붓꽃 데이터
데이터 선택
import seaborn as sns
iris = sns.load_dataset("iris")
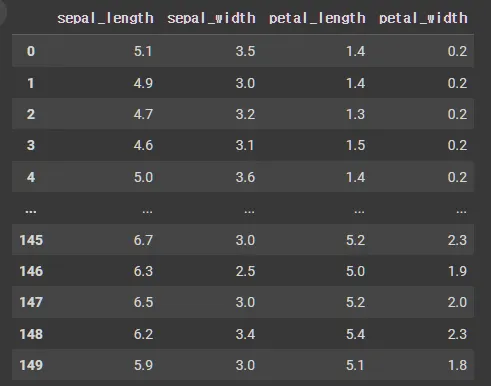
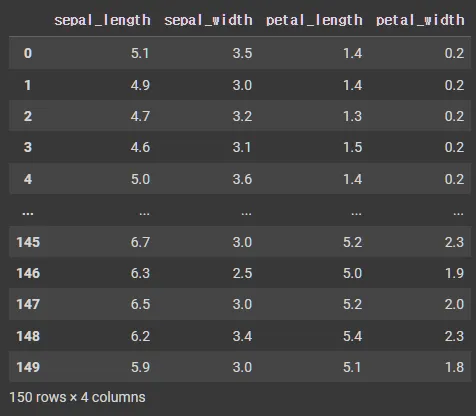
iris.head()
Python
복사
isin(조건) : 조건에 맞는 데이터는 True로 반환, 나머지는 False
1.
원본 데이터 확인
iris['petal_length']
# Data
0 1.4
1 1.4
2 1.3
3 1.5
4 1.4
...
145 5.2
146 5.0
147 5.2
148 5.4
149 5.1
Name: petal_length, Length: 150, dtype: float64
Python
복사
2.
조건 데이터 확인
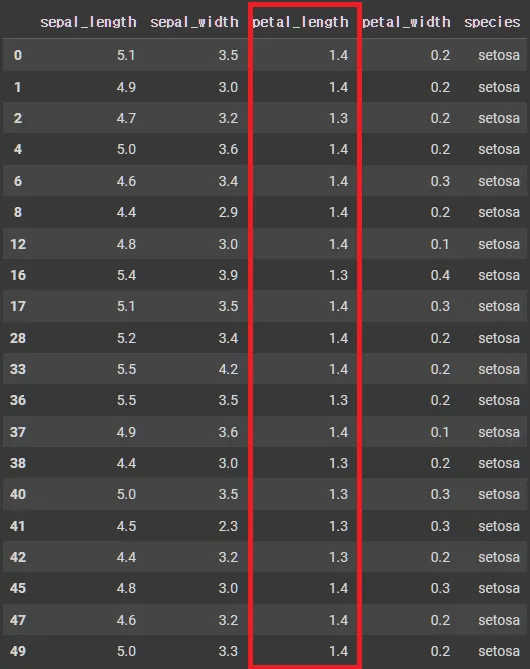
cond = iris['petal_length'].isin([1.4,1.3])
cond
# Data
0 True
1 True
2 True
3 False
4 True
...
145 False
146 False
147 False
148 False
149 False
Name: petal_length, Length: 150, dtype: bool
Python
복사
3.
위의 조건 데이터와 일치하는 데이터만 검색
iris[cond]
# iris[cond][:5] # 슬라이싱도 가능
Python
복사
iloc[] : row, column 데이터 추출
•
row 행 데이터 추출
iris.iloc[4]
sepal_length 5.0
sepal_width 3.6
petal_length 1.4
petal_width 0.2
species setosa
Name: 4, dtype: object
Python
복사
•
row 행 다중 데이터 추출
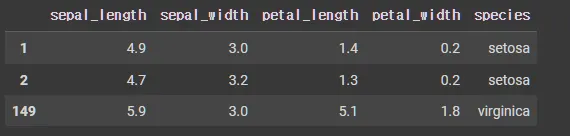
iris.iloc[[1,2,-1]] # -1은 마지막 행번호를 나타냄(loc에서는 사용할 수 없음)
Python
복사
•
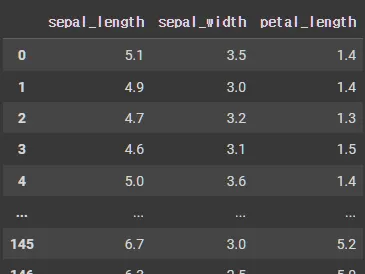
row, column 필터링 데이터 조회
iris.iloc[:,:3] # iloc[행, 열]
Python
복사
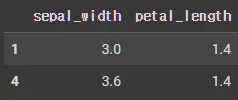
•
row, column 필터링 부분 데이터 추출
iris.iloc[[1,4],[1,2]]
Python
복사
loc[] :
•
row 데이터 추출
iris.loc[4]
sepal_length 5.0
sepal_width 3.6
