


머신러닝 워크플로우
Global Variables
from easydict import EasyDict as edict
args = edict()
args.SEED = 10
args.target_col = 'target'
args
# {'SEED': 10, 'target_col': 'target'}
Python
복사
데이터 수집(또는 데이터 로드)
•
유방암 데이터
총 30개의 속성과 malignant(악성), benign(양성)의 두가지 타겟값을 가지고 있다.
from sklearn.datasets import load_breast_cancer
# 데이터 로드
breast_cancer = load_breast_cancer()
Python
복사
dir(breast_cancer)
['DESCR',
'data',
'data_module',
'feature_names',
'filename',
'frame',
'target',
'target_names']
Python
복사
feature: 학습 및 예측을 할 데이터의 특징, 항목 들
 Bioinformatics[머신러닝] 머신러닝, 딥러닝 Feature/Attribute , Class 뜻. (feat. Feature selection 이 필요한 이유)
target: 목표
Bioinformatics[머신러닝] 머신러닝, 딥러닝 Feature/Attribute , Class 뜻. (feat. Feature selection 이 필요한 이유)
target: 목표
Bioinformatics[머신러닝] 머신러닝, 딥러닝 Feature/Attribute , Class 뜻. (feat. Feature selection 이 필요한 이유)
target: 목표•
feature_names : feature 이름들
breast_cancer.feature_names
array(['mean radius', 'mean texture', 'mean perimeter', 'mean area',
'mean smoothness', 'mean compactness', 'mean concavity',
'mean concave points', 'mean symmetry', 'mean fractal dimension',
'radius error', 'texture error', 'perimeter error', 'area error',
'smoothness error', 'compactness error', 'concavity error',
'concave points error', 'symmetry error',
'fractal dimension error', 'worst radius', 'worst texture',
'worst perimeter', 'worst area', 'worst smoothness',
'worst compactness', 'worst concavity', 'worst concave points',
'worst symmetry', 'worst fractal dimension'], dtype='<U23')
Python
복사
•
target_name : target 이름들
breast_cancer.target_names
array(['malignant', 'benign'], dtype='<U9')
Python
복사
•
description : 해당 데이터 셋에 대한 설명
print(breast_cancer.DESCR)
.. _breast_cancer_dataset:
Breast cancer wisconsin (diagnostic) dataset
--------------------------------------------
**Data Set Characteristics:**
:Number of Instances: 569
:Number of Attributes: 30 numeric, predictive attributes and the class
:Attribute Information:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
...
Python
복사
학습용/검증용 데이터 분리
•
분리하는 이유
◦
머신러닝 모델의 성능을 공정하고 정확하게 평가하기 위함
◦
피처 데이터를 제대로 학습 시키기 위해서
◦
모델 학습이 잘 되기 위해서
•
종류
◦
학습용 데이터 (Training Data)
▪
학습용 데이터는 모델이 학습하는 데 사용되는 데이터
▪
이 데이터를 통해 모델은 입력과 출력 간의 패턴을 학습하고, 주어진 작업을 수행할 수 있도록 파라미터를 최적화함.
◦
검증용 데이터 (Validation Data)
▪
검증용 데이터는 모델이 학습하지 않은 데이터
▪
학습 과정에서 모델의 성능을 평가하고 최적화하기 위해 사용
▪
학습 과정 중에 하이퍼파라미터 튜닝이나 모델 선택에 사용되며, 과적합(overfitting)을 방지하는 데 중요한 역할을 함
•
모듈 가져오기
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
Python
복사
•
데이터 분리
df_cancer = pd.DataFrame(breast_cancer.data, columns= breast_cancer.feature_names)
df_cancer[args.target_col] = breast_cancer[args.target_col]
print(df_cancer.shape)
# (569, 31) : (row: 데이터 양, column: feature=표현)
Python
복사
shape은 NumPy 배열이나 Pandas DataFrame의 형태(차원)를 나타내는 속성
데이터 구조의 행(row)과 열(column)의 개수를 튜플 형태로 반환
행 (Row) : 세로
•
하나의 데이터 포인트: 데이터셋에서 각 행은 하나의 개별 데이터 포인트(혹은 레코드, 샘플)를 나타낸다.
•
예를 들어, 의료 데이터셋에서는 하나의 환자 정보를 나타낼 수 있고, 금융 데이터셋에서는 하나의 거래 기록을 나타낼 수 있다.
•
예시: 만약 train.shape가 (100, 10)이라면, train 데이터셋에는 100개의 행이 있으며, 이는 100개의 개별 데이터 포인트가 있다는 것을 의미
열 (Column) : 가로
•
특징 (Feature) 또는 변수 (Variable): 데이터셋에서 각 열은 데이터 포인트의 한 가지 속성이나 변수를 나타낸다.
•
예를 들어, 의료 데이터셋에서는 나이, 성별, 혈압 등의 속성이 열로 표현될 수 있다.
•
예시: train.shape가 (100, 10)이라면, train 데이터셋에는 10개의 열이 있으며, 이는 각 데이터 포인트가 10개의 다른 특징(변수)을 가지고 있다는 의미
•
데이터 분리
◦
Row로 짜르는 이유
▪
학습한거 내에서 평가받아야 하기 때문
▪
훈련 데이터와 테스트 데이터가 독립적인 샘플로 구성되어야 한다.
▪
한 데이터셋에 속하는 모든 속성(Feature)은 하나의 샘플을 완전하게 구성해야 하며, 이를 위해 행(Row) 단위로 나누어야 한다.
