
learning_rate: 얼마나 강하게 보정할지를 정하는 수치
•
GBM(Gradient Boost)를 병렬 학습이 지원되도록 구현한 라이브러리.
•
따라서 GBM보다 학습이 빠르다.
•
◦
일반 파라미터
▪
부스팅을 수행할 때 트리를 사용할지, 선형 모델을 사용할지 등을 고른다.
◦
부스터 파라미터
▪
선택한 부스터에 따라서 적용할 수 있는 파라미터 종류가 다르다.
◦
학습 과정 파라미터
▪
학습 시나리오를 결정한다.
•
과적합 방지를 위해 조정해야 하는 것
◦
learning_rate 낮추기 & n_estimators 높이기
◦
max_depth 낮추기
◦
min_child_weight 높이기
◦
gamma 높이기
from xgboost import to_graphviz
to_graphviz(xgb)
Python
복사

•
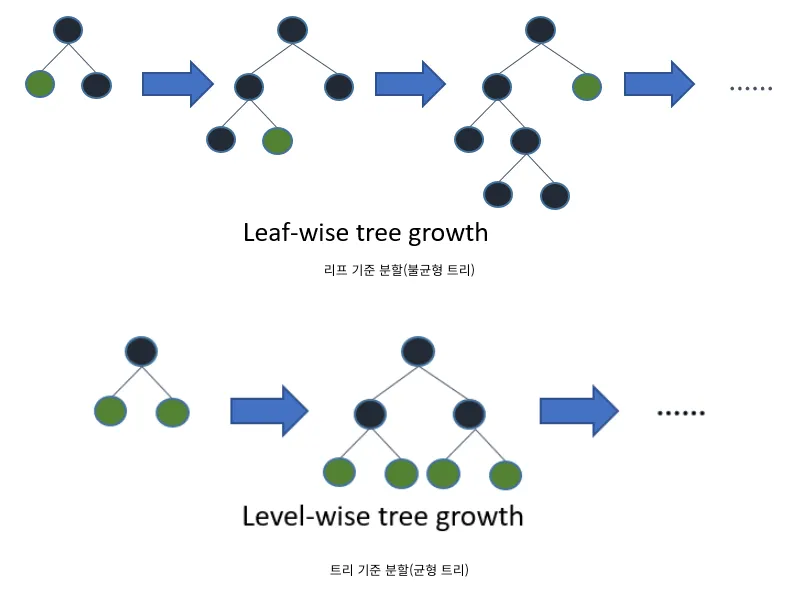
LightGBM은 트리 기준 분할이 아닌 리프 기준 분할 방식을 사용한다.
•
트리의 군형을 맞추지 않고 최대 손실 값을 갖는 리프 노드를 지속적으로 분할하면서 깊고 비대칭적인 트리를 생성한다.
•
이렇게 하면 트리 기준 분할 방식에 비해 예측 오류 손실을 최소화할 수 있다.
•
장점
◦
XGBoost보다 빠르다.