petal_length 1.4
petal_width 0.2
species setosa
Name: 4, dtype: object
Python
복사
•
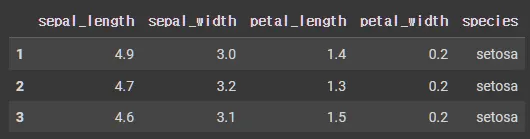
row 부분 데이터 추출
iris.loc[[1,2,3]]
Python
복사
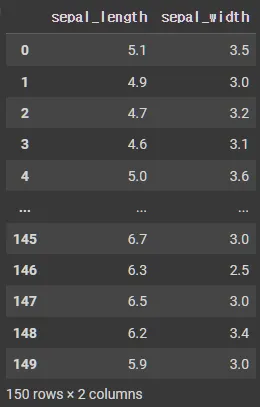
•
column 문자열 필터링 데이터 추출
iris.loc[:,['sepal_length', 'sepal_width']]
Python
복사
마스킹을 이용한 다중 조건 데이터 선택
& : and
•
두개의 조건이 모두 참인 경우, True
| : or
•
두개 중 하나 이상의 조건이 참인 경우, True
~ : not
•
거짓인 경우, True
마스킹
•
기본 마스킹
mask = iris['sepal_length'] < 5.0
iris.loc[mask].head()
Python
복사
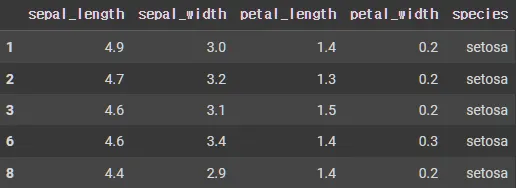
•
AND 마스킹
mask1 = iris['sepal_length'] < 5.0
mask2 = iris['sepal_width'] > 3.0
mask = mask1 & mask2
iris.loc[mask].head()
Python
복사
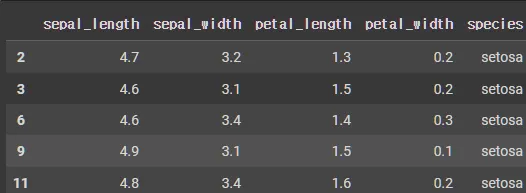
•
OR 마스킹
mask1 = iris['sepal_length'] < 5.0
mask2 = iris['sepal_width'] > 3.0
mask = mask1 | mask2
iris.loc[mask].head()
Python
복사
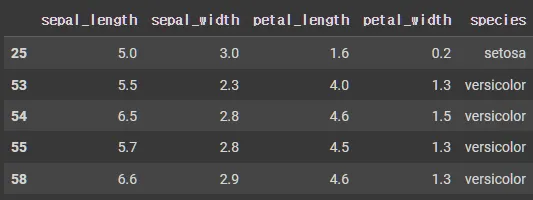
•
NOT 마스킹
mask1 = iris['sepal_length'] < 5.0
mask2 = iris['sepal_width'] > 3.0
mask = mask1 | mask2
iris.loc[~mask].shape
# (74,5)
iris.loc[~mask].head()
Python
복사
데이터 형식에 기반한 열 선택 (select_dtypes)
•
통계 분석 시 많이 사용
include 사용 (포함)
•
숫자형 검증
iris.select_dtypes(include=np.number)
Python
복사
•
데이터형 검증
iris.select_dtypes(include='float64')
Python
복사
exclude 사용 (제외)
•
사용법은 위와 동일
iris.select_dtypes(exclude=np.number)