# train_test_split
train, test = train_test_split(df_cancer, random_state=args.SEED) # 특정 시드로 랜덤 상태 지정
train.shape, test.shape # Row로 짤림 - 학습과 평가
# ((426, 31), (143, 31))
Python
복사
데이터 점검 및 탐색
•
test 데이터는 탐색하지 않음!!
•
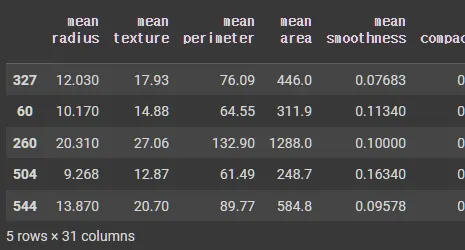
head 데이터 (상위 5개)
train.head()
Python
복사
•
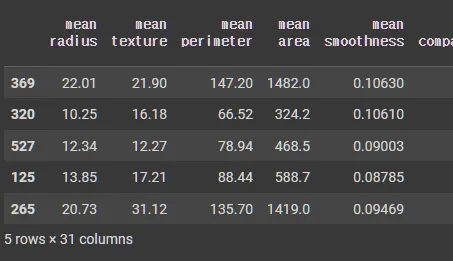
tail 데이터 (하위 5개)
train.tail()
Python
복사
•
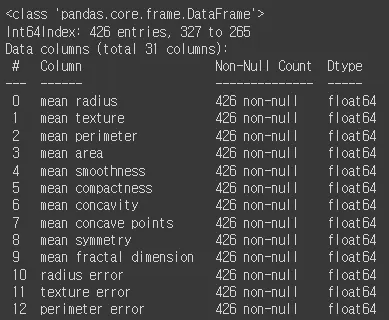
info 데이터 :
각 열의 데이터 타입과 **결측치(null)**가 있는지 확인
train.info()
Python
복사
•
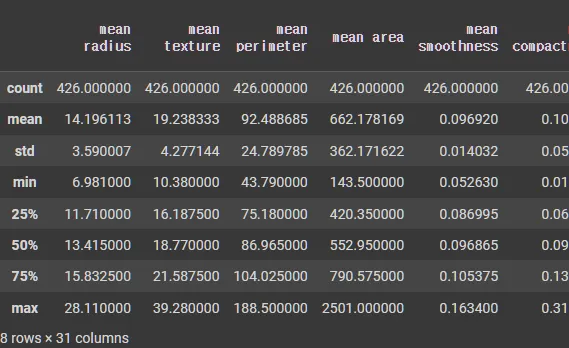
describe 데이터 : 수치형 변수에 대한 기술 통계(평균, 표준편차, 최소값, 최대값 등)를 확인
train.describe()
Python
복사
전처리 및 정제
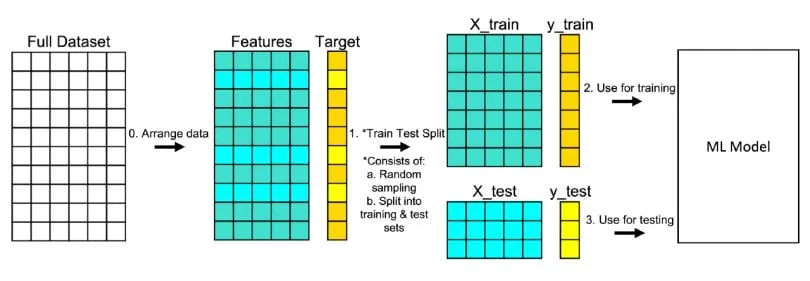
•
데이터 정리 및 분할 : features과 target 분리
x_train, x_test = train.drop(args.target_col, axis=1), test.drop(args.target_col, axis=1)
y_train, y_test = train[args.target_col], test[args.target_col]
Python
복사
•
shape 확인
◦
학습
x_train.shape, y_train.shape
# ((426, 30), (426,))
Python
복사
◦
검증
x_test.shape, y_test.shape
# ((143, 30), (143,))
Python
복사
•
전처리 모듈 다운
from sklearn.preprocessing import StandardScaler
Python
복사
◦
스케일 조정 StandardScaler()
▪
평균 0 , 분산 1로 조정
▪
# standardization
scaler = StandardScaler()
train_scaled = scaler.fit_transform(x_train)
test_scaled = scaler.transform(x_test)
print(f'train.shape: {train.shape}')
print('-'*50)
print(f'train_scaled.shape: {train_scaled.shape}')
# train.shape: (426, 31)
# --------------------------------------------------
# train_scaled.shape: (426, 30)
train_scaled[:1,:]
# array([[-0.60408221, -0.30624914, -0.66228757, -0.59759609, -1.43340425,
# -1.28487074, -1.11254551, -1.12909991, -1.61436823, -0.31081757,
# -0.62155456, -0.5783191 , -0.6928 , -0.50501258, -0.76703944,
# -1.07161825, -1.2493379 , -1.30374665, -0.74688387, -0.81051627,
# -0.67577053, -0.55621057, -0.74396171, -0.63568485, -1.45739321,
# -1.18985953, -1.29522303, -1.34634798, -1.23731664, -0.76362748]])
Python
복사
모델링 및 훈련
from sklearn.linear_model import LogisticRegression
Python
복사
# logistic regression
lr_clf = LogisticRegression()
# 훈련
lr_clf.fit(x_train, y_train)
Python
복사

평가
from sklearn.metrics import accuracy_score
Python
복사
# 예측
pred = lr_clf.predict(x_test)
# 정확도 측정
accuracy_score(y_test, pred)
# 0.9300699300699301
Python
복사