◦
대용량 데이터 처리 가능(메로리 사용량이 상대적으로 적다)
•
◦
num_leaves: 클수록 정확도는 높아지지만 오버피팅 발생 가능
◦
min_data_in_leaf: 클수록 오버피팅 방지
◦
max_depth: 낮추기
◦
learning_rate 낮추기 & n_estimators 높이기
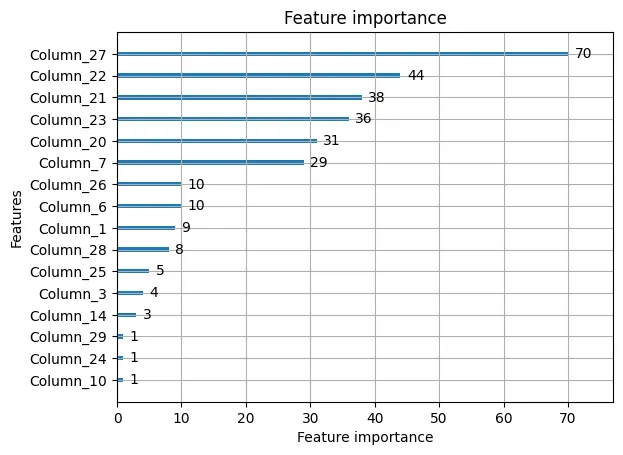
from lightgbm import LGBMClassifier, plot_importance
hp = {
"random_state" : 42,
"max_depth" : 2,
"n_estimators" : 100,
"learning_rate": 0.01,
}
lgb = LGBMClassifier(**hp).fit(X_tr, y_tr)
print(f'훈련용 평가지표: {lgb.score(X_tr, y_tr)} / 테스트용 평가지표: {lgb.score(X_te, y_te)}')
plot_importance(lgb)
plt.show()
Python
복사
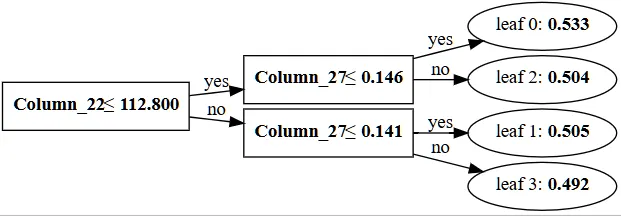
from lightgbm import create_tree_digraph
create_tree_digraph(lgb)
Python
복사
•
범주형 변수가 많을 경우 높은 성능과 함께 빠른 학습 속도를 제공한다.
◦
범주형 변수를 인코딩 하지 않고 넣어도 된다.
•
수치형 변수가 많을 경우 매우 느리다.
•
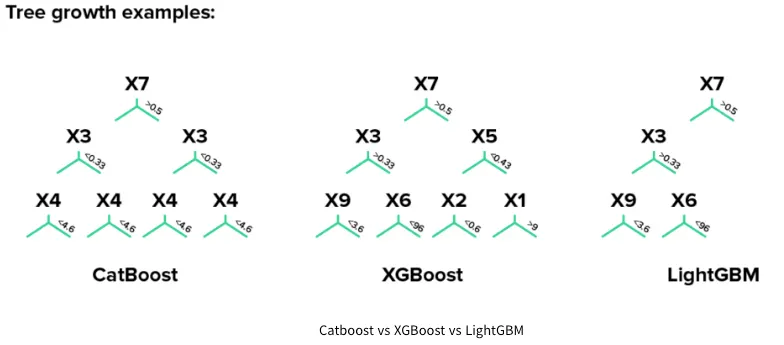
LightGBM은 알고리즘 종류 중 DFS(깊이 우선 탐색)처럼 트리를 우선적으로 깊게 형성하는 방식이다.
•
반면에 XGBmmost와 Catboost는 BFS(너비 우선 탐색)처럼 우선적으로 넓게 트리를 형성한다.
•
이때 XGBoost와 Catboost의 차이점은 트리가 나누어지는 Feature들이 대칭인지 여부에 따라 차이가 난다.