Python
복사

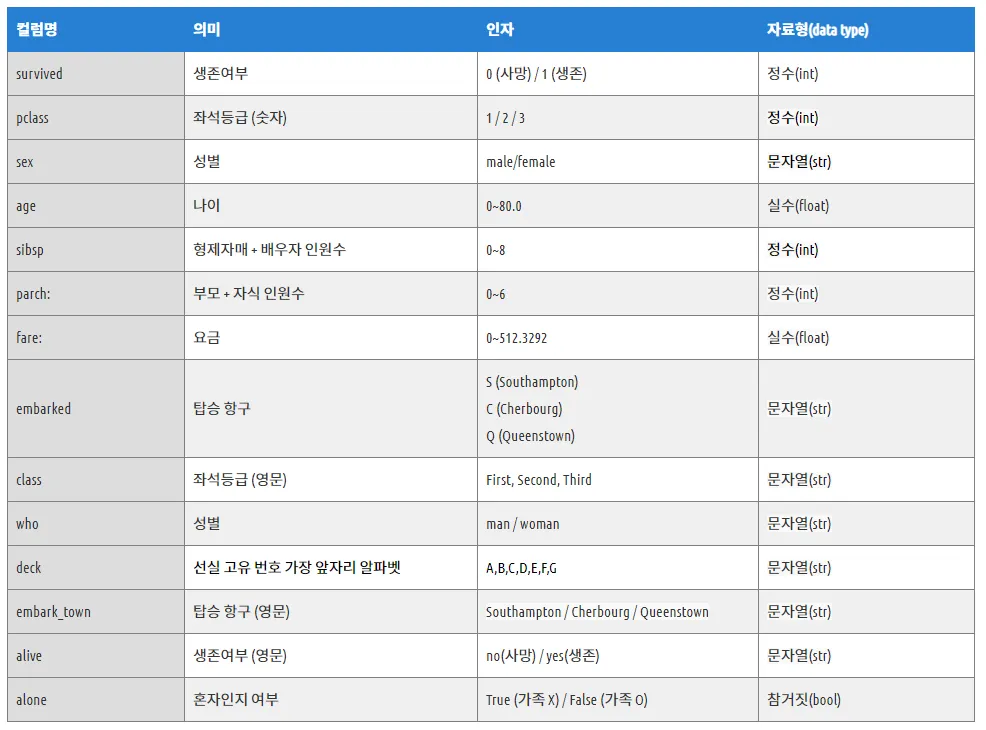
타이타닉
데이터 로드
import seaborn as sns
df = sns.load_dataset('titanic') # 타이타닉 데이터 받아오기
Python
복사
기본 데이터 조회
•
df.head()

•
df.tail()
NULL 값 확인
df.isnull() : 테이블을 널 유무로 판단하여 Boolean으로 표시
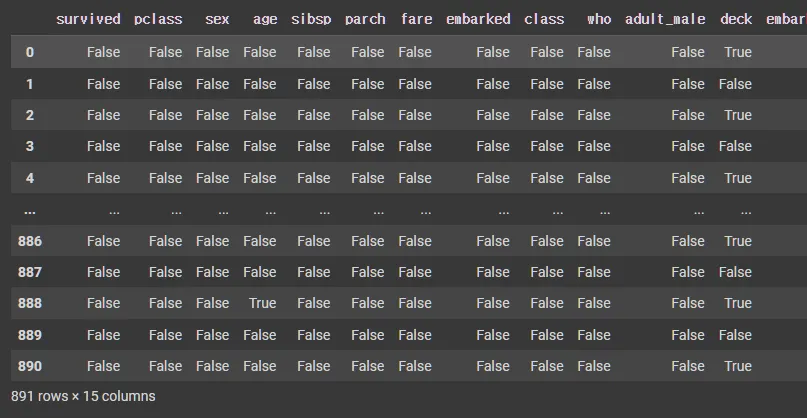
df.isnull().sum() : 칼럼 별 Null 확인
df.isnull().sum() # 컬럼별 널 확인
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
dtype: int64
Python
복사
df.isnull().sum().sum() : 전체 Null 확인
df.isnull().sum().sum() # 전체 널 확인
869
Python
복사
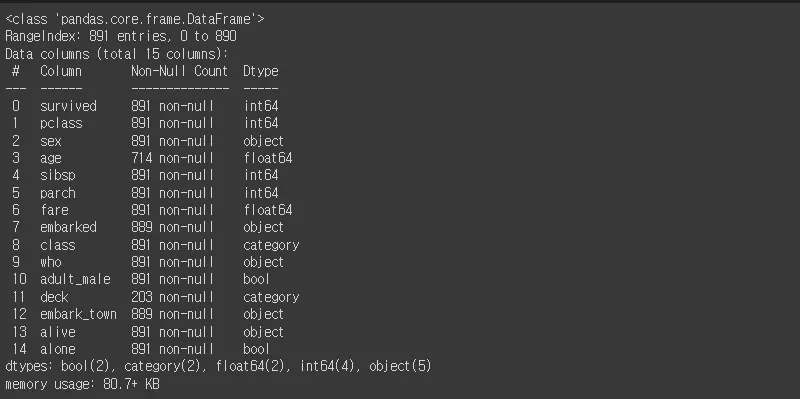
df.info() : 상세 정보 확인
df.info() # 전체 수, null이 있는 컬럼, 데이터 타입 등을 알 수 있음
Python
복사
통계
•
메서드 종류
◦
count() : NaN 값을 제외하고 데이터의 개수를 반환
◦
sum() : 전체 값의 합계 반환
◦
mean() : 평균 값 계산
◦
median() : 중앙값 계산
◦
min(), max() : 최대/최소값 반환
◦
abs() : 모든 값의 절대값 계산
◦
std() : 표준 편차 계산
count()
•
NaN 값을 제외하고 데이터의 개수를 반환
df_number['age'].count() # Series의 통계값을 얻을 수 있음
# 28
Python
복사
sum()
•
전체 값의 합계 반환
df.isnull().sum().sum() # 전체 널 확인
# 869
Python
복사
mean()
•
평균 값 계산
df_number.mean() # DataFrame에서 사용하면 컬럼별 통계값을 얻을 수 있음
survived 0.383838
pclass 2.308642
age 29.699118
sibsp 0.523008
parch 0.381594
fare 32.204208
dtype: float64
Python
복사
•
로우 기준 통계값
df_number.mean(1) # 숫자1을 인풋파람에 넣으면, 로우 기준으로 통계값을 얻을 수 있음
0 5.541667
1 18.713883
2 6.320833
3 15.183333
4 7.675000
...
