


라이브러리 로드
클러스터링(Clustering)
•
클러스터링은 비지도 학습방법이므로 label(정답)이 존재하지 않는 상태에서 학습을 통해 비슷한 개체끼리 그룹으로 묶는다.
•
만약 label이 존재하면서 그룹으로 나눈다면 그것은 지도학습의 분류(Classification) 모델이다.
K-means
•
K개의 랜덤한 중심점으로 부터 가까운 데이터들을 묶는 군집화 기법
•
평균을 사용함에 따라 이상치에 민감
•
거리를 재기 때문에 스케일링 필수
•
초기 중심에 민감
•
K-means++
◦
초기 중심점 선정의 어려움을 해결하기 위한 방법
•
주요 파라미터
◦
n_clusters : 군집수
◦
init : 기본값이 k-means++
알고리즘 작동방식
mglearn.plots.plot_kmeans_algorithm()
Python
복사
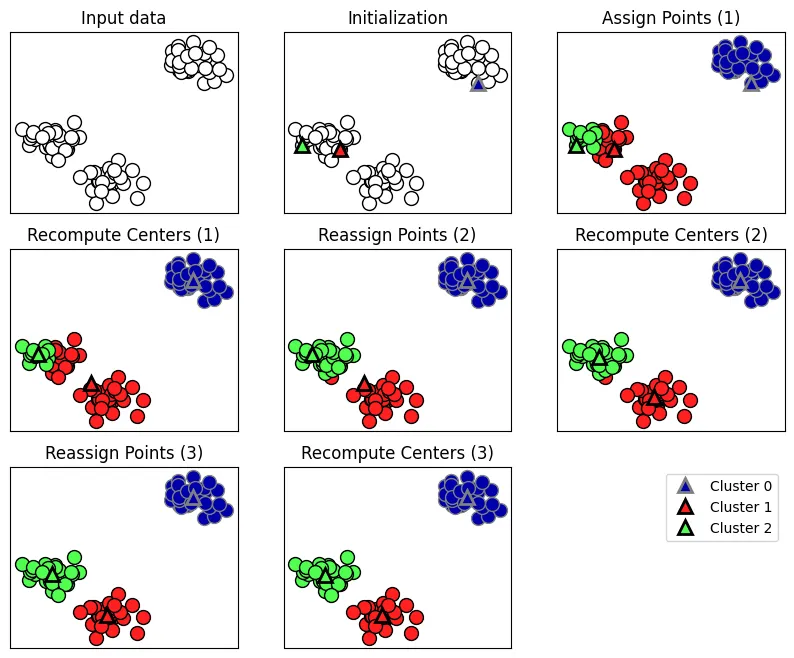
상기 그래프는 K-means의 알고리즘 작동방식을 나타내었습니다.
1.
랜덤으로 중심 초기화(Initialization)
2.
포인트 할당(Assign Points)
데이터 포인트를 가장 가까운 클러스터 중심으로 할당
3.
중심 재계산(Recompute Centers)
클러스터에 할당된 데이터 포인트의 평균으로 클러스터 중심 재정의
4.
포인트 변화가 없을 때까지 2번,3번 반복
모델 학습
from sklearn.datasets import make_blobs
# 인위적으로 2차원 데이터를 생성
X, y = make_blobs(random_state=1)
X.shape, y.shape
# ((100, 2), (100,))
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
Python
복사
# 학습한 라벨 확인
kmeans.labels_
array([0, 1, 1, 1, 2, 2, 2, 1, 0, 0, 1, 1, 2, 0, 2, 2, 2, 0, 1, 1, 2, 1,
2, 0, 1, 2, 2, 0, 0, 2, 0, 0, 2, 0, 1, 2, 1, 1, 1, 2, 2, 1, 0, 1,
1, 2, 0, 0, 0, 0, 1, 2, 2, 2, 0, 2, 1, 1, 0, 0, 1, 2, 2, 1, 1, 2,
0, 2, 0, 1, 1, 1, 2, 0, 0, 1, 2, 2, 0, 1, 0, 1, 1, 2, 0, 0, 0, 0,
1, 0, 2, 0, 0, 1, 1, 2, 2, 0, 2, 0], dtype=int32)
[ ]
# 새로운(?) 데이터 예측하기
kmeans.predict(X)
array([0, 1, 1, 1, 2, 2, 2, 1, 0, 0, 1, 1, 2, 0, 2, 2, 2, 0, 1, 1, 2, 1,
2, 0, 1, 2, 2, 0, 0, 2, 0, 0, 2, 0, 1, 2, 1, 1, 1, 2, 2, 1, 0, 1,
1, 2, 0, 0, 0, 0, 1, 2, 2, 2, 0, 2, 1, 1, 0, 0, 1, 2, 2, 1, 1, 2,
0, 2, 0, 1, 1, 1, 2, 0, 0, 1, 2, 2, 0, 1, 0, 1, 1, 2, 0, 0, 0, 0,
1, 0, 2, 0, 0, 1, 1, 2, 2, 0, 2, 0], dtype=int32)
[ ]
y # 실제 라벨 확인
array([0, 1, 1, 1, 2, 2, 2, 1, 0, 0, 1, 1, 2, 0, 2, 2, 2, 0, 1, 1, 2, 1,
2, 0, 1, 2, 2, 0, 0, 2, 0, 0, 2, 0, 1, 2, 1, 1, 1, 2, 2, 1, 0, 1,
1, 2, 0, 0, 0, 0, 1, 2, 2, 2, 0, 2, 1, 1, 0, 0, 1, 2, 2, 1, 1, 2,
0, 2, 0, 1, 1, 1, 2, 0, 0, 1, 2, 2, 0, 1, 0, 1, 1, 2, 0, 0, 0, 0,
1, 0, 2, 0, 0, 1, 1, 2, 2, 0, 2, 0])
Python
복사