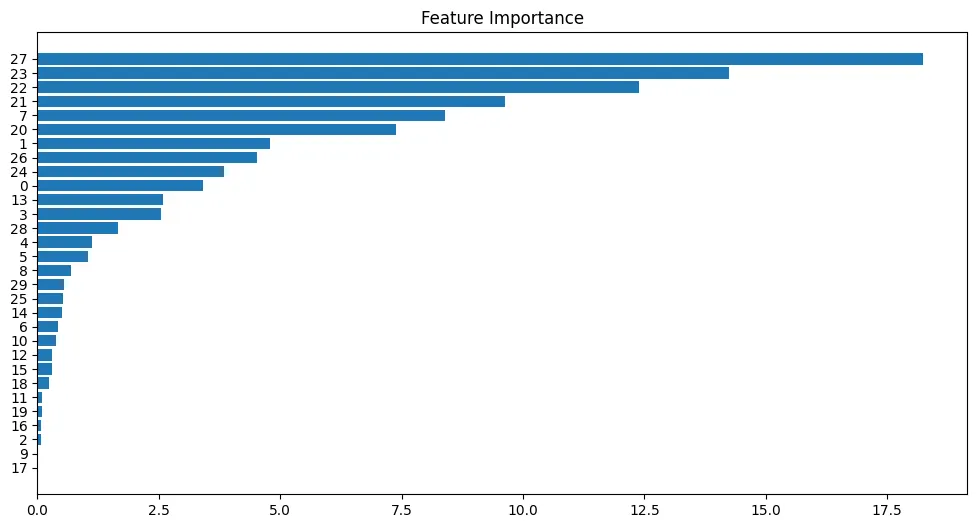
feature_importance = cat.feature_importances_
sorted_idx = np.argsort(feature_importance)
fig = plt.figure(figsize=(12, 6))
plt.barh(range(len(sorted_idx)), feature_importance[sorted_idx], align='center')
plt.yticks(range(len(sorted_idx)), np.array(range(len(X_tr)))[sorted_idx])
# 변수명이 있다면, 아래와 같이...
# plt.yticks(range(len(sorted_idx)), np.array(X_test.columns)[sorted_idx])
plt.title('Feature Importance')
Python
복사
Voting
다른 종류의 모델들의 예측값을 합쳐 최종 결과를 도출해내는 과정
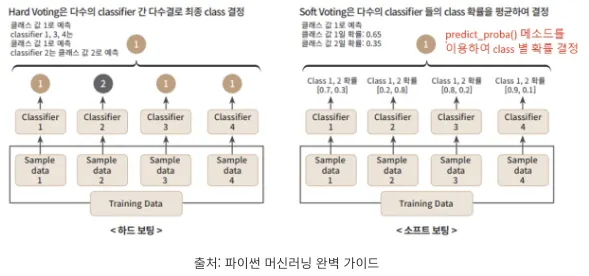
•
Hard voting
◦
모델들의 예측 결과값을 다수결로 최종 class 결정
•
Soft voting
◦
모델들의 예측 결과값간 확률을 평균하여 최종 class 결정
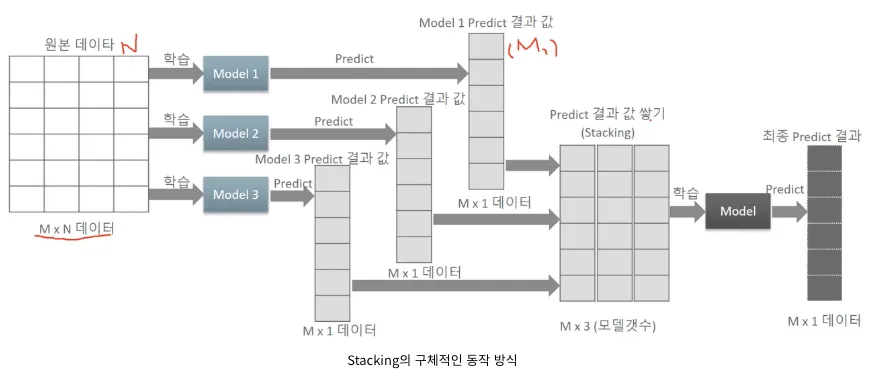
Stacking
개별적인 모델들이 학습하고 예측한 데이터를 쌓아서 또 다른 학습데이터를 만들고 이 데이터를 기반으로 메타 모델을 하나 더 만들어 예측하는 모델이다.
1.
1. training dataset을 이용하여 sub model 예측 결과를 생성한다.
2.
2. 1번의 output 결과를 이용하여 training data로 사용하여 meta learner 모델을 생성한다.