886 7.000000
887 8.500000
888 5.890000
889 9.666667
890 7.125000
Length: 891, dtype: float64
Python
복사
median()
•
평균 값 계산
df_number['age'].median() # Series의 통계값을 얻을 수 있음
# 28.0
Python
복사
min(), max()
•
평균 값 계산
df_number.max() - (df_number.std() + df_number.min()) # 가장 큰수 - (표준편차 + 가장 작은 수)
survived 0.513408
pclass 1.163929
age 65.053503
sibsp 6.897257
parch 5.193943
fare 462.635771
dtype: float64
Python
복사
abs()
•
평균 값 계산
df_number['age'].median() # Series의 통계값을 얻을 수 있음
# 28.0
Python
복사
std()
•
평균 값 계산
df_number['age'].median() # Series의 통계값을 얻을 수 있음
# 28.0
Python
복사
var()
•
분산
df_number.var() # 분산
survived 0.236772
pclass 0.699015
age 211.019125
sibsp 1.216043
parch 0.649728
fare 2469.436846
dtype: float64
Python
복사
value_counts()
df_object.columns
# Index(['sex', 'embarked', 'class', 'who', 'adult_male', 'deck', 'embark_town',
# 'alive', 'alone'],
# dtype='object')
Python
복사
•
valudf_object['class'].value_counts()
•
value 갯수 세기
df_object['class'].value_counts()
# Third 491
# First 216
# Second 184
# Name: class, dtype: int64
df_object['embarked'].value_counts()
# S 644
# C 168
# Q 77
# Name: embarked, dtype: int64
Python
복사
unique(), nunique()
•
unique()
df_object['class'].unique()
# ['Third', 'First', 'Second']
# Categories (3, object): ['First', 'Second', 'Third']
Python
복사
•
nunique()
df_object['class'].nunique()
# 3
Python
복사
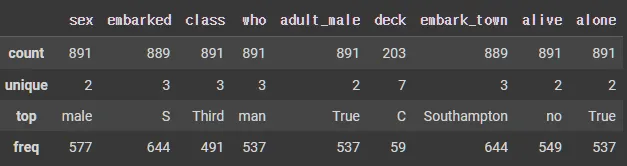
df.describe(exclude=np.number) # 카테고리 데이터에 대한 통계값들
df.describe(include='all') # 수 & 카테고리 데이터 전부에 대한 통계값들
Python
복사

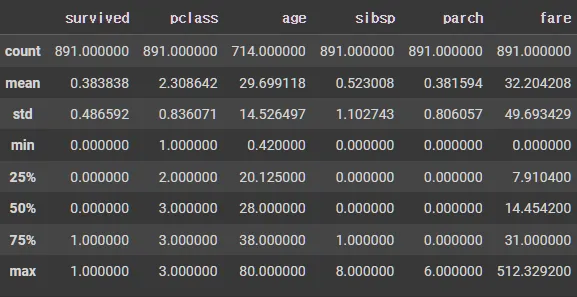
df.describe(include=np.number) # 수에 대한 통계값들
Python
복사
df.describe(exclude=np.number) # 카테고리 데이터에 대한 통계값들
Python
복사
df['adult_male'].describe() # Series에서도 사용가능
# count 891
#unique 2
# top True
# freq 537
# Name: adult_male, dtype: object
Python
복사
map() : series 선택 연산
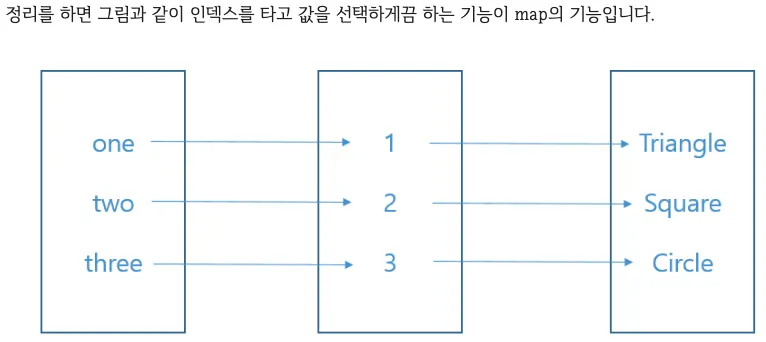
x = pd.Series({'one':1,'two':2,'three':3})
y = pd.Series({1:'triangle',2:'square',3:'circle'})
x
# one 1
# two 2
# three 3
# dtype: int64
y
# 1 triangle
# 2 square
# 3 circle
# dtype: object
x.map(y)
# one triangle
# two square
# three circle
# dtype: object
y.map(x)
# 1 NaN
# 2 NaN
# 3 NaN
# dtype: float64
Python
복사
apply() : + matrix 선택 연산
•
기본
df_tmp = pd.DataFrame(np.arange(12).reshape(4,3),columns=['a','b','c'])
df_tmp
Python
복사
•
Series에 적용
df_tmp['a'].apply(lambda x:x*2) # Series에 적용
0 0
1 6
2 12
3 18
Name: a, dtype: int64
df_tmp
Python
복사
•
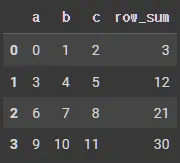
column, row 합계
df_tmp.apply(lambda x:x.sum()) # column 합계
# a 18
# b 22
# c 26
# dtype: int64
df_tmp.apply(lambda x:x.sum(), axis=1) # row 합계
# 0 3
# 1 12
# 2 21
# 3 30
# dtype: int64
Python
복사
•
반환값 추가
df_tmp['row_sum'] = df_tmp.apply(lambda x:x.sum(), axis=1)
df_tmp
Python
복사
•
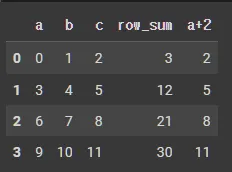
a의 각 data에 덧셈연산한 칼럼들 추가
•
함수 연산 값 추가
def tmpFnc(a,b):
return a+b
df_tmp['a+b'] = df_tmp.apply(lambda x:tmpFnc(x['a'], x['b']), axis=1)
df_tmp
Python
복사
집합
칼럼 조회
df.columns
# Index(['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'fare',
# 'embarked', 'class', 'who', 'adult_male', 'deck', 'embark_town',
# 'alive', 'alone'],
# dtype='object')
Python
복사
선택 칼럼 조회
select_cols = ['age', 'sex', 'pclass', 'fare', 'survived']
df_groupby = df[select_cols]
df_groupby.head()
Python
복사
•
데이터 중에서 두 개의 열을 각각 행 인덱스, 열 인덱스로 사용하여 데이터를 조회하는 것
pd.pivot_table(data(데이터프레임), index='행으로 사용할 열', columns='열로 사용할 열', values='데이터로 사용할 열', aggfunc='데이터 집계함수')
Python
복사
•
파라미터
◦
data: 데이터프레임
◦
values: 데이터로 사용할 열
◦
index: 행으로 사용할 열
◦
columns: 열로 사용할 열
◦
aggfunc: 데이터 집계함수
•
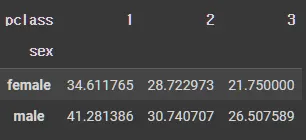
예제 1
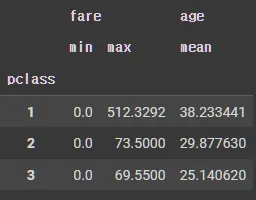
pd.pivot_table(df_groupby, index='sex', columns='pclass', values='age', aggfunc='mean')
Python
복사
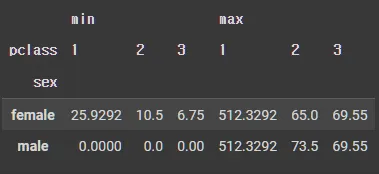
•
예제 2
pd.pivot_table(df_groupby, index='sex', columns='pclass', values='fare', aggfunc=['min', 'max'])
Python
복사
groupby
•
특정 기준으로 그룹화하고, 그룹별로 집계 및 분석을 수행
grouped = df.groupby(by, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=<no_default>, observed=False, dropna=True)
Python
복사
•
파라미터
◦
by: 그룹화할 기준이 되는 열 이름이나 열 이름의 리스트
예: by='column_name' 또는 by=['column1', 'column2']
◦
axis: 그룹화할 축을 지정합니다. 0은 행(기본값), 1은 열을 기준으로 그룹화
◦
level: 멀티인덱스일 때 특정 레벨을 기준으로 그룹화할 수 있다.
◦
as_index: True면 그룹화 기준이 되는 열이 인덱스로 설정, False면 인덱스가 아닌 일반 열
◦
sort: True면 그룹화된 결과를 그룹 키를 기준으로 정렬
◦
group_keys: True면 그룹화 키를 그룹의 결과에 포함
◦
observed: 범주형 데이터의 경우, 관측된 범주만을 그룹화할지 여부를 결정
◦
dropna: True면 NaN 값을 가진 그룹을 제외
1.
단일 열을 기준으로 그룹화
grouped = df.groupby('column_name') # column_name의 각 값에 대해 그룹화
Python
복사
이렇게 하면 column_name의 각 값에 대해 그룹화가 이루어집니다.
2.
여러 열을 기준으로 그룹화
grouped = df.groupby(['column1', 'column2']) # column1과 column2의 값 조합을 기준으로 그룹화
Python
복사
•
예시 1
for key, group in grouped:
print("* key", key)
print("* count", len(group))
print(group.head())
print('\n')
Python
복사
* key female
* count 314
age sex pclass fare survived
1 38.0 female 1 71.2833 1
2 26.0 female 3 7.9250 1
3 35.0 female 1 53.1000 1
8 27.0 female 3 11.1333 1
9 14.0 female 2 30.0708 1
* key male
* count 577
age sex pclass fare survived
0 22.0 male 3 7.2500 0
4 35.0 male 3 8.0500 0
5 NaN male 3 8.4583 0
6 54.0 male 1 51.8625 0
7 2.0 male 3 21.0750 0
Python
복사
•
예제 2 - 여러 칼럼 기준 집합
grouped = df_groupby.groupby(['sex','pclass'])
for key, group in grouped:
print("* key", key)
print("* count", len(group))
print(group.head())
print('\n')
Python
복사
* key ('female', 1)
* count 94
age sex pclass fare survived
1 38.0 female 1 71.2833 1
3 35.0 female 1 53.1000 1
11 58.0 female 1 26.5500 1
31 NaN female 1 146.5208 1
52 49.0 female 1 76.7292 1
* key ('female', 2)
* count 76
age sex pclass fare survived
9 14.0 female 2 30.0708 1
15 55.0 female 2 16.0000 1
41 27.0 female 2 21.0000 0
43 3.0 female 2 41.5792 1
53 29.0 female 2 26.0000 1
* key ('female', 3)
* count 144
age sex pclass fare survived
2 26.0 female 3 7.9250 1
8 27.0 female 3 11.1333 1
10 4.0 female 3 16.7000 1
14 14.0 female 3 7.8542 0
18 31.0 female 3 18.0000 0
* key ('male', 1)
* count 122
age sex pclass fare survived
6 54.0 male 1 51.8625 0
23 28.0 male 1 35.5000 1
27 19.0 male 1 263.0000 0
30 40.0 male 1 27.7208 0
34 28.0 male 1 82.1708 0
* key ('male', 2)
* count 108
age sex pclass fare survived
17 NaN male 2 13.0 1
20 35.0 male 2 26.0 0
21 34.0 male 2 13.0 1
33 66.0 male 2 10.5 0
70 32.0 male 2 10.5 0
* key ('male', 3)
* count 347
age sex pclass fare survived
0 22.0 male 3 7.2500 0
4 35.0 male 3 8.0500 0
5 NaN male 3 8.4583 0
7 2.0 male 3 21.0750 0
12 20.0 male 3 8.0500 0
Python
복사
agg
•
groupby()와 함께 사용되는 메서드로, 그룹화된 데이터에 대해 여러 개의 집계 함수(aggregation function)를 적용할 수 있게 해줌
•
한 번에 여러 함수를 적용하거나, 다른 열에 대해 다른 함수를 적용할 수 있어 매우 유용
grouped = df_groupby.groupby(['sex'])
Python
복사
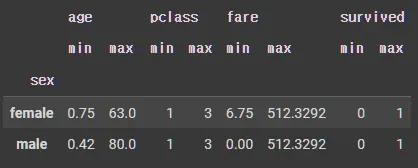
•
최대 최소
grouped.agg(['min', 'max'])
Python
복사
•
딕셔너리 형태
agg_dict = {
'fare': ['min', 'max'],
'age': 'mean'
}
agg_dict
grouped.agg(agg_dict)
Python
복사
transform()
•
그룹별로 매핑함수를 적용하긴 하지만, 그룹별로 집계하지 않고 원래 데이터프레임의 형태로 반환함.
•
아래는 그룹별 데이터를 조회할 때, 일반적인 방법과 transform()를 이용한 방법
◦
일반적인 방법
grouped = df_groupby.groupby(['pclass'])
Python
복사
age_mean = grouped.age.mean()
age_std = grouped.age.std()
for key, group in grouped.age:
group_zscore = (group - age_mean.loc[key]) / age_std.loc[key]
print("* origin :", key)
print(group_zscore.head(3))
print('\n')
Python
복사
* origin : 1
1 -0.015770
3 -0.218434
6 1.065103
Name: age, dtype: float64
* origin : 2
9 -1.134029
15 1.794317
17 NaN
Name: age, dtype: float64
* origin : 3
0 -0.251342
2 0.068776
4 0.789041
Name: age, dtype: float64
Python
복사
◦
transform은 그룹을 기준으로 연산을 하고 그 결과는 다시 원래 데이터프레임의 형태로 반환
def z_score(x):
return (x - x.mean())/ x.std()
# tmp = 'age'
# df_transform = grouped[tmp]transform(z_score)
df_transform = grouped.age.transform(z_score)
print(df_transform.iloc[[1,3,6]])
print(df_transform.iloc[[9,15,17]])
print(df_transform.iloc[[0,2,4]])
Python
복사
1 -0.015770
3 -0.218434
6 1.065103
Name: age, dtype: float64
9 -1.134029
15 1.794317
17 NaN
Name: age, dtype: float64
0 -0.251342
2 0.068776
4 0.789041
Name: age, dtype: float64
Python
복사
기타 응용
filter
test = grouped.filter(lambda x : x.age.mean() < 30) # 그룹별 나이평균이 30미만인 그룹만 조회
print(test.head())
print(test['pclass'].unique())
Python
복사
age sex pclass fare survived
0 22.0 male 3 7.2500 0
2 26.0 female 3 7.9250 1
4 35.0 male 3 8.0500 0
5 NaN male 3 8.4583 0
7 2.0 male 3 21.0750 0
[3 2]
Plain Text
복사
apply, describe
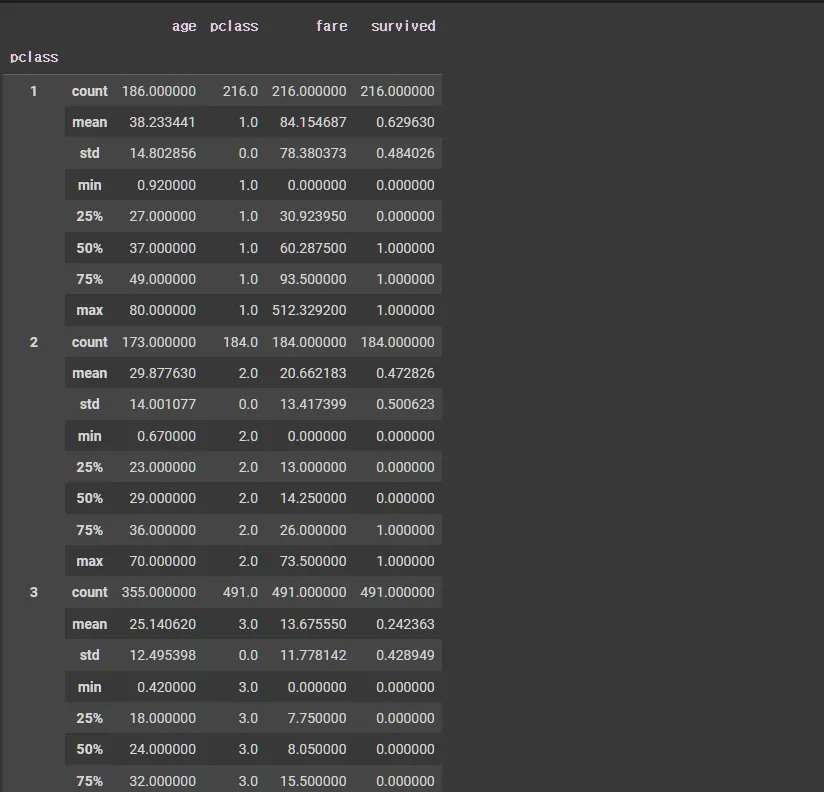
grouped.apply(lambda x : x.describe()) # 그룹별 통계정보
Python
복사
합치기
merge()
•
두 개의 데이터프레임을 특정 기준에 따라 병합(조인)할 때 사용하는 메서드
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
Python
복사
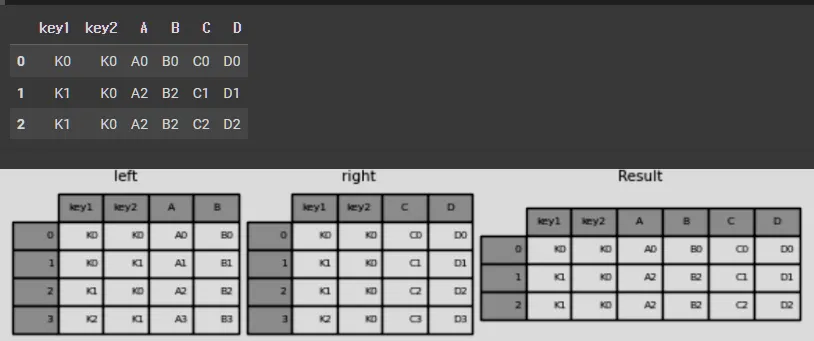
on=””
left = pd.DataFrame(
{
"key": ["K0", "K1", "K2", "K3"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
right = pd.DataFrame(
{
"key": ["K0", "K1", "K2", "K3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
result = pd.merge(left, right, on="key")
result
Python
복사

left = pd.DataFrame(
{
"key1": ["K0", "K0", "K1", "K2"],
"key2": ["K0", "K1", "K0", "K1"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
right = pd.DataFrame(
{
"key1": ["K0", "K1", "K1", "K2"],
"key2": ["K0", "K0", "K0", "K0"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
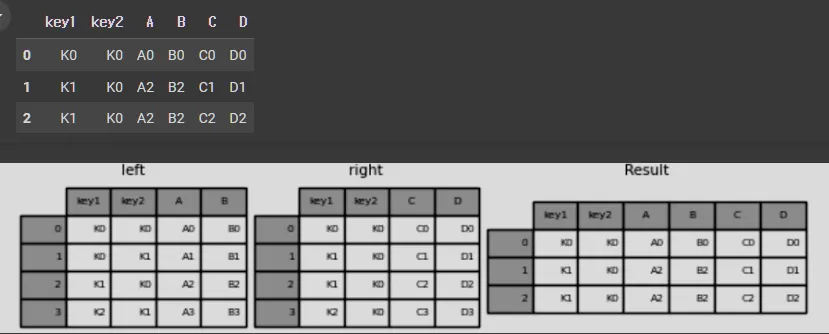
result = pd.merge(left, right, on=["key1", "key2"])
result
Python
복사
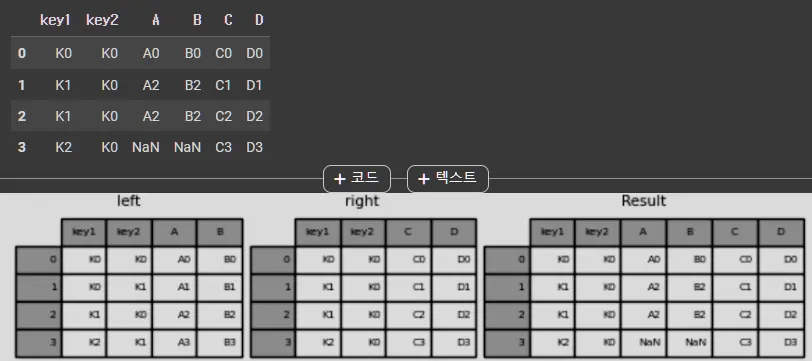
how="left"
result = pd.merge(left, right, how="left", on=["key1", "key2"])
result
Python
복사

how="right"
result = pd.merge(left, right, how="right", on=["key1", "key2"])
result
Python
복사
how="outer"
result = pd.merge(left, right, how="outer", on=["key1", "key2"])
result
Python
복사

how=”inner”
resuSlt = pd.merge(left, right, how="inner", on=["key1", "key2"])
result
Python
복사
concat()
•
두 개 이상의 데이터프레임이나 시리즈를 이어붙이는(결합하는) 메서드
•
concat()은 SQL의 UNION과 비슷하게 데이터프레임을 위아래 또는 좌우로 결합할 수 있으며, 병합할 때 인덱스를 유지하거나 재설정할 수 있는 옵션을 제공
DataFrame & Series
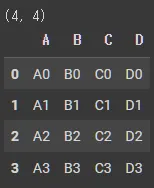
df1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
print(df1.shape)
df1.head()
Python
복사
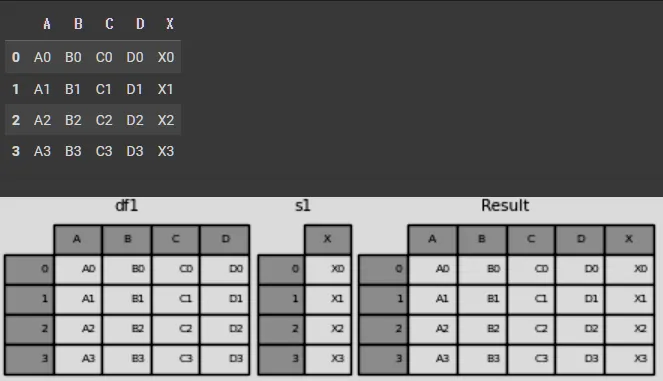
s1 = pd.Series(["X0", "X1", "X2", "X3"], name="X")
result = pd.concat([df1, s1], axis=1)
result
Python
복사
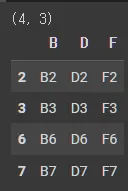
DataFrame & DataFrame
df4 = pd.DataFrame(
{
"B": ["B2", "B3", "B6", "B7"],
"D": ["D2", "D3", "D6", "D7"],
"F": ["F2", "F3", "F6", "F7"],
},
index=[2, 3, 6, 7],
)
print(df4.shape)
df4.head()
Python
복사
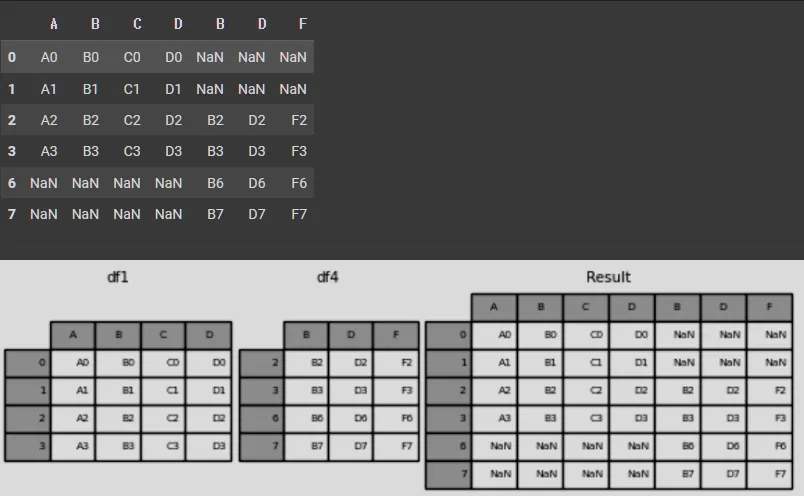
result = pd.concat([df1, df4], axis=1)
result
Python
복사